Author:AXYZdong 硕士在读 工科男
有一点思考,有一点想法,有一点理性!
定个小小目标,努力成为习惯!在最美的年华遇见更好的自己!
CSDN@AXYZdong,CSDN首发,AXYZdong原创
唯一博客更新的地址为: 👉 AXYZdong的博客 👈
B站主页为:AXYZdong的个人主页
AI专栏
- ⭐⭐⭐【AI常用框架和工具】(点击跳转)
包括常用工具Numpy、Pandas、Matplotlib,常用框架Keras、TensorFlow、PyTorch。理论知识结合代码实例,常用工具库结合深度学习框架,适合AI的初学者入门。
文章目录
- AI专栏
- 1 什么是机器学习
- 1.1 机器学习概念
- 1.2 机器学习、人工智能和深度学习关系
- 1.3 机器学习的发展史
- 1.4 机器学习应用场景
- 2 机器学习分类
- 2.1 机器学习算法划分
- 2.2 机器学习一般过程
- 2.3 常见算法
- 3 基本术语和概念
1 什么是机器学习
1.1 机器学习概念

- 历史数据训练,得出模型算法
- 新的数据输入到模型算法,进行预测得出未知属性
1.2 机器学习、人工智能和深度学习关系

交叉的领域
- 微积分(偏导数、向量-值函数、方向梯度)
- 概率论(贝叶斯定理、组合学、抽样方法)
- 计算科学
- 凸分析
- 算法复杂度
1.3 机器学习的发展史
- 1950,阿兰·图灵创造了“图灵测试”。
- 1957,Frank Rosenblatt设计出第1个计算机神经网络一感知机。
- 1981,Gerald Dejong提出基于解释的学习(ExplanationBased Learning,EBL)这一概念。
- 1990年代机器学习的方法从知识驱动转为数据驱动。
- 2016,谷歌的人工智能算法打败了围棋专业选手。
1.4 机器学习应用场景
属性预测,价值评估,客户分层,异常检测,疾病检测,风险管理,个性化推荐,垃圾信息识别,智能排序,等级评分,流失预警,文本识别,图像识别,量化交易分析,用户画像,路径优化,店铺选址,资源优化,作诗作歌词,恶意软件识别,精准营销,智能投顾搜索优化,诈骗检测,关联匹配等等。
2 机器学习分类
2.1 机器学习算法划分
- 监督学习(Supervised Learning)
- 回归(Regression)
- 分类(Classification)
- 半监督学习(Semi-supervised Learning)
Training Data有少量的Labelled data和大量的Unlabeled data。
在半监督学习的技术中,这些没有label的data,它们可能也是对学习有帮助。 - 无监督学习(Unsupervised Learning)
没有任何label,机器可以无师自通。 - 强化学习(Reinforcement Learning)
又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
有监督:是指在未加标签的数据中,根据数据本身之间的属性对数据进行分类,相似相近的数据分在同一类;不相似或不相近的数据分在不同的类中。
无监督:通过已知数据以及其对应的输出来训练,得到一个最优模型,再利用这个模型将所有新的数据样本映射为相应的输出结果,对输出结果进行简单的判断从而实现分类。
2.2 机器学习一般过程
-
数据采集
通过爬虫、API和数据库的方式进行数据收集。 -
数据处理
特征选择、预处理以及将其转换为对于机器学习算法有益处的格式。 -
算法选择
从机器学习的算法开始,将训练数据的算法特征应用到算法中。 -
结果实施
训练、评估、参数选择、模型使用。
强化学习训练过程:

2.3 常见算法
- 有监督学习常见算法
- 线性回归
- 决策树
- 逻辑回归
- SVM
- 装袋算法
- 随机森林
- KNN
- 朴素贝叶斯
- 集成算法系列
- GBDT
- 无监督学习常见算法
- K-Means
- K-Mediods
- DBSCAN
- Aprior
- FP-Growth
3 基本术语和概念
-
数据集
训练集\验证集\测试集
训练模型的数据集合 -
样本/示例
行Record
一个事件或对象 -
属性/特征
列 feature
性质 -
样本空间
属性长成的空间 -
训练数据/训练样本
模型训练 -
学习/训练
从数据集中学
得模型的过程 -
模型/学习器
训练后的结果 -
目标函数
算法学习后得到的
参数、阀值、比例等构成的函数 -
模型评价
评估模型性能优劣过程 -
损失函数/代价函数
评估原始数据与预
测数据差距的函数
评估模型效果 -
偏差:算法的期望预测与真实值之间的偏差程度,反映了模型本身的拟合能力。
-
方差:方差度量了同等大小训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。
-
泛化能力:机器学习的目标是使学得的模型能够很好地适用于新的样本,而不是仅仅在训练样本上工作的很好,学得的模型适用于新样本的能力称为泛化能力。
-
误差:学习到的模型在样本上的预测结果与样本的真实结果之间的差。
- 训练误差:在训练集上
- 泛化误差:在新样本上
-
过拟合和欠拟合
- 在回归问题中(从左到右:欠拟合、正常拟合、过拟合)
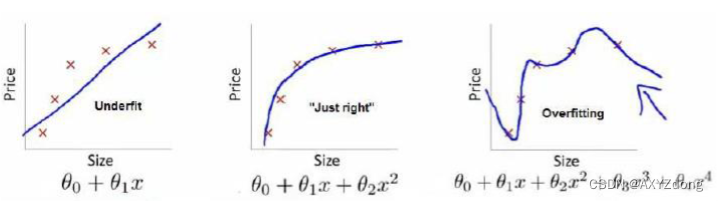
- 在分类问题中(从左到右:欠拟合、正常拟合、过拟合)
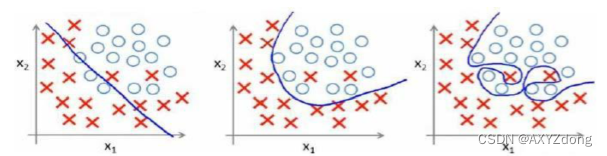
- 在回归问题中(从左到右:欠拟合、正常拟合、过拟合)
Reference
- [1] https://connect.huaweicloud.com/courses/learn/Learning/sp:cloudEdu_?courseNo=course-v1:HuaweiX+CBUCNXE086+Self-paced&courseType=1
—— END ——
如果以上内容有任何错误或者不准确的地方,欢迎在下面 👇 留言。或者你有更好的想法,欢迎一起交流学习~~~
更多精彩内容请前往 AXYZdong的博客