列存储
- 什么是列存储?
- 语法实现
- 语法格式
- 参数说明
- 示例
- 源码分析(创建表)
- 语法层(Gram.y)
- 子模块(utility.cpp)
- 总结
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档
什么是列存储?
列存储是一种优化技术,用于在数据库系统中存储和查询大量数据。与传统的行存储方式不同,列存储将每个列的数据分别存储在独立的存储单元中,而不是按照行的方式存储。这种存储方式在分析性查询、聚合操作和大规模数据处理等场景下具有很大的优势。
行、列存储模型各有优劣,建议根据实际情况选择。通常openGauss用于OLTP(联机事务处理)场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的OLAP(联机分析处理)场景时,才使用列存储。默认情况下,创建的表为行存储。行存储和列存储的差异如下图所示:
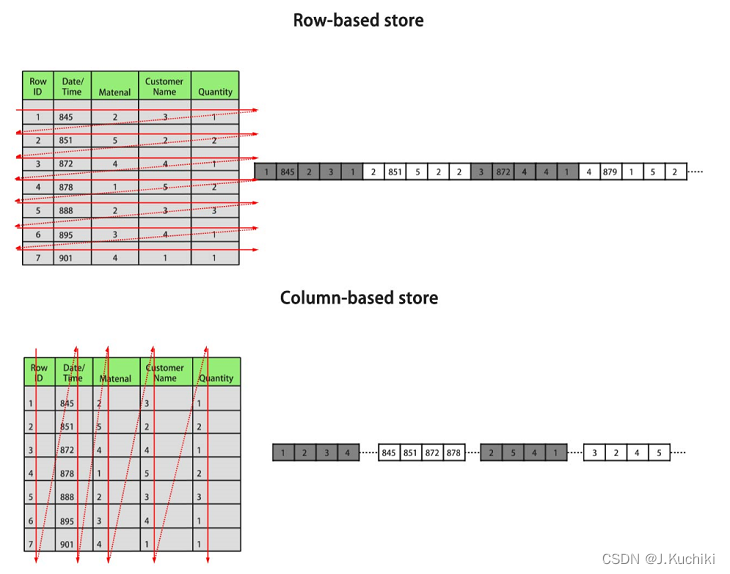
上图中,左上为行存表,右上为行存表在硬盘上的存储方式。左下为列存表,右下为列存表在硬盘上的存储方式。
列存储的特点和优势:
- 压缩效率高:由于相同类型的数据在列中是连续存储的,可以采用更加高效的压缩算法,从而减少存储空间的使用。
- 数据读取效率高:在查询中只加载需要的列,减少了不必要的数据传输,提高了查询效率。
- 聚合操作效率高:在列存储中,同一列的数据相邻存储,这样在进行聚合操作时只需要对该列中的数据进行计算,减少了不必要的读取和计算。
- 列存储适合分析性查询:分析性查询通常涉及多个列的聚合和筛选操作,列存储的存储方式更适合这种场景,可以提高查询效率。
- 适用于大规模数据处理:列存储在大规模数据处理、数据仓库等场景中具有明显的性能优势,能够更好地支持复杂的分析任务。
列存储相比于行存储的优点和缺点如下:
| 存储模型 | 优点 | 缺点 |
|---|---|---|
| 行存 | 数据被保存在一起。INSERT/UPDATE容易。 | 选择(SELECT)时即使只涉及某几列,所有数据也都会被读取。 |
| 列存 | 1. 查询时只有涉及到的列会被读取。 2. 投影(Projection)很高效。 3. 任何列都能作为索引。 | 1. 选择完成时,被选择的列要重新组装。 2. INSERT/UPDATE比较麻烦。 |
一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不多的情况下,适合列存储。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
| 存储类型 | 适用场景 |
|---|---|
| 行存 | 1. 点查询(返回记录少,基于索引的简单查询)。 2. 增、删、改操作较多的场景。 3. 频繁的更新、少量的插入。 |
| 列存 | 1. 统计分析类查询 (关联、分组操作较多的场景)。 2. 即席查询(查询条件不确定,行存表扫描难以使用索引)。 3. 一次性大批量插入。 4. 表列数较多,建议使用列存表。 5. 如果每次查询时,只涉及了表的少数(<50%总列数)几个列,建议使用列存表。 |
语法实现
语法格式
CREATE TABLE table_name
(column_name data_type [, ... ])
[ WITH ( ORIENTATION = value) ];
参数说明
| 参数 | 说明 |
|---|---|
| table_name | 要创建的表名。 |
| column_name | 新表中要创建的字段名。 |
| data_type | 字段的数据类型。 |
| ORIENTATION | 指定表数据的存储方式,即行存方式、列存方式,该参数设置成功后就不再支持修改。 取值范围: ROW,表示表的数据将以行式存储。 行存储适合于OLTP业务,适用于点查询或者增删操作较多的场景。 ROW,表示表的数据将以行式存储。 列存储适合于数据仓库业务,此类型的表上会做大量的汇聚计算,且涉及的列操作较少。 |
示例
来看一下官方文档给出的两个实际案例:
- 不指定ORIENTATION参数时,表默认为行存表。例如:
openGauss=# CREATE TABLE customer_test1
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
);
--删除表
openGauss=# DROP TABLE customer_test1;
- 创建列存表时,需要指定ORIENTATION参数。例如:
openGauss=# CREATE TABLE customer_test2
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
)
WITH (ORIENTATION = COLUMN);
--删除表
openGauss=# DROP TABLE customer_test2;
源码分析(创建表)
语法层(Gram.y)
接下来从代码实现层面来看看吧,创建列存表所涉及的语法代码如下:
注:Gram.y文件是YACC(Yet Another Compiler Compiler)工具生成的语法分析器的输入文件,用于解析SQL语句或其他领域特定语言。
columnDef: ColId Typename ColCmprsMode create_generic_options ColQualList
{
ColumnDef *n = makeNode(ColumnDef);
n->colname = $1;
n->typname = $2;
n->inhcount = 0;
n->is_local = true;
n->is_not_null = false;
n->is_from_type = false;
n->storage = 0;
n->cmprs_mode = $3;
n->raw_default = NULL;
n->cooked_default = NULL;
n->collOid = InvalidOid;
n->fdwoptions = $4;
n->clientLogicColumnRef=NULL;
SplitColQualList($5, &n->constraints, &n->collClause,&n->clientLogicColumnRef, yyscanner);
$$ = (Node *)n;
}
;
下面我们来分析一下这段代码:
columnDef::这是一个非终结符,表示列定义的语法规则开始。ColId Typename ColCmprsMode create_generic_options ColQualList:这是规则的产生式,由一系列非终结符组成,代表列定义的各个部分。{ }:这是动作部分的开始和结束,包含在花括号内的代码会在解析这个规则时执行。ColumnDef *n = makeNode(ColumnDef);:在这里,创建了一个ColumnDef类型的节点,并将其指针赋值给 n。n->colname = $1;:将解析得到的列名(通过$1表示)赋值给列定义的节点的colname字段。n->typname = $2;:将解析得到的类型名赋值给列定义的节点的typname字段。n->inhcount = 0;:将继承计数字段初始化为 0。n->is_local = true;:设置is_local字段为true。n->is_not_null = false;:设置is_not_null字段为false。n->is_from_type = false;:设置is_from_type字段为false。n->storage = 0;:将存储字段初始化为 0。n->cmprs_mode = $3;:将解析得到的压缩模式赋值给cmprs_mode字段。n->raw_default = NULL;:将默认原始值字段初始化为NULL。n->cooked_default = NULL;:将默认经过处理的值字段初始化为NULL。n->collOid = InvalidOid;:将排序规则OID初始化为InvalidOid。n->fdwoptions = $4;:将解析得到的外部数据包含选项赋值给fdwoptions字段。n->clientLogicColumnRef=NULL;:将客户逻辑列引用字段初始化为NULL。SplitColQualList($5, &n->constraints, &n->collClause, &n->clientLogicColumnRef, yyscanner);:调用函数SplitColQualList,将解析得到的列限制、排序规则和客户逻辑列引用传递给相应的字段。$$ = (Node *)n;:将构造的列定义节点 n 赋值给规则的结果。;:表示语法规则结束。
其中,ColumnDef 结构一般在数据库的源代码中进行定义。它通常是作为系统内部数据结构的一部分,用于表示用户在创建表时定义的列的属性。
ColumnDef 结构源码如下:(路径:src/include/nodes/parsenodes_common.h)
/*
* ColumnDef - 列定义(用于各种创建操作)
*
* 如果列有默认值,我们可以在“原始”形式(未经转换的解析树)或“处理过”形式(经过解析分析的可执行表达式树)中拥有该值的表达式,
* 这取决于如何创建此 ColumnDef 节点(通过解析还是从现有关系继承)。在同一个节点中不应同时存在两者!
*
* 类似地,我们可以在原始形式(表示为 CollateClause,arg==NULL)或处理过形式(校对的 OID)中拥有 COLLATE 规范。
*
* 约束列表可能在由 gram.y 生成的原始解析树中包含 CONSTR_DEFAULT 项,但 transformCreateStmt 将删除该项并设置 raw_default。
* CONSTR_DEFAULT 项不应出现在任何后续处理中。
*/
typedef struct ColumnDef {
NodeTag type; /* 结点类型标记 */
char *colname; /* 列名 */
TypeName *typname; /* 列的数据类型 */
int kvtype; /* 如果使用 KV 存储,kv 属性类型 */
int inhcount; /* 列继承的次数 */
bool is_local; /* 列是否有本地(非继承)定义 */
bool is_not_null; /* 是否指定 NOT NULL 约束? */
bool is_from_type; /* 列定义来自表类型 */
bool is_serial; /* 列是否是序列类型 */
char storage; /* attstorage 设置,或默认为 0 */
int8 cmprs_mode; /* 应用于此列的压缩方法 */
Node *raw_default; /* 默认值(未经转换的解析树) */
Node *cooked_default; /* 默认值(经过转换的表达式树) */
CollateClause *collClause; /* 未经转换的 COLLATE 规范,如果有的话 */
Oid collOid; /* 校对 OID(如果未设置,则为 InvalidOid) */
List *constraints; /* 列的其他约束 */
List *fdwoptions; /* 每列的 FDW 选项 */
ClientLogicColumnRef *clientLogicColumnRef; /* 客户端逻辑引用 */
Position *position;
Form_pg_attribute dropped_attr; /* 在创建类似表 OE 过程中被删除的属性的结构 */
} ColumnDef;
这里重点来看看n->cmprs_mode = $3;也就是列的压缩方法是如何定义的:
ColCmprsMode: /* 列压缩模式规则 */
DELTA {$$ = ATT_CMPR_DELTA;} /* delta 压缩 */
| PREFIX {$$ = ATT_CMPR_PREFIX;} /* 前缀压缩 */
| DICTIONARY {$$ = ATT_CMPR_DICTIONARY;} /* 字典压缩 */
| NUMSTR {$$ = ATT_CMPR_NUMSTR;} /* 数字-字符串压缩 */
| NOCOMPRESS {$$ = ATT_CMPR_NOCOMPRESS;} /* 不压缩 */
| /* EMPTY */ {$$ = ATT_CMPR_UNDEFINED;} /* 用户未指定 */
;
以上代码是 opengauss 数据库系统中定义列压缩模式的规则。每行代码对应了一种列压缩模式,例如 DELTA 压缩、前缀压缩、字典压缩等。在解析和创建表的过程中,用户可以通过指定列的压缩模式来定义对该列的数据压缩方式。根据语法规则,解析器会将不同的压缩模式转换为对应的内部表示值,以便在内部进行处理。
子模块(utility.cpp)
函数 CreateCommand(路径:src/gausskernel/process/tcop/utility.cpp),用于处理创建表(CREATE 命令)的操作,源码如下:
/*
* Notice: parse_tree could be from cached plan, do not modify it under other memory context
*/
#ifdef PGXC
void CreateCommand(CreateStmt *parse_tree, const char *query_string, ParamListInfo params,
bool is_top_level, bool sent_to_remote)
#else
void CreateCommand(CreateStmt* parse_tree, const char* query_string, ParamListInfo params, bool is_top_level)
#endif
{
List* stmts = NIL;
ListCell* l = NULL;
Oid rel_oid;
#ifdef PGXC
bool is_temp = false;
bool is_object_temp = false;
PGXCSubCluster* sub_cluster = NULL;
char* tablespace_name = NULL;
char relpersistence = RELPERSISTENCE_PERMANENT;
bool table_is_exist = false;
char* internal_data = NULL;
List* uuids = (List*)copyObject(parse_tree->uuids);
char* first_exec_node = NULL;
bool is_first_node = false;
char* query_string_with_info = (char*)query_string;
char* query_string_with_data = (char*)query_string;
if (IS_PGXC_COORDINATOR && !IsConnFromCoord()) {
first_exec_node = find_first_exec_cn();
is_first_node = (strcmp(first_exec_node, g_instance.attr.attr_common.PGXCNodeName) == 0);
}
#endif
/*
* DefineRelation() needs to know "isTopLevel"
* by "DfsDDLIsTopLevelXact" to prevent "create hdfs table" running
* inside a transaction block.
