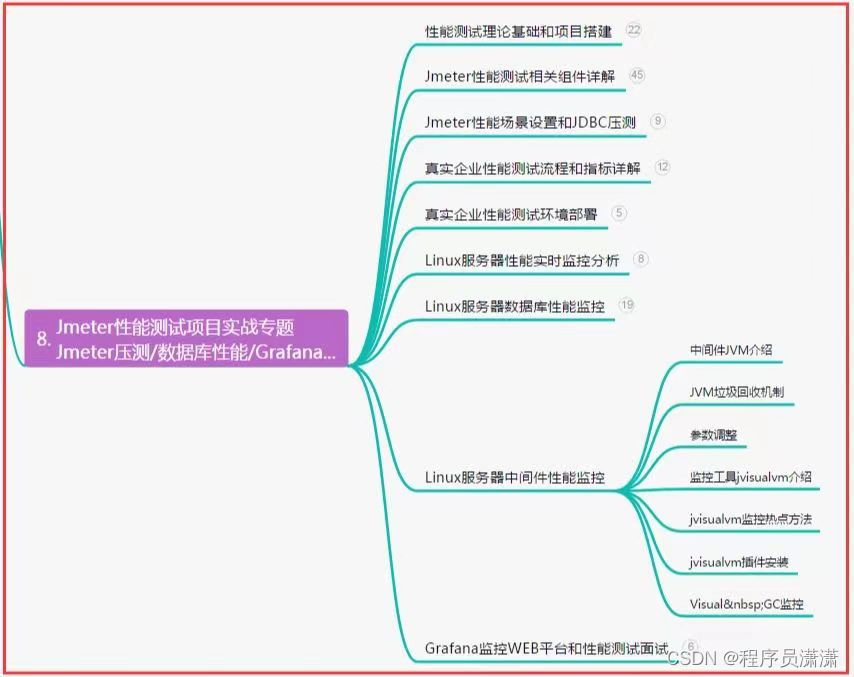
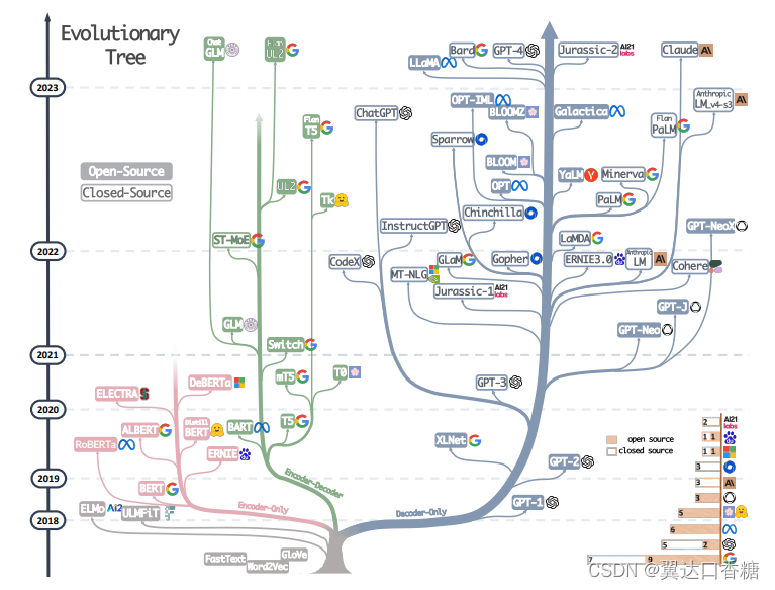
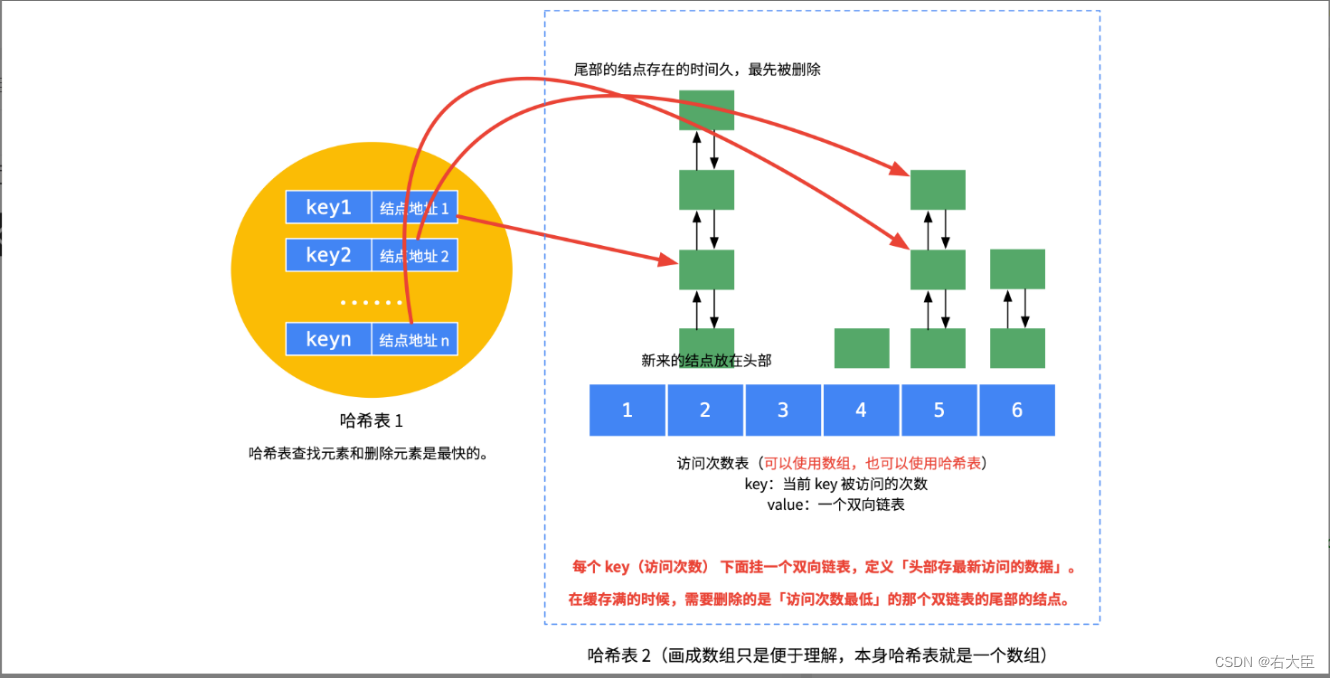
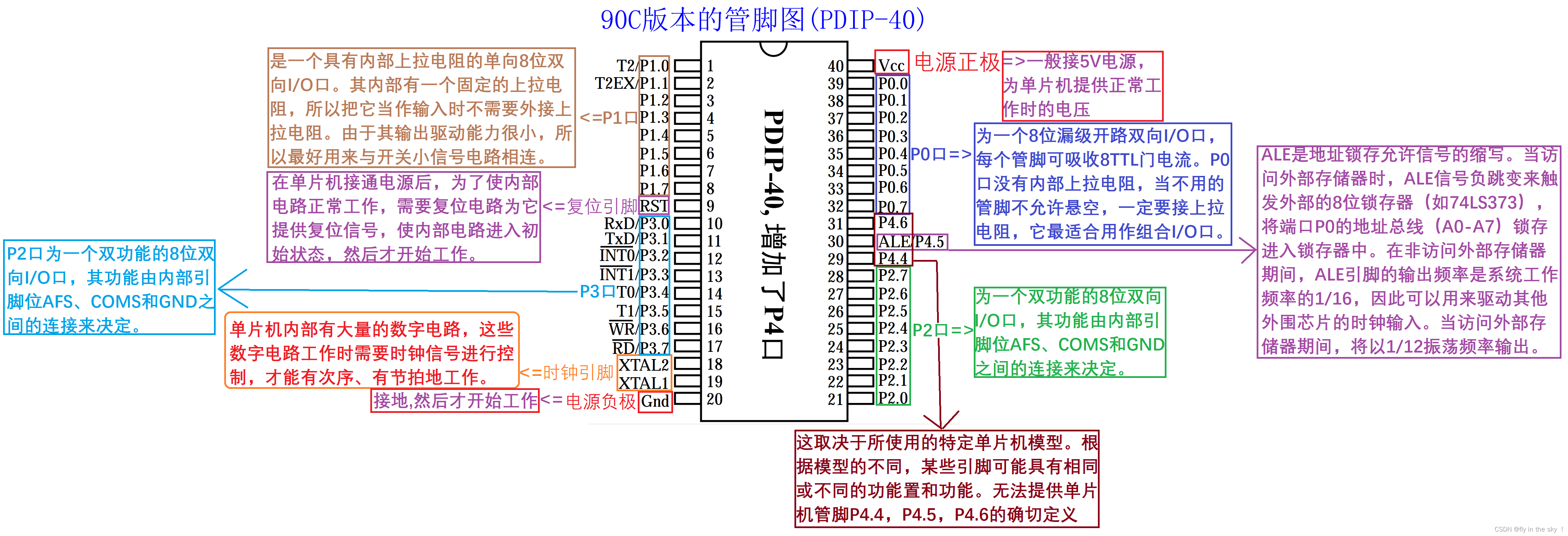
第1题:统计指定范围里的数
给定一个数的序列S,以及一个区间[L, R], 求序列中介于该区间的数的个数,即序列中大于等于L且小于等于R的数的个数。
时间限制:1000
内存限制:65536
输入
第一行1个整数n、,分别表示序列的长度。(0 < n ≤ 10000) 第二行n个正整数,表示序列里的每一个数,每个数小于等于10000000 第三行2个整数L、R,分别表示区间的左端点,区间的右端点。(1 ≤ L ≤ R ≤ 1000000)
输出
输出一个整数,表示序列中大于等于L且小于等于R的数的个数。
样例输入
5
11 8 1 10 16
1 10
样例输出
3
以下是使用C语言编写的解决方案,用于统计序列中介于给定区间的数的个数:
#include <stdio.h>
int countNumbersInRange(int arr[], int n, int L, int R) {
int count = 0;
for (int i = 0; i < n; i++) {
if (arr[i] >= L && arr[i] <= R) {
count++;
}
}
return count;
}
int main() {
int n;
scanf("%d", &n);
int arr[n];
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
int L, R;
scanf("%d %d", &L, &R);
