第四阶段
时 间:2023年8月17日
参加人:全班人员
内 容:
基于metrics-server弹性伸缩
目录
一、Kubernetes部署方式
(一)minikube
(二)二进制包
(三)Kubeadm
二、基于kubeadm部署K8S集群
(一)环境准备
(二)部署kubernetes集群
(三)安装Dashboard UI
(四)metrics-server服务部署
(五)弹性伸缩
一、Kubernetes部署方式
官方提供Kubernetes部署3种方式
(一)minikube
Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,尝试Kubernetes或日常开发的用户使用。不能用于生产环境。
官方文档:Install Tools | Kubernetes
(二)二进制包
从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。目前企业生产环境中主要使用该方式。
下载地址:
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.11.md#v1113
(三)Kubeadm
Kubeadm 是谷歌推出的一个专门用于快速部署 kubernetes 集群的工具。在集群部署的过程中,可以通过 kubeadm init 来初始化 master 节点,然后使用 kubeadm join 将其他的节点加入到集群中。
1、Kubeadm 通过简单配置可以快速将一个最小可用的集群运行起来。它在设计之初关注点是快速安装并将集群运行起来,而不是一步步关于各节点环境的准备工作。同样的,kubernetes 集群在使用过程中的各种插件也不是 kubeadm 关注的重点,比如 kubernetes集群 WEB Dashboard、prometheus 监控集群业务等。kubeadm 应用的目的是作为所有部署的基础,并通过 kubeadm 使得部署 kubernetes 集群更加容易。
2、Kubeadm 的简单快捷的部署可以应用到如下三方面:
·新用户可以从 kubeadm 开始快速搭建 Kubernete 并了解。
·熟悉 Kubernetes 的用户可以使用 kubeadm 快速搭建集群并测试他们的应用。
·大型的项目可以将 kubeadm 配合其他的安装工具一起使用,形成一个比较复杂的系统。
·官方文档:
Kubeadm | Kubernetes
Installing kubeadm | Kubernetes
二、基于kubeadm部署K8S集群
(一)环境准备
| IP地址 | 主机名 | 组件 |
| 192.168.100.131 | k8s-master | kubeadm、kubelet、kubectl、docker-ce |
| 192.168.100.132 | k8s-node01 | kubeadm、kubelet、kubectl、docker-ce |
| 192.168.100.133 | k8s-node02 | kubeadm、kubelet、kubectl、docker-ce |
注意:所有主机配置推荐CPU:2C+ Memory:2G+

1、主机初始化配置
所有主机配置禁用防火墙和selinux
[root@localhost ~]# setenforce 0
[root@localhost ~]# iptables -F
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
[root@localhost ~]# systemctl stop NetworkManager
[root@localhost ~]# systemctl disable NetworkManager
[root@localhost ~]# sed -i '/^SELINUX=/s/enforcing/disabled/' /etc/selinux/config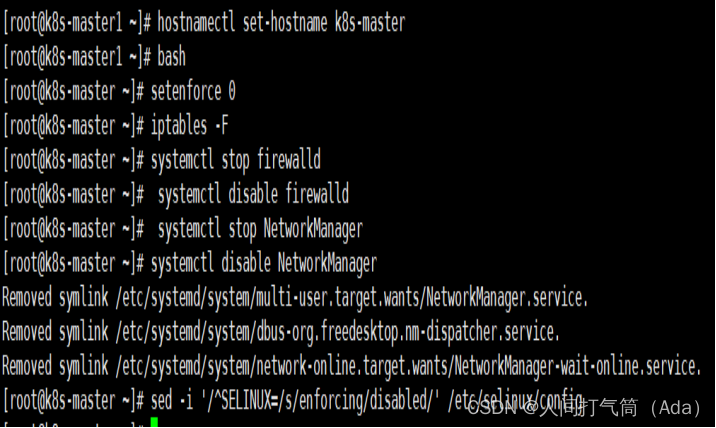
2、配置主机名并绑定hosts,不同主机名称不同
[root@localhost ~]# hostname k8s-master
[root@localhost ~]# bash
[root@k8s-master ~]# cat << EOF >> /etc/hosts
192.168.100.131 k8s-master
192.168.100.132 k8s-node01
192.168.100.133 k8s-node02
EOF
[root@localhost ~]# hostname k8s-node01
[root@k8s-node01 ~]# cat /etc/hosts