*/
if (IS_PGXC_COORDINATOR && !IsConnFromCoord())
u_sess->exec_cxt.DfsDDLIsTopLevelXact = is_top_level;
/* Run parse analysis ... */
if (u_sess->attr.attr_sql.enable_parallel_ddl)
stmts = transformCreateStmt((CreateStmt*)parse_tree, query_string, NIL, true, is_first_node);
else
stmts = transformCreateStmt((CreateStmt*)parse_tree, query_string, NIL, false);
/*
* If stmts is NULL, then the table is exists.
* we need record that for searching the group of table.
*/
if (stmts == NIL) {
table_is_exist = true;
/*
* Just return here, if we continue
* to send if not exists stmt, may
* cause the inconsistency of metadata.
* If we under xc_maintenance_mode, we can do
* this to slove some problem of inconsistency.
*/
if (u_sess->attr.attr_common.xc_maintenance_mode == false)
return;
}
#ifdef PGXC
if (IS_MAIN_COORDINATOR) {
/*
* Scan the list of objects.
* Temporary tables are created on Datanodes only.
* Non-temporary objects are created on all nodes.
* In case temporary and non-temporary objects are mized return an error.
*/
bool is_first = true;
foreach (l, stmts) {
Node* stmt = (Node*)lfirst(l);
if (IsA(stmt, CreateStmt)) {
CreateStmt* stmt_loc = (CreateStmt*)stmt;
sub_cluster = stmt_loc->subcluster;
tablespace_name = stmt_loc->tablespacename;
relpersistence = stmt_loc->relation->relpersistence;
is_object_temp = stmt_loc->relation->relpersistence == RELPERSISTENCE_TEMP;
internal_data = stmt_loc->internalData;
if (is_object_temp)
u_sess->exec_cxt.hasTempObject = true;
if (is_first) {
is_first = false;
if (is_object_temp)
is_temp = true;
} else {
if (is_object_temp != is_temp)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("CREATE not supported for TEMP and non-TEMP objects"),
errdetail("You should separate TEMP and non-TEMP objects")));
}
} else if (IsA(stmt, CreateForeignTableStmt)) {
#ifdef ENABLE_MULTIPLE_NODES
validate_streaming_engine_status(stmt);
#endif
if (in_logic_cluster()) {
CreateStmt* stmt_loc = (CreateStmt*)stmt;
sub_cluster = stmt_loc->subcluster;
}
/* There are no temporary foreign tables */
if (is_first) {
is_first = false;
} else {
if (!is_temp)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("CREATE not supported for TEMP and non-TEMP objects"),
errdetail("You should separate TEMP and non-TEMP objects")));
}
} else if (IsA(stmt, CreateSeqStmt)) {
CreateSeqStmt* sstmt = (CreateSeqStmt*)stmt;
Const* n = makeConst(INT8OID, -1, InvalidOid, sizeof(int64), Int64GetDatum(sstmt->uuid), false, true);
uuids = lappend(uuids, n);
}
}
/* Package the internalData after the query_string */
if (internal_data != NULL) {
query_string_with_data = append_internal_data_to_query(internal_data, query_string);
}
/*
* Now package the uuids message that create table on RemoteNode need.
*/
if (uuids != NIL) {
char* uuid_info = nodeToString(uuids);
AssembleHybridMessage(&query_string_with_info, query_string_with_data, uuid_info);
} else
query_string_with_info = query_string_with_data;
}
/*
* If I am the main execute CN but not CCN,
* Notify the CCN to create firstly, and then notify other CNs except me.
*/
if (IS_PGXC_COORDINATOR && !IsConnFromCoord()) {
if (u_sess->attr.attr_sql.enable_parallel_ddl && !is_first_node) {
if (!sent_to_remote) {
RemoteQuery* step = makeNode(RemoteQuery);
step->combine_type = COMBINE_TYPE_SAME;
step->sql_statement = (char*)query_string_with_info;
if (is_object_temp)
step->exec_type = EXEC_ON_NONE;
else
step->exec_type = EXEC_ON_COORDS;
step->exec_nodes = NULL;
step->is_temp = is_temp;
ExecRemoteUtility_ParallelDDLMode(step, first_exec_node);
pfree_ext(step);
}
}
}
if (u_sess->attr.attr_sql.enable_parallel_ddl) {
if (IS_PGXC_COORDINATOR && !IsConnFromCoord() && !is_first_node)
stmts = transformCreateStmt((CreateStmt*)parse_tree, query_string, uuids, false);
}
#endif
#ifdef PGXC
/*
* Add a RemoteQuery node for a query at top level on a remote
* Coordinator, if not already done so
*/
if (!sent_to_remote) {
if (u_sess->attr.attr_sql.enable_parallel_ddl && !is_first_node)
stmts = AddRemoteQueryNode(stmts, query_string_with_info, EXEC_ON_DATANODES, is_temp);
else
stmts = AddRemoteQueryNode(stmts, query_string_with_info, CHOOSE_EXEC_NODES(is_object_temp), is_temp);
if (IS_PGXC_COORDINATOR && !IsConnFromCoord() &&
(sub_cluster == NULL || sub_cluster->clustertype == SUBCLUSTER_GROUP)) {
const char* group_name = NULL;
Oid group_oid = InvalidOid;
/*
* If TO-GROUP clause is specified when creating table, we
* only have to add required datanode in remote DDL execution
*/
if (sub_cluster != NULL) {
ListCell* lc = NULL;
foreach (lc, sub_cluster->members) {
group_name = strVal(lfirst(lc));
}
} else if (in_logic_cluster() && !table_is_exist) {
/*
* for CreateForeignTableStmt ,
* CreateTableStmt with user not attached to logic cluster
*/
group_name = PgxcGroupGetCurrentLogicCluster();
if (group_name == NULL) {
ereport(ERROR, (errcode(ERRCODE_UNDEFINED_OBJECT), errmsg("Cannot find logic cluster.")));
}
} else {
Oid tablespace_id = InvalidOid;
bool dfs_tablespace = false;
if (tablespace_name != NULL) {
tablespace_id = get_tablespace_oid(tablespace_name, false);
} else {
tablespace_id = GetDefaultTablespace(relpersistence);
}
/* Determine if we are working on a HDFS table. */
dfs_tablespace = IsSpecifiedTblspc(tablespace_id, FILESYSTEM_HDFS);
/*
* If TO-GROUP clause is not specified we are using the installation group to
* distribute table.
*
* For HDFS table/Foreign Table we don't refer default_storage_nodegroup
* to make table creation.
*/
if (table_is_exist) {
Oid rel_id = RangeVarGetRelid(((CreateStmt*)parse_tree)->relation, NoLock, true);
if (OidIsValid(rel_id)) {
Oid table_groupoid = get_pgxc_class_groupoid(rel_id);
if (OidIsValid(table_groupoid)) {
group_name = get_pgxc_groupname(table_groupoid);
}
}
if (group_name == NULL) {
group_name = PgxcGroupGetInstallationGroup();
}
} else if (dfs_tablespace || IsA(parse_tree, CreateForeignTableStmt)) {
group_name = PgxcGroupGetInstallationGroup();
} else if (strcmp(u_sess->attr.attr_sql.default_storage_nodegroup, INSTALLATION_MODE) == 0 ||
u_sess->attr.attr_common.IsInplaceUpgrade) {
group_name = PgxcGroupGetInstallationGroup();
} else {
group_name = u_sess->attr.attr_sql.default_storage_nodegroup;
}
/* If we didn't identify an installation node group error it out out */
if (group_name == NULL) {
ereport(ERROR,
(errcode(ERRCODE_UNDEFINED_OBJECT),
errmsg("Installation node group is not defined in current cluster")));
}
}
/* Fetch group name */
group_oid = get_pgxc_groupoid(group_name);
if (!OidIsValid(group_oid)) {
ereport(ERROR,
(errcode(ERRCODE_UNDEFINED_OBJECT), errmsg("Target node group \"%s\" doesn't exist", group_name)));
}
if (in_logic_cluster()) {
check_logic_cluster_create_priv(group_oid, group_name);
} else {
/* No limit in logic cluster mode */
/* check to block non-redistribution process creating table to old group */
if (!u_sess->attr.attr_sql.enable_cluster_resize) {
char in_redistribution = get_pgxc_group_redistributionstatus(group_oid);
if (in_redistribution == 'y') {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("Unable to create table on old installation group \"%s\" while in cluster "
"resizing.",
group_name)));
}
}
}
/* Build exec_nodes to table creation */
const int total_len = list_length(stmts);
Node* node = (Node*)list_nth(stmts, (total_len - 1));
// *node* should be a RemoteQuery Node
AssertEreport(query_string != NULL, MOD_EXECUTOR, "Node type is not remote type");
RemoteQuery* rquery = (RemoteQuery*)node;
// *exec_nodes* should be a NULL pointer
AssertEreport(!rquery->exec_nodes, MOD_EXECUTOR, "remote query is not DN");
rquery->exec_nodes = makeNode(ExecNodes);
/* Set group oid here for sending bucket map to dn */
rquery->exec_nodes->distribution.group_oid = group_oid;
if (find_hashbucket_options(stmts)) {
rquery->is_send_bucket_map = true;
}
/*
* Check node group permissions, we only do such kind of ACL check
* for user-defined nodegroup(none-installation)
*/
AclResult acl_result = pg_nodegroup_aclcheck(group_oid, GetUserId(), ACL_CREATE);
if (acl_result != ACLCHECK_OK) {
aclcheck_error(acl_result, ACL_KIND_NODEGROUP, group_name);
}
/*
* Notice!!
* In cluster resizing stage we need special processing logics in table creation as:
* [1]. create table delete_delta ... to group old_group on all DN
* [2]. display pgxc_group.group_members
* [3]. drop table delete_delta ==> drop delete_delta on all DN
*
* So, as normal, when target node group's status is marked as 'installation' or
* 'redistribution', we have to issue a full-DN create table request, remeber
* pgxc_class.group_members still reflects table's logic distribution to tell pgxc
* planner to build Scan operator in multi_nodegroup way. The reason we have to so is
* to be compatible with current gs_switch_relfilenode() invokation in cluster expand
* and shrunk mechanism.
*/
if (need_full_dn_execution(group_name)) {
/* Sepcial path, issue full-DN create table request */
rquery->exec_nodes->nodeList = GetAllDataNodes();
} else {
/* Normal path, issue only needs DNs in create table request */
Oid* members = NULL;
int nmembers = 0;
nmembers = get_pgxc_groupmembers(group_oid, &members);
/* Append nodeId to exec_nodes */
rquery->exec_nodes->nodeList = GetNodeGroupNodeList(members, nmembers);
pfree_ext(members);
if (uuids && nmembers < u_sess->pgxc_cxt.NumDataNodes) {
char* create_seqs;
RemoteQuery* step;
/* Create table in NodeGroup with sequence. */
create_seqs = assemble_create_sequence_msg(stmts, uuids);
step = make_remote_query_for_seq(rquery->exec_nodes, create_seqs);
stmts = lappend(stmts, step);
}
}
}
}
#endif
if (uuids != NIL) {
list_free_deep(uuids);
uuids = NIL;
}
/* ... and do it */
foreach (l, stmts) {
Node* stmt = (Node*)lfirst(l);
if (IsA(stmt, CreateStmt)) {
Datum toast_options;
static const char* const validnsps[] = HEAP_RELOPT_NAMESPACES;
/* forbid user to set or change inner options */
ForbidOutUsersToSetInnerOptions(((CreateStmt*)stmt)->options);
/* Create the table itself */
rel_oid = DefineRelation((CreateStmt*)stmt,
((CreateStmt*)stmt)->relkind == RELKIND_MATVIEW ?
