文章目录
- 背景
- 想要得到的数据格式
- 业务层获取数据,部门及用户,构建树结构
- TreeUtil生成的格式
- 部门实体
- 用户实体
背景
目前拥有用户和部门两组数据,根据部门和用户的关系,生成部门树,且每个部门下拥有哪些与子部门同级的用户列表
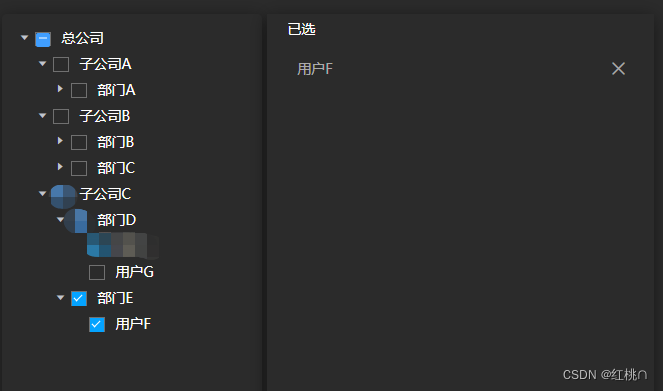
想要得到的数据格式
[
{
"id":100,
"name":"东方金信",
"parentId":0,
"depts":[
{
"id":101,
"name":"SDP组",
"parentId":100,
"depts":null,
"users":null
}
],
"users":[
{
"id":1,
"nickname":"芋道源码",
"username":"admin"
}
]
},
{
"id":102,
"name":"AAA",
"parentId":0,
"depts":[
{
"id":103,
"name":"SDP组",
"parentId":102,
"depts":null,
"users":null
}
],
"users":null
}
]
业务层获取数据,部门及用户,构建树结构
public List<DeptUserSimpleRespVO> getDeptUserListByNickname(String nickname, CommonStatusEnum status) {
List<DeptUserSimpleRespVO> deptUserSimpleRespVOs = deptService.getDeptList();
List<UserSimpleRespVO> adminUserDOS = userMapper.selectList();
AtomicBoolean hasUndistributedDeptUser = new AtomicBoolean(false);
// 设置未分配部门的用户部门为 -1L
Long undistributedDeptId = -1L;
Map<Long, List<AdminUserDO>> deptIdAndUsers = adminUserDOS.stream()
.filter(adminUserDO -> {
if (adminUserDO.getDeptId() == null) {
adminUserDO.setDeptId(undistributedDeptId);
hasUndistributedDeptUser.set(true);
}
return true;
})
.collect(Collectors.groupingBy(AdminUserDO::getDeptId));
if (hasUndistributedDeptUser.get()) {
DeptUserSimpleRespVO undistributedDept = new DeptUserSimpleRespVO();
undistributedDept.setId(undistributedDeptId);
undistributedDept.setParentId(0L);
undistributedDept.setName("未分配部门");
deptUserSimpleRespVOs.add(undistributedDept);
}
// 将用户塞进部门
deptUserSimpleRespVOs.forEach(deptUserSimpleRespVO -> {
List<UserSimpleRespVO> userSimpleRespVOS = deptIdAndUsers.get(deptUserSimpleRespVO.getId()));
deptUserSimpleRespVO.setUsers(userSimpleRespVOS);
});
// 构建部门树并返回
return TreeUtil.buildTree(deptUserSimpleRespVOs,
DeptUserSimpleRespVO::getId, DeptUserSimpleRespVO::getParentId,
DeptUserSimpleRespVO::getId, DeptUserSimpleRespVO::setDepts);
}
TreeUtil生成的格式
import cn.hutool.core.collection.CollUtil;
import cn.hutool.json.JSONUtil;
import org.springframework.util.Assert;
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
/**
* href: https://blog.csdn.net/qq_41902662/article/details/127984296
* @author jiaohongtao
* @version 1.0.0
* @since 2023/08/15
*/
public class TreeUtil {
/**
* 构造数据树 O(N)
*
* @param list 原集合
* @param mKey 父级被子集关联的字段,比如id
* @param treeConnectKey 子集关联父级的字段,比如parentId
* @param treeSortKey 同级菜单的排序字段,比如sort
* @param consumer 添加子集的函数,如dto.setChild(list)
* @param <T>
* @return
*/
public static <T> List<T> buildTree(List<T> list, Function<T, ?> mKey, Function<T, ?> treeConnectKey,
Function<T, ? extends Comparable> treeSortKey, Consumers<T, T> consumer) {
if (CollUtil.isEmpty(list)) {
return Collections.emptyList();
}
/*Assert.notNull(mKey, "父级被子级关联的字段不能为空");
Assert.notNull(treeConnectKey, "子级关联父级的字段不能为空");