[root@localhost ~]# hostname k8s-node02
[root@k8s-node02 ~]#cat /etc/hosts

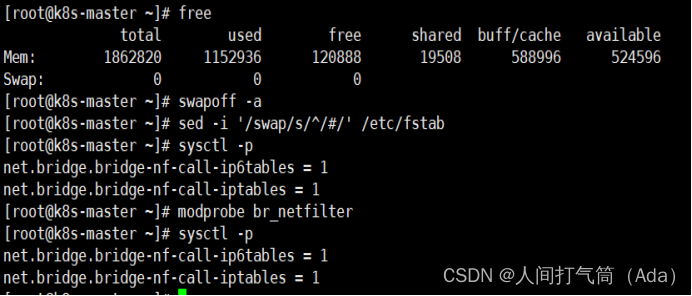
3、主机配置初始化
[root@k8s-master ~]# yum -y install vim wget net-tools lrzsz

[root@k8s-master ~]# swapoff -a
[root@k8s-master ~]# sed -i '/swap/s/^/#/' /etc/fstab
[root@k8s-master ~]# cat << EOF >> /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@k8s-master ~]# modprobe br_netfilter
[root@k8s-master ~]# sysctl -p
4、部署docker环境
1)三台主机上分别部署 Docker 环境,因为 Kubernetes 对容器的编排需要 Docker 的支持。
[root@k8s-master ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@k8s-master ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
2)使用 YUM 方式安装 Docker 时,推荐使用阿里的 YUM 源。
[root@k8s-master ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
3)清除缓存
[root@k8s-master ~]# yum clean all && yum makecache fast
4)启动docker
[root@k8s-master ~]# yum -y install docker-ce
[root@k8s-master ~]# systemctl start docker
[root@k8s-master ~]# systemctl enable docker
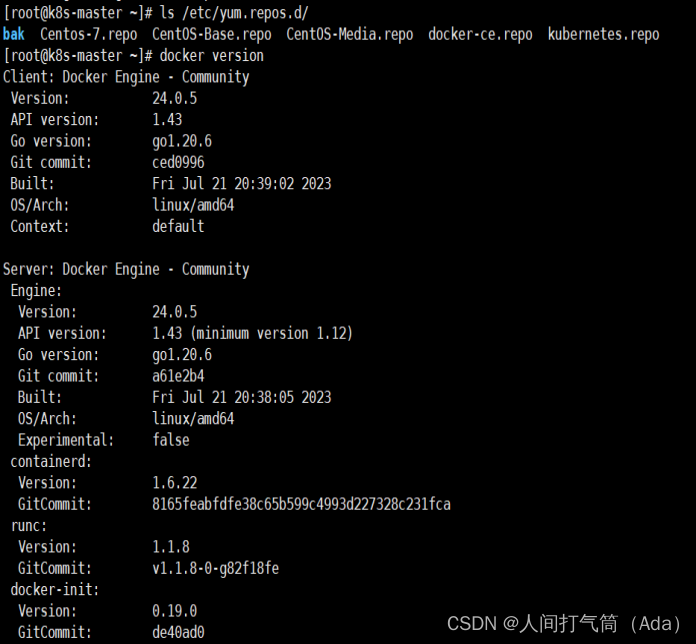
5)镜像加速器(所有主机配置)
[root@k8s-master ~]# cat << END > /etc/docker/daemon.json
{ "registry-mirrors":[ "https://nyakyfun.mirror.aliyuncs.com" ]
}
END
6)重启docker
[root@k8s-master ~]# systemctl daemon-reload
[root@k8s-master ~]# systemctl restart docker
(二)部署kubernetes集群
三个节点都需要安装下面三个组件
kubeadm:安装工具,使所有的组件都会以容器的方式运行
kubectl:客户端连接K8S API工具
kubelet:运行在node节点,用来启动容器的工具
使用 YUM 方式安装 Kubernetes时,推荐使用阿里的 YUM 源。
[root@k8s-master ~]# ls /etc/yum.repos.d/
[root@k8s-master ~]# cat > /etc/yum.repos.d/kubernetes.repo

3、安装kubelet kubeadm kubectl
所有主机配置
[root@k8s-master ~]# yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0

