Perl简介
Perl 是 Practical Extraction and Report Language 的缩写,可翻译为 “实用报表提取语言”。最开始,Perl是一门文本处理语言,不过现在已经是通用的语言了。
作者吐槽其write-only,想必是因为其灵活性,同一目标下能写出差异极大的代码;Perl对awk、sed、grep和其它Perl想替代的unix工具是后向兼容的,这也导致其不易读。
CPAN("the Comprehensive Perl Archive Network"全面的Perl存档网络),Perl库集中地。
用不着知道什么特殊的指令就可以编译Perl程序,只要把它当做批处理或者shell脚本执行就可以了。
Perl的爆炸性增长很大程度上是因为那些前Unix系统程序员的渴望,他们希望从他们的‘’老家‘’带着尽可能多的东西。在Windows上工作的web设计者通常会非常开心地发现他们的 Perl程序可以不加修改地在Unix服务器上跑。Perl最初是当做一种Unix的脚本语言设计的,但是它早就移植到大多数其它操作系统里了。
java GUI吐槽
a product isn’t good until revision 3,从一个月做成的初代awt,到后来的swing
再后来还有java FX。
语言是一种抽象
汇编语言是底层物理机的最小抽象。
FORTRAN, BASIC 和 C 是汇编语言的抽象。
但它们的抽象程度不够,程序员仍然要考虑电脑的结构。
另一种思路是对问题建模而不对机器建模。早期语言如LISP和APL,前者认为所有的问题都是lists,后者认为所有的问题都algorithmic。Prolog语言将所有问题转化为一系列的决策。
语言是解决问题的工具,对待问题有不同的建模方法。
UML类图中间的留白
顶部是类名,底部是方法,中间可以认为是private的内容,所以留白了。
内置的java.lang
在所有.java文件中,默认import java.lang。
java.lang下有system类,system类下有in out err三个field,有getproperty等获取系统信息的方法。
boolean
非boolean类型不能参与逻辑运算,这与C/C++不同。
boolean类型可以参与按位运算,除了按位取反(为了避免与非运算混淆)。
random
如果无参创建random对象,则默认以当前时间作为随机种子。一个种子对应一个固定的随机序列。
数字表示法
toBinaryString()方法可以查看数的二进制形式。
将常数加上后缀L/F/D后可以赋给相应的类型。
常数可以加上前缀0/0X/0b表示八进制、十六进制、二进制。
常数中可以添加下划线,方便阅读。有一定要求,开头结尾、前缀后缀旁边不能加;不能连续加。
指数默认为double类型,如果要赋常数指数给float,需要加f后缀。
移位运算
在C中,如果对有符号数使用右移,那么将不可移植,因为不同的编译器会有不同的处理,有的是算术右移,有的是逻辑右移。
在java中,则用>>(有符号)和>>>(全补0)加以区分。
char、byte、short在移位(以及任何算术和位运算)之前会被转为int型。
原书中对于每个类型支持的所有算术/关系/逻辑运算都给出了例子。
一个还是两个=&|
= & | 这三个符号在一个和两个时数量是不同的,如果误用了,Java会给compile error。
基本类型转型
Java中,除了boolean,其它所有类型都可以转型。窄转需要显式说明。
浮点转整数默认截断,想四舍五入要调用round。
goto,for与switch
goto是java的保留字,但java不支持goto。
java有for each 和 for in(for : ),冒号后可以是数组名,也可以是python式的range。
java的switch支持字符串和枚举类型。
default
default在java中被用作关键字,表示接口的默认方法(在声明接口时就写好了函数的内容,实现类可以无需覆写就能使用)。
this自动做第一个参数
对于非静态的方法,会自动把this作为第一个输入参数。
gc细节
最朴素简单的一种gc就是引用计数。当有引用指向它的时候,引用计数+1;离开作用域或者被置为null的时候计数-1。
基于引用计数的gc没有用于任何实用的JVM。一是有循环引用的问题,解决循环引用需要很高昂的代价。二是维护引用计数的开销。
第二种gc,我的理解是,live object traversal。从栈和静态存储区出发,被reference引用到的是活对象,被活对象引用的也是活对象。这种思路解决了循环引用问题,因为自环不会被遍历到。
实用的策略是适应性策略(我对它的理解就是复合策略,在不同的系统状态下采取不同的策略,因时制宜)。
在找到所有live object后,策略之一叫stop-and-copy,即把所有live object复制到新的heap中,老heap直接全部回收。这样可以一次性解决所有碎片(变得compact)。还需要有一个新旧地址映射表,以确保搬移后对象对对象的引用仍是正确的。
stop-and-copy的问题在于,一个是导致最大可用内存变少了,二是在没有新垃圾产生或新垃圾较少的时候,复制操作是不必要的开销。
如果发现,系统处于没有新垃圾产生或新垃圾较少的状态,那么采用mark-and-sweep会很快(而不是只用stop-and-copy单一策略或只用mark-and-sweep单一策略,这就叫adaptive)。其做法是,在live object traversal的过程中,给活对象做标记。遍历完成后,进行全对象遍历,如果没有标记,那就清理。
stop-and-copy和mark-and-sweep都需要停止程序运行。
考虑到objects有的存在时间长,有的存在时间短;有的obects较大,有的objects较小。对于存在时间短的对象(上次gc后才创建的新对象),将其进行stop-and-copy,其它对象则只是generation count+1。对于较大的objects,不对其进行copy,只是generation count+1。如果JVM发现各对象的存在时间都很长,那就切换到mark-and-sweep;如果JVM发现碎片化严重,那就切换到stop-and-copy。
GC优化
JIT,just-in-time compiler
其作用是将部分代码转为机器码,这样这部分代码就不需要经过JVM的解释,从而提高速度。
应当只在必要的时候使用JIT,因为JIT后的代码体积会比bytecode要大,这可能会导致缺页,反而拖慢速度。
Java hotspot的思想是,每次执行一段代码,就对其进行一次优化。这样执行次数越多的代码,执行速度就越快。
变长参数
由于不知道参数的类型和数量,要用objects[] varargs。
在需要重载时慎用变长参数。
枚举类型
public enum Spiciness{
NOT,MILD,MEDIUM,HOT,FLAMING
}
表示常量时,大写,如果有多个词,用下划线连接。
ENUM的使用如下:
Spiciness howHot = Spiciness.MEDIUM;
可以认为,每一个enum是一个有方法的类,有values、ordinal、toString方法。
for(Spiciness s:Spiciness.values()){
System.out.println(s + ",ordinal " + s.ordinal());
}
/*
NOT,ordinal 0
MILD,ordinal 1
MEDIUM,ordinal 2
HOT,ordinal 3
FLAMING,ordinal 4
*/
用dispose函数做gc不做的事
gc何时调用,以及是否会被调用,回收的顺序,都是不确定的。
如果需要显式cleanup,一般自己提供dispose方法中,写在finally子句中。书中给的例子是图形的擦除。
Each class has its own dispose() method to restore non-memory things back to the way they were before the object existed.
抽象类与接口
抽象类介于类和接口之间,一个不具体的类的实例(比如乐器)没有意义,所以不让用户实例化。
类中如果有抽象方法,那么类必须是抽象类。抽象类中可以没有抽象方法。
继承抽象类后,但凡还有抽象方法没有实现,那就还是一个抽象类。
Perhaps the most notable difference between an interface and anabstract class is the idiomatic ways the two are used. An interface typically suggests a “type of class” or an adjective, like Runnable, or
Serializable, whereas an abstract class is usually part of your class hierarchy and is a “type of thing,” like String or ActionHero.
