本章会讨论 Cargo 其他一些更为高级的功能,我们将展示如何:
- 使用发布配置来自定义构建
- 将库发布到 crates.io
- 使用工作空间来组织更大的项目
- 从 crates.io 安装二进制文件
- 使用自定义的命令来扩展 Cargo
Cargo 的功能不止本章所介绍的,关于其全部功能的详尽解释,请查看 文档
14.1 采用发布配置自定义构建
在 Rust 中 发布配置(release profiles)是预定义的、可定制的带有不同选项的配置,他们允许程序员更灵活地控制代码编译的多种选项。每一个配置都彼此相互独立。
Cargo 有两个主要的配置:运行 cargo build 时采用的 dev 配置和运行 cargo build --release 的 release 配置。dev 配置被定义为开发时的好的默认配置,release 配置则有着良好的发布构建的默认配置。
这些配置名称可能很眼熟,因为它们出现在构建的输出中:
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
$ cargo build --release
Finished release [optimized] target(s) in 0.0 secs
构建输出中的 dev 和 release 表明编译器在使用不同的配置。
当项目的 Cargo.toml 文件中没有任何 [profile.*] 部分的时候,Cargo 会对每一个配置都采用默认设置。通过增加任何希望定制的配置对应的 [profile.*] 部分,我们可以选择覆盖任意默认设置的子集。例如,如下是 dev 和 release 配置的 opt-level 设置的默认值:
文件名: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
opt-level 设置控制 Rust 会对代码进行何种程度的优化。这个配置的值从 0 到 3。越高的优化级别需要更多的时间编译,所以如果你在进行开发并经常编译,可能会希望在牺牲一些代码性能的情况下编译得快一些。这就是为什么 dev 的 opt-level 默认为 0。当你准备发布时,花费更多时间在编译上则更好。只需要在发布模式编译一次,而编译出来的程序则会运行很多次,所以发布模式用更长的编译时间换取运行更快的代码。这正是为什么 release 配置的 opt-level 默认为 3。
对于每个配置的设置和其默认值的完整列表,请查看 Cargo 的文档。
14.2 将crate 发布到Crates.io
我们曾经在项目中使用 crates.io 上的包作为依赖,不过你也可以通过发布自己的包来向它人分享代码。crates.io 用来分发包的源代码,所以它主要托管开源代码。
Rust 和 Cargo 有一些帮助它人更方便找到和使用你发布的包的功能。我们将介绍一些这样的功能,接着讲到如何发布一个包。
编写有用的文档注释