[root@k8s-master ~]# systemctl enable kubelet

[root@k8s-master ~]# kubectl version
kubelet 刚安装完成后,通过 systemctl start kubelet 方式是无法启动的,需要加入节点或初始化为 master 后才可启动成功。
Kubeadm 提供了很多配置项,Kubeadm 配置在 Kubernetes 集群中是存储在ConfigMap 中的,也可将这些配置写入配置文件,方便管理复杂的配置项。Kubeadm 配内容是通过 kubeadm config 命令写入配置文件的。
在master节点安装,master 定于为192.168.100.131,通过如下指令创建默认的init-config.yaml文件:
[root@k8s-master ~]# kubeadm config print init-defaults > init-config.yaml

init-config.yaml配置
[root@k8s-master ~]# cat init-config.yaml

5、安装master节点
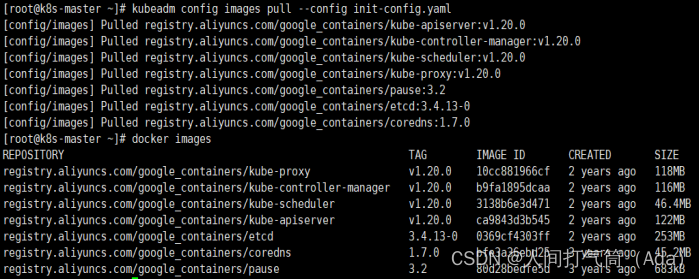
1)拉取所需镜像
[root@k8s-master ~]# kubeadm config images list --config init-config.yaml
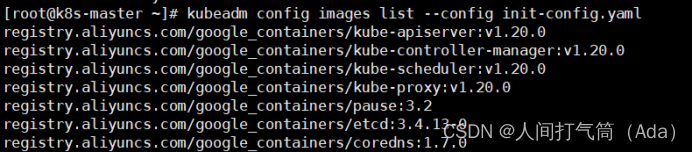
[root@k8s-master ~]# kubeadm config images pull --config init-config.yaml
2)安装matser节点
[root@k8s-master ~]# kubeadm init --config=init-config.yaml //初始化安装K8S
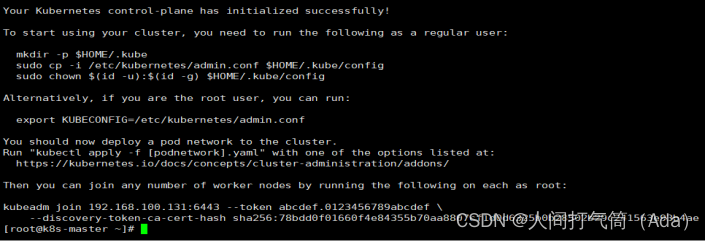
3)根据提示操作
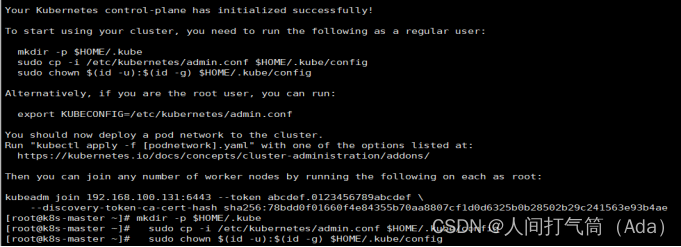
kubectl 默认会在执行的用户家目录下面的.kube 目录下寻找config 文件。这里是将在初始化时[kubeconfig]步骤生成的admin.conf 拷贝到.kube/config
[root@k8s-master ~]# mkdir -p $HOME/.kube
[root@k8s-master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
Kubeadm 通过初始化安装是不包括网络插件的,也就是说初始化之后是不具备相关网络功能的,比如 k8s-master 节点上查看节点信息都是“Not Ready”状态、Pod 的 CoreDNS无法提供服务等。

6、安装node节点
1)根据master安装时的提示信息
[root@k8s-node01 ~]# kubeadm join 192.168.100.131:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:78bdd0f01660f4e84355b70aa8807cf1d0d6325b0b28502b29c241563e93b4ae
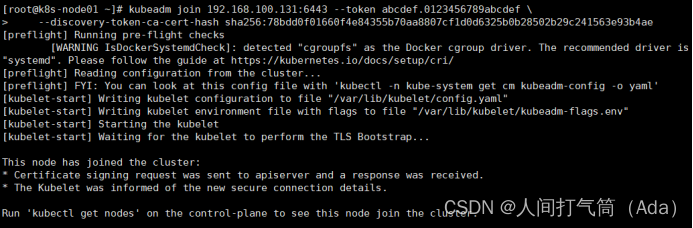
[root@k8s-master ~]# kubectl get nodes
[root@k8s-node02 ~]# kubeadm join 192.168.100.131:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:78bdd0f01660f4e84355b70aa8807cf1d0d6325b0b28502b29c241563e93b4ae
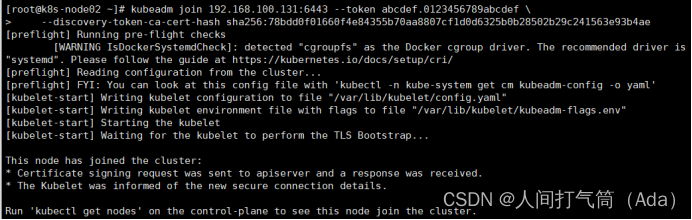
Master操作:
[root@k8s-master ~]# kubectl get nodes

