[oneAPI] 手写数字识别-LSTM
- 手写数字识别
- 参数与包
- 加载数据
- 模型
- 训练过程
- 结果
- oneAPI
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
手写数字识别
使用了pytorch以及Intel® Optimization for PyTorch,通过优化扩展了 PyTorch,使英特尔硬件的性能进一步提升,让手写数字识别问题更加的快速高效
使用MNIST数据集,该数据集包含了一系列以黑白图像表示的手写数字,每个图像的大小为28x28像素,数据集组成如下:
- 训练集:包含60,000个图像和标签,用于训练模型。
- 测试集:包含10,000个图像和标签,用于测试模型的性能。
每个图像都被标记为0到9之间的一个数字,表示图像中显示的手写数字。这个数据集常常被用来验证图像分类模型的性能,特别是在计算机视觉领域。
参数与包
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import intel_extension_for_pytorch as ipex
# Device configuration
device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
sequence_length = 28
input_size = 28
hidden_size = 128
num_layers = 2
num_classes = 10
batch_size = 100
num_epochs = 2
learning_rate = 0.01
加载数据
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='../../data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='../../data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
模型
# Recurrent neural network (many-to-one)
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# Set initial hidden and cell states
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
# Forward propagate LSTM
out, _ = self.lstm(x, (h0, c0)) # out: tensor of shape (batch_size, seq_length, hidden_size)
# Decode the hidden state of the last time step
out = self.fc(out[:, -1, :])
return out
训练过程
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
model, optimizer = ipex.optimize(model, optimizer=optimizer)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch + 1, num_epochs, i + 1, total_step, loss.item()))
# Test the model
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
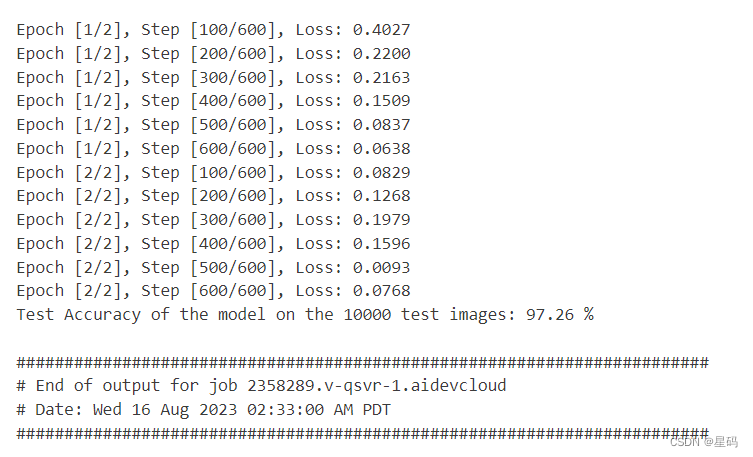
print('Test Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))
# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')
结果
oneAPI
import intel_extension_for_pytorch as ipex
# Device configuration
device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')
# 模型
model = ConvNet(num_classes).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
model, optimizer = ipex.optimize(model, optimizer=optimizer)