准确的包文档有助于其他用户理解如何以及何时使用他们,所以花一些时间编写文档是值得的。第三章中我们讨论了如何使用两斜杠 // 注释 Rust 代码。Rust 也有特定的用于文档的注释类型,通常被称为 文档注释(documentation comments),他们会生成 HTML 文档。这些 HTML 展示公有 API 文档注释的内容,他们意在让对库感兴趣的程序员理解如何 使用 这个 crate,而不是它是如何被 实现 的。
文档注释使用三斜杠 /// 而不是两斜杆以支持 Markdown 注解来格式化文本。文档注释就位于需要文档的项的之前
/// 将给定的数字加一
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
这里,我们提供了一个 add_one 函数工作的描述,接着开始了一个标题为 Examples 的部分,和展示如何使用 add_one 函数的代码。可以运行 cargo doc 来生成这个文档注释的 HTML 文档。这个命令运行由 Rust 分发的工具 rustdoc 并将生成的 HTML 文档放入 target/doc 目录。
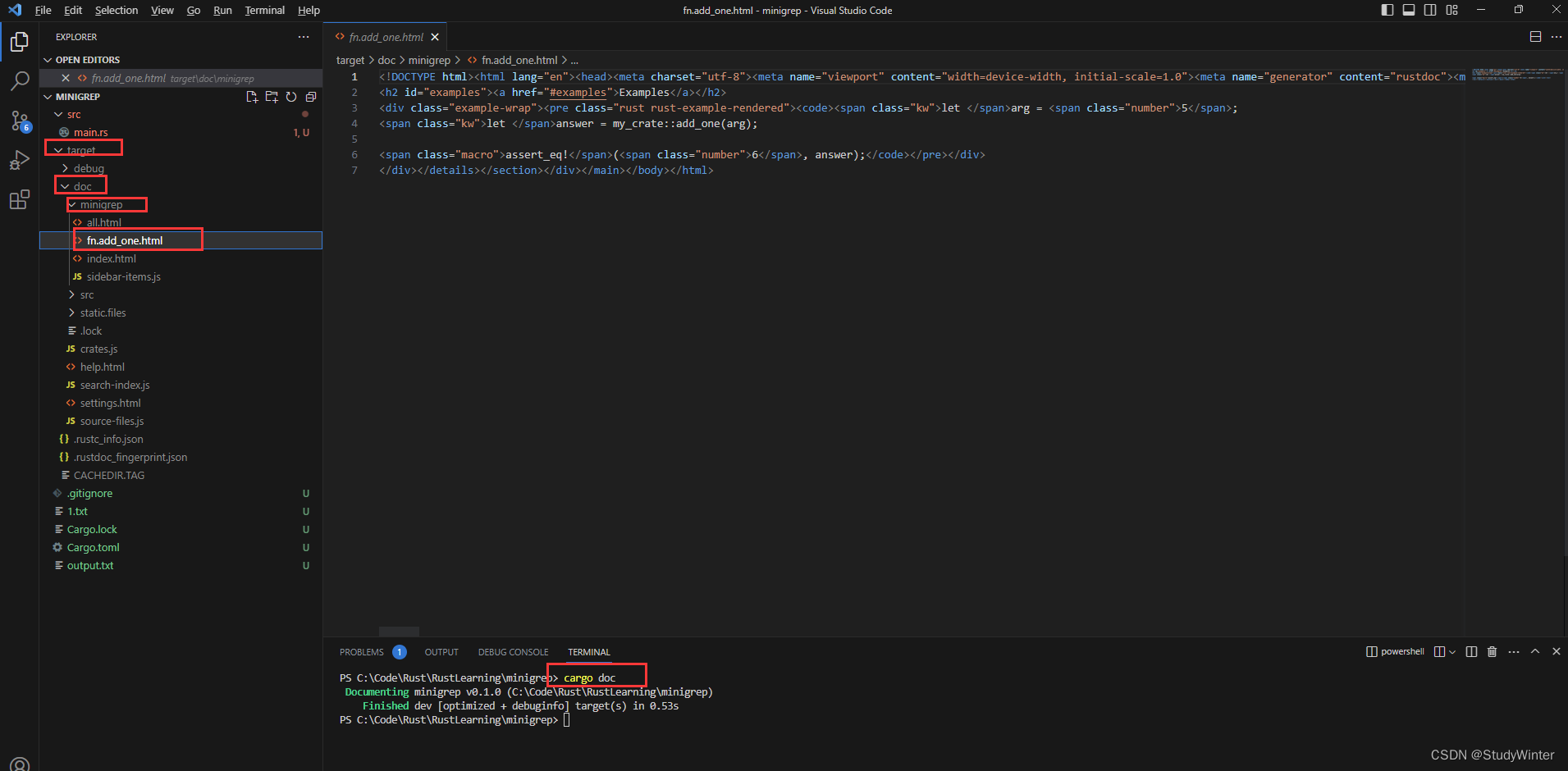
为了方便起见,运行 cargo doc --open 会构建当前 crate 文档(同时还有所有 crate 依赖的文档)的 HTML 并在浏览器中打开。导航到 add_one 函数将会发现文档注释的文本是如何渲染的,
输入命令后,浏览器自动打开。
常用(文档注释)部分
其他一些 crate 作者经常在文档注释中使用的部分有:
- Panics:这个函数可能会
panic!的场景。并不希望程序崩溃的函数调用者应该确保他们不会在这些情况下调用此函数。 - Errors:如果这个函数返回
Result,此部分描述可能会出现何种错误以及什么情况会造成这些错误,这有助于调用者编写代码来采用不同的方式处理不同的错误。 - Safety:如果这个函数使用
unsafe代码(这会在第十九章讨论),这一部分应该会涉及到期望函数调用者支持的确保unsafe块中代码正常工作的不变条件(invariants)。
文档注释作为测试
在文档注释中增加示例代码块是一个清楚的表明如何使用库的方法,这么做还有一个额外的好处:cargo test 也会像测试那样运行文档中的示例代码!没有什么比有例子的文档更好的了!也没有什么比不能正常工作的例子更糟的了,因为代码在编写文档时已经改变。
注释包含项的结构
还有另一种风格的文档注释,//!,这为包含注释的项,而不是注释之后的项增加文档。这通常用于 crate 根文件(通常是 src/lib.rs)或模块的根文件为 crate 或模块整体提供文档。
作为一个例子,如果我们希望增加描述包含 add_one 函数的 my_crate crate 目的的文档,可以在 src/lib.rs 开头增加以 //! 开头的注释
//! # My Crate
//!