在Java 8之前,接口中的方法默认是抽象的,接口不包含一丁点实现。
Java 8 allows both default methods and static methods. 也就是说,接口中可以指定默认实现(default methods),这样实现类可以不必实现接口中的所有方法(没实现的会采用接口中的默认实现)。这一特性的好处在于,可以向接口中添加新的方法,而不必修改其每一个实现类。利用default methods可以实现类似多继承的效果,可以从多个来源继承有实现的方法(同名也行,只要signature不同就行)。至于接口中的static方法,跟“模板方法”设计模式有关,但我没太看懂。
接口中的方法默认是public的。所以其实现类中的接口实现也是public的。
接口中可以有属性,但这些属性都是static、final的,因此无法通过实现接口来获取field。
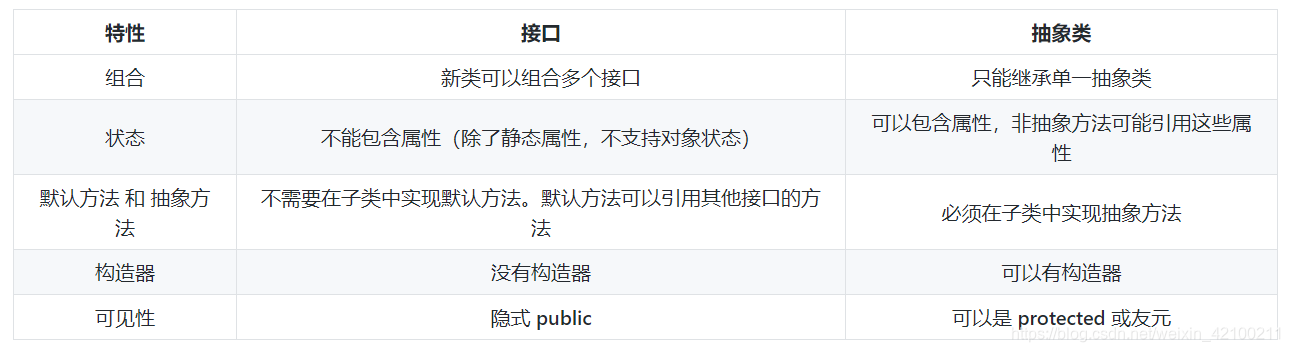
继承父类和实现接口相比,耦合更紧。
接口可以继承一或多个接口。
类中可以定义多个相关的接口(nested interface),这么做的好处我暂时没搞明白。
内部类和匿名类
内部类一般在类中,此外也可以在类的方法中。
乍一看和聚合有点像,但有区别:it knows about and can communicate with the surrounding class.
匿名函数(及其进阶“方法引用”)可以替代内部类,实现closure behavior。A closure is a callable object that retains information from the scope where it was created.
内部类也会生成.class文件,生成的.class文件名为外部类名$内部类名。
匿名内部类则会采用数字编号。
非static的内部类
非static的内部类中有包围类的引用,可以访问包围类的所有元素。使用外部类名.this可以访问到外部类;使用外部对象名.new 内部类名可以创建一个内部类对象(由此可见,非static的内部类的创建依赖于包围类的创建)。
内部类相较普通类更加特殊,可以声明为protected和private。这样的好处我暂时不明白。
类还可以在其它地方声明,如下图:

这六种情况书中有提及,但我没有深究,仅看普通匿名类。
匿名内部类
public class Parcel7 {
public Contents contents() {
return new Contents() { // Insert class definition
private int i = 11;
@Override
public int value() { return i; }
}; // Semicolon required
第二行的含义是:创建一个继承/实现自Contents的匿名类。
如果需要有参创建,在第二行和第三行小括号加入参数即可。注意,在匿名内部类中使用的参数必须是final/等效final的类型。
下面是上面的等效非匿名类实现(起了一个MyContents的类名字):
public class Parcel7b {
class MyContents implements Contents {
private int i = 11;
@Override
public int value() { return i; }
}
public Contents contents() {
return new MyContents();
}
由于匿名内部类没有名字,所以想再创建时找不到了,这种初始化方法称为实例初始化。匿名内部类的主要作用是简化代码编写。
匿名类的局限性
Anonymous inner classes are somewhat limited compared to regular inheritance, because they can either extend a class or implement an interface, but not both. And if you do implement an interface, you can only implement one.
nested class(即static的内部类)
如果不需要内外类之间的联系,可以使用static内部类,static内部类中没有外部类的引用。
Fields and methods in ordinary inner classes can only be at the outer level of a class, so ordinary inner classes cannot have static data, static fields, or nested classes.However, nested classes can
have all these.
为什么需要内部类
内部类通常继承自接口或抽象类,使用内部类跟用外部类继承接口有何区别?
Each inner class can independently inherit from an implementation. Thus, the inner class is not limited by whether the outer class is already inheriting from an implementation.
inner classes effectively allow you to inherit from more than one non-interface.
理由一是多继承。每个内部类都可以继承不同的抽象类。
The inner class can have multiple instances, each with its own state information, independent of the information in the outer class object.
理由二是每个内部类可以有多个实例,每个实例有各自的状态;
In a single outer class you can have several inner classes, each of which implements the same interface or inherits from the same class in a different way.
理由三是对于同一个接口,可以由不同的内部类做不同的实现;
There is no potentially confusing “is-a” relationship with the inner class; it’s a separate entity.
理由四感觉意思有点像聚合和继承的辨析,即外部类逻辑上不应该继承,此时可以交由内部类去继承。
理由五,可以用内部类实现回调,而不需要使用函数指针(Java不提供函数指针)。回调函数常用于GUI功能(以及其它事件驱动的场景)。
宽泛地说,内部类更加灵活。理由三(实现多个action)和理由五使得内部类适合用于事件驱动场景。
内部类的继承
The problem is that the “secret” reference to the enclosing class object must be initialized, and yet in the derived class there’s no longer a default object to attach to.
关键是,继承后,隐含的外部类引用需要挑明。
书中讨论了在外部类中继承内部类,然后在内部类子类中重写内部类方法的情况。没仔细看。
方法中的内部类(local inner class)
方法中的内部类没有可见性修饰符,因为它不是外部类的一部分;
方法中的内部类可以访问方法内的final变量,也可以访问外部类的成员。
the only justification for using a local inner class instead of an anonymous inner class is if you need a
named constructor and/or an overloaded constructor, since an anonymous inner class can only use instance initialization. Another reason to make a local inner class rather than an anonymous inner class is if you make more than one object of that class.
函数式编程
OO abstracts data, FP abstracts behavior.
平时写代码,传的参数都是数据。函数式编程,我的理解是,传的是代码,这些代码能改变接收者的行为。继续学习可知,不仅是将函数传给函数,还有对函数的各种操作,比如函数组合和函数拆分(currying)。
FP的原则是,immutable(数据不可变,所以没有并发问题), no side effect。
no side effect的进一步解释:
Values are handed to a function which then produces new values but never modifies anything external to itself(including its arguments or elements outside of that function’s scope).
这一特性可以减少很多bug。
A functional programming language manipulates pieces of code as easily as it manipulates data.
Although Java is not a functional language, Java 8 Lambda Expressions and Method References allow you to program in a functional style.