int result = countNumbersInRange(arr, n, L, R);
printf("%d\n", result);
return 0;
}
在此解决方案中,我们首先定义了一个名为countNumbersInRange的函数,该函数接受一个整数数组arr、数组的长度n,以及区间的左端点L和右端点R。函数遍历序列中的每个数,如果数的值介于L和R之间(包括两端点),则计数器增加。最后,函数返回计数器的值。
在主函数中,我们首先读取序列的长度n,然后依次读取序列中的每个数,并将它们存储在数组arr中。接下来,我们读取区间的左端点L和右端点R。最后,我们调用countNumbersInRange函数,并将结果打印输出。
请注意,在C语言中,数组的索引从0开始,因此在循环中使用i < n来遍历数组。同时,为了接收用户的输入,请使用scanf函数。
编译并运行上述代码,根据给定的输入示例,将会输出结果为3。
第2题:按照个位数排序
对于给定的正整数序列,按照个位数从小到大排序,个位数相同的按照本身大小从小到大排序。
时间限制:1000
内存限制:65536
输入
第一行1个整数n,表示序列的大小。( 0 < n ≤ 1000) 第二行n个正整数,表示序列的每个数,每个数不大于100000000。
输出
输出按照题目要求排序后的序列
样例输入
6
17 23 9 13 88 10
样例输出
10 13 23 17 88 9
以下是使用C语言编写的解决方案,用于按照个位数排序给定的正整数序列:
#include <stdio.h>
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
void sortByDigit(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
int digit1 = arr[j] % 10;