//! `my_crate` 是一个使得特定计算更方便的
//! 工具集合
/// 将给定的数字加一。
// --snip--
注意 //! 的最后一行之后没有任何代码。因为他们以 //! 开头而不是 ///,这是属于包含此注释的项而不是注释之后项的文档。在这个情况中,包含这个注释的项是 src/lib.rs 文件,也就是 crate 根文件。这些注释描述了整个 crate。
使用pub use 导出合适的公有API
公有 API 的结构是你发布 crate 时主要需要考虑的。crate 用户没有你那么熟悉其结构,并且如果模块层级过大他们可能会难以找到所需的部分。
好消息是,即使文件结构对于用户来说 不是 很方便,你也无需重新安排内部组织:你可以选择使用 pub use 重导出(re-export)项来使公有结构不同于私有结构。重导出获取位于一个位置的公有项并将其公开到另一个位置,好像它就定义在这个新位置一样。
例如,假设我们创建了一个描述美术信息的库 art。这个库中包含了一个有两个枚举 PrimaryColor 和 SecondaryColor 的模块 kinds,以及一个包含函数 mix 的模块 utils(lib.rs)
//! # Art
//!
//! 一个描述美术信息的库。
pub mod kinds {
/// 采用 RGB 色彩模式的主要颜色。
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// 采用 RGB 色彩模式的次要颜色。
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// 等量的混合两个主要颜色
/// 来创建一个次要颜色。
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
SecondaryColor::Orange
}
}
fn main() {}
cargo doc 所生成的 crate 文档
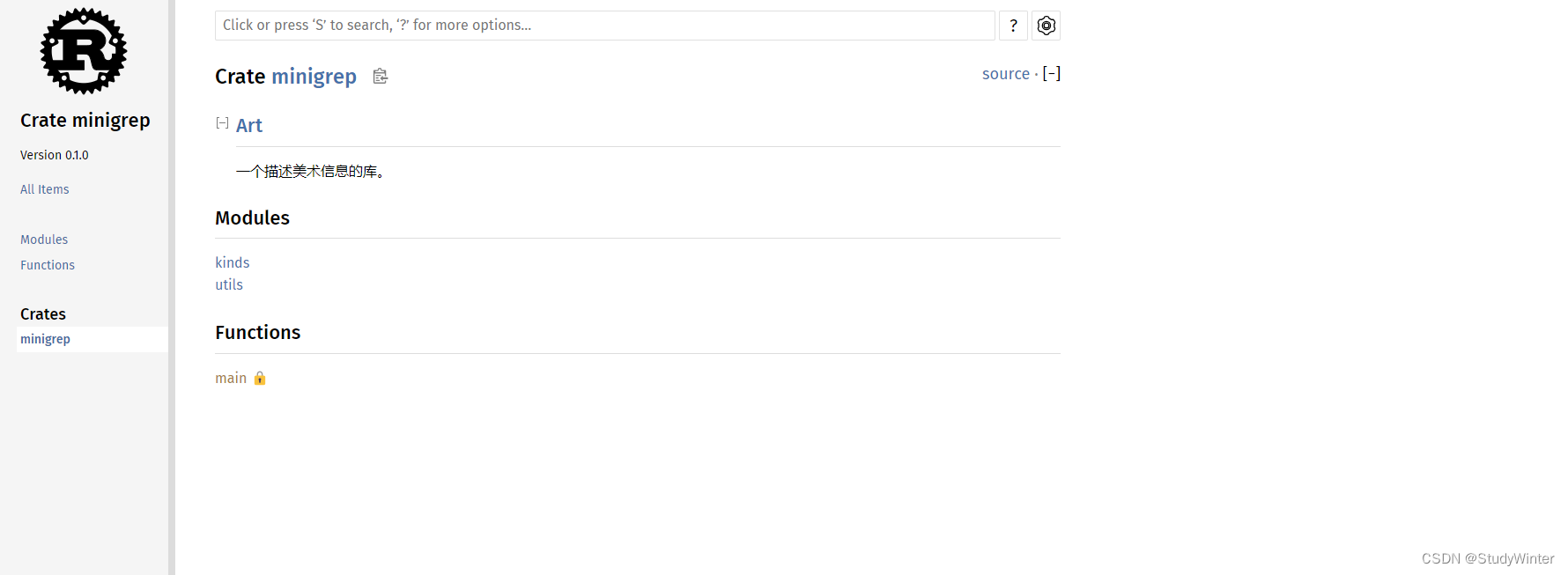
注意 PrimaryColor 和 SecondaryColor 类型、以及 mix 函数都没有在首页中列出。我们必须点击 kinds 或 utils 才能看到他们。
另一个依赖这个库的 crate 需要 use 语句来导入 art 中的项,这包含指定其当前定义的模块结构。示例展示了一个使用 art crate 中 PrimaryColor 和 mix 项的 crate 的例子:(main.rs)
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}
