目录
一. 进程间通信概述
二. 管道的概念
三. 通过管道实现进程间通信
3.1 实现原理
3.2 匿名管道创建系统接口pipe
3.3 管道通信的模拟实现
3.4 管道通信的访问控制规则
3.5 管道通信的特点
四. 通过匿名管道实现进程池
4.1 进程池的概念
4.2 进程池的模拟实现
五. 命名管道
5.1 命名管道的功能
5.2 命名管道的创建和使用
六. 总结
一. 进程间通信概述
进程间通信的目的:实现进程之间的数据传输、共享资源、事件通知、多进程协同等操作。‘
进程间通信的技术手段:进程间要实现通信,就必须要让不同的进程看到同一块资源(内存空间),而由于进程之间具有独立性,因此这块资源不能隶属于任何一个进程,应当由操作系统内核提供。
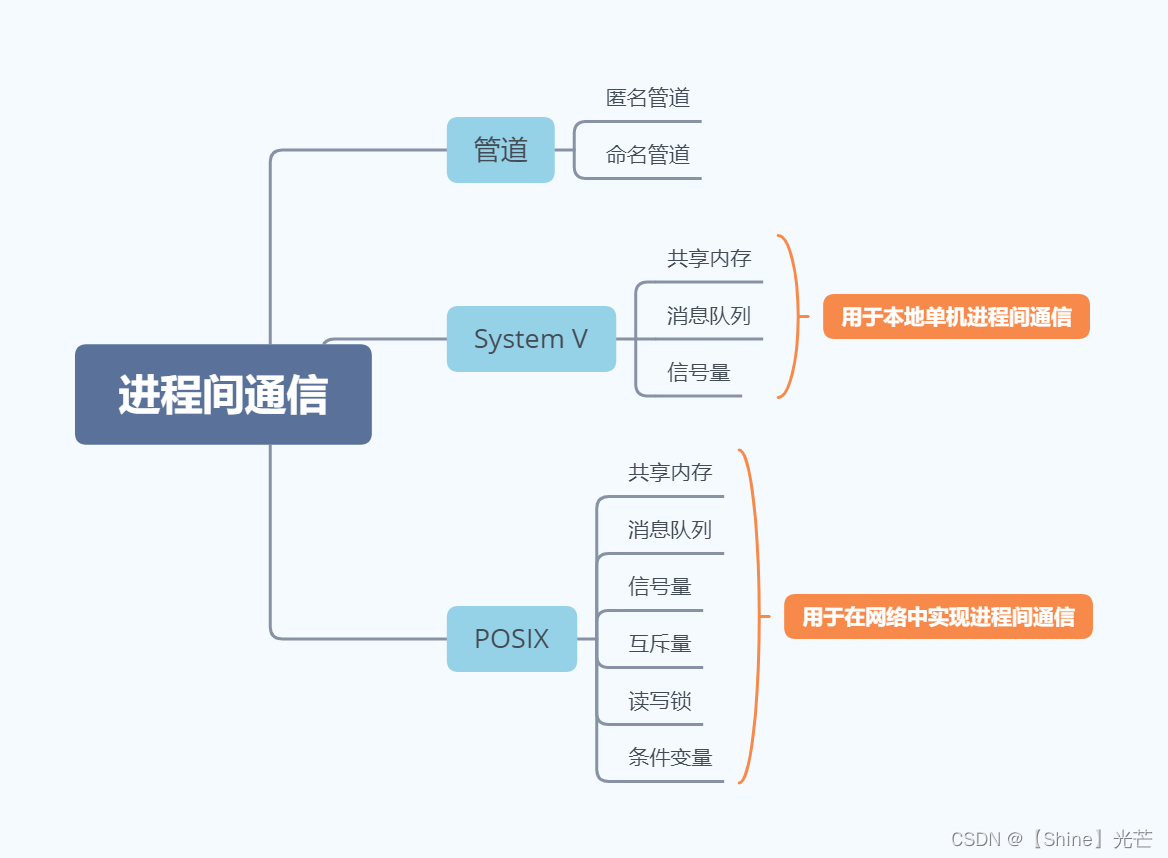
进程间通信的方法:管道、SystemV、POSIX
管道:匿名管道、命名管道。
System V:共享内存、消息队列、信号量 。-- 用于本地计算机进行单机进程间通信
POSIX:消息队列、共享内存、信号量、互斥量、读写锁、条件变量。 -- 在网络中,用于多机之间的进程间通信。
二. 管道的概念
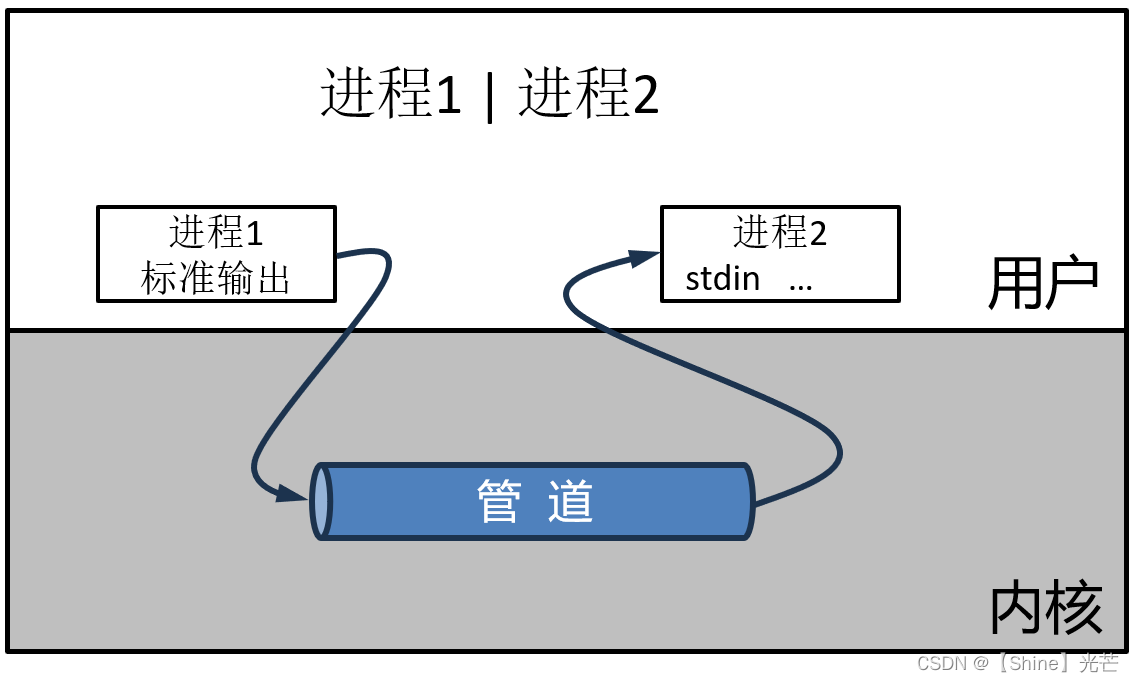
管道,是用于传输资源(数据)的一种媒介,可以实现进程之间的单向通信(也只能单向通信)。
由于进程之间具有相互独立性,因此,管道只能由操作系统内核提供,不能源自任意进程,管道的本质是一种内存级文件,即:内容不会被刷新到磁盘上的文件。
三. 通过管道实现进程间通信
3.1 实现原理
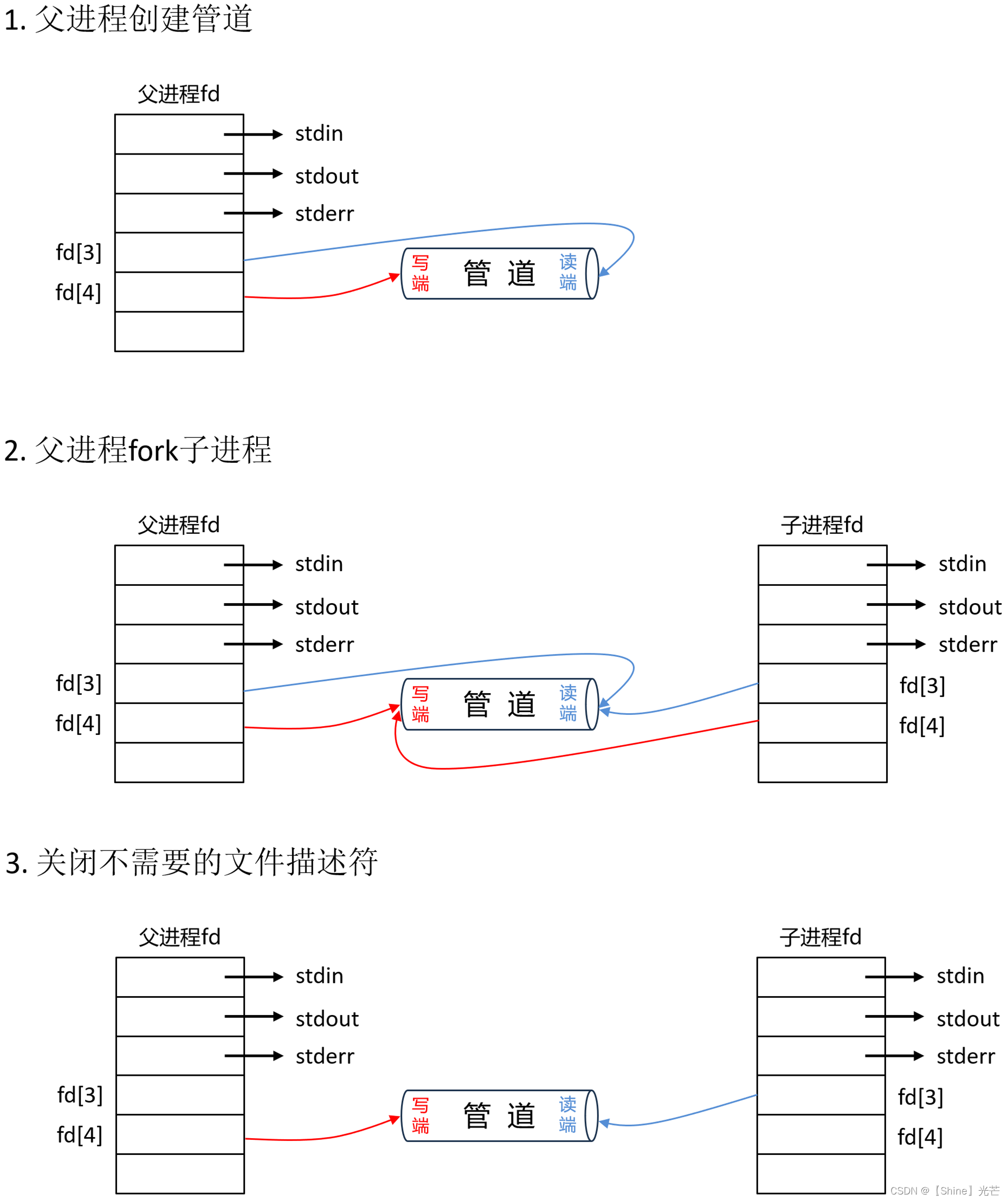
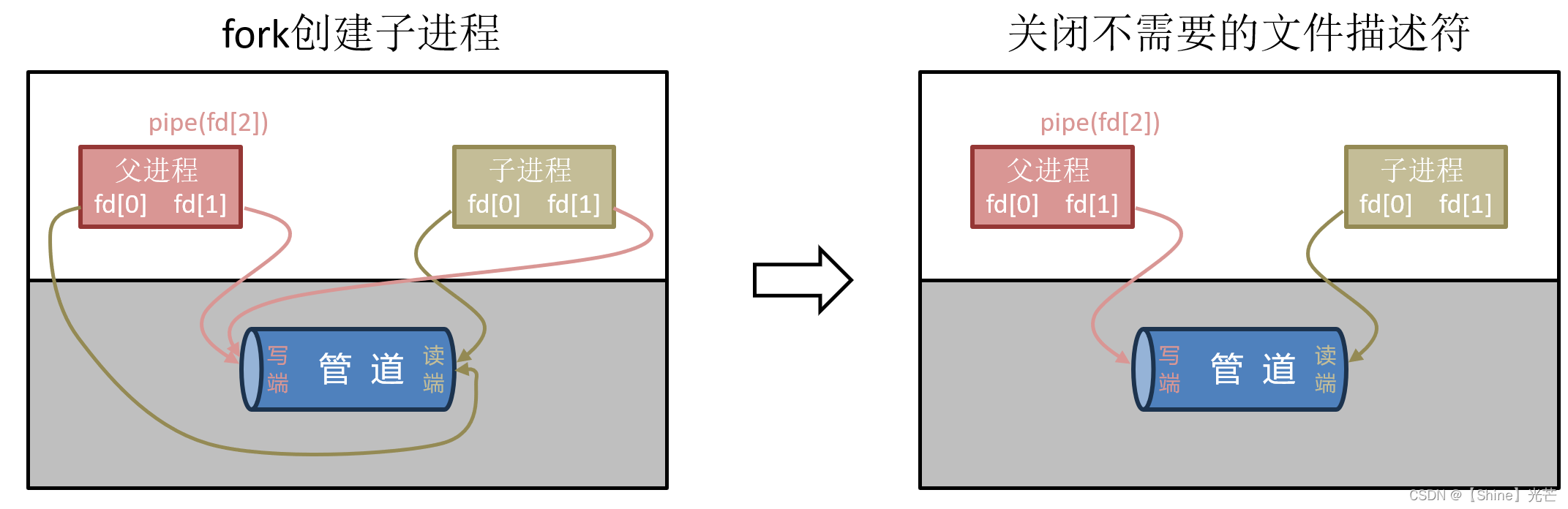
管道,尤其是匿名管道,一般用于具有亲缘关系的进程之间的通信,其底层实现原理如下:
- 父进程以读和写的方式创建匿名管道,由于管道的本质是文件,因此父进程会有两个文件描述符fd分别指向管道(一个读一个写)。