int digit2 = arr[j + 1] % 10;
if (digit1 > digit2 || (digit1 == digit2 && arr[j] > arr[j + 1])) {
swap(&arr[j], &arr[j + 1]);
}
}
}
}
int main() {
int n;
scanf("%d", &n);
int arr[n];
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
sortByDigit(arr, n);
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
在此解决方案中,我们首先定义了一个名为swap的函数,用于交换两个整数的值。
然后,我们定义了一个名为sortByDigit的函数,该函数接受一个整数数组arr和数组的长度n。函数使用冒泡排序算法来按照个位数从小到大排序,如果个位数相同,则按照数本身的大小从小到大排序。
在主函数中,我们首先读取序列的大小n,然后依次读取序列中的每个数,并将它们存储在数组arr中。接下来,我们调用sortByDigit函数对数组进行排序。最后,我们使用循环遍历数组,并打印输出排序后的序列。
请注意,在C语言中,数组的索引从0开始,因此在循环中使用i < n来遍历数组。同时,为了接收用户的输入,请使用scanf函数。
编译并运行上述代码,根据给定的输入示例,将会输出排序后的序列:10 13 23 17 88 9。
第3题:过滤多余的空格
一个句子中也许有多个连续空格,过滤掉多余的空格,只留下一个空格。
时间限制:1000
内存限制:65536
输入
一行,一个字符串(长度不超过200),句子的头和尾都没有空格。
输出
过滤之后的句子。
样例输入
Hello world.This is c language.