RELKIND_MATVIEW : RELKIND_RELATION,
InvalidOid);
/*
* Let AlterTableCreateToastTable decide if this one
* needs a secondary relation too.
*/
CommandCounterIncrement();
/* parse and validate reloptions for the toast table */
toast_options =
transformRelOptions((Datum)0, ((CreateStmt*)stmt)->options, "toast", validnsps, true, false);
(void)heap_reloptions(RELKIND_TOASTVALUE, toast_options, true);
AlterTableCreateToastTable(rel_oid, toast_options, ((CreateStmt *)stmt)->oldToastNode);
AlterCStoreCreateTables(rel_oid, toast_options, (CreateStmt*)stmt);
AlterDfsCreateTables(rel_oid, toast_options, (CreateStmt*)stmt);
#ifdef ENABLE_MULTIPLE_NODES
Datum reloptions = transformRelOptions(
(Datum)0, ((CreateStmt*)stmt)->options, NULL, validnsps, true, false);
StdRdOptions* std_opt = (StdRdOptions*)heap_reloptions(RELKIND_RELATION, reloptions, true);
if (StdRelOptIsTsStore(std_opt)) {
create_ts_store_tables(rel_oid, toast_options);
}
/* create partition policy if ttl or period defined */
create_part_policy_if_needed((CreateStmt*)stmt, rel_oid);
#endif /* ENABLE_MULTIPLE_NODES */
} else if (IsA(stmt, CreateForeignTableStmt)) {
/* forbid user to set or change inner options */
ForbidOutUsersToSetInnerOptions(((CreateStmt*)stmt)->options);
/* if this is a log ft, check its definition */
check_log_ft_definition((CreateForeignTableStmt*)stmt);
/* Create the table itself */
if (pg_strcasecmp(((CreateForeignTableStmt *)stmt)->servername,
STREAMING_SERVER) == 0) {
/* Create stream */
rel_oid = DefineRelation((CreateStmt*)stmt, RELKIND_STREAM, InvalidOid);
} else {
/* Create foreign table */
rel_oid = DefineRelation((CreateStmt*)stmt, RELKIND_FOREIGN_TABLE, InvalidOid);
}
CreateForeignTable((CreateForeignTableStmt*)stmt, rel_oid);
} else {
if (IsA(stmt, AlterTableStmt))
((AlterTableStmt*)stmt)->fromCreate = true;
/* Recurse for anything else */
ProcessUtility(stmt,
query_string_with_info,
params,
false,
None_Receiver,
#ifdef PGXC
true,
#endif /* PGXC */
NULL);
}
/* Need CCI between commands */
if (lnext(l) != NULL)
CommandCounterIncrement();
}
/* reset */
t_thrd.xact_cxt.inheritFileNode = false;
parse_tree->uuids = NIL;
}
CreateCommand 函数负责处理 CREATE TABLE、CREATE FOREIGN TABLE 等创建表的 SQL 语句。下面简单介绍一下CreateCommand 函数的执行流程:
- 在开始之前,根据宏定义,函数有不同的参数,具体分为 PGXC(PostgreSQL扩展性集群)模式和非 PGXC 模式。在 PGXC 模式下,还有一些额外的变量用于并行 DDL(数据定义语言)执行和集群扩展/缩减。
- 这个函数首先初始化一些变量,包括一些用于 PGXC 模式下的信息,例如集群信息、表空间名、表的持久性等。
- 设置当前会话的状态,以便 DefineRelation() 函数判断是否需要执行 DDL 语句。对于 PGXC 模式,还会设置并行 DDL 的状态。
- 进行解析分析,将原始的 parse_tree 转化为一个列表 stmts,其中包含了各种 DDL 语句。解析分析是数据库执行 DDL 语句的第一步,将原始的语法树转换为可以执行的逻辑语句。
- 如果 stmts 为空,意味着表已经存在,会标记 table_is_exist 为真。这可能会在集群中有一些特殊的处理,具体操作可能会终止或返回。
- 在 PGXC 模式下,根据一些条件判断,选择性地设置 query_string_with_info,可能包含集群信息和UUID等。
- 在 PGXC 模式下,如果当前节点是主协调器且不是从协调器连接的,会根据条件发送远程查询,进行表的创建操作,具体取决于表的临时性质和是否启用并行 DDL。
- 在 PGXC 模式下,如果启用了并行 DDL,会再次进行解析分析,为了在并行 DDL 模式下对每个节点进行处理。
- 进行迭代处理 stmts 列表中的每个语句,根据语句类型分别执行相应的操作:
- 如果是 CreateStmt,调用 DefineRelation 函数定义表,然后根据情况创建相应的关联表(如 TOAST 表、列存储表、分布式表等)。
- 如果是 CreateForeignTableStmt,调用 DefineRelation 函数定义外部表,然后根据情况创建相应的外部表。
- 对于其他类型的语句,进行递归处理。
- 在语句执行之间,增加 CommandCounter,确保在不同语句之间的数据一致性。
- 最后,清理和释放一些资源,包括清空 uuids 列表和重置相关状态。
其中,函数 DefineRelation 是用于创建新表及其元数据的核心函数,它涵盖了与表的物理存储和逻辑结构相关的各种操作,并确保表的定义符合数据库系统的要求。
DefineRelation 函数源码如下:(路径:src/gausskernel/optimizer/commands/tablecmds.cpp)
/* ----------------------------------------------------------------
* DefineRelation
* Creates a new relation.
*
* stmt carries parsetree information from an ordinary CREATE TABLE statement.
* The other arguments are used to extend the behavior for other cases:
* relkind: relkind to assign to the new relation
* ownerId: if not InvalidOid, use this as the new relation's owner.
*
* Note that permissions checks are done against current user regardless of
* ownerId. A nonzero ownerId is used when someone is creating a relation
* "on behalf of" someone else, so we still want to see that the current user
* has permissions to do it.
*
* If successful, returns the OID of the new relation.
* ----------------------------------------------------------------
*/
Oid DefineRelation(CreateStmt* stmt, char relkind, Oid ownerId)
{
char relname[NAMEDATALEN];
Oid namespaceId;
List* schema = stmt->tableElts;
Oid relationId;
Oid tablespaceId;
Relation rel;
TupleDesc descriptor;
List* inheritOids = NIL;
List* old_constraints = NIL;
bool localHasOids = false;
int parentOidCount;
List* rawDefaults = NIL;
List* cookedDefaults = NIL;
List *ceLst = NIL;
Datum reloptions;
ListCell* listptr = NULL;
AttrNumber attnum;
static const char* const validnsps[] = HEAP_RELOPT_NAMESPACES;
Oid ofTypeId;
Node* orientedFrom = NULL;
char* storeChar = ORIENTATION_ROW;
bool timeseries_checked = false;
bool dfsTablespace = false;
bool isInitdbOnDN = false;
HashBucketInfo* bucketinfo = NULL;
DistributionType distType;
/*
* isalter is true, change the owner of the objects as the owner of the
* namespace, if the owner of the namespce has the same name as the namescpe
*/
bool isalter = false;
bool hashbucket = false;
bool relisshared = u_sess->attr.attr_common.IsInplaceUpgrade && u_sess->upg_cxt.new_catalog_isshared;
errno_t rc;
/*
* Truncate relname to appropriate length (probably a waste of time, as
* parser should have done this already).
*/
rc = strncpy_s(relname, NAMEDATALEN, stmt->relation->relname, NAMEDATALEN - 1);
securec_check(rc, "", "");
if (stmt->relation->relpersistence == RELPERSISTENCE_UNLOGGED && STMT_RETRY_ENABLED)
stmt->relation->relpersistence = RELPERSISTENCE_PERMANENT;
/* During grayscale upgrade, forbid creating LIST/RANGE tables if workingVersionNum is too low. */
if (stmt->distributeby != NULL) {
distType = stmt->distributeby->disttype;
if ((distType == DISTTYPE_RANGE || distType == DISTTYPE_LIST) &&
t_thrd.proc->workingVersionNum < RANGE_LIST_DISTRIBUTION_VERSION_NUM) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg(
"Working Version Num less than %u does not support LIST/RANGE distributed tables.",
RANGE_LIST_DISTRIBUTION_VERSION_NUM)));
}
}
/*
* Check consistency of arguments
*/
if (stmt->oncommit != ONCOMMIT_NOOP
&& !(stmt->relation->relpersistence == RELPERSISTENCE_TEMP
|| stmt->relation->relpersistence == RELPERSISTENCE_GLOBAL_TEMP)) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("ON COMMIT can only be used on temporary tables")));
}
//@Temp Table. We do not support on commit drop right now.
if ((stmt->relation->relpersistence == RELPERSISTENCE_TEMP
|| stmt->relation->relpersistence == RELPERSISTENCE_GLOBAL_TEMP)
&& stmt->oncommit == ONCOMMIT_DROP) {
ereport(
ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg(
"ON COMMIT only support PRESERVE ROWS or DELETE ROWS option")));
}
if (stmt->constraints != NIL && relkind == RELKIND_FOREIGN_TABLE) {
ereport(ERROR, (errcode(ERRCODE_WRONG_OBJECT_TYPE), errmsg("constraints on foreign tables are not supported")));
}
if (stmt->constraints != NIL && relkind == RELKIND_STREAM) {
ereport(ERROR, (errcode(ERRCODE_WRONG_OBJECT_TYPE), errmsg("constraints on streams are not supported")));
}
/*
* For foreign table ROUNDROBIN distribution is a built-in support.
*/
if (IsA(stmt, CreateForeignTableStmt) &&
(IsSpecifiedFDW(((CreateForeignTableStmt*)stmt)->servername, DIST_FDW) ||
IsSpecifiedFDW(((CreateForeignTableStmt*)stmt)->servername, LOG_FDW) ||
IsSpecifiedFDW(((CreateForeignTableStmt*)stmt)->servername, GC_FDW)) &&
(IS_PGXC_COORDINATOR || (isRestoreMode && stmt->subcluster)) && !stmt->distributeby) {
stmt->distributeby = makeNode(DistributeBy);
stmt->distributeby->disttype = DISTTYPE_ROUNDROBIN;
stmt->distributeby->colname = NULL;
}
/*
* Look up the namespace in which we are supposed to create the relation,
* check we have permission to create there, lock it against concurrent
* drop, and mark stmt->relation as RELPERSISTENCE_TEMP if a temporary
* namespace is selected.
*/
namespaceId = RangeVarGetAndCheckCreationNamespace(stmt->relation, NoLock, NULL);
if (u_sess->attr.attr_sql.enforce_a_behavior) {
/* Identify user ID that will own the table
*
* change the owner of the objects as the owner of the namespace
* if the owner of the namespce has the same name as the namescpe
* note: the object must be of the ordinary table, sequence, view or
* composite type
*/
if (!OidIsValid(ownerId) && (relkind == RELKIND_RELATION || relkind == RELKIND_SEQUENCE ||
relkind == RELKIND_VIEW || relkind == RELKIND_COMPOSITE_TYPE
|| relkind == RELKIND_CONTQUERY))
ownerId = GetUserIdFromNspId(namespaceId);
if (!OidIsValid(ownerId))
ownerId = GetUserId();
else if (ownerId != GetUserId())
isalter = true;
if (isalter) {
/* Check namespace permissions. */
AclResult aclresult;
aclresult = pg_namespace_aclcheck(namespaceId, ownerId, ACL_CREATE);
if (aclresult != ACLCHECK_OK)
aclcheck_error(aclresult, ACL_KIND_NAMESPACE, get_namespace_name(namespaceId));
}
}
/*
* Security check: disallow creating temp tables from security-restricted
* code. This is needed because calling code might not expect untrusted
* tables to appear in pg_temp at the front of its search path.