在Java 8之前,一般通过策略模式或者匿名内部类来实现函数式编程。
interface Strategy {
String approach(String msg);
}
class Soft implements Strategy {
public String approach(String msg) {
return msg.toLowerCase() + "?";
}
}
class Unrelated {
static String twice(String msg) {
return msg + " " + msg;
}
}
class Strategize {
Strategy strategy;
String msg;
Strategize(String msg) {
strategy = new Soft(); // [1]
this.msg = msg;
}
void communicate() {
System.out.println(strategy.approach(msg));
}
void changeStrategy(Strategy strategy) {
this.strategy = strategy;
}
public static void main(String[] args) {
Strategy[] strategies = {
new Strategy() { // [2]
public String approach(String msg) {
return msg.toUpperCase() + "!";
}
},
msg -> msg.substring(0, 5), // [3]
Unrelated::twice // [4]
};
Strategize s = new Strategize("Hello there");
s.communicate();
for(Strategy newStrategy : strategies) {
s.changeStrategy(newStrategy); // [5]
s.communicate(); // [6]
}
}
}
代码中,[2]是内部类,[3]是匿名表达式,[4]是方法引用。
上面的main函数调用了四个策略,分别是默认策略soft,和234。
匿名表达式的基本语法
箭头左侧是参数,右侧是被return的表达式。箭头可以读作“produce”。
方法引用的基本语法
双冒号左边是类名或对象名,右边是方法名。
可以认为匿名表达式是一个函数(而不是往常那样,一切皆类)。
只有一个参数时,参数的括号可以省略(如上面的代码)。
如果想写多行,需要在大括号内写return语句。
匿名表达式也可以先声明再使用(此时其类型为接口,也不再匿名,使用时通过表达式名字.接口方法()来调用)。
匿名表达式也可以写递归。
除了上面例子中的用法,方法引用也可以(实际上,作者用了must这个词,而不是“可以”。作者补充说,只要能确保编译器能获取到参数的类型即可。在上面的例子中并没有先声明再使用,因为msg已知是string类型)先声明再使用。此时其类型也为接口(作者说,这有点不可思议,Java 8允许我们将函数直接赋给interface,尽管内部还是由编译器将匿名表达式和方法引用包装成了实现了该接口的类的一个实例。正因编译器做了这些事情,才起到了简化代码的作用。这种interface称为functional interface也就是函数式接口,里面有且仅有一个方法,作用就是提供参数和返回值的类型信息。callable和runnable似乎都是函数式接口)。
上面的代码中引用了类的静态方法,也可以引用对象的普通方法,也可以引用类的普通方法(称为UnboundMethodReference,unbound指的是没有引用具体对象的方法)。
方法引用也可以引用构造函数,细节略。
runnable
thread的构造函数需要一个runnable接口的实现。上面代码中的匿名内部类、匿名表达式和方法引用都可以作为thread构造函数的参数。
对于内置的函数式接口(参见java.util.functional)的命名,书中举了大量例子(如ToIntFunction、Supplier),细节略。如果将方法引用赋给内置的函数式接口,则自动具有此接口的方法。文中还讲解了如何写自己的函数式接口(比如BiFunction无法满足的超过两个参数的情况)。
闭包与回调
(在内部类的章节好像提过)
闭包(Closure)是一种能被调用的对象,它保存了创建它的作用域的信息(比如内部类会保留外部类的reference)。
回调允许客户类通过内部类引用来调用其外部类的方法。
高阶函数
就是能产生函数的函数。比如,高阶函数的返回值可以是一个匿名表达式。高阶函数没有存在的必要,直接用匿名表达式就行了。
如果想返回一个使用外部参数的函数,需要语言支持闭包。
local variables referenced from a lambda expression must be final or effectively final。
接口继承接口可以算是接口重命名的一种方法。
curry函数(curry为人名)有点像高阶函数,其作用是把多参数的函数转为一系列单参数的函数。
// Curried function:
Function<String, Function<String, String>> sum =
a -> b -> a + b; // [1]
System.out.println(uncurried("Hi ", "Ho"));
Function<String, String>
hi = sum.apply("Hi "); // [2]
System.out.println(hi.apply("Ho"));
// Partial application:
Function<String, String> sumHi =
sum.apply("Hup ");
System.out.println(sumHi.apply("Ho"));
System.out.println(sumHi.apply("Hey"));
effectively final
To be “effectively final” means you could apply the final keyword to the variable declaration without changing any of the rest of the code.
如果能加上final修饰,并且不修改其它地方的代码,仍能通过编译,就算等效final。
函数组合 function composition
有java.util.function的支持,也是函数式编程的一部分。
static Function<String, String>
f1 = s -> {
System.out.println(s);
return s.replace('A', '_');
},
f2 = s -> s.substring(3),
f3 = s -> s.toLowerCase(),
f4 = f1.compose(f2).andThen(f3);
在这个例子中,执行f4相当于依次执行f2、f1、f3。
static Predicate<String>
p1 = s -> s.contains("bar"),
p2 = s -> s.length() < 5,
p3 = s -> s.contains("foo"),
p4 = p1.negate().and(p2).or(p3);
在这个例子中,p4相当于 (!p1 && p2) || p3。
函数式编程语言如scala,可以嵌入到Java项目中。
流
A stream is a sequence of elements that is not associated with any particular storage mechanism—indeed, we say that streams have “no storage.”
以前,我们用容器存多个对象,然后写循环去处理它们,“处理”才是核心目的。如果使用流的话,不需要声明变量,不考虑存储,也不需要显式迭代,而是专注于处理。使用流的编程风格很明显可以减少代码字数,而且更加清晰。作者大力推荐,认为这挽留了那些抛弃Java转投函数式语言Scala的程序员(据此可推断流是函数式编程的特征)。
There are three types of operations: creating streams, modifying elements of a stream ( intermediate operations), and consuming stream elements ( terminal operations).
流式操作分为创建、修改、消费三个过程。
public static void main(String[] args) {
new Random(47)
.ints(5, 20)
.distinct()
.limit(7)
.sorted()
.forEach(System.out::println);
}
System.out.println(range(10, 20).sum());
Internal iteration produces more readable code, but it also makes it easier to use multiple processors: By loosening control of how iteration happens, you can hand that control over to a parallelizing mechanism.
隐式迭代不只是易读,由于将更多工作交给了内部,反而性能更高。
Another important aspect of streams is that they are lazy, which means they are only evaluated when absolutely necessary. You can think of a stream as a “delayed list.” Because of delayed evaluation, streams enable us to represent very large (even infinite) sequences without memory concerns.
由于lazy的特性,流可以解决机器学习、统计等领域内存不足的问题。
parallel()
parallel() tells Java to try to run operations on multiple processors. It can do this precisely because we use streams—it can split the stream into multiple streams (often, one stream per processor) and run each stream on a different processor. Because we use internal iteration rather than external iteration, this is possible.