样例输出
Hello world.This is c language.
以下是使用C语言编写的解决方案,用于过滤多余的空格,只保留一个空格:
#include <stdio.h>
#include <string.h>
void filterSpaces(char* sentence) {
int len = strlen(sentence);
int i, j;
// 移除句子中多余的空格
i = 0;
j = 0;
while (i < len) {
if (sentence[i] == ' ') {
// 如果当前字符是空格
sentence[j++] = sentence[i++]; // 保留一个空格
while (i < len && sentence[i] == ' ') {
i++; // 跳过连续的空格
}
} else {
sentence[j++] = sentence[i++]; // 非空格字符直接复制
}
}
sentence[j] = '\0'; // 添加字符串结束符
}
int main() {
char sentence[201];
fgets(sentence, sizeof(sentence), stdin);
filterSpaces(sentence);
printf("%s\n", sentence);
return 0;
}
在此解决方案中,我们定义了一个名为filterSpaces的函数,该函数接受一个字符数组sentence,并在原地修改句子,过滤多余的空格,只保留一个空格。函数使用双指针技术,一个指针i用于遍历句子中的字符,另一个指针j用于记录过滤后的字符位置。
在主函数中,我们首先使用fgets函数读取一行输入句子,并将其存储在字符数组sentence中。接下来,我们调用filterSpaces函数对句子进行处理。最后,我们使用printf函数打印输出过滤后的句子。
请注意,在C语言中,字符串以空字符(‘\0’)结尾,因此在处理后的句子末尾添加了字符串结束符。
编译并运行上述代码,根据给定的输入示例,将会输出过滤后的句子:“Hello world.This is c language.”
第4题:图像叠加
给出两幅相同大小的黑白图像(用0-1矩阵)表示,0表示白点,1表示黑点,求两幅图像叠加后的图像。
说明:若两幅图像在相同位置上的像素点都是白色,叠加后为白色,否则为黑色。
时间限制:1000
内存限制:65536
输入
第一行包含两个整数m和n,表示图像的行数和列数,中间用单个空格隔开。1 <= m <= 100, 1 <= n <= 100。 之后m行,每行n个整数0或1,表示第一幅黑白图像上各像素点的颜色。相邻两个数之间用单个空格隔开。 之后m行,每行n个整数0或1,表示第二幅黑白图像上各像素点的颜色。相邻两个数之间用单个空格隔开。
输出
m行,每行n个整数,表示叠加后黑白图像上各像素点的颜色。
样例输入
3 3
1 0 1
0 0 1
1 1 0
1 1 0
0 0 1
0 0 1
样例输出
1 1 1
0 0 1
1 1 1
以下是使用C语言编写的解决方案,用于图像叠加:
#include <stdio.h>
void overlayImages(int image1[][100], int image2[][100], int result[][100], int m, int n) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (image1[i][j] == 0 && image2[i][j] == 0) {
result[i][j] = 0; // 两幅图像在相同位置上的像素点都是白色
} else {
result[i][j] = 1; // 其他情况为黑色
}
}
}
}
int main() {
int m, n;
scanf("%d %d", &m, &n);
int image1[100][100];
int image2[100][100];
int result[100][100];
// 读取第一幅图像
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
scanf("%d", &image1[i][j]);
}
}
// 读取第二幅图像
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
scanf("%d", &image2[i][j]);
}
}
overlayImages(image1, image2, result, m, n);
// 输出叠加后的图像
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
printf("%d ", result[i][j]);
}
printf("\n");
}
return 0;
}
在此解决方案中,我们定义了一个名为overlayImages的函数,该函数接受两个二维整数数组image1和image2,以及一个二维整数数组result,还有图像的行数m和列数n。函数遍历两幅图像的像素点,根据题目要求进行叠加操作,并将结果存储在result数组中。
在主函数中,我们首先读取图像的行数m和列数n。然后,我们定义了三个二维整数数组image1、image2和result,分别用于存储两幅图像和叠加后的图像。接下来,我们按行读取第一幅图像的像素点,并存储在image1数组中。然后,我们按行读取第二幅图像的像素点,并存储在image2数组中。接下来,我们调用overlayImages函数对两幅图像进行叠加操作,并将结果存储在result数组中。最后,我们使用循环打印输出叠加后的图像。