- fork创建子进程,子进程的文件描述符及指向与父进程相同。
- 关闭不需要的文件描述符,一般父进程用于写数据,子进程用于读数据,因此父进程关闭用来读的fd,子进程关闭用于写的fd。
经过上面的步骤,父进程的写fd和子进程的读fd就指向了相同的内存级文件(管道),通过父进程向管道中写的数据,就能被子进程读出来。
3.2 匿名管道创建系统接口pipe
原型:int pipe(int pipefd[2])
参数:pipefd为输出型参数,pipefd[0]为读端文件描述符,pipefd[1]为写端文件描述符。
返回值:如果成功创建管道返回0,失败返回-1并设置全局错误码。
头文件:#include <sys/fcntl.h>、#include <unistd.h>
一般pipe由父进程来调用,调用pipe后父进程要fork创建子进程,在父进程中一般要关闭pipefd[0],在子进程中一般要关闭pipefd[1]。
3.3 管道通信的模拟实现
代码3.1通过管道,实现父进程向子进程发生消息,父进程每隔1s写一次消息,子进程不间断读取并输出消息,由于写慢读快,子进程需要阻塞等待父进程写消息后才能读。
代码3.1:模拟实现管道通信
#include <iostream>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/fcntl.h>
#define SIZE 1024
int main()
{
// 1. 父进程创建管道
int pipefd[2] = {0}; // 管道读写对应的文件描述符
int n = pipe(pipefd); // 创建管道
if(n == -1) // 管道创建失败
{
perror("pipe");
exit(1);
}
// 2. fork子进程
pid_t id = fork(); // 创建子进程
if(id < 0) //子进程创建失败
{
perror("fork");
exit(2);
}
else if(id == 0) //子进程代码
{