前面已经提到,在初始化 k8s-master 时并没有网络相关配置,所以无法跟 node 节点通信,因此状态都是“NotReady”。但是通过 kubeadm join 加入的 node 节点已经在k8s-master 上可以看到。
Master 节点NotReady 的原因就是因为没有使用任何的网络插件,此时Node 和Master的连接还不正常。目前最流行的Kubernetes 网络插件有Flannel、Calico、Canal、Weave 这里选择使用flannel。
所有主机:
master上传kube-flannel.yml,所有主机上传flannel_v0.12.0-amd64.tar,cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master ~]# docker load < flannel_v0.12.0-amd64.tar
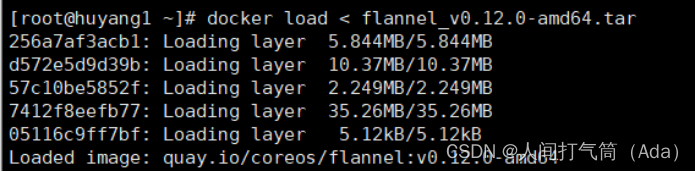
上传插件:
[root@k8s-master ~]# tar xf cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master ~]# cp flannel /opt/cni/bin/

master上传kube-flannel.yml
master主机配置:
[root@k8s-master ~]# kubectl apply -f kube-flannel.yml
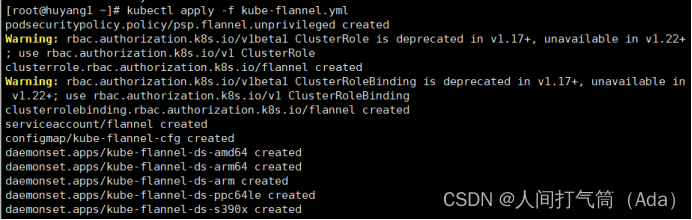
[root@k8s-master ~]# kubectl get nodes
[root@k8s-master ~]# kubectl get pods -n kube-system

已经是ready状态
(三)安装Dashboard UI
dashboard的github仓库地址:https://github.com/kubernetes/dashboard
代码仓库当中,有给出安装示例的相关部署文件,我们可以直接获取之后,直接部署即可
[root@k8s-master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended.yaml
默认这个部署文件当中,会单独创建一个名为kubernetes-dashboard的命名空间,并将kubernetes-dashboard部署在该命名空间下。dashboard的镜像来自docker hub官方,所以可不用修改镜像地址,直接从官方获取即可。
在默认情况下,dashboard并不对外开放访问端口,这里简化操作,直接使用nodePort的方式将其端口暴露出来,修改serivce部分的定义:
所有主机下载镜像
[root@k8s-master ~]# docker pull kubernetesui/dashboard:v2.0.0
[root@k8s-master ~]# docker pull kubernetesui/metrics-scraper:v1.0.4
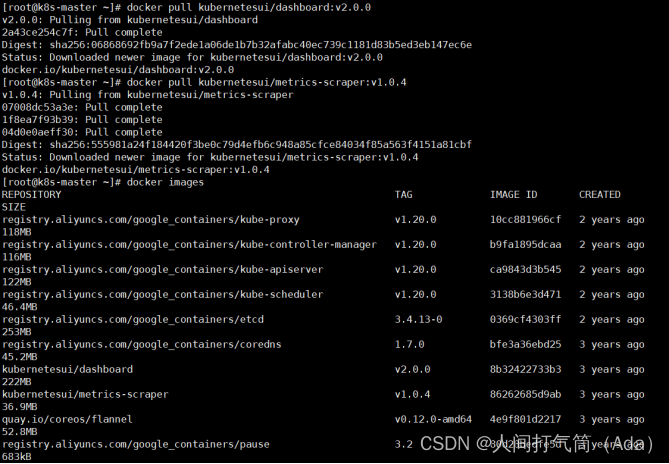
[root@k8s-master ~]# vim recommended.yaml
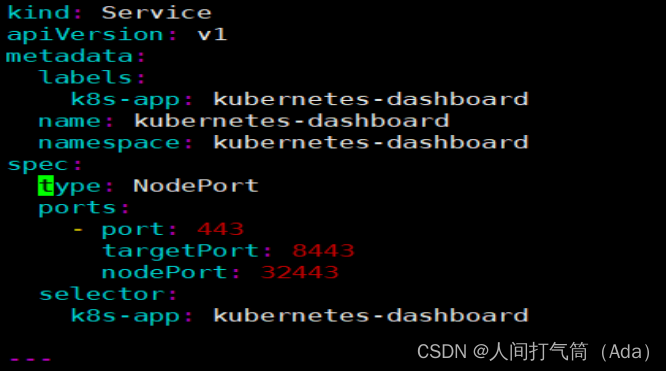
3、权限配置
配置一个超级管理员权限
[root@k8s-master ~]# vim recommended.yaml