简单来说,parallel()使得流被拆分为多个流,由多个处理器处理。
对于parallel的情况,可以使用forEachOrdered(),则跟串行时结果一致。
of与generate创建流
stream.of(new Bubble(1), new Bubble(2), new Bubble(3));
所有的collections都有stream方法,将集合内容转为流;
Set<String> w = new HashSet<>(Arrays.asList(
"It's a wonderful day for pie!".split(" ")
));
w.stream()
.map(x -> x + " ")
.forEach(System.out::print);
向stream.generate()中传入supplier(一个函数式接口)的实现类,也可以创建流。
builder创建流
用stream的builder方法构建一个builder对象,往builder对象中add一些信息,再调用builder.build即可创建一个流。
class FileToWordsBuilder {
Stream.Builder<String> builder = Stream.builder();
public FileToWordsBuilder(String filePath) throws Exception {
Files.lines(Paths.get(filePath))
.skip(1) // Skip the comment line at the beginning
.forEach(line -> {
for(String w : line.split("[ .?,]+"))
builder.add(w);
});
}
Stream<String> stream() {
return builder.build();
}
public static void main(String[] args) throws Exception {
new FileToWordsBuilder("Cheese.dat").stream()
.limit(7)
.map(w -> w + " ")
.forEach(System.out::print);
}
}
iterate
Stream<Integer> numbers() {
return Stream.iterate(0, i -> {
int result = x + i;
x = i;
return result;
});
}
第一个参数是初始入参,每一轮的结果会作为下一轮的入参。
在这个斐波那契数列的例子中,i是上一个元素,x是上上个元素。
通过skip和limit方法,可以从这个流中获取一定范围内的斐波那契数。
peek调试
官方文档描述,peek主要用于调试。
FileToWords.stream("Cheese.dat")
.skip(21)
.limit(4)
.map(w -> w + " ")
.peek(System.out::print)
.map(String::toUpperCase)
.peek(System.out::print)
.map(String::toLowerCase)
.forEach(System.out::print);
/* Output:
Well WELL well it IT it s S s so SO so
*/
从注释中可以看出内部(或者叫隐式)循环。每个词都好像经过了流水线,每个map/peek就是一道工序。两者的区别在于,peek接收的是consumer类型,而map接收的是function。peek只是操作,但不返回结果。而map会将处理结果作为新的流。
元素的删除
distinct()
filter(Predictate)
noneMatch()
rangeClosed()
flatmap
如果map中的处理函数返回的是一个流,而又想接后续的步骤,此时可以将map替换为flatmap,这样返回的是流内数据类型而不是流类型。
flatmap做了两件事,首先是map,然后是flat(将流扁平化为流内的元素)。
对空流的处理
对一部分可能因空值而抛出异常的操作,将结果封装为optional类。
如findFirst返回流的第一个元素,以optional为返回类型。又如max和min(获取流中元素的最值)
对optional类调用isPresent(判空)和get(get的前提是present)来获取最终结果。
Optional.empty表示空值。
针对optional类,还封装了一些简化代码的函数,如orElseGet()。
终结操作
注意,如果没有终结操作,流是不会工作的(类似缺氧中管道没有造出口)。
toArray()
forEach(Consumer)
collect(Collector)
count()
如下面的例子中,将流的内容放进了一个TreeSet。书中还有其它例子。
somestream.collect(Collectors.toCollection(TreeSet::new));
reduce(BinaryOperator) Combining All Stream Elements
断言
断言可以通过-ea选项 enable assertion来开启。可以对包级别的开关进行控制。
此外,也可以调用classloader的setDefaultAssertionStatus方法来进行开关。
使用google guava的话,就可以避免开关的麻烦,而是始终开启。
precondition,postcondition,invariant
这三样就是DbC,design by contract的基本内容了。
这三种都是运行时的检查,与之相对的是开发阶段写好的unit test。
precondition,其实就是入参检查。
postcondition,其实就是返回前的返回值检查。
invariant的解释较为复杂。invariant是不变量的意思,但并不是constant那样,能存储的、具体的变量,而是一种不变的“性质”。比如堆性质和二叉搜索树性质。(https://stackoverflow.com/questions/112064/what-is-an-invariant)
An invariant gives guarantees about the state of the object that must
be maintained between method calls. However, it doesn’t restrain a
method from temporarily diverging from those guarantees during the
execution of the method. It just says that the state information of the
object will always obey the stated rules:
- Upon entry to the method.
- Before leaving the method.
In addition, the invariant is a guarantee about the state of the object
after construction.
比如说,建堆后(after construction)是大根堆,插入大根堆前(upon entry to the method)是大根堆,插入大根堆后(before leaving the method)还是大根堆。但插入过程中,这个性质可能暂时会被破坏。
如果precondition、postcondition、invariant成了性能瓶颈的话,取消顺序是:
操作前的性质检查 - 返回值检查 - 操作后的性质检查 - 入参检查 - 试想,如果每次插入都不会破坏性质,那么插入前或许可以不用检查性质。
- 经过单元测试后,你对自己的程序很有把握,或许可以不检查返回值。
- 如果类的成员变量是public的,那么就能通过unit test来检查运行过程中的状态,或许插入后也不用检查性质。
- 不建议取消入参检查,因为入参往往是不可控的
可以说明precondition, postcondition, invariant的另一个例子是队列:

DynamicTest
JUnit5提供的功能,简单来说就是动态生成测试代码(而不是在编辑器中把所有代码都显式写好)。应用场景之一是,同一个方法有多个版本,都需要做一样的测试。大一新生的想法是“能放进一个循环”就好了。用流和DynamicTest可以实现“循环”的效果。
TDD(测试驱动开发)
只是一种构想,先写测试,再写代码。这样可能会有更清晰的目标。
先通过功能测试,再通过健壮性测试,直到最后能通过所有预定测试。
通过这种方法来量化进度,以及保存/恢复工作现场。
这种方式的问题在于,一开始就要有一个全局认识(换言之,TDD的优点可能不是TDD本身带来的,而是你“一开始就能给出所有预定测试”的这种能力和知识带来的)。
java的benchmark比c的更复杂
根本原因在于java的运行环境更加复杂(jvm)
需要控制:
- CPU frequency
- power saving features
- other processes running on the same machine,
- optimizer options
等等。
benchmark与profile的区别
benchmark一般是用来做算法的优化(针对一个方法)
profile一般是用来寻找系统的瓶颈(针对整个系统)
通过注解调用JMH,做benchmark
JMH,全称 Java Microbenchmarking Harness
JMH是比较decent的micro-benchmark(相比Time duration)。
JMH为我们提供的BlackHole.consumeCPU(int tokens)方法,这个方法根据参数tokens线性的消耗CPU,它不会休眠,但是会真的消费CPU时间。用于帮助模拟真实的环境。
通过-jvisualvm调用VisualVM,做profile
VisualVM位于javac所在的目录。