示例中使用 art crate 代码的作者不得不搞清楚 PrimaryColor 位于 kinds 模块而 mix 位于 utils 模块。art crate 的模块结构相比使用它的开发者来说对编写它的开发者更有意义。其内部的 kinds 模块和 utils 模块的组织结构并没有对尝试理解如何使用它的人提供任何有价值的信息。art crate 的模块结构因不得不搞清楚所需的内容在何处和必须在 use 语句中指定模块名称而显得混乱和不便。
为了从公有 API 中去掉 crate 的内部组织,我们可以增加 pub use 语句来重导出项到顶层结构(lib.rs)
//! # Art
//!
//! 一个描述美术信息的库。
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
}
pub mod utils {
// --snip--
}

创建Crates.io账号
在你可以发布任何 crate 之前,需要在 crates.io 上注册账号并获取一个 API token。为此,访问位于 crates.io 的首页并使用 GitHub 账号登陆。(目前 GitHub 账号是必须的,不过将来该网站可能会支持其他创建账号的方法)一旦登陆之后,查看位于 https://crates.io/me/ 的账户设置页面并获取 API token。
发布新crate 之前
发布到Crates.io
使用cargo yank 从 Crates.io 撤回版本
14.3 Cargo工作空间
随着项目开发的深入,库 crate 持续增大,而你希望将其进一步拆分成多个库 crate。对于这种情况,Cargo 提供了一个叫 工作空间(workspaces)的功能,它可以帮助我们管理多个相关的协同开发的包。
创建工作空间
工作空间 是一系列共享同样的 Cargo.lock 和输出目录的包。让我们使用工作空间创建一个项目 —— 这里采用常见的代码以便可以关注工作空间的结构。有多种组织工作空间的方式;我们将展示一个常用方法。我们的工作空间有一个二进制项目和两个库。二进制项目会提供主要功能,并会依赖另两个库。一个库会提供 add_one 方法而第二个会提供 add_two 方法。这三个 crate 将会是相同工作空间的一部分。让我们以新建工作空间目录开始:
$ mkdir add
$ cd add
接着在 add* 目录中,创建 Cargo.toml 文件。这个 Cargo.toml 文件配置了整个工作空间。它不会包含 [package] 或其他我们在 Cargo.toml 中见过的元信息。相反,它以 [workspace] 部分作为开始,并通过指定 adder 的路径来为工作空间增加成员,如下会加入二进制 crate:
[workspace]
members = [
"adder",
]
接下来,在 add 目录运行 cargo new 新建 adder 二进制 crate:
$ cargo new adder
Created binary (application) `adder` project