*/
if ((stmt->relation->relpersistence == RELPERSISTENCE_TEMP
|| stmt->relation->relpersistence == RELPERSISTENCE_GLOBAL_TEMP)
&& InSecurityRestrictedOperation()) {
ereport(ERROR,
(errcode(ERRCODE_INSUFFICIENT_PRIVILEGE),
errmsg("cannot create temporary table within security-restricted operation")));
}
/*
* Select tablespace to use. If not specified, use default tablespace
* (which may in turn default to database's default).
*/
if (stmt->tablespacename) {
tablespaceId = get_tablespace_oid(stmt->tablespacename, false);
} else {
tablespaceId = GetDefaultTablespace(stmt->relation->relpersistence);
/* note InvalidOid is OK in this case */
}
dfsTablespace = IsSpecifiedTblspc(tablespaceId, FILESYSTEM_HDFS);
if (dfsTablespace) {
FEATURE_NOT_PUBLIC_ERROR("HDFS is not yet supported.");
}
if (dfsTablespace && is_feature_disabled(DATA_STORAGE_FORMAT)) {
ereport(ERROR, (errcode(ERRCODE_FEATURE_NOT_SUPPORTED), errmsg("Unsupport the dfs table in this version.")));
}
PreCheckCreatedObj(stmt, dfsTablespace, relkind);
/* Check permissions except when using database's default */
if (OidIsValid(tablespaceId) && tablespaceId != u_sess->proc_cxt.MyDatabaseTableSpace) {
AclResult aclresult;
aclresult = pg_tablespace_aclcheck(tablespaceId, GetUserId(), ACL_CREATE);
if (aclresult != ACLCHECK_OK)
aclcheck_error(aclresult, ACL_KIND_TABLESPACE, get_tablespace_name(tablespaceId));
// view is not related to tablespace, so no need to check permissions
if (isalter && relkind != RELKIND_VIEW && relkind != RELKIND_CONTQUERY) {
aclresult = pg_tablespace_aclcheck(tablespaceId, ownerId, ACL_CREATE);
if (aclresult != ACLCHECK_OK)
aclcheck_error(aclresult, ACL_KIND_TABLESPACE, get_tablespace_name(tablespaceId));
}
}
/* In all cases disallow placing user relations in pg_global */
if (!relisshared && tablespaceId == GLOBALTABLESPACE_OID)
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE),
errmsg("only shared relations can be placed in pg_global tablespace")));
/* Identify user ID that will own the table */
if (!OidIsValid(ownerId))
ownerId = GetUserId();
/* Add default options for relation if need. */
if (!dfsTablespace) {
if (!u_sess->attr.attr_common.IsInplaceUpgrade) {
stmt->options = AddDefaultOptionsIfNeed(stmt->options, relkind, stmt->row_compress);
}
} else {
checkObjectCreatedinHDFSTblspc(stmt, relkind);
}
/* Only support one partial cluster key for dfs table. */
if (stmt->clusterKeys && list_length(stmt->clusterKeys) > 1) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("Only support one partial cluster key for dfs/cstore table.")));
}
/* Check tablespace's permissions for partition */
if (stmt->partTableState) {
check_part_tbl_space(stmt, ownerId, dfsTablespace);
}
/*
* Parse and validate reloptions, if any.
*/
/* global temp table */
OnCommitAction oncommitAction = GttOncommitOption(stmt->options);
if (stmt->relation->relpersistence == RELPERSISTENCE_GLOBAL_TEMP
&& relkind == RELKIND_RELATION) {
if (oncommitAction != ONCOMMIT_NOOP && stmt->oncommit == ONCOMMIT_NOOP) {
stmt->oncommit = oncommitAction;
} else {
if (oncommitAction != ONCOMMIT_NOOP && stmt->oncommit != ONCOMMIT_NOOP) {
stmt->options = RemoveRelOption(stmt->options, "on_commit_delete_rows", NULL);
}
DefElem *opt = makeNode(DefElem);
opt->type = T_DefElem;
opt->defnamespace = NULL;
opt->defname = "on_commit_delete_rows";
opt->defaction = DEFELEM_UNSPEC;
/* use reloptions to remember on commit clause */
if (stmt->oncommit == ONCOMMIT_DELETE_ROWS) {
opt->arg = reinterpret_cast<Node *>(makeString("true"));
} else if (stmt->oncommit == ONCOMMIT_PRESERVE_ROWS) {
opt->arg = reinterpret_cast<Node *>(makeString("false"));
} else if (stmt->oncommit == ONCOMMIT_NOOP) {
opt->arg = reinterpret_cast<Node *>(makeString("false"));
} else {
elog(ERROR, "global temp table not support on commit drop clause");
}
stmt->options = lappend(stmt->options, opt);
}
} else if (oncommitAction != ONCOMMIT_NOOP) {
elog(ERROR, "The parameter on_commit_delete_rows is exclusive to the global temp table, which cannot be "
"specified by a regular table");
}
reloptions = transformRelOptions((Datum)0, stmt->options, NULL, validnsps, true, false);
orientedFrom = (Node*)makeString(ORIENTATION_ROW); /* default is ORIENTATION_ROW */
StdRdOptions* std_opt = (StdRdOptions*)heap_reloptions(relkind, reloptions, true);
if (std_opt != NULL) {
hashbucket = std_opt->hashbucket;
if (hashbucket == true && t_thrd.proc->workingVersionNum < 92063) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("hash bucket table not supported in current version!")));
}
if (pg_strcasecmp(ORIENTATION_COLUMN, StdRdOptionsGetStringData(std_opt, orientation, ORIENTATION_ROW)) == 0) {
orientedFrom = (Node*)makeString(ORIENTATION_COLUMN);
storeChar = ORIENTATION_COLUMN;
} else if (pg_strcasecmp(ORIENTATION_ORC,
StdRdOptionsGetStringData(std_opt, orientation, ORIENTATION_ROW)) == 0) {
/*
* Don't allow "create DFS table" to run inside a transaction block.
*
* "DfsDDLIsTopLevelXact" is set in "case T_CreateStmt" of
* standard_ProcessUtility()
*
* exception: allow "CREATE DFS TABLE" operation in transaction block
* during redis a table.
*/
if (IS_PGXC_COORDINATOR && !IsConnFromCoord() && u_sess->attr.attr_sql.enable_cluster_resize == false)
PreventTransactionChain(u_sess->exec_cxt.DfsDDLIsTopLevelXact, "CREATE DFS TABLE");
orientedFrom = (Node*)makeString(ORIENTATION_ORC);
storeChar = ORIENTATION_COLUMN;
} else if(0 == pg_strcasecmp(ORIENTATION_TIMESERIES,
StdRdOptionsGetStringData(std_opt, orientation, ORIENTATION_ROW))) {
orientedFrom = (Node *)makeString(ORIENTATION_TIMESERIES);
storeChar = ORIENTATION_TIMESERIES;
/* for ts table redistribute, timeseries table redis_ is reserved */
if (!u_sess->attr.attr_sql.enable_cluster_resize) {
if (strncmp(relname, "redis_", 6) == 0) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("Invalid table name prefix redis_, reserved in redis mode.")));
}
}
/*
* Check the kvtype parameter legality for timeseries storage method.
* If all the kvtype exclude tstime are same, change the orientation to row or column explicitly.
*/
timeseries_checked = validate_timeseries(&stmt, &reloptions, &storeChar, &orientedFrom);
std_opt = (StdRdOptions*)heap_reloptions(relkind, reloptions, true);
}
// Set kvtype to ATT_KV_UNDEFINED in row-oriented or column-oriented table.
if (0 != pg_strcasecmp(storeChar, ORIENTATION_TIMESERIES)) {
clear_kvtype_row_column(stmt);
}
/*
* Because we also support create partition policy for non timeseries table, we should check parameter
* ttl and period if it contains
*/
if (timeseries_checked ||
0 != pg_strcasecmp(TIME_UNDEFINED, StdRdOptionsGetStringData(std_opt, ttl, TIME_UNDEFINED)) ||
0 != pg_strcasecmp(TIME_UNDEFINED, StdRdOptionsGetStringData(std_opt, period, TIME_UNDEFINED))) {
partition_policy_check(stmt, std_opt, timeseries_checked);
if (stmt->partTableState != NULL) {
check_part_tbl_space(stmt, ownerId, dfsTablespace);
checkPartitionSynax(stmt);
}
}
if (IS_SINGLE_NODE && stmt->partTableState != NULL) {
if (stmt->partTableState->rowMovement != ROWMOVEMENT_DISABLE)
stmt->partTableState->rowMovement = ROWMOVEMENT_ENABLE;
}
if (0 == pg_strcasecmp(storeChar, ORIENTATION_COLUMN)) {
CheckCStoreUnsupportedFeature(stmt);
CheckCStoreRelOption(std_opt);
ForbidToSetOptionsForColTbl(stmt->options);
if (stmt->partTableState) {
if (stmt->partTableState->rowMovement == ROWMOVEMENT_DISABLE) {
ereport(NOTICE,
(errmsg("disable row movement is invalid for column stored tables."
" They always enable row movement between partitions.")));
}
/* always enable rowmovement for column stored tables */
stmt->partTableState->rowMovement = ROWMOVEMENT_ENABLE;
}
} else if (0 == pg_strcasecmp(storeChar, ORIENTATION_TIMESERIES)) {
/* check both support coloumn store and row store */
CheckCStoreUnsupportedFeature(stmt);
CheckCStoreRelOption(std_opt);
if (stmt->partTableState) {
if (stmt->partTableState->rowMovement == ROWMOVEMENT_DISABLE)
ereport(NOTICE,
(errmsg("disable row movement is invalid for timeseries stored tables."
" They always enable row movement between partitions.")));
/* always enable rowmovement for column stored tables */
stmt->partTableState->rowMovement = ROWMOVEMENT_ENABLE;
}
if (relkind == RELKIND_RELATION) {
/* only care heap relation. ignore foreign table and index relation */
forbid_to_set_options_for_timeseries_tbl(stmt->options);
}
/* construct distribute keys using tstag if not specified */
if (stmt->distributeby == NULL) {
ListCell* cell = NULL;
DistributeBy* newnode = makeNode(DistributeBy);
List* colnames = NIL;
newnode->disttype = DISTTYPE_HASH;
foreach (cell, schema) {
ColumnDef* colDef = (ColumnDef*)lfirst(cell);
if (colDef->kvtype == ATT_KV_TAG && IsTypeDistributable(colDef->typname->typeOid)) {
colnames = lappend(colnames, makeString(colDef->colname));
}
}
if (list_length(colnames) == 0) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("No column can be used as distribution column.")));
}
newnode->colname = colnames;
stmt->distributeby = newnode;
/* if specified hidetag, add a hidden column as distribution column */
} else if (stmt->distributeby->disttype == DISTTYPE_HIDETAG &&
stmt->distributeby->colname == NULL) {
bool has_distcol = false;
ListCell* cell;
foreach (cell, schema) {
ColumnDef* colDef = (ColumnDef*)lfirst(cell);
if (colDef->kvtype == ATT_KV_TAG && IsTypeDistributable(colDef->typname->typeOid)) {
has_distcol = true;
}
}
if (!has_distcol) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("No column can be used as distribution column.")));
}
ColumnDef* colDef = makeColumnDef(TS_PSEUDO_DIST_COLUMN, "char");
colDef->kvtype = ATT_KV_HIDE;
stmt->tableElts = lappend(stmt->tableElts, colDef);
/* still use hash logic later */
DistributeBy* distnode = stmt->distributeby;
distnode->disttype = DISTTYPE_HASH;
distnode->colname = lappend(distnode->colname, makeString(colDef->colname));
ereport(LOG, (errmodule(MOD_TIMESERIES), errmsg("use implicit distribution column method.")));
}
} else {
if (relkind == RELKIND_RELATION) {
/* only care heap relation. ignore foreign table and index relation */
ForbidToSetOptionsForRowTbl(stmt->options);
}
}
pfree_ext(std_opt);
}
if (pg_strcasecmp(storeChar, ORIENTATION_ROW) == 0) {
RowTblCheckCompressionOption(stmt->options);
}
if (stmt->ofTypename) {
AclResult aclresult;
ofTypeId = typenameTypeId(NULL, stmt->ofTypename);
aclresult = pg_type_aclcheck(ofTypeId, GetUserId(), ACL_USAGE);
if (aclresult != ACLCHECK_OK)
aclcheck_error_type(aclresult, ofTypeId);
if (isalter) {
ofTypeId = typenameTypeId(NULL, stmt->ofTypename);
aclresult = pg_type_aclcheck(ofTypeId, ownerId, ACL_USAGE);
if (aclresult != ACLCHECK_OK)
aclcheck_error_type(aclresult, ofTypeId);
}
} else
ofTypeId = InvalidOid;
/*
* Look up inheritance ancestors and generate relation schema, including
* inherited attributes.