// 3. 子进程 -- 用于读取管道中的数据
// 3.1 关闭不需要的文件描述符,子进程关写pipefd[1]
close(pipefd[1]);
// 3.2 读取数据并打印到标准输出流
// 如果写慢读快,那么读要等写
// 如果写快读慢,那么等待管道被写满后,就不能再继续写
char read_buffer[1024] = {0}; // 读数据文件缓冲区
while(true)
{
ssize_t sz = read(pipefd[0], read_buffer, SIZE - 1); //数据读取
// 如果写端退出,那么读端read读到0,读端最终会退出
// 如果读端退出,OS会强制终止写端进程
if(sz > 0) // 确实读到了数据
{
read_buffer[sz] = '\0';
std::cout << "Father# " << read_buffer << std::endl;
}
else if(sz == 0) // 写端关闭
{
std::cout << "Father quit, write end, read end!" << std::endl;
break;
}
else // sz < 0
{
perror("read");
break;
}
}
close(pipefd[0]);
exit(0);
}
// 3. 父进程代码 -- 用于写数据
// 3.1 关闭不需要的文件描述符,父进程关读pipdfd[0];
close(pipefd[0]);
// 3.2 向管道写数据
const char* msg = "I am father process, I am sending message";
char send_buffer[SIZE] = {0}; // 写数据缓冲区
int count = 0;
while(true)
{
snprintf(send_buffer, SIZE, "%s,%d", msg, ++count);
write(pipefd[1], send_buffer, strlen(send_buffer));