文件非内容操作
此处从简,需要再查。如:
- 相对路径和绝对路径的转换
- 文件各属性(是否存在、大小、类型、修改时间等)的展示
- 如果FileSystems.getDefault().supportedFileAttributeViews().contains(“posix”),
可以用Files.getPosixFilePermissions()来获取权限信息。 - (临时)文件/目录的创建
- FileSystems.getDefault().getSeparator()解决正反斜杠的问题
- 一层遍历Files.newDirectoryStream(testPath).forEach(System.out::println);
- 递归遍历Files.walk(testPath).forEach(System.out::println);
- FileSystems.getDefault()还能获取磁盘根目录
- FileSystems.getDefault().newWatchService()能监视一层目录下的变化(文件的删除/添加/修改)。
- pathMatcher可以用于查找文件。有glob(专用于路径匹配的unix程序)和regex两种工作模式。
java.nio.file下有Files类,下有walkFileTree方法,可以实现遍历。其中,可以重载preVisitDirectory(), postVisitDirectory(), visitFile(), visitFileFailed()四种行为。书中给了一个递归删除文件的示例。
文件内容操作(其实就是文件读写)
- Files.readAllLines(),一次性读入内存
考虑到内存限制和实际处理范围,往往不需要全部读入。
- Files.lines(),流式处理
传统套娃io(装饰器模式)
优点和装饰器模式的优点一样,可以随心组合穿搭,比较灵活。
缺点是代码复杂,套娃。
可以用上面的readAllLines和lines替代,也可用nio替代。
所有与输入有关系的类都继承自inputStream,
所有与输出有关系的类都继承自outputStream。
inputStream或reader的所有派生类都有read方法。
outputStream或writer的所有派生类都有write方法。
inputStream各个子类的作用是,将不同的数据来源都转为“输入流”。
outputStream则相反。
FilterInputStream 和 FilterOutputStream 是用来提供装饰器类接口以控制特定输入流 InputStream 和输出流 OutputStream 的两个类。它们是所有装饰器的基类。
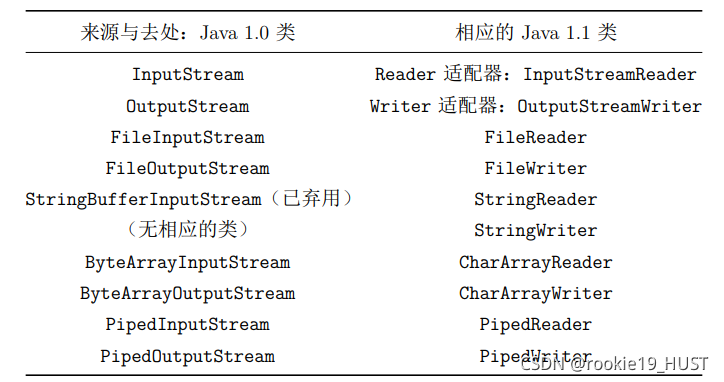
reader和writer
inputStream和outputStream是Java1.0的内容。reader和writer是Java1.1的内容。主要是添加了对Unicode的支持(一次操作16比特),方便字符IO。在字节IO的场景,仍然使用inputStream和outputStream。reader和writer不是为了替代inputStream和outputStream。
目前Unicode character set 4,都是4个字节。计划只使用17个平面(每个平面有2字节也就是65536个码位)。unicode实现的是字符和数字的一一对应。utf-8和utf-16则负责字符对应的数字的存储(在unicode层面,每个字符是平等的、等长的,但实际操作的时候肯定是采用非前缀变长编码)。

RandomAccessFile
划重点:读写一体
RandomAccessFile 适用于由大小已知的记录组成的文件,所以我们可以使用seek() 将文件指针从一条记录移动到另一条记录,然后对记录进行读取和修改。文件中记录的大小不一定都相同,只要我们能确定那些记录有多大以及它们在文件中的位置即可。
在 Java 1.4 中,RandomAccessFile 的大多数功能(但不是全部)都被 nio 中的内存映射文件(mmap)取代。
RandomAccessFile和Stream系列是独立的。
例子:基准测试决定何时开启并发
书中举了一个array setAll和array parallelSetAll的例子,
C: The number of client threads performing operations.
P: The amount of parallelism used by a parallel algorithm.
N: The size of the array: 10^(2*k), where k=1…7 is usually
enough to exercise different cache footprints.
Q: The cost of the setter operation.
N*Q (basically, the amount of work) is critical to parallel performance. With less work, the parallel algorithm may actually run slower.
也就是说,并发的优势只有在工作量足够大的时候才能体现出来。如果Q过于简单,那么N在耗尽内存之前都无法增长到一个足够大的值。
java读入的变迁
一种方法是,先用StringReader解码,然后用BufferedReader的readline。如果数据不是按行分割的,可能还需要行内split。这个过程称为input - tokenize - parse。
另一种方法是Scanner。
Scanner
除了char,基本类型(包括BigDecimal和BigInteger)都有nextXXX方法。Scanner假定IOException代表结束,因此使用Scanner时不需要捕获IOException异常。也可以显式使用其ioException()方法来手动检测此异常。Scanner可以用正则表达式来指定delimiter。
除了基本类型,Scanner可以按指定的正则表达式来读取下一个pattern。
RTTI, runtime type information
多态意在使用普适性的代码一次解决一整个族。
但偶尔难免有“特殊”需求,比如shape的经典例子中,我们添加rotate()方法,但我们希望circle不这么做。
RTTI的作用就是,指定或排除特定的子类,以这种“特殊性”与多态的“普适性”互为补充。
典型的操作是,调用Class.forName(String className),就可以在不new的情况下获取一个Class Object。
作用接近的操作是,调用className.class。也能获取一个Class Object,但不会触发类初始化。
RTTI的另一种形式是instanceof。
Class的其它方法,如获取简单/完整类名,判断是否为接口,获取父类Class,获取其实现的接口列表,获取实例newInstance()。
在java中,如果没有显式使用括号进行向下转型,则无法通过编译。此外,通过编译后,为了确保向下转型的合法性,建议使用instanceof来避免ClassCastException。
instanceof
instanceof是一个双目运算符。前面是对象,后面是类名关键字。这个类名关键字,既不能用一个内容与类名相同的字符串去指代,也不能用这个类的.class来指代,它只能是一个类名关键字(symbol)。
无法指代意味着不能用循环变量去替换。如果有类似需求,可以使用isInstance(),这个方法的参数是对象实例,方法的主体是Class类实例。
instanceof和isInstance都会追溯继承链。而getClass()后直接用==或者equals方法比较则不会追溯继承链。
// obj instanceof T
boolean result;
if (obj == null) {
result = false;
} else {
try {
T temp = (T) obj; // checkcast
result = true;
} catch (ClassCastException e) {
result = false;
}
}
反射
反射的初衷是应对多机情况,编译时.class还不在本机,运行时才传输过来。
反射可以生成.class,这一核心功能可以解决上述问题,也可用于其它场景,比如动态代理时动态生成代理类(克服静态代理时“每个接口都要写一个代理类,造成代理类过多”的问题)。
静态代理不难理解,可以起到保护代码的作用,也可以在不侵入源码的情况下增强功能(可以理解为给real object多套了一层壳,一个增强功能的例子是,在开始前和结束后打印日志)。而动态代理的必要性我目前还没有切身体会。
动态代理介绍
https://www.cnblogs.com/whirly/p/10154887.html
反射也是对象序列化的基础。
反射能在运行时获取Class对象的信息,比如一个类有哪些方法(包括其所有父类)。作者认为这可以节省查看父类代码或者看文档的时间。
Indeed, reflection and generics are required to compensate for the overconstraining nature of static typing。
通过反射,获取class后,获取declaredMethod,setAccessible(true)后invoke,可以调用protected甚至private方法。即使只发布编译后的代码,也能通过:
javap -private 类名
来获取所有方法的名称。只要有了方法名称,就能用反射调用。
内部类、匿名类中的方法亦然。
至于成员,除了final成员不会被set修改,其它的都能通过反射get和set。
反射也可以获取泛型的具体类型。getClass().getTypeParameters()。
The intent of OO programming is to use polymorphic
method calls everywhere you can, and RTTI only when you must.