*/
schema = MergeAttributes(
schema, stmt->inhRelations, stmt->relation->relpersistence, &inheritOids, &old_constraints, &parentOidCount);
/*
* Create a tuple descriptor from the relation schema. Note that this
* deals with column names, types, and NOT NULL constraints, but not
* default values or CHECK constraints; we handle those below.
*/
if (relkind == RELKIND_COMPOSITE_TYPE)
descriptor = BuildDescForRelation(schema, orientedFrom, relkind);
else
descriptor = BuildDescForRelation(schema, orientedFrom);
/* Must specify at least one column when creating a table. */
if (descriptor->natts == 0 && relkind != RELKIND_COMPOSITE_TYPE) {
ereport(ERROR, (errcode(ERRCODE_FEATURE_NOT_SUPPORTED), errmsg("must have at least one column")));
}
if (stmt->partTableState) {
List* pos = NIL;
/* get partitionkey's position */
pos = GetPartitionkeyPos(stmt->partTableState->partitionKey, schema);
/* check partitionkey's datatype */
if (stmt->partTableState->partitionStrategy == PART_STRATEGY_VALUE) {
CheckValuePartitionKeyType(descriptor->attrs, pos);
} else if (stmt->partTableState->partitionStrategy == PART_STRATEGY_INTERVAL) {
CheckIntervalPartitionKeyType(descriptor->attrs, pos);
CheckIntervalValue(descriptor->attrs, pos, stmt->partTableState->intervalPartDef);
} else if (stmt->partTableState->partitionStrategy == PART_STRATEGY_RANGE) {
CheckRangePartitionKeyType(descriptor->attrs, pos);
} else if (stmt->partTableState->partitionStrategy == PART_STRATEGY_LIST) {
CheckListPartitionKeyType(descriptor->attrs, pos);
} else if (stmt->partTableState->partitionStrategy == PART_STRATEGY_HASH) {
CheckHashPartitionKeyType(descriptor->attrs, pos);
} else {
list_free_ext(pos);
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED), errmsg("Unsupported partition table!")));
}
/*
* Check partitionkey's value for none value-partition table as for value
* partition table, partition value is known until data get loaded.
*/
if (stmt->partTableState->partitionStrategy != PART_STRATEGY_VALUE &&
stmt->partTableState->partitionStrategy != PART_STRATEGY_HASH &&
stmt->partTableState->partitionStrategy != PART_STRATEGY_LIST)
ComparePartitionValue(pos, descriptor->attrs, stmt->partTableState->partitionList);
else if (stmt->partTableState->partitionStrategy == PART_STRATEGY_LIST)
CompareListValue(pos, descriptor->attrs, stmt->partTableState);
list_free_ext(pos);
}
localHasOids = interpretOidsOption(stmt->options);
descriptor->tdhasoid = (localHasOids || parentOidCount > 0);
if ((pg_strcasecmp(storeChar, ORIENTATION_COLUMN) == 0 || pg_strcasecmp(storeChar, ORIENTATION_TIMESERIES) == 0) &&
localHasOids) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("Local OID column not supported in column/timeseries store tables.")));
}
bool is_gc_fdw = false;
if (!isRestoreMode && IsA(stmt, CreateForeignTableStmt) &&
(IsSpecifiedFDW(((CreateForeignTableStmt*)stmt)->servername, GC_FDW))) {
is_gc_fdw = true;
}
/*
* Find columns with default values and prepare for insertion of the
* defaults. Pre-cooked (that is, inherited) defaults go into a list of
* CookedConstraint structs that we'll pass to heap_create_with_catalog,
* while raw defaults go into a list of RawColumnDefault structs that will
* be processed by AddRelationNewConstraints. (We can't deal with raw
* expressions until we can do transformExpr.)
*
* We can set the atthasdef flags now in the tuple descriptor; this just
* saves StoreAttrDefault from having to do an immediate update of the
* pg_attribute rows.
*/
rawDefaults = NIL;
cookedDefaults = NIL;
attnum = 0;
foreach (listptr, schema) {
ColumnDef* colDef = (ColumnDef*)lfirst(listptr);
attnum++;
if (is_gc_fdw) {
if (colDef->constraints != NULL || colDef->is_not_null == true) {
ereport(ERROR,
(errcode(ERRCODE_WRONG_OBJECT_TYPE),
errmsg("column constraint on postgres foreign tables are not supported")));
}
Type ctype = typenameType(NULL, colDef->typname, NULL);
if (ctype) {
Form_pg_type typtup = (Form_pg_type)GETSTRUCT(ctype);
if (typtup->typrelid > 0) {
ereport(ERROR,
(errcode(ERRCODE_WRONG_OBJECT_TYPE),
errmsg("relation type column on postgres foreign tables are not supported")));
}
ReleaseSysCache(ctype);
}
}
if (colDef->raw_default != NULL) {
RawColumnDefault* rawEnt = NULL;
if (relkind == RELKIND_FOREIGN_TABLE) {
if (!(IsA(stmt, CreateForeignTableStmt) && (
#ifdef ENABLE_MOT
isMOTTableFromSrvName(((CreateForeignTableStmt*)stmt)->servername) ||
#endif
isPostgresFDWFromSrvName(((CreateForeignTableStmt*)stmt)->servername))))
ereport(ERROR,
(errcode(ERRCODE_WRONG_OBJECT_TYPE),
errmsg("default values on foreign tables are not supported")));
}
if (relkind == RELKIND_STREAM) {
ereport(ERROR,
(errcode(ERRCODE_WRONG_OBJECT_TYPE), errmsg("default values on streams are not supported")));
}
Assert(colDef->cooked_default == NULL);
rawEnt = (RawColumnDefault*)palloc(sizeof(RawColumnDefault));
rawEnt->attnum = attnum;
rawEnt->raw_default = colDef->raw_default;
rawDefaults = lappend(rawDefaults, rawEnt);
descriptor->attrs[attnum - 1]->atthasdef = true;
} else if (colDef->cooked_default != NULL) {
CookedConstraint* cooked = NULL;
cooked = (CookedConstraint*)palloc(sizeof(CookedConstraint));
cooked->contype = CONSTR_DEFAULT;
cooked->name = NULL;
cooked->attnum = attnum;
cooked->expr = colDef->cooked_default;
cooked->skip_validation = false;
cooked->is_local = true; /* not used for defaults */
cooked->inhcount = 0; /* ditto */
cooked->is_no_inherit = false;
cookedDefaults = lappend(cookedDefaults, cooked);
descriptor->attrs[attnum - 1]->atthasdef = true;
}
if (colDef->clientLogicColumnRef != NULL) {
CeHeapInfo *ceHeapInfo = NULL;
ceHeapInfo = (CeHeapInfo*) palloc(sizeof(CeHeapInfo));
ceHeapInfo->attnum = attnum;
set_column_encryption(colDef, ceHeapInfo);
ceLst = lappend (ceLst, ceHeapInfo);
}
}
/*Get hash partition key based on relation distribution info*/
bool createbucket = false;
/* restore mode */
if (isRestoreMode) {
/* table need hash partition */
if (hashbucket == true) {
/* here is dn */
if (u_sess->storage_cxt.dumpHashbucketIds != NULL) {
Assert(stmt->distributeby == NULL);
createbucket = true;
} else {
if (unlikely(stmt->distributeby == NULL)) {
ereport(ERROR,
(errcode(ERRCODE_UNEXPECTED_NULL_VALUE), errmsg("distributeby is NULL.")));
}
}
bucketinfo = GetRelationBucketInfo(stmt->distributeby, descriptor, &createbucket, InvalidOid, true);
Assert((createbucket == true && bucketinfo->bucketlist != NULL && bucketinfo->bucketcol != NULL) ||
(createbucket == false && bucketinfo->bucketlist == NULL && bucketinfo->bucketcol != NULL));
}
} else {
/* here is normal mode */
/* check if the table can be hash partition */
if (!IS_SINGLE_NODE && !IsInitdb && (relkind == RELKIND_RELATION) && !IsSystemNamespace(namespaceId) &&
!IsCStoreNamespace(namespaceId) && (0 == pg_strcasecmp(storeChar, ORIENTATION_ROW)) &&
(stmt->relation->relpersistence == RELPERSISTENCE_PERMANENT)) {
if (hashbucket == true || u_sess->attr.attr_storage.enable_hashbucket) {
if (IS_PGXC_DATANODE) {
createbucket = true;
}
bucketinfo = GetRelationBucketInfo(stmt->distributeby, descriptor,
&createbucket, stmt->oldBucket, hashbucket);
Assert((bucketinfo == NULL && u_sess->attr.attr_storage.enable_hashbucket) ||
(createbucket == true && bucketinfo->bucketlist != NULL && bucketinfo->bucketcol != NULL) ||
(createbucket == false && bucketinfo->bucketlist == NULL && bucketinfo->bucketcol != NULL));
}
} else if (hashbucket == true) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("The table %s do not support hash bucket", stmt->relation->relname)));
}
}
/*
* Create the relation. Inherited defaults and constraints are passed in
* for immediate handling --- since they don't need parsing, they can be
* stored immediately.
*/
relationId = heap_create_with_catalog(relname,
namespaceId,
tablespaceId,
InvalidOid,
InvalidOid,
ofTypeId,
ownerId,
descriptor,
list_concat(cookedDefaults, old_constraints),
relkind,
stmt->relation->relpersistence,
relisshared,
relisshared,
localHasOids,
parentOidCount,
stmt->oncommit,
reloptions,
true,
(g_instance.attr.attr_common.allowSystemTableMods || u_sess->attr.attr_common.IsInplaceUpgrade),
stmt->partTableState,
stmt->row_compress,
stmt->oldNode,
bucketinfo,
true,
ceLst);
if (bucketinfo != NULL) {
pfree_ext(bucketinfo->bucketcol);
pfree_ext(bucketinfo->bucketlist);
pfree_ext(bucketinfo);
}
/* Store inheritance information for new rel. */
StoreCatalogInheritance(relationId, inheritOids);
/*
* We must bump the command counter to make the newly-created relation
* tuple visible for opening.
*/
CommandCounterIncrement();
#ifdef PGXC
/*
* Add to pgxc_class.
* we need to do this after CommandCounterIncrement
* Distribution info is to be added under the following conditions:
* 1. The create table command is being run on a coordinator
* 2. The create table command is being run in restore mode and
* the statement contains distribute by clause.
* While adding a new datanode to the cluster an existing dump
* that was taken from a datanode is used, and
* While adding a new coordinator to the cluster an exiting dump
* that was taken from a coordinator is used.
* The dump taken from a datanode does NOT contain any DISTRIBUTE BY
* clause. This fact is used here to make sure that when the
* DISTRIBUTE BY clause is missing in the statemnet the system
* should not try to find out the node list itself.
* 3. When the sum of shmemNumDataNodes and shmemNumCoords equals to one,
* the create table command is executed on datanode.In this case, we
* do not write created table info in pgxc_class.