sleep(1);
}
close(pipefd[1]);
return 0;
}3.4 管道通信的访问控制规则
- 读快写慢:读端需要阻塞等待写端写入数据后才能读。
- 写快读慢:管道被写满后就不能继续写入,需要等待数据被读出。
- 写端关闭:读端read读到0,退出。
- 读端关闭:OS强制终止写端进程。
3.5 管道通信的特点
- 管道(匿名管道),常用于具有亲缘关系的进程的进程间通信。
- 管道通信存在访问控制。
- 管道通信是一种面向字节流式的通信。-- 面向流式的通信:可以多次写入的内容一次读取,也可以一次写入的内容分多次读取。
- 管道的本质是文件(内存级文件),文件的生命周期随进程的结束而结束,因此进程结束时,管道关闭。
- 管道通信为单向通信,是半双工通信的一种特殊形式。
半双工通信:通信双方在某一时刻,只能单独进行写或读。(并不是说某一端只能进行写或读,而是不能写和读同时进行)
全双工通信:通信双方可以写和读同时进行。
四. 通过匿名管道实现进程池
4.1 进程池的概念
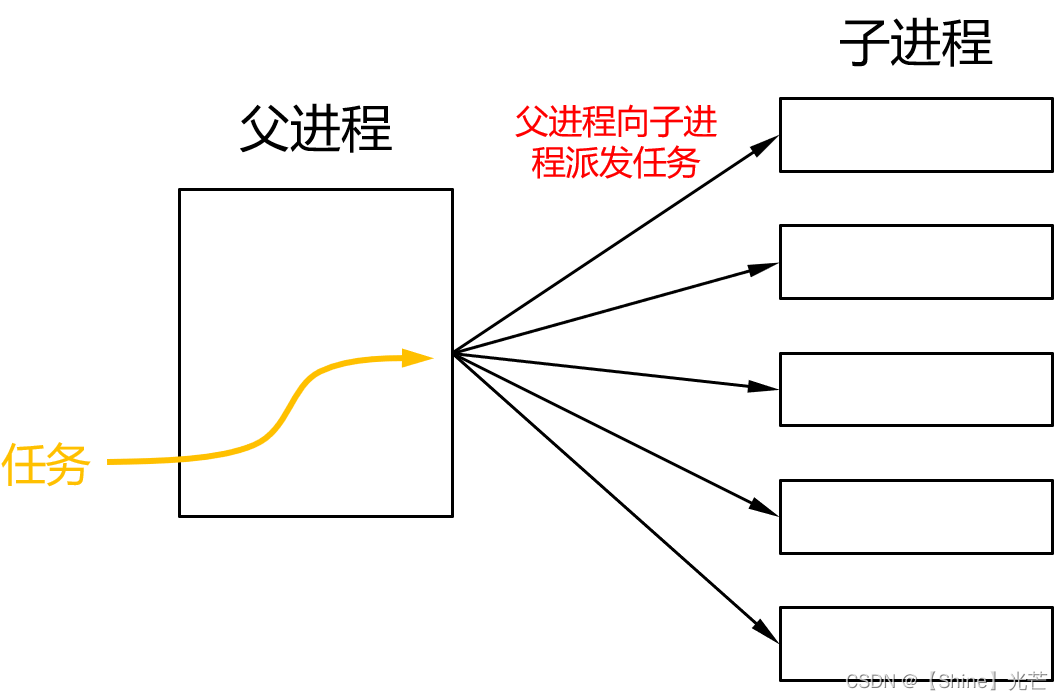
父进程创建N个子进程,按照一定的规则向子进程派发任务,父进程只负责向子进程派发任务,具体的任务由子进程来完成。
如果父进程将均衡的向每个子进程派发任务,这种算法称为单机版负载均衡。
4.2 进程池的模拟实现
采用rand随机生成来决定选用哪个子进程来执行任务。
task.hpp文件:父进程派发的任务
#ifndef __TASK_DEFINE_
#define __TASK_DEFINE_
#include <iostream>
#include <vector>
#include <functional>
typedef std::function<void()> func; // 类型重定义
std::vector<func> trace_back; // 回调函数
std::vector<std::string> desc; // 任务编号及对应说明