到此为止,可以运行 cargo build 来构建工作空间。add 目录中的文件应该看起来像这样:

工作空间在顶级目录有一个 target 目录;adder 并没有自己的 target 目录。即使进入 adder 目录运行 cargo build,构建结果也位于 add/target 而不是 add/adder/target。工作空间中的 crate 之间相互依赖。如果每个 crate 有其自己的 target 目录,为了在自己的 target 目录中生成构建结果,工作空间中的每一个 crate 都不得不相互重新编译其他 crate。通过共享一个 target 目录,工作空间可以避免其他 crate 多余的重复构建。
在工作空间中创建第二个crate
接下来,让我们在工作空间中指定另一个成员 crate。这个 crate 位于 add-one 目录中,所以修改顶级 Cargo.toml 为也包含 add-one 路径:
[workspace]
members = [
"adder",
"add-one",
]
接着新生成一个叫做 add-one 的库:
$ cargo new add-one --lib
Created library `add-one` project
现在 add 目录应该有如下目录和文件:
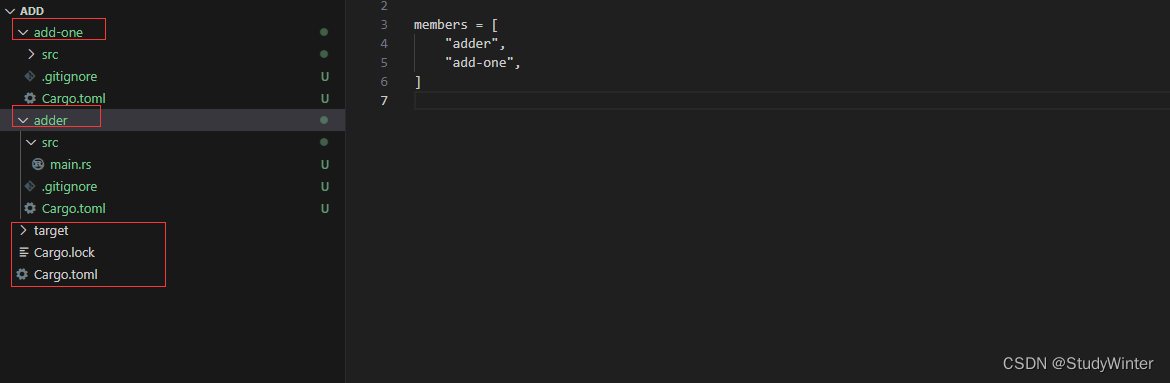
在 add-one/src/lib.rs 文件中,增加一个 add_one 函数:
文件名: add-one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
现在工作空间中有了一个库 crate,让 adder 依赖库 crate add-one。首先需要在 adder/Cargo.toml 文件中增加 add-one 作为路径依赖:
文件名: adder/Cargo.toml
[dependencies]
add-one = { path = "../add-one" }
cargo并不假定工作空间中的Crates会相互依赖,所以需要明确表明工作空间中 crate 的依赖关系。
接下来,在 adder crate 中使用 add-one crate 的函数 add_one。打开 adder/src/main.rs 在顶部增加一行 use 将新 add-one 库 crate 引入作用域。接着修改 main 函数来调用 add_one 函数
文件名: adder/src/main.rs
use add_one;
fn main() {
let num = 10;
println!("Hello, world! {} plus one is {}!", num, add_one::add_one(num));
}
在 add 目录中运行 cargo build 来构建工作空间!
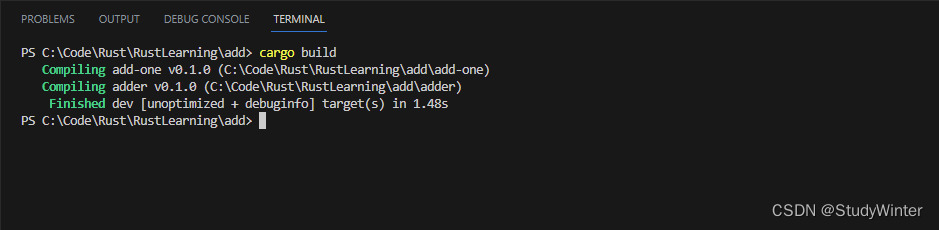
