yolov5l网络示意图:
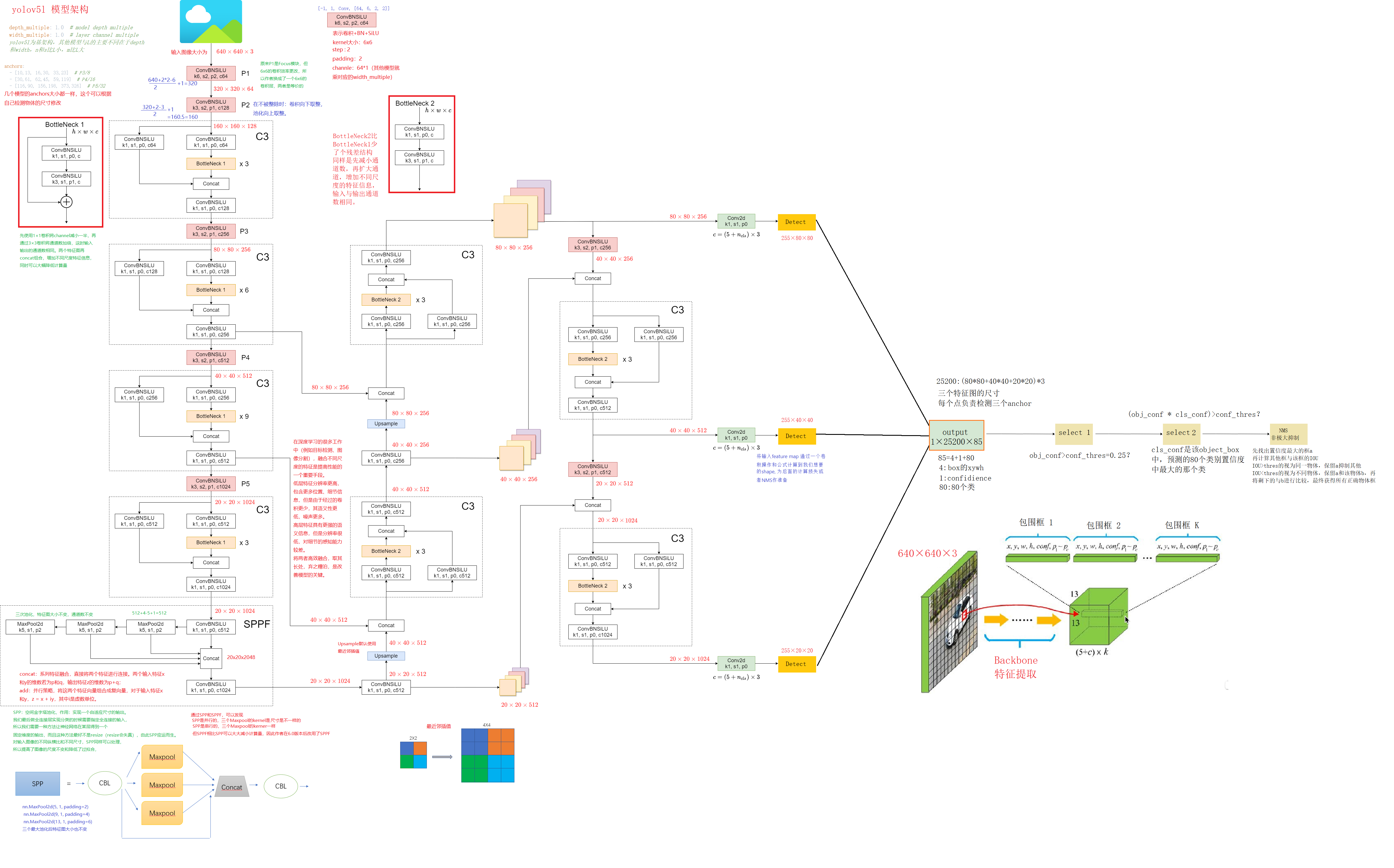
以yolov5s为例(模型都是在yolov5l上修改了depth_multiple和width_multiple,上面图形是画的yolov5l的,下面的yaml是yolov5s的目的是为了更好的计算网络信息)
nc: 80 # number of classes
depth_multiple:0.5 # model depth multiple 控制模型的深度(BottleneckCSP个数)
width_multiple:0.5 # layer channel multiple 控制Conv通道channel个数(卷积核数量)
# depth_multiple表示BottleneckCSP模块的缩放因子,将所有BottleneckCSP模块的Bottleneck乘上该参数得到最终个数
# width_multiple表示卷积通道的缩放因子,就是将配置里面的backbone和head部分有关Conv通道的设置,全部乘以该系数
# 通过这两个参数就可以实现不同复杂度的模型设计
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8 wh stride=8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args[output_channel,kernel_size,stride,padding]]
# from表示当前模块的输入来自那一层的输出,-1表示来自上一层的输出
# number表示本模块重复的次数,1表示只有一个,3表示重复3次
# module: 模块名
# 第一层作者将focus模块改为了卷积模块,因为这个卷积块和focus的功能一样,但是效率更高
# 第一层的卷积核为 [inp:3, outp:64*0.5=32, k:6, stride:2, padding:2] width_multiple是控制特征图的深度的,输出的channel要乘width_multiple
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2(特征图尺寸变为原来的1/2 320*320)
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 下采样,将特征图变为原图的1/4 160*160 [32, 128*0.5=64, 3, 2]
[-1, 3, C3, [128]], # 2 [64, 64, 1] depth_multiple控制模型深度,3表示重复3次,3*depth_multiple=1.5,向上取整,yolov5s 重复两次
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 特征图:80*80
[-1, 9, C3, [256]], # 4 C3模块是
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 特征图:40*40
[-1, 9, C3, [512]], # 6
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 特征图:20*20
[-1, 3, C3, [1024]], # 8
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 head 作者没有区分neck模块,所以head部分包含了PANet+Detect部分
head:
[[-1, 1, Conv, [512, 1, 1]], # 10 对backbone后的特征图进行1x1的卷积降维
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11 使用nearest最近只插值,进行上采样增大特征图尺寸 特征图:40*40
[[-1, 6], 1, Concat, [1]], # 12 与6的输出进行concat
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]], # 14 特征图:40*40
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #15 特征图:80*80
[[-1, 4], 1, Concat, [1]], # 16
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 18 特征图:40*40
[[-1, 14], 1, Concat, [1]], # 19 cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 21 特征图:80*80
[[-1, 10], 1, Concat, [1]], # 22 cat head P5 特征图:80*80
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # 24 Detect(P3, P4, P5)
]
yaml文件和最上面的流程图是对应的,下面看模型搭建过程。
在train是通过 model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) 进入模型搭建的,传入参数:cfg就是我们yaml文件中定义的网络,ch表示输入是彩色图,nc是num classes,anchors就是anchors。下面看具体怎么搭建的。
首先进入yolo.py中的Model类,先进入init函数,先解析传入的yaml模型参数文件,得到一个字典:
{
'nc': 20,
'depth_multiple': 0.33,
'width_multiple': 0.5,