*/
if ((*t_thrd.pgxc_cxt.shmemNumDataNodes + *t_thrd.pgxc_cxt.shmemNumCoords) == 1)
isInitdbOnDN = true;
if ((!u_sess->attr.attr_common.IsInplaceUpgrade || !IsSystemNamespace(namespaceId)) &&
(IS_PGXC_COORDINATOR || (isRestoreMode && stmt->distributeby != NULL && !isInitdbOnDN)) &&
(relkind == RELKIND_RELATION || relkind == RELKIND_MATVIEW ||
(relkind == RELKIND_STREAM && stmt->distributeby != NULL) ||
#ifdef ENABLE_MOT
(relkind == RELKIND_FOREIGN_TABLE && (stmt->distributeby != NULL ||
(IsA(stmt, CreateForeignTableStmt) &&
isMOTTableFromSrvName(((CreateForeignTableStmt*)stmt)->servername)))))) {
#else
(relkind == RELKIND_FOREIGN_TABLE && stmt->distributeby != NULL))) {
#endif
char* logic_cluster_name = NULL;
PGXCSubCluster* subcluster = stmt->subcluster;
bool isinstallationgroup = (dfsTablespace || relkind == RELKIND_FOREIGN_TABLE
|| relkind == RELKIND_STREAM);
if (in_logic_cluster()) {
isinstallationgroup = false;
if (subcluster == NULL) {
logic_cluster_name = PgxcGroupGetCurrentLogicCluster();
if (logic_cluster_name != NULL) {
subcluster = makeNode(PGXCSubCluster);
subcluster->clustertype = SUBCLUSTER_GROUP;
subcluster->members = list_make1(makeString(logic_cluster_name));
}
}
}
/* assemble referenceoid for slice reference table creation */
FetchSliceReftableOid(stmt, namespaceId);
AddRelationDistribution(
relname, relationId, stmt->distributeby, subcluster, inheritOids, descriptor, isinstallationgroup);
if (logic_cluster_name != NULL && subcluster != NULL) {
list_free_deep(subcluster->members);
pfree_ext(subcluster);
pfree_ext(logic_cluster_name);
}
CommandCounterIncrement();
/* Make sure locator info gets rebuilt */
RelationCacheInvalidateEntry(relationId);
}
/* If no Datanodes defined, do not create foreign table */
if (IS_PGXC_COORDINATOR && (relkind == RELKIND_FOREIGN_TABLE || relkind == RELKIND_STREAM)
&& u_sess->pgxc_cxt.NumDataNodes == 0) {
ereport(ERROR, (errcode(ERRCODE_UNDEFINED_OBJECT), errmsg("No Datanode defined in cluster")));
}
#endif
/*
* Open the new relation and acquire exclusive lock on it. This isn't
* really necessary for locking out other backends (since they can't see
* the new rel anyway until we commit), but it keeps the lock manager from
* complaining about deadlock risks.
*/
rel = relation_open(relationId, AccessExclusiveLock);
/*
* Now add any newly specified column default values and CHECK constraints
* to the new relation. These are passed to us in the form of raw
* parsetrees; we need to transform them to executable expression trees
* before they can be added. The most convenient way to do that is to
* apply the parser's transformExpr routine, but transformExpr doesn't
* work unless we have a pre-existing relation. So, the transformation has
* to be postponed to this final step of CREATE TABLE.
*/
if (rawDefaults != NULL || stmt->constraints != NULL) {
List *tmp = AddRelationNewConstraints(rel, rawDefaults, stmt->constraints, true, true);
list_free_ext(tmp);
}
/*
* Now add any cluter key constraint for relation if has.
*/
if (stmt->clusterKeys)
AddRelClusterConstraints(rel, stmt->clusterKeys);
/*
* Clean up. We keep lock on new relation (although it shouldn't be
* visible to anyone else anyway, until commit).
*/
relation_close(rel, NoLock);
list_free_ext(rawDefaults);
list_free_ext(ceLst);
return relationId;
}
可以看到 DefineRelation 函数非常的长,没关系,我们只看我们需要的部分就可以啦。
首先,来看一下 heap_reloptions 函数, heap_reloptions 函数用于获取表的存储选项,它需要传入表的类型 relkind(如 RELKIND_RELATION 表示普通关系表,RELKIND_FOREIGN_TABLE 表示外部表等)以及 reloptions,它是一个存储选项列表。这些选项可以包括各种关于表的存储细节的信息。
heap_reloptions 函数源码如下:(路径:src/gausskernel/storage/access/common/reloptions.cpp)
/*
* 解析堆、视图和 TOAST 表的选项。
*/
bytea *heap_reloptions(char relkind, Datum reloptions, bool validate)
{
StdRdOptions *rdopts = NULL;
// 根据关系类型选择相应的选项解析
switch (relkind) {
case RELKIND_TOASTVALUE:
// 对于 TOAST 表,使用默认选项解析,类型为 RELOPT_KIND_TOAST
rdopts = (StdRdOptions *)default_reloptions(reloptions, validate, RELOPT_KIND_TOAST);
if (rdopts != NULL) {
/* 调整仅适用于 TOAST 关系的默认参数 */
rdopts->fillfactor = 100;
rdopts->autovacuum.analyze_threshold = -1;
rdopts->autovacuum.analyze_scale_factor = -1;
}
return (bytea *)rdopts;
case RELKIND_RELATION:
// 对于堆关系,使用默认选项解析,类型为 RELOPT_KIND_HEAP
return default_reloptions(reloptions, validate, RELOPT_KIND_HEAP);
case RELKIND_VIEW:
case RELKIND_CONTQUERY:
case RELKIND_MATVIEW:
// 对于视图、连续查询和物化视图,使用默认选项解析,类型为 RELOPT_KIND_VIEW
return default_reloptions(reloptions, validate, RELOPT_KIND_VIEW);
default:
/* 不支持其他关系类型 */
return NULL;
}
}
其中,RELKIND_TOASTVALUE、RELKIND_RELATION、RELKIND_VIEW、RELKIND_CONTQUERY和RELKIND_MATVIEW分别代表不同类型的数据库关系,表示以下含义:
| 数据库关系类型 | 含义 |
|---|---|
| RELKIND_TOASTVALUE | 用于存储大对象(Large Object,如大文本或大二进制数据)的分片数据。这些分片数据通常是对原始数据进行分段存储,以便在需要时进行透明的读取和管理。 |
| RELKIND_RELATION | 这是普通的堆表(Heap Table),也就是一般的数据表。它用于存储实际的行数据,以及与之关联的各种列信息。 |
| RELKIND_VIEW | 这是一个视图(View),它是一个虚拟的表,由查询定义而来。视图不存储实际的数据,而是提供对其他关系数据的逻辑视图。 |
| RELKIND_CONTQUERY | 这是一种持续查询(Continuous Query),用于处理流数据(Stream Data)。持续查询关系允许用户定义一种查询,它可以随着新数据的到达而动态更新结果。 |
| RELKIND_MATVIEW | 这是物化视图(Materialized View),也是一种虚拟的表,但是与普通视图不同,物化视图会实际存储计算结果,以提高查询性能。 |
default_reloptions 函数的作用是获取一个指向表的默认关系选项的指针,以便后续的处理和使用。总而言之,heap_reloptions 函数的作用是提取存储信息,对表的 reloptions 进行提取,存储到 StdRdOptions 结构体中。
以案例中的 SQL 语句为例:
openGauss=# CREATE TABLE customer_test2
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
)
WITH (ORIENTATION = COLUMN);
调试信息如下:

接着再来分析如下判断条件:
if (pg_strcasecmp(ORIENTATION_COLUMN, StdRdOptionsGetStringData(std_opt, orientation, ORIENTATION_ROW)) == 0) {
orientedFrom = (Node*)makeString(ORIENTATION_COLUMN);
storeChar = ORIENTATION_COLUMN;
}
首先,它使用
StdRdOptionsGetStringData(std_opt, orientation, ORIENTATION_ROW)从存储选项中获取方向信息,然后通过pg_strcasecmp函数将获取到的方向信息与字符串常量ORIENTATION_COLUMN进行不区分大小写的比较。
如果比较的结果为 0,表示存储选项中的方向信息与ORIENTATION_COLUMN相匹配,那么就会执行以下操作:
- 将变量
orientedFrom设置为一个表示列存储方向的节点,使用makeString(ORIENTATION_COLUMN)创建这个节点。- 将变量
storeChar设置为字符串常量ORIENTATION_COLUMN,以便后续的操作可以使用这个标识来表示方向信息。换句话说,这段代码的作用是检查存储选项中的方向信息是否为列存储,如果是,则设置相应的变量来表示这个信息。
由实际案例的调试信息可以看到方向信息是列存储
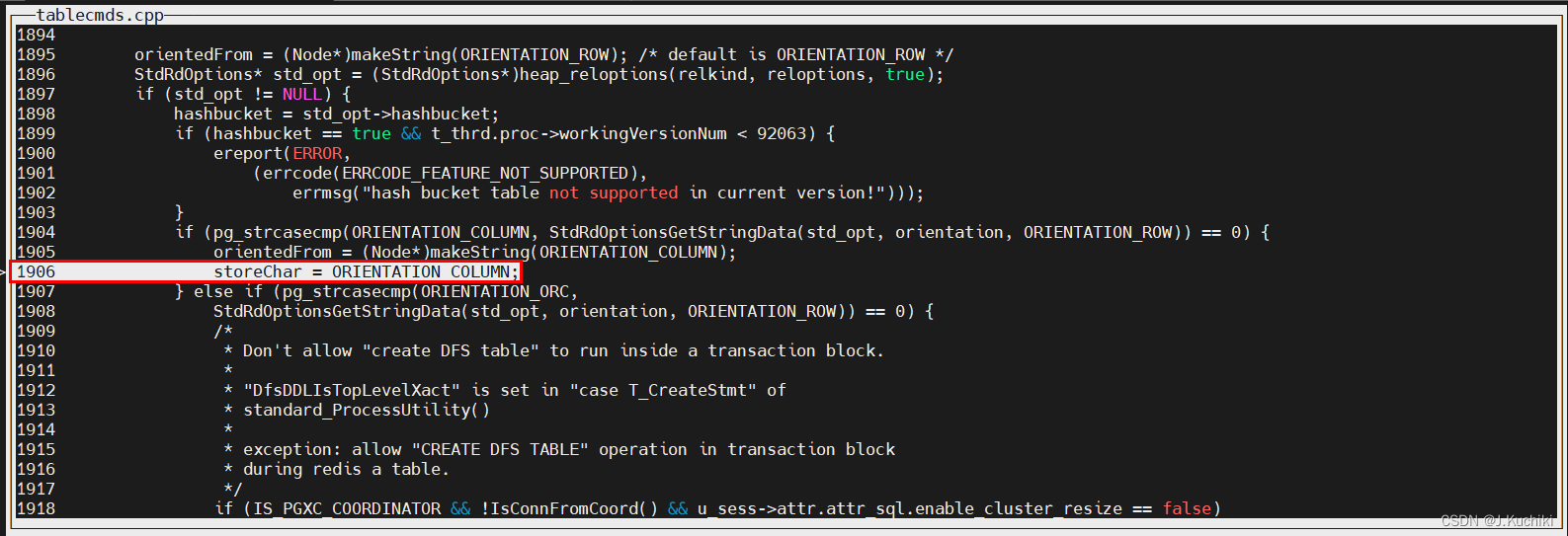
接着再来分析如下判断条件:
// Set kvtype to ATT_KV_UNDEFINED in row-oriented or column-oriented table.
if (0 != pg_strcasecmp(storeChar, ORIENTATION_TIMESERIES)) {
clear_kvtype_row_column(stmt);
}
这个判断是在检查存储选项中的方向信息是否为 "TIMESERIES",如果不是的话,就执行一个函数 clear_kvtype_row_column(stmt) 来设置表的 kvtype 属性为 ATT_KV_UNDEFINED。
换句话说,当存储选项中的方向信息不是 "TIMESERIES" 时,将执行一些操作来将表的 kvtype 设置为未定义状态。
最后,再来分析如下判断条件:
if (0 == pg_strcasecmp(storeChar, ORIENTATION_COLUMN)) {
CheckCStoreUnsupportedFeature(stmt);
CheckCStoreRelOption(std_opt);
ForbidToSetOptionsForColTbl(stmt->options);
if (stmt->partTableState) {
if (stmt->partTableState->rowMovement == ROWMOVEMENT_DISABLE) {
ereport(NOTICE,
(errmsg("disable row movement is invalid for column stored tables."