Assert.notNull(consumer, "消费函数不能为空");*/
//线程安全类集合
List<T> tree = Collections.synchronizedList(new ArrayList<>());
//按上级id分组
/*final Map<?, List<T>> collect = list.parallelStream()
.collect(Collectors.groupingBy(treeConnectKey));*/
final Map<?, List<T>> collect = list.stream().collect(Collectors.groupingBy(treeConnectKey));
// list.parallelStream().filter(m -> {
list.stream().filter(m -> {
final boolean b = (Long) treeConnectKey.apply(m) != 0L;
if (!b) {
tree.add(m);
}
return b;
}).forEach(
//通过对象地址引用实现父子级关联,即使父级先添加了子级,子级在添加孙子级,父子孙三级也全部都会关联
m -> {
if (treeSortKey != null) {
consumer.accept(m, CollUtil.sort(collect.get(mKey.apply(m)), Comparator.comparing(treeSortKey)));
} else {
consumer.accept(m, collect.get(mKey.apply(m)));
}
}
);
if (treeSortKey != null) {
//排序
tree.sort(Comparator.comparing(treeSortKey));
Stream<T> peek = tree.parallelStream().peek(b -> consumer.accept(b, CollUtil.sort(collect.get(mKey.apply(b)), Comparator.comparing(treeSortKey))));
return peek.collect(Collectors.toList());
} else {
return tree.parallelStream().peek(b -> consumer.accept(b, collect.get(mKey.apply(b)))).collect(Collectors.toList());
}
}
@FunctionalInterface
public interface Consumers<T, N> {
/**
* 消费函数
*
* @param m
* @param n
*/
void accept(T m, List<N> n);
}
public static void main(String[] args) {
//模拟原始数据
final List<DeptDTO> dtos = new ArrayList<>();
DeptDTO deptDTO1 = new DeptDTO(1L, 0L, "A");
DeptDTO deptDTO2 = new DeptDTO(2L, 1L, "B");
DeptDTO deptDTO3 = new DeptDTO(3L, 1L, "C");
DeptDTO deptDTO4 = new DeptDTO(4L, 2L, "D");
DeptDTO deptDTO5 = new DeptDTO(5L, 3L, "E");
DeptDTO deptDTO6 = new DeptDTO(6L, 3L, "F");
DeptDTO deptDTO7 = new DeptDTO(7L, null, "G");
DeptDTO deptDTO8 = new DeptDTO(8L, null, "H");
dtos.add(deptDTO1);
dtos.add(deptDTO2);
dtos.add(deptDTO3);
dtos.add(deptDTO4);
dtos.add(deptDTO5);
dtos.add(deptDTO6);
dtos.add(deptDTO7);
dtos.add(deptDTO8);
DeptDTO noDeptDTO = new DeptDTO(-1L, 0L, "未分配部门");
dtos.add(noDeptDTO);
List<DeptDTO> collect = dtos.stream().filter(dto -> {
if (dto.getParentId() == null) {
dto.setParentId(-1L);
}
return true;
}).collect(Collectors.toList());
//获取树结构
List<DeptDTO> tree = TreeUtil.buildTree(collect, DeptDTO::getId, DeptDTO::getParentId, DeptDTO::getParentId, DeptDTO::setChild);
System.out.println(JSONUtil.toJsonStr(tree));
}
}
部门实体
import com.jiao.vo.user.UserSimpleRespVO;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class DeptUserSimpleRespVO {
private Long id;
private String name;
private Long parentId;
private List<DeptUserSimpleRespVO> depts;
private List<UserSimpleRespVO> users;
}
用户实体
package com.jiao.vo.user;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class UserSimpleRespVO {
private Long id;
private String nickname;
private String username;
}