为什么这么说呢?RTTI提供的特殊性,从一个角度看是补充了多态提供的普适性,从另一个角度看就是破坏了多态提供的普适性。至于反射,我个人认为破坏了继承中的可见性。
java.util.Optional
Optional的初衷是辅助stream,但也可以作为NullpointerException的一种更优雅的解决方式。思想类似数据库中,有的列可以不填。Optional,可选的,正是这个意思。
DTO的特征是,只有在构造时才能填写信息,使用时只读而不添加信息。一个DTO的例子是Person类。可以将DTO的成员变量用Optional做一个保护。比如本来是String类型,改写为Optional<String>。这样字段为空的时候也不会抛异常。
更详细的例子,以及另一种代码实践可以参考原书。
java返回多个不同类型的对象
之前初学java的时候,竟然还专门写了一篇博客。
返回不同类型的对象,用tuple<String, Integer>这样的写法即可。或者借助泛型tuple<A,B>。
泛型
感觉已经基本理解了,例子比较多,类似c++ STL,也有supplier<T>这样的例子。泛型类似无穷重载。
除了无穷重载提高代码复用率,泛型可以在编译时就检查类型,而不是运行时才发现把object转为具体类型时出错。
java 泛型的一个问题是,不支持基本类型(虽然有自动装箱和自动拆箱)。
一般建议是,
- 尽可能使用泛型
- 尽可能使用泛型方法而不是泛型类(普通类中可以有泛型方法)
Java泛型是用erasure实现的。使用泛型的时候,不包含任何具体类型信息,代码会把所有东西都当作object处理。因此List<A>和List<B>getClass()比较的结果是一样的。这与C++不同。这可以理解为类的退化,即List<A>会退化(erasure)为List。
C++会把T指定的类型替换进代码里,而Java不会,Java只会用T的bound替换进代码里。如果没有指定bound,那bound就是Object。(bound的解释:比如<? extends A>,bound就是A。指定bound的好处在于,由于你自己添加了限制确保了安全,编译器会更宽容,通过你对bound下方法的调用,否则只有对Object方法的调用才能通过编译)。这可以理解为参数类型的退化(erasure)。
这种退化设计的初衷是兼容Java 5之前的没使用泛型的库。它不是功能性的考虑,而是一种妥协。
虽然会发生退化,但类型信息也不是完全没用。指定类型信息后,编译时就会检查传入参数的类型是否为指定类型。获取泛型类返回的对象时,也不需要显式做类型转换(比如从List<String>中取对象的时候,不需要(String)来做类型转换)。编译器会自动插入类型转换的代码(转换的目标类型当然就是我们在泛型类中指定的类型)。
可以这么理解,编译时是有类型信息的,运行时都退化了。
有class Solid2<T extends Coord & HasColor & Weight>的写法。
但通配符?只能extends一个bound。
如果是super的话,只能写<? super downbound>。
网上的说法是,T用于泛型类的定义、声明,?用于泛型类的使用。
如果库函数的参数类型为List probablyDogs,那么传List<Dog>也是可以的。这就导致即使应用层程序员已经使用了泛型,也不一定能保证类型安全。解决这个问题的方法:
List<Dog> dogs2 = Collections.checkedList(
new ArrayList<>(), Dog.class);
不过我并未遇到过Java 5的库。
为什么说Java的泛型代码不好写
因为Java的泛型是反直觉的,T不会被直接替换。在泛型类代码中使用运行时类型的操作都需要替代方法。
这里只是粗略的语言描述,如果真的需要写泛型类,可以再回去看原书。
想在泛型类的代码中使用instanceof T:
直接用是不行的。error: illegal generic type for instanceof
需要在泛型类的入参中加入一个Class对象,在泛型类的成员中记录这个Class对象,然后用isInstance()。
这个Class对象被作者称为“type tag”,或者type token。
想在泛型类的代码中使用new T():
直接用是不行的。error: unexpected type
比较完备的解决方案之一是在泛型类的入参中加入一个factory对象,比如IntegerFactory implements supplier<Integer>。
另一个比较完备的解决方案是使用模板方法设计模式,在泛型类的子类中实现具体对象的创建。
想在泛型类的代码中创建T[]:
直接创建是不行的。error: generic array creation
在泛型类中添加一个ArrayList<>成员。
mixin
https://www.zhihu.com/question/20778853/answer/16166094
传统的「接口」概念中并不包含实现,而 Mixin 包含实现。实际上 Mixin 的作用和 Java 中的众多以「able」结尾的接口很相似。不同的是 Mixin 提供了(默认)实现,而 Java 中实现了 -able 接口的类需要类自身来实现这些混入的功能(Serializable 接口是个例外)。
array是否有必要使用
结论:arrayList内部借助array实现。平时直接用arrayList即可。
由于collections通过autobox也能支持原始类型,array唯一的优势就是性能了。不过array和arrayList的性能差距往往根本不造成问题。
Enumeration
enum Shrubbery { GROUND, CRAWLING, HANGING }
enum可以理解为关键字,Shrubbery是类名,里面的是对象名。里面的对象都是static final的。
整数值遵循声明顺序(从0开始)。这一特性可以用于责任链设计模式(责任链有点像快递自动分拣,与流水线的区别在于不一定会经过所有工序,可能在某一工序后就完成了)。工序在前的先声明。
enum具有有限性,因此其另一个用途是有限状态机。
enum可以用于switch语句。
所有的enum类都继承自Enum类,并且都是final的。因此不能让enum类继承其它类,也没有类能继承enum类。
enum的扩展(增加枚举种类或是子类型)
由于enum不能被继承,一个替代方案是,声明一个接口,将多个enum类放在接口的定义中。比如Food接口,enum类实现Food接口。需要扩展的时候,就声明新的实现Food接口的enum类。
另一个方案是,enum of enums,即枚举成员是enum类。
EnumSet和EnumMap
性能很高,对标int[]。
原理是连续存储,存储顺序按enum类内的顺序。
EnumSet可以用来替代flag。EnumSet是基于long实现的。支持集合运算。
EnumMap可以用于命令模式(以一个枚举变量为key,以方法为value)。
enum的遍历
for(Shrubbery s : Shrubbery.values())
需要注意的是,values并不是Enum中的方法,所以如果将enum类向上转型,就不能使用values()方法。但可以使用Class类的getEnumConstants()方法。
values是编译器插入的static方法。
enum转为数字
s.ordinal()
获取enum中成员名称
s.name()
获取成员所在的enum类名
s.getDeclaringClass()
enum之间的比较
s.compareTo(Shrubbery.CRAWLING)
s.Equals(Shrubbery.CRAWLING)
用String[]建立Enum
for(String s :“HANGING CRAWLING GROUND”.split(" ")) {
Shrubbery shrub =
Enum.valueOf(Shrubbery.class, s);
System.out.println(shrub);
}
enum和普通类的相似性
enum类同样可以有方法,主要用途之一就是增加一些补充信息(比如增加有参构造函数让enum对象内含成员字符串),重写toString()的行为等。
enum实现多重派发multiple dispatching
多重派发理解有一定难度,而且百度得到的资料很烂。
https://en.wikipedia.org/wiki/Double_dispatch
这个维基,直接看C++例子,两种小行星和两种飞船之间的碰撞。由于两种小行星互为父子类,两种飞船互为父子类,我们需要运行时类型(因为参数的静态类型是父类,不知道实际参数是父类还是子类)才能精确确认碰撞结果。
也可以看原书石头剪刀布的例子。
这两个例子的共同特点就是,事件的结果跟参数和calling object两者的运行时类型都有关系。
按照平时的写法,calling object的运行时类型会被区分(也就是动态绑定,多态的基础)。但参数的运行时类型不会被区分。
用visitor设计模式解决这个场景(两个对象相互作用)的问题。在一个运算数的处理方法中,调用另一个运算数的处理方法(另一个运算数的处理方法以这一个运算数的this为入参),这样就能确保双方的运行时类型都参与处理过程。
第一次决策取决于calling object的动态类型,由于calling object的处理函数中调用了入参实例的方法(以calling object为入参),第二次决策就会受calling object的运行时类型影响。
用enum可以简化第二次决策,在calling object的处理函数中用switch,做出第二次决策。或者在calling object的处理函数中用EnumMap。
enum适合需要画表的场景(比如,石头剪刀布问题可以抽象为一个3x3的表格)。
java并发编程
开篇讲的是并发concurrency和并行parallelism的区别。
相似性在于都用thread来实现。
区别在于设计理念和初衷。
并发通过合理调度减少block等待时间,解决IO-bound。
并行通过拆分任务、增加计算资源来解决compute-bound。
并发能带来优化的前提是存在等待(不局限于io等待)。
UI如果不用并发的话,未响应会严重影响体验。
Clojure、Scala、Frege可以在jvm运行。它们更适合并发编程。除了jvm能运行的,还可以通过foreign function interface(FFI)来使用其它天然并发语言。哪怕我们不显式创建thread而是用其它语言代替,我们也无法避免并发,因为平时常用的很多库是并发的。作者建议,并发编程永远不要过度自信,尽可能调知名库,尽可能少写自己的代码。
作者说了一大堆,围绕着这一句:Java will never be a language designed for concurrency, but simply a language that allows it.