" They always enable row movement between partitions.")));
}
/* always enable rowmovement for column stored tables */
stmt->partTableState->rowMovement = ROWMOVEMENT_ENABLE;
}
} else if (0 == pg_strcasecmp(storeChar, ORIENTATION_TIMESERIES)) {
/* check both support coloumn store and row store */
CheckCStoreUnsupportedFeature(stmt);
CheckCStoreRelOption(std_opt);
if (stmt->partTableState) {
if (stmt->partTableState->rowMovement == ROWMOVEMENT_DISABLE)
ereport(NOTICE,
(errmsg("disable row movement is invalid for timeseries stored tables."
" They always enable row movement between partitions.")));
/* always enable rowmovement for column stored tables */
stmt->partTableState->rowMovement = ROWMOVEMENT_ENABLE;
}
if (relkind == RELKIND_RELATION) {
/* only care heap relation. ignore foreign table and index relation */
forbid_to_set_options_for_timeseries_tbl(stmt->options);
}
/* construct distribute keys using tstag if not specified */
if (stmt->distributeby == NULL) {
ListCell* cell = NULL;
DistributeBy* newnode = makeNode(DistributeBy);
List* colnames = NIL;
newnode->disttype = DISTTYPE_HASH;
foreach (cell, schema) {
ColumnDef* colDef = (ColumnDef*)lfirst(cell);
if (colDef->kvtype == ATT_KV_TAG && IsTypeDistributable(colDef->typname->typeOid)) {
colnames = lappend(colnames, makeString(colDef->colname));
}
}
if (list_length(colnames) == 0) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("No column can be used as distribution column.")));
}
newnode->colname = colnames;
stmt->distributeby = newnode;
/* if specified hidetag, add a hidden column as distribution column */
} else if (stmt->distributeby->disttype == DISTTYPE_HIDETAG &&
stmt->distributeby->colname == NULL) {
bool has_distcol = false;
ListCell* cell;
foreach (cell, schema) {
ColumnDef* colDef = (ColumnDef*)lfirst(cell);
if (colDef->kvtype == ATT_KV_TAG && IsTypeDistributable(colDef->typname->typeOid)) {
has_distcol = true;
}
}
if (!has_distcol) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("No column can be used as distribution column.")));
}
ColumnDef* colDef = makeColumnDef(TS_PSEUDO_DIST_COLUMN, "char");
colDef->kvtype = ATT_KV_HIDE;
stmt->tableElts = lappend(stmt->tableElts, colDef);
/* still use hash logic later */
DistributeBy* distnode = stmt->distributeby;
distnode->disttype = DISTTYPE_HASH;
distnode->colname = lappend(distnode->colname, makeString(colDef->colname));
ereport(LOG, (errmodule(MOD_TIMESERIES), errmsg("use implicit distribution column method.")));
}
} else {
if (relkind == RELKIND_RELATION) {
/* only care heap relation. ignore foreign table and index relation */
ForbidToSetOptionsForRowTbl(stmt->options);
}
}
这段代码根据存储选项中的方向信息(storeChar)执行一系列操作。
- 如果存储选项的方向是
"COLUMN",则执行以下操作:
- 调用
CheckCStoreUnsupportedFeature(stmt),检查是否支持列存储的特性。- 调用
CheckCStoreRelOption(std_opt),检查列存储的关系选项。- 调用
ForbidToSetOptionsForColTbl(stmt->options),禁止为列存储表设置特定的选项。- 如果存在分区表状态
(stmt->partTableState),则根据分区表状态设置行移动属性为"ROWMOVEMENT_ENABLE",因为列存储表总是启用分区间的行移动。
- 如果存储选项的方向是
"TIMESERIES",则执行以下操作:
- 调用
CheckCStoreUnsupportedFeature(stmt),检查是否支持列存储的特性。- 调用
CheckCStoreRelOption(std_opt),检查列存储的关系选项。- 如果存在分区表状态
(stmt->partTableState),则根据分区表状态设置行移动属性为"ROWMOVEMENT_ENABLE"。- 如果表的类型是普通表
(relkind == RELKIND_RELATION),则禁止为时序存储表设置特定的选项。- 构建分布键使用时间戳标签列作为分布列,如果未指定分布键的话。
- 如果指定了隐藏标签
("HIDETAG")的分布方式,且未指定分布列,则添加一个隐藏列作为分布列。
- 如果存储选项的方向不是
"COLUMN"或"TIMESERIES",则执行以下操作:
- 如果表的类型是普通表
(relkind == RELKIND_RELATION),则禁止为行存储表设置特定的选项。
其次,我们进入到 CheckCStoreUnsupportedFeature 函数来看看吧,这个函数用于检查列存储表是否支持指定的特性,如果不支持则报告错误。
CheckCStoreUnsupportedFeature 函数源码如下:(路径:src/gausskernel/optimizer/commands/tablecmds.cpp)
// all unsupported features are checked and error reported here for cstore table
static void CheckCStoreUnsupportedFeature(CreateStmt* stmt)
{
Assert(stmt);
if (stmt->relation->relpersistence == RELPERSISTENCE_GLOBAL_TEMP) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("global temporary table can only support heap table")));
}
if (stmt->ofTypename)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("Unsupport feature"),
errdetail("cstore/timeseries don't support relation defination "
"with composite type using CREATE TABLE OF TYPENAME.")));
if (stmt->inhRelations) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("Unsupport feature"),
errdetail("cstore/timeseries don't support relation defination with inheritance.")));
}
if (stmt->relation->schemaname != NULL &&
IsSystemNamespace(get_namespace_oid(stmt->relation->schemaname, false))) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("Unsupport feature"),
errdetail("cstore/timeseries don't support relation defination with System namespace.")));
}
CheckPartitionUnsupported(stmt);
// Check constraints
ListCell* lc = NULL;
foreach (lc, stmt->tableEltsDup) {
Node* element = (Node*)lfirst(lc);
/* check table-level constraints */
if (IsA(element, Constraint) && !CSTORE_SUPPORT_CONSTRAINT(((Constraint*)element)->contype)) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("column/timeseries store unsupport constraint \"%s\"",
GetConstraintType(((Constraint*)element)->contype))));
} else if (IsA(element, ColumnDef)) {
List* colConsList = ((ColumnDef*)element)->constraints;
ListCell* lc2 = NULL;
/* check column-level constraints */
foreach (lc2, colConsList) {
Constraint* colCons = (Constraint*)lfirst(lc2);
if (!CSTORE_SUPPORT_CONSTRAINT(colCons->contype)) {
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("column/timeseries store unsupport constraint \"%s\"",
GetConstraintType(colCons->contype))));
}
}
}
}
}
下面是函数中每个部分的解释:
- 首先,函数使用
Assert(stmt)确保传入的CreateStmt结构体非空。- 如果要创建的表是全局临时表
(stmt->relation->relpersistence == RELPERSISTENCE_GLOBAL_TEMP),则报告错误,因为列存储表不支持全局临时表。- 如果表的定义中使用了
CREATE TABLE OF TYPENAME,报告错误,因为列存储表不支持使用复合类型定义。- 如果表的定义使用了继承
(stmt->inhRelations),报告错误,因为列存储表不支持继承。- 如果表的模式名不为空且属于系统命名空间,报告错误,因为列存储表不支持在系统命名空间中定义。
- 调用
CheckPartitionUnsupported(stmt)检查分区相关的不支持特性。- 遍历
stmt->tableEltsDup中的每个元素(表元素,如列定义、约束等),检查是否存在不受支持的约束类型。如果存在不受支持的约束,报告错误。
- 针对表级约束,检查约束类型是否受支持。
- 针对列级约束,检查每个列的约束列表中的约束类型是否受支持。
其次,我们再来看看 CheckCStoreRelOption 函数,该函数主要检查 PARTIAL_CLUSTER_ROWS 是否小于 MAX_BATCHROW 的值。StdRdOptions 是一个用于存储关系选项的数据结构,它在代码中用于表示存储引擎的特定选项。
其源码如下:(路径:src/gausskernel/optimizer/commands/tablecmds.cpp)
void CheckCStoreRelOption(StdRdOptions* std_opt)
{
Assert(std_opt);
if (std_opt->partial_cluster_rows < std_opt->max_batch_rows && std_opt->partial_cluster_rows >= 0) {
ereport(ERROR,
(errcode(ERRCODE_INVALID_TABLE_DEFINITION),
errmsg("PARTIAL_CLUSTER_ROWS cannot be less than MAX_BATCHROW."),
errdetail("PARTIAL_CLUSTER_ROWS must be greater than or equal to MAX_BATCHROW."),
errhint("PARTIAL_CLUSTER_ROWS is MAX_BATCHROW multiplied by an integer.")));
}
}
以下是函数的解释:
- 首先,函数使用
Assert(std_opt)确保传入的StdRdOptions结构体非空。- 如果
PARTIAL_CLUSTER_ROWS的值小于MAX_BATCHROW并且大于等于0,报告错误。这是因为在列存储表中,PARTIAL_CLUSTER_ROWS表示部分数据块的行数,而MAX_BATCHROW表示每个批处理的最大行数。这两个参数应该满足PARTIAL_CLUSTER_ROWS >= MAX_BATCHROW的关系。
报告的错误信息包括:
"PARTIAL_CLUSTER_ROWS"不能小于"MAX_BATCHROW"。"PARTIAL_CLUSTER_ROWS"必须大于或等于"MAX_BATCHROW"。- 提示说明
"PARTIAL_CLUSTER_ROWS"是"MAX_BATCHROW"乘以一个整数。
了解完了函数,我们再分别来看一下函数中的以下两个函数
AlterTableCreateToastTable(rel_oid, toast_options, ((CreateStmt *)stmt)->oldToastNode);
AlterCStoreCreateTables(rel_oid, toast_options, (CreateStmt*)stmt);
其中,AlterTableCreateToastTable 函数的作用是为表创建 TOAST(The Oversized-Attribute Storage Technique)表,用于存储那些超过一定大小的大型列数据。TOAST 表存储的是被压缩和分割成块的列值,以优化数据库性能和存储空间的使用。
参数解释:
rel_oid:要创建 TOAST 表的主表的对象标识符(OID)。toast_options:创建TOAST表的选项,包括压缩、存储引擎等设置。((CreateStmt *)stmt)->oldToastNode:源表的 TOAST 表节点(如果存在的话),用于在执行ALTER TABLE操作时将现有的 TOAST 表与新创建的 TOAST 表进行合并。
AlterTableCreateToastTable 函数源码如下:(路径:src/common/backend/catalog/toasting.cpp)
/*
* AlterTableCreateToastTable
* If the table needs a toast table, and doesn't already have one,
* then create a toast table for it.
*
* reloptions for the toast table can be passed, too. Pass (Datum) 0
* for default reloptions.
*
* We expect the caller to have verified that the relation is a table and have
* already done any necessary permission checks. Callers expect this function
* to end with CommandCounterIncrement if it makes any changes.
*/
void AlterTableCreateToastTable(Oid relOid, Datum reloptions, List *filenodelist)
{
Relation rel;
bool rel_is_partitioned = check_rel_is_partitioned(relOid);
if (!rel_is_partitioned) {
/*
* Grab an exclusive lock on the target table, since we'll update its
* pg_class tuple. This is redundant for all present uses, since caller
* will have such a lock already. But the lock is needed to ensure that
* concurrent readers of the pg_class tuple won't have visibility issues,
* so let's be safe.