[root@k8s-master ~]# kubectl apply -f recommended.yaml

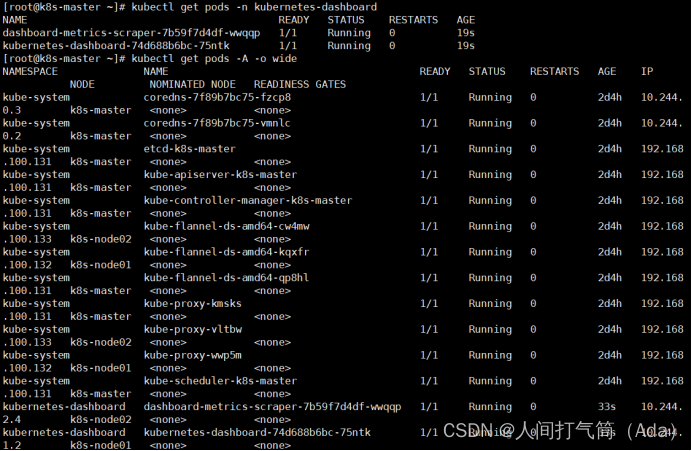
[root@k8s-master ~]# kubectl get pods -n kubernetes-dashboard
[root@k8s-master ~]# kubectl get pods -A -o wide
使用谷歌浏览器测试访问 https://192.168.100.131:32443
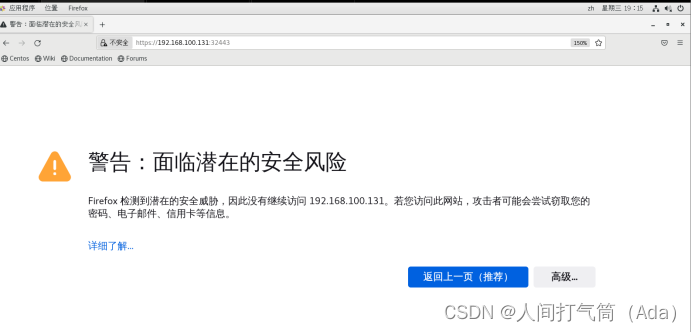

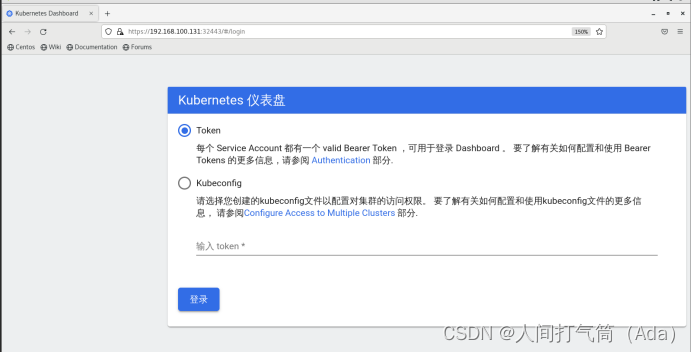
可以看到出现如上图画面,需要我们输入一个kubeconfig文件或者一个token。事实上在安装dashboard时,也为我们默认创建好了一个serviceaccount,为kubernetes-dashboard,并为其生成好了token,
我们可以通过如下指令获取该sa的token:
[root@k8s-master ~]# kubectl describe secret -n kubernetes-dashboard $(kubectl get secret -n kubernetes-dashboard |grep kubernetes-dashboard-token | awk '{print $1}') |grep token | awk '{print $2}'