为了在顶层 add 目录运行二进制 crate,需要通过 -p 参数和包名称来运行 cargo run 指定工作空间中我们希望使用的包:

在工作空间中依赖外部crate
还需注意的是工作空间只在根目录有一个 Cargo.lock,而不是在每一个 crate 目录都有 Cargo.lock。这确保了所有的 crate 都使用完全相同版本的依赖。如果在 Cargo.toml 和 add-one/Cargo.toml 中都增加 rand crate,则 Cargo 会将其都解析为同一版本并记录到唯一的 Cargo.lock 中。使得工作空间中的所有 crate 都使用相同的依赖意味着其中的 crate 都是相互兼容的。让我们在 add-one/Cargo.toml 中的 [dependencies] 部分增加 rand crate 以便能够在 add-one crate 中使用 rand crate:
文件名: add-one/Cargo.toml
[dependencies]
rand = "0.5.5"
现在就可以在 add-one/src/lib.rs 中增加 use rand; 了,接着在 add 目录运行 cargo build 构建整个工作空间就会引入并编译 rand crate:
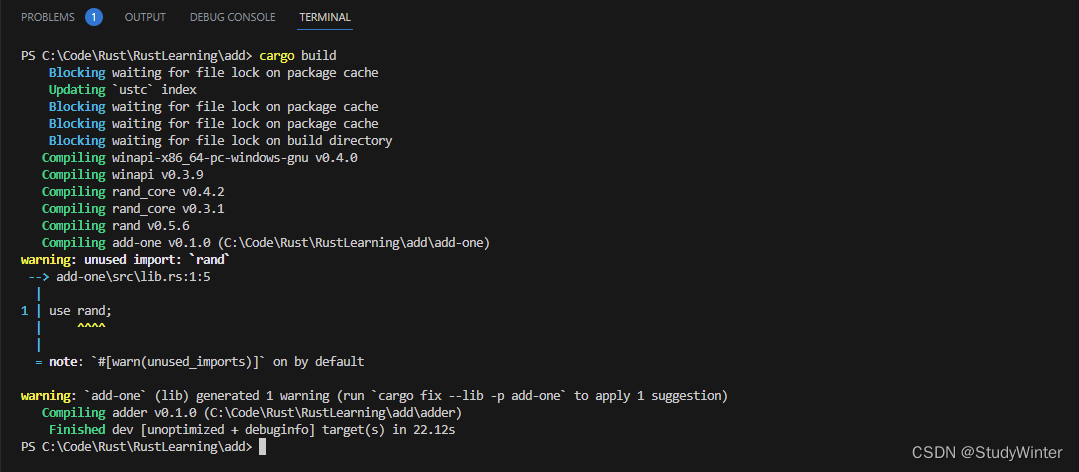
现在顶级的 Cargo.lock 包含了 add-one 的 rand 依赖的信息。然而,即使 rand 被用于工作空间的某处,也不能在其他 crate 中使用它,除非也在他们的 Cargo.toml 中加入 rand。
为工作空间增加测试
作为另一个提升,让我们为 add_one crate 中的 add_one::add_one 函数增加一个测试:
文件名: add-one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}
在顶级 add 目录运行 cargo test:
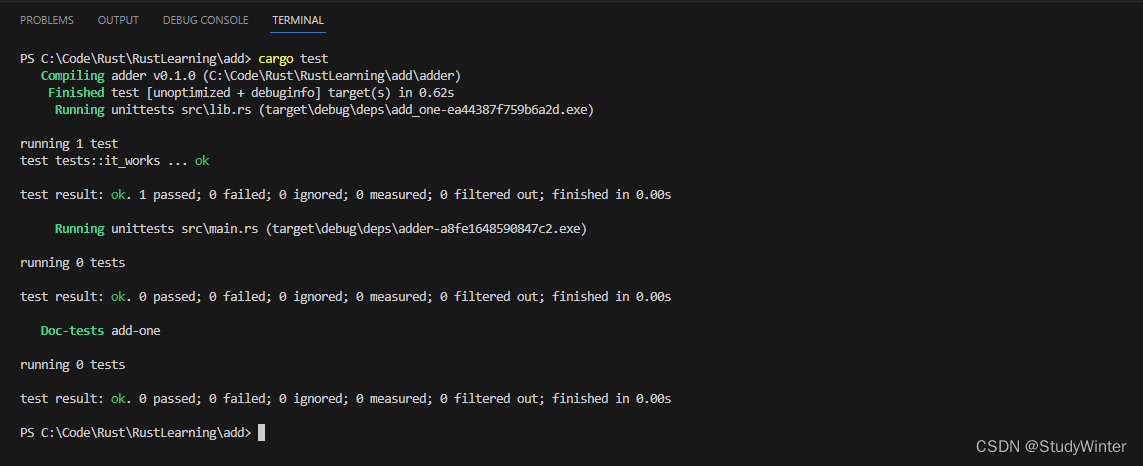
输出的第一部分显示 add-one crate 的 it_works 测试通过了。下一个部分显示 adder crate 中找到了 0 个测试,最后一部分显示 add-one crate 中有 0 个文档测试。在像这样的工作空间结构中运行 cargo test 会运行工作空间中所有 crate 的测试。
也可以选择运行工作空间中特定 crate 的测试,通过在根目录使用 -p 参数并指定希望测试的 crate 名称:
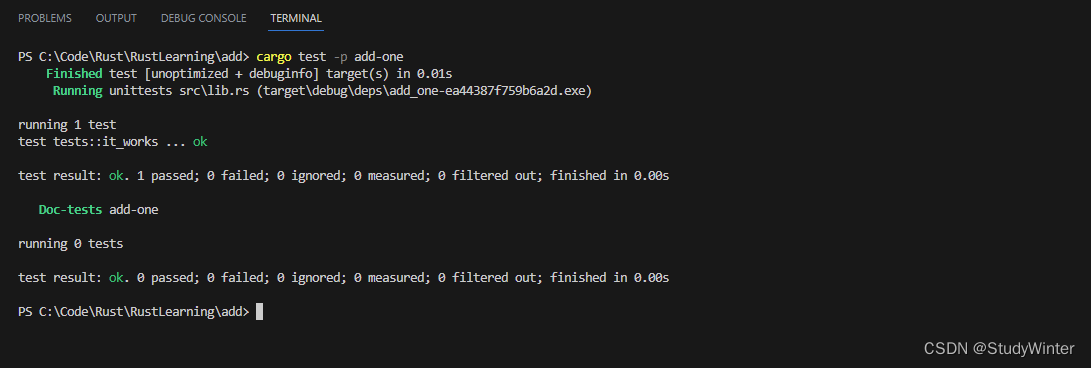
输出显示了 cargo test 只运行了 add-one crate 的测试而没有运行 adder crate 的测试。