*/
rel = heap_open(relOid, AccessExclusiveLock);
if (needs_toast_table(rel))
(void)create_toast_table(rel, InvalidOid, InvalidOid, reloptions, false, filenodelist);
} else {
rel = heap_open(relOid, AccessShareLock);
if (needs_toast_table(rel))
(void)createToastTableForPartitionedTable(rel, reloptions, filenodelist);
}
heap_close(rel, NoLock);
}
在 AlterTableCreateToastTable 函数中, if (needs_toast_table(rel)) 判断的是是否需要为某个表创建 TOAST 表。其中,needs_toast_table 函数中有如下代码段:
// column-store relations don't need any toast tables.
if (RelationIsColStore(rel))
return false;
因为 TOAST 表的创建和维护会增加一些开销,而对于列存储表来说,通常已经具备了高效存储和压缩的特性,所以不像行存储表那样需要单独的 TOAST 表来处理大型列数据。
AlterCStoreCreateTables 函数的作用是为一个列存储表执行一些列存储特定的操作,主要包括以下几个方面:
- 创建 CStore 子表(Delta 表) : 对于列存储表,通常会有一个主表和一个或多个子表(如 Delta 表)。Delta 表用于存储新增和修改的数据,以便在之后的时间点将这些变更合并到主表中。这个函数可能会创建或配置 Delta 表。
- 配置存储选项: 列存储表可能有一些特定的存储选项,这些选项可能会影响数据的存储、压缩、索引等方面。函数可能会根据提供的参数进行相应的存储选项配置。
- 处理 TOAST 表: 尽管列存储表不需要创建 TOAST 表,但在某些情况下可能需要处理 TOAST 相关的选项,例如对于那些不同存储方式混合的列存储表
AlterCStoreCreateTables 函数源码如下所示:(路径:src/common/backend/catalog/cstore_ctlg.cpp)
/*
* AlterTableCreateDeltaTable
* 如果是一个 ColStore 表,就应该调用这个函数。
* 这个函数用于创建一个 Delta 表。
*/
void AlterCStoreCreateTables(Oid relOid, Datum reloptions, CreateStmt* mainTblStmt)
{
Relation rel;
/*
* 获取目标表的排它锁,因为我们将会更新它的 pg_class 元组。
* 这对于目前的所有使用情况来说都是多余的,因为调用者已经有了这样的锁。
* 但是为了确保并发读取 pg_class 元组的其他进程不会出现可见性问题,我们保险起见加上这个锁。
*/
rel = heap_open(relOid, AccessExclusiveLock);
/*
* Dfs 表将会使用 AlterDfsCreateTables 函数处理。
*/
if (!RelationIsCUFormat(rel)) {
heap_close(rel, NoLock);
return;
}
if (!RELATION_IS_PARTITIONED(rel)) {
/* create_delta_table 函数完成所有工作 */
// 用于创建 Delta 表的,Delta 表存储了列存储表中发生的数据变更(如插入、更新、删除操作)的信息,以便后续进行数据恢复或查询。
(void)CreateDeltaTable(rel, reloptions, false, mainTblStmt);
// 用于创建 CUDesc 表,也就是变更描述表,CUDesc 表用于记录列存储表中数据变更的信息,如插入、更新、删除的数据。
(void)CreateCUDescTable(rel, reloptions, false);
// 通过静态方法调用来创建列存储表的存储空间
CStore::CreateStorage(rel, InvalidOid);
} else {
createCUDescTableForPartitionedTable(rel, reloptions);
createDeltaTableForPartitionedTable(rel, reloptions, mainTblStmt);
CreateStorageForPartition(rel);
}
heap_close(rel, NoLock);
}
这里重点看一下 CStore::CreateStorage ,CreateStorage 为 CStore 类中的静态方法 ,用来创建列存储表的存储空间,源码如下所示:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
/* DONT call in redo */
// 提醒不要在恢复(redo)过程中调用这个函数
void CStore::CreateStorage(Relation rel, Oid newRelFileNode)
{
// 获取表的元组描述(Tuple Descriptor)。
TupleDesc desc = RelationGetDescr(rel);
// 获取表的属性数量。
int nattrs = desc->natts;
// 获取表的属性信息数组。
Form_pg_attribute* attrs = desc->attrs;
// 获取表的持久性信息,即表是持久性表还是临时表。
char relpersistence = rel->rd_rel->relpersistence;
// 获取表的关系文件节点信息。
RelFileNode rd_node = rel->rd_node;
// 如果 newRelFileNode 是有效的(即指定了新的关系文件节点),则将当前表的关系文件节点更新为新的关系文件节点。
if (OidIsValid(newRelFileNode)) {
// use the new filenode if *newRelFileNode* is valid.
rd_node.relNode = newRelFileNode;
}
for (int i = 0; i < nattrs; i++) {
// 如果当前属性已被标记为删除(attisdropped 为 true),则跳过此属性。
if (attrs[i]->attisdropped)
continue;
// 获取当前属性的属性编号。
int attrid = attrs[i]->attnum;
// 创建一个 CFileNode 实例,用于表示关系文件节点和属性编号。
CFileNode cnode(rd_node, attrid, MAIN_FORKNUM);
// create cu file in disk.
// 创建一个 CUStorage 实例,表示列存储单元(Column Unit)的存储。
CUStorage* custorage = New(CurrentMemoryContext) CUStorage(cnode);
Assert(custorage);
// 调用 custorage 的 CreateStorage 方法来创建存储空间。它会在磁盘上创建相应的 CU 文件。
custorage->CreateStorage(0, false);
// 删除之前创建的 custorage 实例。
DELETE_EX(custorage);
// log and insert into the pending delete list.
// 将关系文件节点、属性编号、持久性信息和表的拥有者信息传递给它,以记录创建存储空间的操作。
CStoreRelCreateStorage(&rd_node, attrid, relpersistence, rel->rd_rel->relowner);
}
}
调试信息如下所示:
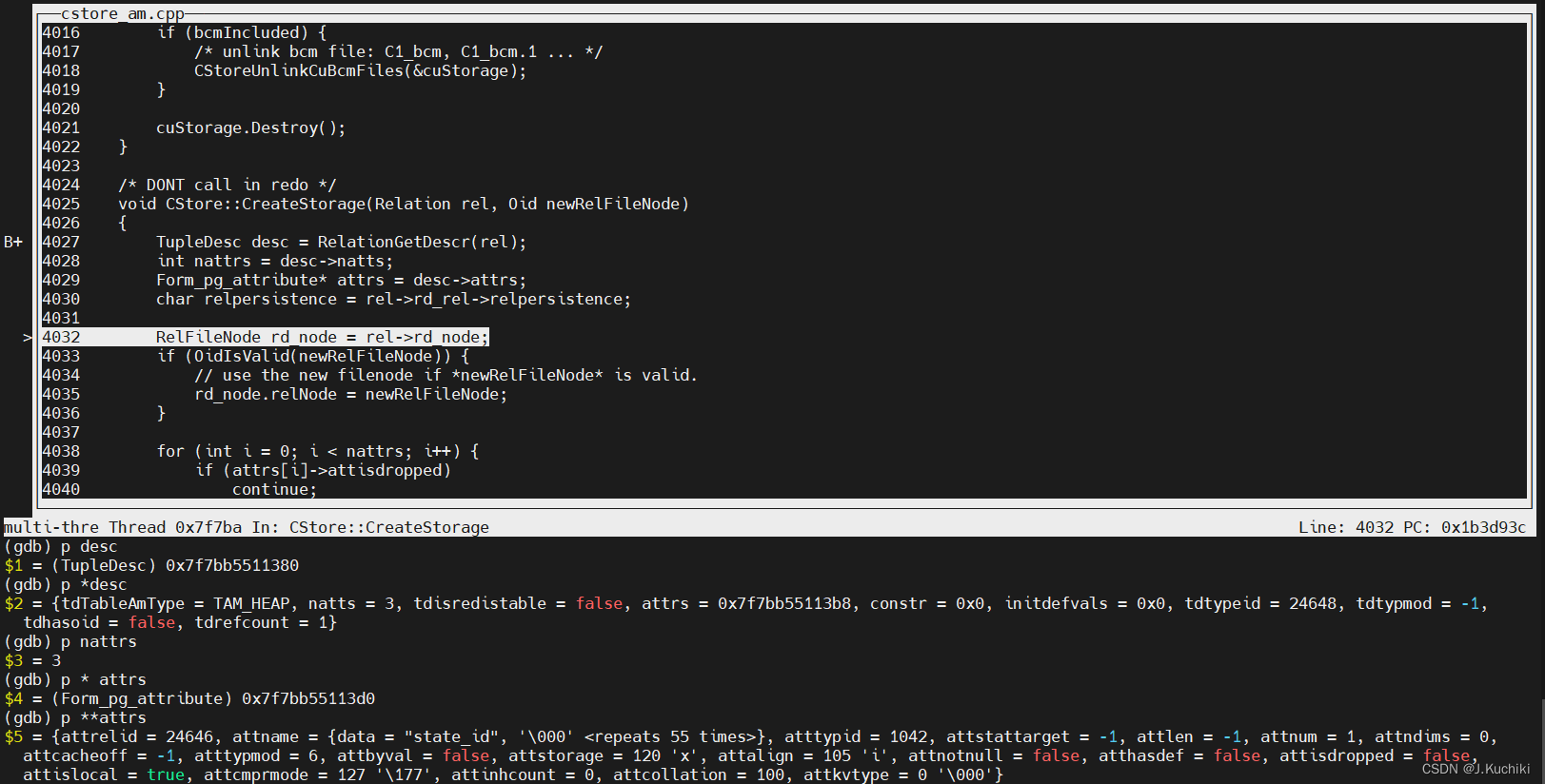
这里我们对 Form_pg_attribute* attrs = desc->attrs; 稍作解析:
{attrelid = 24646, attname = {data = "state_id", '\000' <repeats 55 times>}, atttypid = 1042, attstattarget = -1, attlen = -1, attnum = 1, attndims = 0,
attcacheoff = -1, atttypmod = 6, attbyval = false, attstorage = 120 'x', attalign = 105 'i', attnotnull = false, atthasdef = false, attisdropped = false,
attislocal = true, attcmprmode = 127 '\177', attinhcount = 0, attcollation = 100, attkvtype = 0 '\000'}
| 参数 | 含义 |
|---|---|
| attrelid = 24646 | 表示这个属性所属的表的关系 ID。 |
| attname = {data = “state_id”, ‘\000’ <repeats 55 times>} | 表示属性的名称,这里是 “state_id”。 |
| atttypid = 1042 | 表示属性的数据类型的 OID。在这个例子中,OID 为 1042,对应的数据类型是字符类型。 |
| attstattarget = -1 | 表示在自动统计分析期间收集统计信息的目标值。在这里是 -1,表示未指定。 |
| attlen = -1 | 表示属性的长度(字节数)。在这里是 -1,表示长度是可变的。 |
| attnum = 1 | 表示属性的编号(从 1 开始)。在这里是 1。 |
| attndims = 0 | 表示属性的维度数目。在这里是 0,表示这是一个标量属性。 |
| attcacheoff = -1 | 表示属性在元组中的偏移量。在这里是 -1,表示未指定。 |
| atttypmod = 6 | 表示属性的类型修饰符。在这里是 6,具体含义取决于属性的数据类型。 |
| attbyval = false | 表示属性是否按值传递。在这里是 false,表示不是按值传递。 |
| attstorage = 120 ‘x’ | 表示属性的存储方式。在这里是 ‘x’,表示外部存储。 |
| attalign = 105 ‘i’ | 表示属性的对齐方式。在这里是 ‘i’,表示按照 int 类型的对齐方式。 |
| attnotnull = false | 表示属性是否可以为 NULL。在这里是 false,表示可以为 NULL。 |
| atthasdef = false | 表示属性是否有默认值。在这里是 false,表示没有默认值。 |
| attisdropped = false | 表示属性是否被标记为已删除。在这里是 false,表示没有被标记为删除。 |
| attislocal = true | 表示属性是否是本地属性。在这里是 true,表示是本表的属性。 |
| attcmprmode = 127 ‘\177’ | 表示属性的压缩模式。在这里是 127,具体含义取决于属性的数据类型和存储方式。 |
| attinhcount = 0 | 表示从父表继承的次数。在这里是 0,表示没有从父表继承。 |
| attcollation = 100 | 表示属性的排序规则的 OID。在这里是 100,对应的排序规则。 |
| attkvtype = 0 ‘\000’ | 表示属性的键值类型。在这里是 0,表示不是键值属性。 |
总结
到此,本文初步介绍了列存储创建表的大致流程,其中很多的细节可能并没有详细展开。此外,列存储所涉及的模块和相关知识也非常多,在后续的学习中会不断的跟进。