'anchors': [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]],
'backbone': [[-1, 1, 'Focus', [64, 3]], [-1, 1, 'Conv', [128, 3, 2]], [-1, 3, 'C3', [128]], [-1, 1, 'Conv', [256, 3, 2]], [-1, 9, 'C3', [256]], [-1, 1,'Conv', [512, 3, 2]], [-1, 9, 'C3', [512]], [-1, 1, 'Conv', [1024, 3, 2]], [-1, 1, 'SPP', [1024, [5, 9, 13]]], [-1, 3, 'C3', [1024, False]]],
'head': [[-1, 1, 'Conv', [512, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 6], 1, 'Concat', [1]], [-1, 3, 'C3', [512, False]], [-1, 1, 'Conv', [256, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 4], 1, 'Concat', [1]], [-1, 3, 'C3', [256, False]], [-1, 1, 'Conv', [256, 3, 2]], [[-1, 14], 1, 'Concat', [1]], [-1, 3, 'C3', [512, False]], [-1, 1, 'Conv', [512, 3, 2]], [[-1, 10], 1, 'Concat', [1]], [-1, 3, 'C3', [1024, False]], [[17, 20, 23], 1, 'Detect', ['nc', 'anchors']]]
}
然后通过 self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) 进入 parse_model函数进行模型搭建。
返回值self.model: 初始化的整个网络模型(包括Detect层结构);
self.save: 所有层结构中from不等于-1的序号,并排好序 [4, 6, 10, 14, 17, 20, 23]
parse_model先用一个for循环for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']) 将backbone和head中的数组分别取出来,如:[-1, 1, Conv, [64, 6, 2, 2] 并将模块名,等分别取出,赋值给(f, n, m, args)
然后是判断if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, CBAM]:
这些是和卷积有关的操作,所有放一块了。比如m=Conv 这样就取到了模块名称和args,将args传入Conv函数,就搭建了一层网络了。
我认为yolo的核心代码就是parse_model函数,简小精悍(当然最主要的还是Conv,C3,Bottleneck这些函数)
def parse_model(d, ch): # model_dict, input_channels(3)
"""
用在上面Model模块中 解析模型文件(字典形式),并搭建网络结构
这个函数其实主要做的就是: 更新当前层的args(参数),计算c2(当前层的输出channel) =>
使用当前层的参数搭建当前层 => 生成 layers + save
:params d: model_dict 模型文件 字典形式 {dict:7} yolov5s.yaml中的6个元素 + ch
:params ch: 记录模型每一层的输出channel 初始ch=[3] 后面会删除
:return nn.Sequential(*layers): 网络的每一层的层结构
:return sorted(save): 把所有层结构中from不是-1的值记下 并排序 [4, 6, 10, 14, 17, 20, 23]
"""
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
# 读取d字典中的anchors和parameters(nc、depth_multiple、width_multiple)
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
# na: number of anchors 每一个predict head上的anchor数 传入的anchors为包含六个元素的列表,除2是anchor的数量
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors
# no: number of outputs 每一个predict head层的输出channel = anchors * (classes + 5) = 75(VOC)
no = na * (nc + 5)
# 开始搭建网络
# layers: 保存每一层的层结构
# save: 记录下所有层结构中from中不是-1的层结构序号
# c2: 保存当前层的输出channel
layers, save, c2 = [], [], ch[-1]
# from(当前层输入来自哪些层), number(当前层次数 初定), module(当前层类别), args(当前层类参数 初定)
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # 遍历backbone和head的每一层
# eval(string) 得到当前层的真实类名 例如: m= Focus -> <class 'models.common.Focus'>
m = eval(m) if isinstance(m, str) else m