void execuleUrl()
{
std::cout << "execuleUrl" << std::endl;
}
void save()
{
std::cout << "save data" << std::endl;
}
void visitSQL()
{
std::cout << "visit SQL" << std::endl;
}
void online()
{
std::cout << "take online" << std::endl;
}
void load()
{
trace_back.emplace_back(execuleUrl);
desc.emplace_back("execuleUrl");
trace_back.emplace_back(save);
desc.emplace_back("save data");
trace_back.emplace_back(visitSQL);
desc.emplace_back("visit SQL");
trace_back.emplace_back(online);
desc.emplace_back("take online");
}
void show()
{
int count = 0;
for(const auto& msg : desc)
{
std::cout << count << ": " << msg << std::endl;
++count;
}
}
int handlerSize()
{
return trace_back.size();
}
#endifPipePool.cc文件:进程池的实现源文件
#include <iostream>
#include <vector>
#include <ctime>
#include <cstdlib>
#include <cassert>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include "task.hpp"
#define PROCESS_NUM 5
void distributeTask(int who, int fd, uint32_t command)
{
// 派发任务
ssize_t n = write(fd, &command, sizeof(uint32_t));
assert(n == sizeof(uint32_t));
}
uint32_t waitCommand(int fd, bool &quit)
{
uint32_t command = 0;
ssize_t n = read(fd, &command, sizeof(uint32_t));
if (n == 0)
{
quit = true;
return -1;
}
assert(n == sizeof(uint32_t));
return command;
}
int main()
{
load(); // 载入任务
// 创建子进程
int pipefd[2] = {0};
std::vector<std::pair<pid_t, int>> slot; // 记录子进程id以及写端文件描述符
for (int i = 0; i < PROCESS_NUM; ++i)
{
// 创建管道
int ret = pipe(pipefd);
if (ret == -1) // 管道创建失败
{
perror("pipe");
exit(1);
}
// 创建子进程
pid_t id = fork();
if (id < 0) // 如果子进程创建失败
{
perror("fork");
exit(2);
}
else if (id == 0) // 子进程代码
{
// 子进程代码
// 关闭不需要的文件描述符
close(pipefd[1]); // 子进程关写
while (true)
{
// 阻塞等待指令
bool quit = false;
uint32_t command = waitCommand(pipefd[0], quit);
if (quit)