关于一门编程语言的发展,作者打了一个这样的比方:气体,液体,固体。
一开始是热情奔放而自由的,后来则有了越来越多的限制。
作者强烈建议使用最新的、最高层的并发写法,比如parallel stream和completableFutures。前者data-oriented,适合同构数据的简单拆分(配合spliterator使用);后者task-oriented,适合不同的任务。
还有一些推荐常用的,比如atomic系列,concurrentLinkedDeque,ExecutorService,ArrayBlockingQueue。
虽然一个对象在完成之前并不可见,但构造函数并不是线程安全的。比如类中有一个static计数器用于统计实例总数,类成员中包含id,单线程下不会有重复id,而多线程则会有很多重复的id。
书中举了一个例子,即使构造函数本身没有share任何变量,构造函数的参数可能share了,导致在不知情的状况下出现了线程安全问题。一个解决方法是用工厂方法,然后给工厂方法加锁。其实也可以直接把构造函数的代码放在synchronized块里。
java的Thread对象比普通对象要大得多,通常几千个Thread就会OOM。
这是因为,Thread对象需要较大的空间:
- 程序计数器
- Java代码栈
- native代码栈
- thread-local变量
- 线程管理变量
workstealingpool(工作窃取线程池)
允许已经耗尽输入队列中的工作项的线程从其他队列 “窃取” 工作项。
异常处理
线程如果抛异常,会导致线程死亡。
Thread类有成员UncaughtExceptionHandler。原书有相关factory和默认handler设定的套路代码,来解决thread抛出的异常。
synchronized基本用法
synchronized方法
把共享资源封装在一个类里,让其为private,只能通过方法来访问。在这些访问方法上添加synchronized关键字,则在其返回前,其它的调用会被阻塞。
每一个访问共享资源的方法都需要被同步(前提是,private。否则都是空中楼阁)。
synchronized代码块
使用前提是,块外的代码是线程安全的。
synchronized(syncObject) {
// This code can be accessed
// by only one task at a time
}
显式锁基本用法
java.util.concurrent.locks.*
主要方法包括lock,unlock。结合try finally使用,代码量较synchronized大。
但能做到一些更特别的事情,比如ReentrantLock,可以在tryLock()之后放弃,也可以规定tryLock2秒后放弃。
其它组件
delayQueue,可以放延时任务。队列top是一个已经到期的、到期最久的元素。
设计模式
从变化中寻找不变,抽象出来,就成了设计模式。
避免牵一发而动全身,将修改限制在一个小范围内。
把经常变化的部分和不变的部分分开。
另一种观点是,设计模式是语言失败的体现(因为这说明,相应场景没有直接的语言支持,而是需要一些trick)
单例模式,精髓是不对外暴露构造函数
代理模式,状态模式
代理模式就是给real object套壳,状态模式就是在代理模式的基础上提供一个替换real object的方法。
代理模式的四个用途:
- 远程代理,RMI
- 虚拟代理,创建时只有壳,实际使用时才创建real object
- 保护代理,不对外暴露real object
- 智能引用,比如统计一个方法被调用的次数
工厂模式,
可以将反射用于工厂模式,给一个类名字符串,利用反射获取其构造函数。
策略模式,
有点像状态模式,但real object是具体的算法类。
到现在我算是看明白了,设计模式一般就是加层,加抽象。这样才能解耦,解变与不变之间的耦。
原书附录:软件设计
加层箴言:All software design problems can be simplified by introducing an extra level of conceptual indirection.
java不怕类多(除了Thread类),如果需要就可以建。比如,一个switch太长,可以考虑用多态。高内聚,说的是一个类做一件事,不能太复杂。
控制参数列表长度。如果你发现一个都不能少,那可能是方法所处的位置不合适。
不要复制粘贴自己的代码段,如果需要多次使用,就应该封装为方法。
继承时默念is a,添加成员时默念has a。
多用聚合,少用继承。
尽量避免将方法声明为final来改善性能,除非这真的是瓶颈。
如果两个类耦合很紧,可以考虑将其中一个作为另一个的内部类。
避免premature optimization。先跑起来验证设计,再优化性能。
一个简单但容易被忽视的道理是,方法越长,越不好维护。
如果你做sdk,那把一个东西设为public后就不能回头了。
构造函数里最好少做点事情,容易出问题。
将所有的清扫工作放在dispose()中,并设置一个boolean flag,表示dispose()是否执行过。
如果一个对象需要gc以外的清扫,创建过后紧跟try-finally。
如果finalize()需要继承基类finalize(),在末尾调用super.finalize(),确保需要用到基类内容的时候仍然可用。
如果collection是定长的,可以调用toArray()后再返回。
原书附录: javadoc
javadoc xxx.java
常用的tag:
- @see (链接跳转)
- @author
- @version
- @since (自xx版本后的新feature)
- @param
- @return
- @throws
- @Deprecated (Java5后代替了@deprecated)
书中给了一个简单的Demo。
原书附录:传引用
java中的都是引用。如果方法会修改入参,称之为side effect。
有人喜欢纠结Java到底是引用传递还是值传递,但做这样的区分,背后的价值其实就是副作用的问题,就是入参是否会被修改。
区分值传递和引用传递的依据是,变量本身是否有被克隆。值传递会克隆变量本身。引用传递则只是传递你变量的地址,而不是复制一份变量的内容。
java中,基本类型是值传递的,而对象类型就见仁见智了,取决于对Java对象的理解。Object在堆上的内容没有被复制,但地址值本身被复制了。
建议不要修改入参。如果有需要,可以clone()一份后再操作。需要注意的是,Object的clone()是protected的,如果需要使用,需要override为public的(内容直接调用super.clone()即可,或者自己实现)。
clone()