请注意,在C语言中,二维数组的索引从0开始,因此在循环中使用i < m和j < n来遍历二维数组。
编译并运行上述代码,根据给定的输入示例,将会输出叠加后的图像:
1 1 1
0 0 1
1 1 1
第5题:出书最多
假定图书馆新进了m(10 ≤ m ≤ 999)本图书,它们都是由n(1 ≤ n ≤ 26)个作者独立或相互合作编著的。假设m本图书编号为整数(1到999),作者的姓名为字母(‘A’到’Z’),请根据图书作者列表找出参与编著图书最多的作者和他的图书列表。
时间限制:1000
内存限制:65536
输入
第一行为所进图书数量m,其余m行,每行是一本图书的信息,其中第一个整数为图书编号,接着一个空格之后是一个由大写英文字母组成的没有重复字符的字符串,每个字母代表一个作者。输入数据保证仅有一个作者出书最多。
输出
输出有多行: 第一行为出书最多的作者字母; 第二行为作者出书的数量; 其余各行为作者参与编著的图书编号(按输入顺序输出)。
样例输入
11
307 F
895 H
410 GPKCV
567 SPIM
822 YSHDLPM
834 BXPRD
872 LJU
791 BPJWIA
580 AGMVY
619 NAFL
233 PDJWXK
样例输出
P
6
410
567
822
834
791
233
以下是使用C语言编写的解决方案,用于找出参与编著图书最多的作者和他的图书列表:
#include <stdio.h>
#include <string.h>
#define MAX_AUTHORS 26
#define MAX_BOOKS 999
typedef struct {
char author;
int bookIds[MAX_BOOKS];
int numBooks;
} Author;
void findMostProductiveAuthor(Author authors[], int m) {
int maxBooks = 0;
char mostProductiveAuthor;
int i;
// 找出出书最多的作者
for (i = 0; i < MAX_AUTHORS; i++) {
if (authors[i].numBooks > maxBooks) {
maxBooks = authors[i].numBooks;
mostProductiveAuthor = authors[i].author;
}
}
// 输出出书最多的作者字母
printf("%c\n", mostProductiveAuthor);
// 输出作者出书的数量
printf("%d\n", maxBooks);
// 输出作者参与编著的图书编号
for (i = 0; i < authors[mostProductiveAuthor - 'A'].numBooks; i++) {
printf("%d\n", authors[mostProductiveAuthor - 'A'].bookIds[i]);
}
}
int main() {
int m;
scanf("%d", &m);
Author authors[MAX_AUTHORS];
memset(authors, 0, sizeof(authors));
int i, j;
int bookId;
char authorList[MAX_AUTHORS + 1];
for (i = 0; i < m; i++) {
scanf("%d %[^\n]", &bookId, authorList);
for (j = 0; j < strlen(authorList); j++) {
authors[authorList[j] - 'A'].author = authorList[j];
authors[authorList[j] - 'A'].bookIds[authors[authorList[j] - 'A'].numBooks++] = bookId;
}
}
findMostProductiveAuthor(authors, m);
return 0;
}
在此解决方案中,我们定义了一个名为Author的结构体,用于存储作者的信息。结构体包含一个author字段表示作者字母,一个bookIds数组表示作者参与编著的图书编号,以及一个numBooks字段表示作者出书的数量。
在主函数中,我们首先读取图书的数量m。然后,我们定义了一个Author类型的数组authors,用于存储作者的信息。我们使用memset函数将数组初始化为零。接下来,我们使用循环按行读取每本图书的信息。对于每本图书,我们提取图书编号和作者列表,并将作者信息存储在authors数组中的相应位置。我们通过将作者字母减去字母’A’的ASCII值来计算数组中的索引。
然后,我们调用findMostProductiveAuthor函数来找出出书最多的作者和他的图书列表。该函数遍历authors数组,找出出书最多的作者,并输出相应的信息。
请注意,在C语言中,字符可以用整数表示。因此,我们可以使用作者字母’A’的ASCII值作为索引来访问authors数组中的相应位置。
编译并运行上述代码,根据给定的输入示例,将会输出作者出书最多的信息:
P
6
410
567
822
834
791
233