输入获取的token

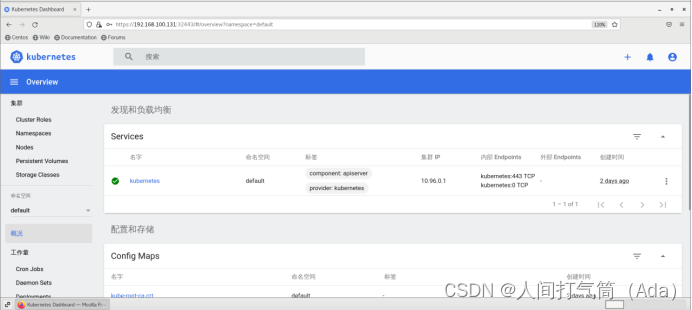
查看集群概况:
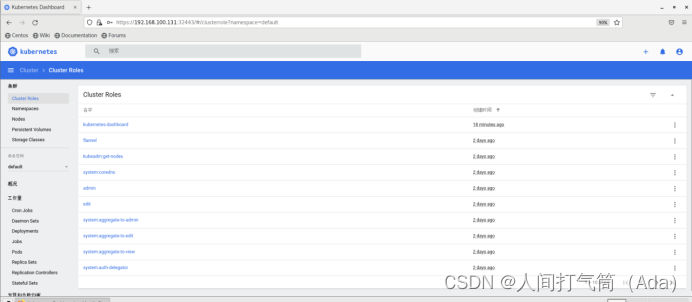
查看集群roles:
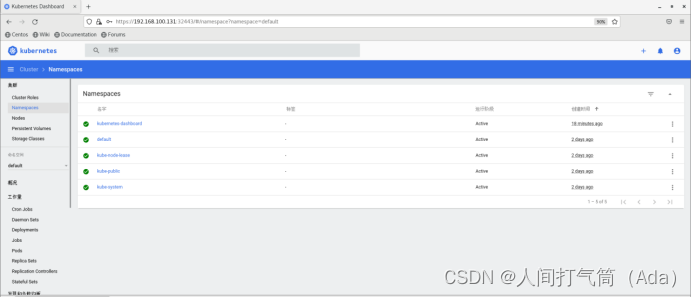
查看集群namespaces:
查看集群nodes:

查看集群pods:

(四)metrics-server服务部署
heapster已经被metrics-server取代,metrics-server是K8S中的资源指标获取工具
所有node节点上
[root@k8s-node01 ~]# docker pull bluersw/metrics-server-amd64:v0.3.6
[root@k8s-node01 ~]# docker tag bluersw/metrics-server-amd64:v0.3.6 k8s.gcr.io/metrics-server-amd64:v0.3.6

2、修改 Kubernetes apiserver 启动参数
在kube-apiserver项中添加如下配置选项 修改后apiserver会自动重启
[root@k8s-master ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml
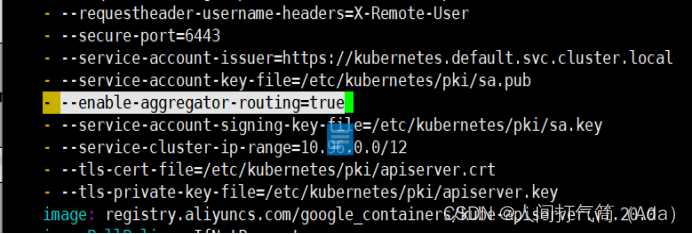
3、Master上进行部署
[root@k8s-master ~]# wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
修改安装脚本:
[root@k8s-master ~]# vim components.yaml
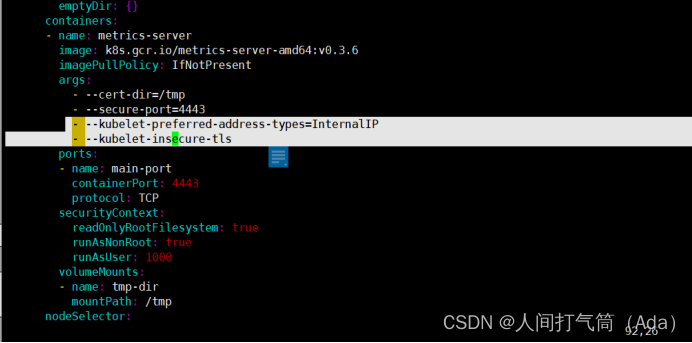
[root@k8s-master ~]# kubectl create -f components.yaml
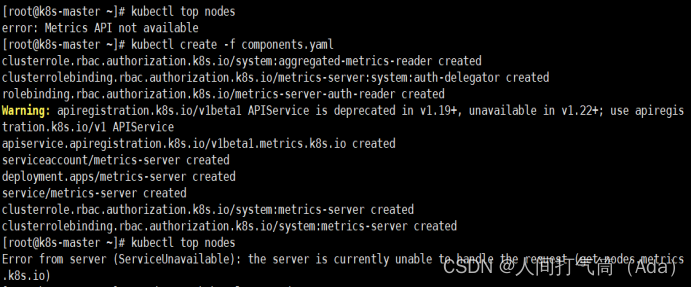
等待1-2分钟后查看结果
[root@k8s-master ~]# kubectl top nodes