ArrayList的clone是浅拷贝。我感觉我之前对浅拷贝的理解有问题。
首先需要强调的是,clone确实会产生一个新的Object,会在堆上创建新内容。clone前后用==判断是不相等的,说明实际指向的堆地址不同。
但用equals、hashcode、toString都是相等的,对其中一个List的元素进行遍历increment后另一个list中的元素也会变。这是因为,两个list中的内容是同一批引用。这批引用,以及引用中的引用,一直递归下去,都没有被clone。
这是合理的,因为无法确保表层以下的类是否是cloneable的。
clone()是Object的方法(实际操作是判断实际需要的空间大小,分配空间,然后bitwise拷贝)。有关类需要同时满足实现cloneable和override public clone两个条件。
实际使用时,对于clone的返回值需要(downcast)。需要try-catch CloneNotSupportedException。
如果有深拷贝的需求,在super.clone()后调用内容物的clone()即可。
深拷贝的另一个方式是利用序列化,打散后再重建,得到的是一个内容相同的Object。但性能上有量级差距。
序列化
序列化是一种更高级的抽象(相比把数据存到文件或数据库),自此可以将一个对象声明为“持久对象”。
序列化能弥补操作系统之间的差异,却不必担心数据在不同机器上的表示会
不同,也不必关心宇节的顺序或者其他任何细节。
序列化是一种轻量级的持久化,因为不能用某种 “persistent”(持久)关
键字来简单地定义一个对象,并让系统自动维护其他细节问题。需要显式序列化和反序列化。如果需要个更严格的持久性机制,可以考虑像 Hibernate 之类的工具。
序列化的两个主要用途,第一是RMI,第二是Java Beans。
Serializable跟cloneable一样,也是一个空接口,仅用于标记。
在对一个 Serializable 对象进行还原的过程中,没有调用任何构造器,包括默认的构造器。整个对象都是通过从 InputStream 中取得数据恢复而来的。
最基本的demo包括objectOutputStream和writeObject方法的调用,以及相应的逆过程。
有时候我们需要“部分序列化”。序列化会将private数据保存下来。也许要考虑特殊的安全问题,你不希望对象的某一部分被序列化;或者一个对象被还原以后,某子对象需要重新创建,从而不必将该子对象序列化。
非默认序列化
这是一种白名单的“部分序列化”,没有任何东西会自动序列化,全部都需要显式指定。
可以通过实现Externalizable而非Serializable来实现对序列化过程的控制。
Externalizable继承了Serializable,添加了readExternal和writeExternal方法。这两个方法会在序列化和反序列化还原的过程中被自动调用,以便执行一些特殊操作。
与默认的反序列化不同,对于一个 Externalizable 对象,所有普通的默认构造器都会被调用(包括在字段定义时的初始化),然后调用 readExternal()。
Externalizable的一种替代方案是在Serializable对象中实现readObject和writeObject,只要我们提供了这两个方法,就会自动使用它们而不是默认的序列化机制。
transient
“部分序列化”也有黑名单的做法,可以用 transient(瞬时)关键字逐个字段地关闭序列化,它的意思是 “不用麻烦你保存或恢复数据——我自己会处理的”。
xml序列化
对象序列化的一个重要限制是它只是 Java 的解决方案:只有 Java 程序才能反序列化这种对象。
XML是一个更加通用的方案。
使用XOM类库(如nu.xom)即可。
重定向输入输出与执行外部程序
System.setOut()
Process process = new ProcessBuilder(command.split(" ")).start();
equals()和hashcode()重载
@Override
public boolean equals(Object rval) {
return rval instanceof Animal &&
// Objects.equals(id, ((Animal)rval).id) && // [1]
Objects.equals(name, ((Animal)rval).name) &&
Objects.equals(size, ((Animal)rval).size);
}
@Override
public int hashCode() {
return Objects.hash(name, size);
// return Objects.hash(name, size, id); // [2]
}
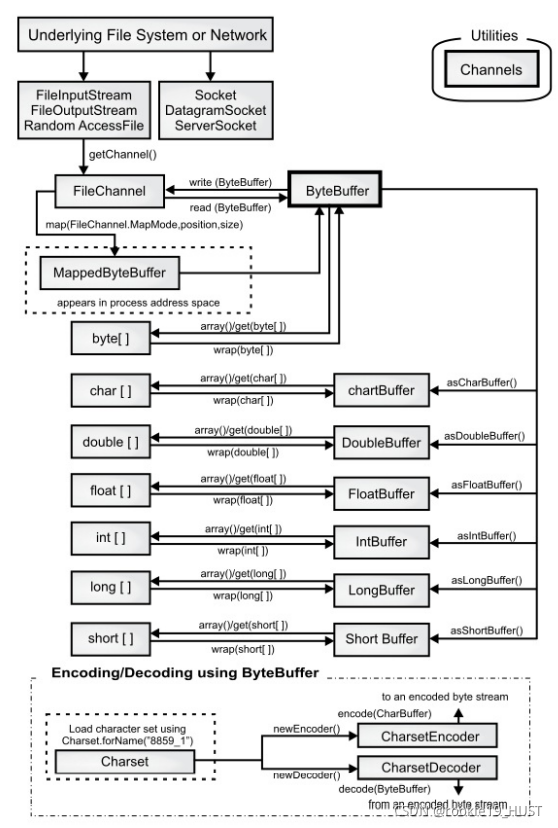
nio
Java1.4,重点是非阻塞。调用channel的map方法比经典流io要快十至百倍。
nio的核心是channel,buffer,selector。
channel就像矿井,buffer就像矿车。必须通过矿车才能跟矿井交互。
buffer的三个关键属性,capacity,limit,position。有读写模式之分。
capacity即容量,position即当前读/写进度,limit是最多能写/读多少。对于写来说,最多把buffer写满。对于读来说,最多把已经写入的所有内容读完。
flip()函数将写模式调整为读模式,实际行为就是limit=position,position=0。
hasRemaining()会检查position和limit之间的距离。
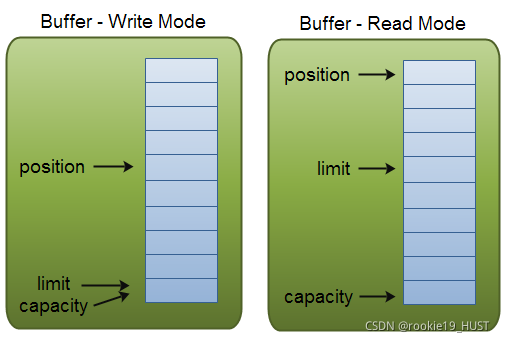
其它常用函数此处省略。
selector允许一个线程处理多个channel。
下图中,只写了FileChannel,但右边network三样也有对应的channel。
语言未来
由于 JVM,Java 使得取代自己变得更加容易。现在有可能会有人创建一种新语言,并使其在短时间内像 Java 一样高效运行。以前,为新语言开发一个正确有效的编译器需要花费大部分开发时间。
这种情况已经发生了,包括像 Scala 这样的高级静态语言,以及动态语言,新的且可移植的,如 Groovy,Clojure,JRuby 和 Jython。这是未来,并且过渡很顺畅,因为可以很轻易地将这些新语言与现有 Java 代码结合使用,并且必要时可以重写那些在 Java中的瓶颈。
在撰写本文时,Java 是世界上的头号编程语言。然而,Java 最终将会减弱,就像C++ 一样,沦只在特殊情况下使用(或者只是用来支持传统的代码,因为它不能像 C++那样和硬件连接)。