# 没什么用
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
# ------------------- 更新当前层的args(参数),计算c2(当前层的输出channel) -------------------
# depth gain 控制深度 如v5s: n*0.33 n: 当前模块的次数(间接控制深度)
n = max(round(n * gd), 1) if n > 1 else n
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d,
Focus, CrossConv, BottleneckCSP, C3, C3TR, CBAM]:
# c1: 当前层的输入的channel数 c2: 当前层的输出的channel数(初定) ch: 记录着所有层的输出channel f为-1就是上一层的输出,作为这一层的输入,args[0] 比如 [128, 3, 2] 128就是这层channel的个数 即输出维度
c1, c2 = ch[f], args[0]
# if not output no=75 只有最后一层c2=no 最后一层不用控制宽度,输出channel必须是no
if c2 != no:
# width gain 控制宽度 如v5s: c2*0.5 c2: 当前层的最终输出的channel数(间接控制宽度) 8是为了方便GPU计算
c2 = make_divisible(c2 * gw, 8)
# 在初始arg的基础上更新 加入当前层的输入 channel 并更新当前层
# [in_channel, out_channel, *args[1:]]
args = [c1, c2, *args[1:]]
# 如果当前层是 BottleneckCSP/C3/C3TR, 则需要在args中加入bottleneck的个数
# [in_channel, out_channel, Bottleneck的个数n, bool(True表示有 shortcut 默认,反之无)]
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # 在第二个位置插入bottleneck个数 n
n = 1 # 恢复默认值1
elif m is nn.BatchNorm2d:
# BN层只需要返回上一层的输出 channel
args = [ch[f]]
elif m is Concat:
# Concat层则将f中所有的输出累加得到这层的输出channel
c2 = sum([ch[x] for x in f])
elif m is Detect: # Detect(YOLO Layer)层
# 在args中加入三个Detect层的输出channel
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors 几乎不执行
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract: # 不怎么用
c2 = ch[f] * args[0] ** 2
elif m is Expand: # 不怎么用
c2 = ch[f] // args[0] ** 2
elif m is SELayer: # 加入SE模块
channel, re = args[0], args[1]
channel = make_divisible(channel * gw, 8) if channel != no else channel
args = [channel, re]
else:
# Upsample
c2 = ch[f] # args不变
# -----------------------------------------------------------------------------------
# m_: 得到当前层module 如果n>1就创建多个m(当前层结构), 如果n=1就创建一个m
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args)
# 打印当前层结构的一些基本信息
t = str(m)[8:-2].replace('__main__.', '') # t = module type 'modules.common.Focus'
np = sum([x.numel() for x in m_.parameters()]) # number params 计算这一层的参数量
m_.i, m_.f, m_.type, m_.np = i, f, t, np # index, 'from' index, number, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
# append to savelist 把所有层结构中from不是-1的值记下 [6, 4, 14, 10, 17, 20, 23]
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1)
# 将当前层结构module加入layers中
layers.append(m_)
if i == 0:
ch = [] # 去除输入channel [3]
# 把当前层的输出channel数加入ch
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
代码解释很详细,可以自己看下。这样就返回了搭建好的网络,并放入Sequential中返回,save每一层的输出,因为后面需要用来作concat等操作要用到 不在self.save层的输出就为None











![[LINUX]基本权限](https://img-blog.csdnimg.cn/e66d33db5c364d87ae9ba019c1d93ab5.png)