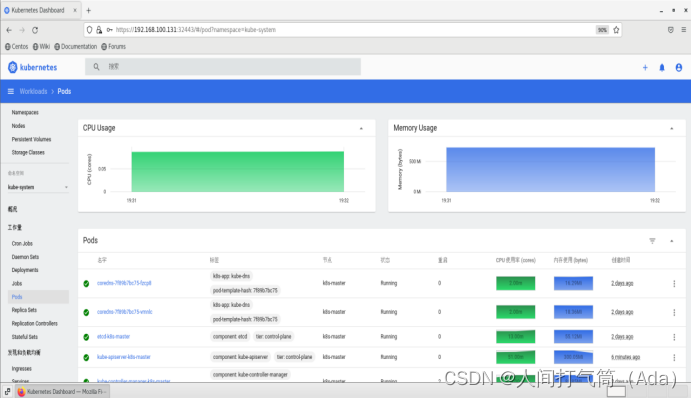
再回到dashboard界面可以看到CPU和内存使用情况了
(五)弹性伸缩
HPA(Horizontal Pod Autoscaler,Pod水平自动伸缩)的操作对象是replication controller, deployment, replica set, stateful set 中的pod数量。注意,Horizontal Pod Autoscaling不适用于无法伸缩的对象,例如DaemonSets。
HPA根据观察到的CPU使用量与用户的阈值进行比对,做出是否需要增减实例(Pods)数量的决策。控制器会定期调整副本控制器或部署中副本的数量,以使观察到的平均CPU利用率与用户指定的目标相匹配。