如果你选择向 crates.io发布工作空间中的 crate,每一个工作空间中的 crate 需要单独发布。cargo publish 命令并没有 --all 或者 -p 参数,所以必须进入每一个 crate 的目录并运行 cargo publish 来发布工作空间中的每一个 crate
14.4 使用cargo install 从Crates.io安装二进制文件
cargo install 命令用于在本地安装和使用二进制 crate。它并不打算替换系统中的包;它意在作为一个方便 Rust 开发者们安装其他人已经在 crates.io 上共享的工具的手段。只有拥有二进制目标文件的包能够被安装。二进制目标 文件是在 crate 有 src/main.rs 或者其他指定为二进制文件时所创建的可执行程序,这不同于自身不能执行但适合包含在其他程序中的库目标文件。通常 crate 的 README 文件中有该 crate 是库、二进制目标还是两者都是的信息。
所有来自 cargo install 的二进制文件都安装到 Rust 安装根目录的 bin 文件夹中。如果你使用 rustup.rs 安装的 Rust 且没有自定义任何配置,这将是 $HOME/.cargo/bin。确保将这个目录添加到 $PATH 环境变量中就能够运行通过 cargo install 安装的程序了。
如果想要安装 ripgrep,可以运行如下:
$ cargo install ripgrep
Updating registry `https://github.com/rust-lang/crates.io-index`
Downloading ripgrep v0.3.2
--snip--
Compiling ripgrep v0.3.2
Finished release [optimized + debuginfo] target(s) in 97.91 secs
Installing ~/.cargo/bin/rg
最后一行输出展示了安装的二进制文件的位置和名称,在这里 ripgrep 被命名为 rg。只要你像上面提到的那样将安装目录加入 $PATH,就可以运行 rg --help 并开始使用一个更快更 Rust 的工具来搜索文件了!
14.5 Cargo自定义扩展命令
Cargo 的设计使得开发者可以通过新的子命令来对 Cargo 进行扩展,而无需修改 Cargo 本身。如果 $PATH 中有类似 cargo-something 的二进制文件,就可以通过 cargo something 来像 Cargo 子命令一样运行它。像这样的自定义命令也可以运行 cargo --list 来展示出来。能够通过 cargo install 向 Cargo 安装扩展并可以如内建 Cargo 工具那样运行他们是 Cargo 设计上的一个非常方便的优点!
参考:更多关于 Cargo 和 Crates.io 的内容 - Rust 程序设计语言 简体中文版 (bootcss.com)