Horizontal Pod Autoscaler 会实现为一个控制循环,其周期由--horizontal-pod-autoscaler-sync-period选项指定(默认15秒)。
在每个周期内,controller manager都会根据每个HorizontalPodAutoscaler定义的指定的指标去查询资源利用率。 controller manager从资源指标API(针对每个pod资源指标)或自定义指标API(针对所有其他指标)获取指标。
[root@k8s-master ~]# mkdir hpa
[root@k8s-master ~]# cd hpa
创建hpa测试应用的deployment
[root@k8s-master hpa]# vim nginx.yaml
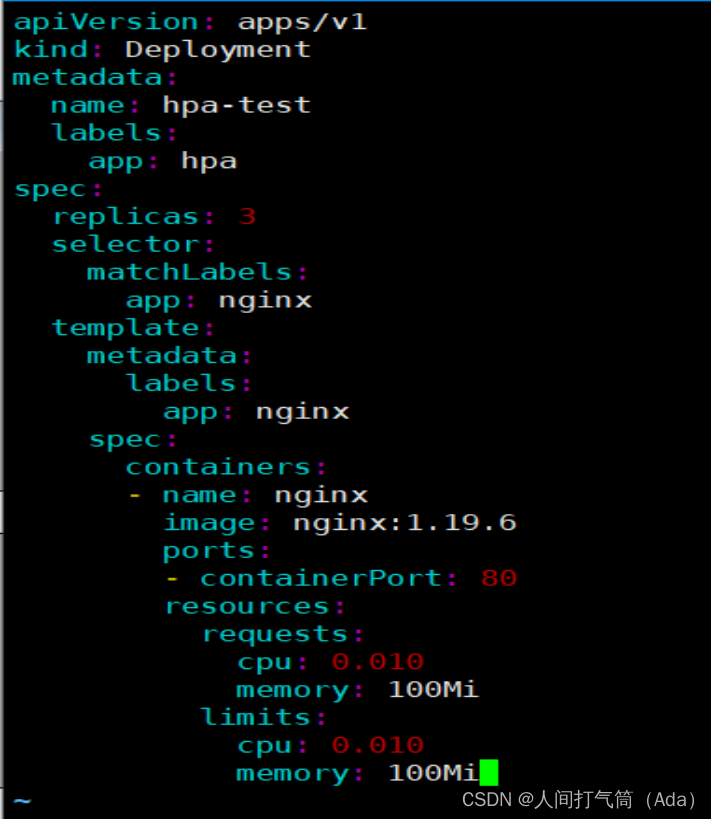
使用的资源是: CPU 0.010个核,内存100M
[root@k8s-master hpa]# kubectl apply -f nginx.yaml
[root@k8s-master hpa]# kubectl get pod
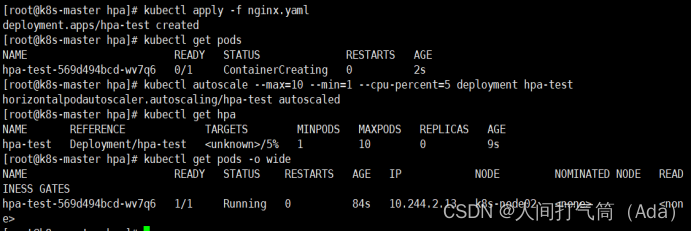
创建hpa策略
[root@k8s-master hpa]# kubectl autoscale --max=10 --min=1 --cpu-percent=5 deployment hpa-test
[root@k8s-master ~]# kubectl get hpa
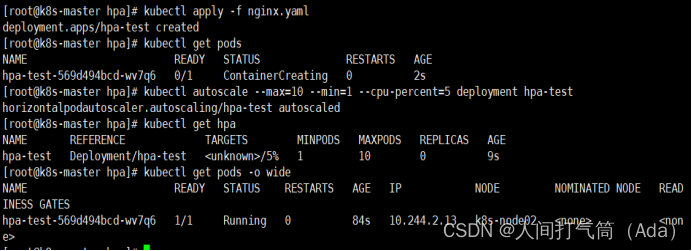
模拟业务压力测试

[root@k8s-master ~]# kubectl get pod -o wide
[root@k8s-master ~]# while true;do curl -I 10.244.1.4 ;done

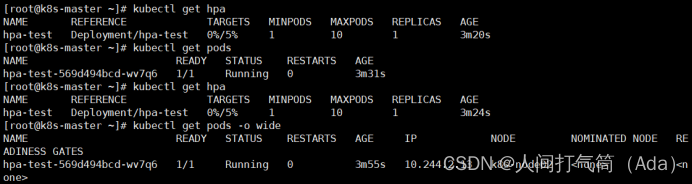
观察资源使用情况及弹性伸缩情况
[root@k8s-master ~]# kubectl get hpa
[root@k8s-master ~]# kubectl get pod

查看cpu情况:
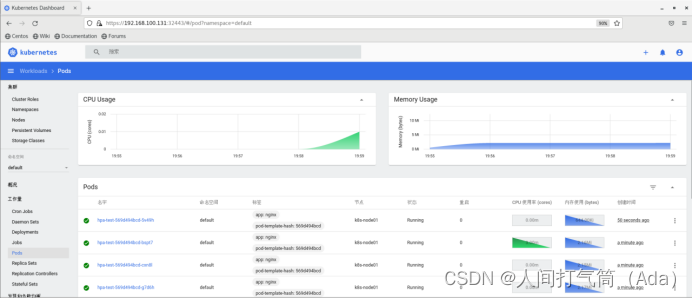

将压力测试终止后,稍等一小会儿pod数量会自动缩减到1

[root@k8s-master ~]# kubectl get pod


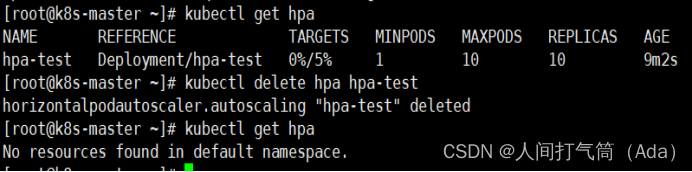
删除hpa策略
[root@k8s-master ~]# kubectl delete hpa hpa-test
[root@k8s-master ~]# kubectl get hpa