{
std::cout << "write close, read also close!" << std::endl;
break;
}
if (command >= 0 && command < handlerSize())
{
trace_back[command]();
}
else
{
std::cerr << "choice wrong" << std::endl;
}
}
close(pipefd[0]);
exit(0);
}
// 父进程代码
close(pipefd[0]); // 关闭读
slot.emplace_back(id, pipefd[1]); // 将子进程id和对应写端文件描述符插入顺序表
}
srand((unsigned int)time(NULL));
// 父进程,开始派发任务
int select = 0;
while (true)
{
std::cout << "##############################" << std::endl;
std::cout << "## 1. show 2. choice ##" << std::endl;
std::cout << "##############################" << std::endl;
std::cout << "Please Select: > ";
std::cin >> select;
if (select == 1)
{
show();
}
else if (select == 2)
{
int choice = 0;
std::cout << "Please chose task: > ";
std::cin >> choice;
int proc = rand() % PROCESS_NUM; // 选择子进程完成任务
distributeTask(slot[proc].first, slot[proc].second, choice); // 派发任务
usleep(100000);
}
else
{
std::cerr << "choice error" << std::endl;
break;
}
}
// 父进程关闭写端,子进程退出
for (const auto &iter : slot)
{
close(iter.second);
}
// 父进程阻塞等待子进程退出
for (const auto &iter : slot)
{
waitpid(iter.first, NULL, 0);
}
return 0;
}五. 命名管道
5.1 命名管道的功能
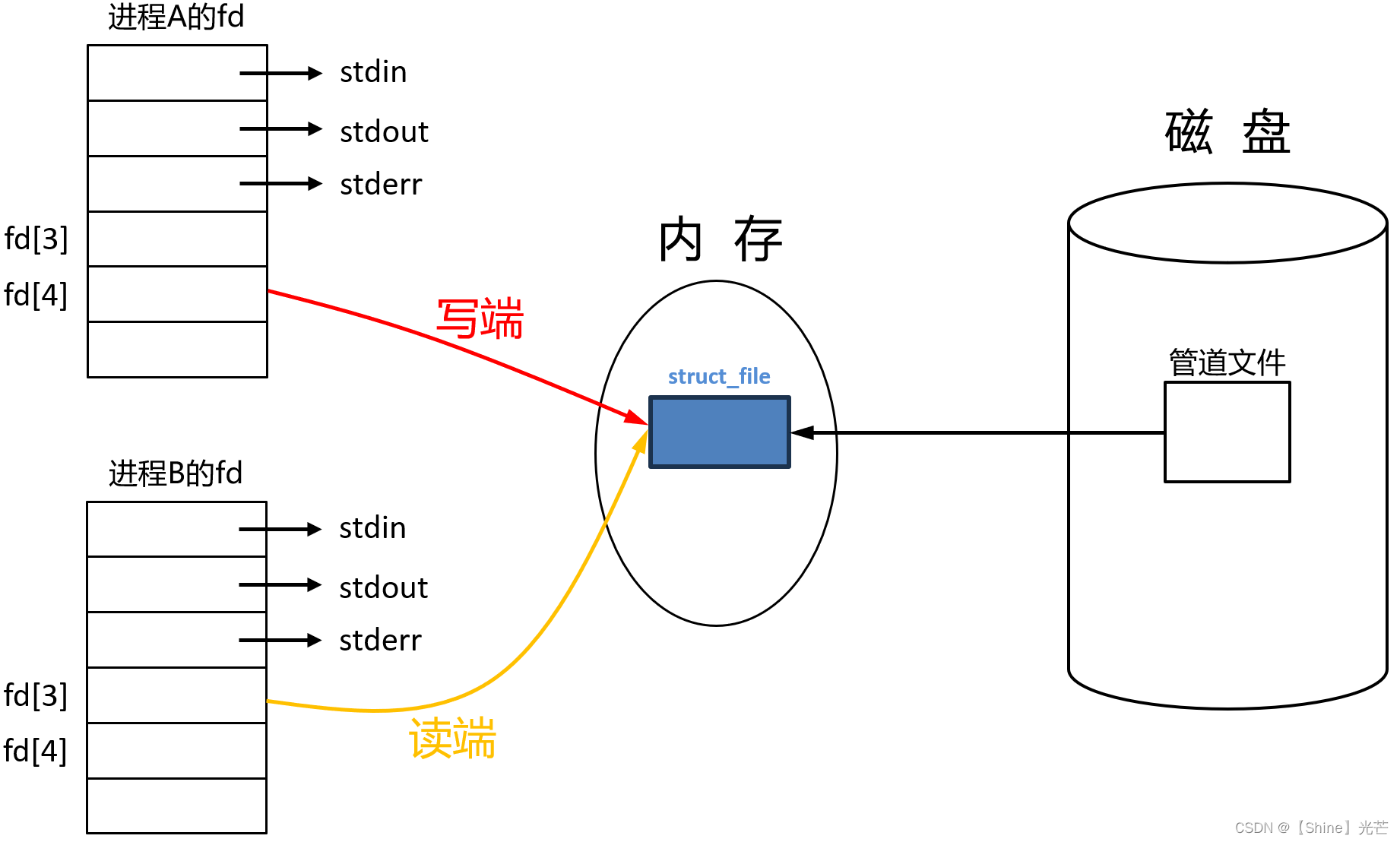
一般意义上的管道(匿名管道)只能实现父子进程之间的通信,而命名管道可以实现不相关进程之间的进程间通信。
命名管道是一种特殊类型的文件,具有以下特性:
- 可以被打开,但不会将内存中的数据刷新到磁盘。
- 具有属于自己的名称。
- 在系统中有唯一的路径。
两个不相关的进程,可以通过访问同一管道文件,来实现进程间通信。
5.2 命名管道的创建和使用
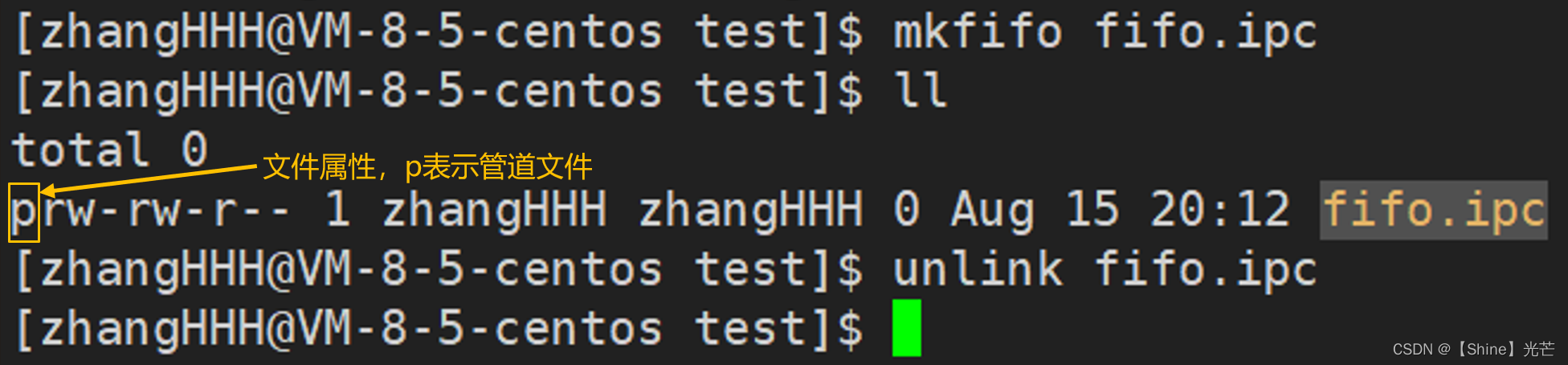
- 通过指令创建管道文件:mkfifo [文件名]
- 删除管道文件:unlink、rm均可
同样,C语言库函数中也有mkfifo,其功能也是创建管道文件,mkfifo库函数的信息如下:
- 函数原型:int mkfifo(const char* pathname, mode_t mode);
- 函数参数:pathname为创建的管道文件名和路径,mode为起始权限。
- 返回值:创建成功返回0,失败返回-1并设置全局错误码。
也存在unlink库函数,用于删除管道文件,原型为:int unlink(const char* pathname)
假设有两个进程A和B,进程A以写的方式打开管道文件,进程B以读的方式打开管道文件,如果进程B先运行,需要等到进程A以写的方式打开管道文件后,进程B才可以以读打开的方式打开管道文件,否则,进程B要一直等待管道文件被以读的方式打开。
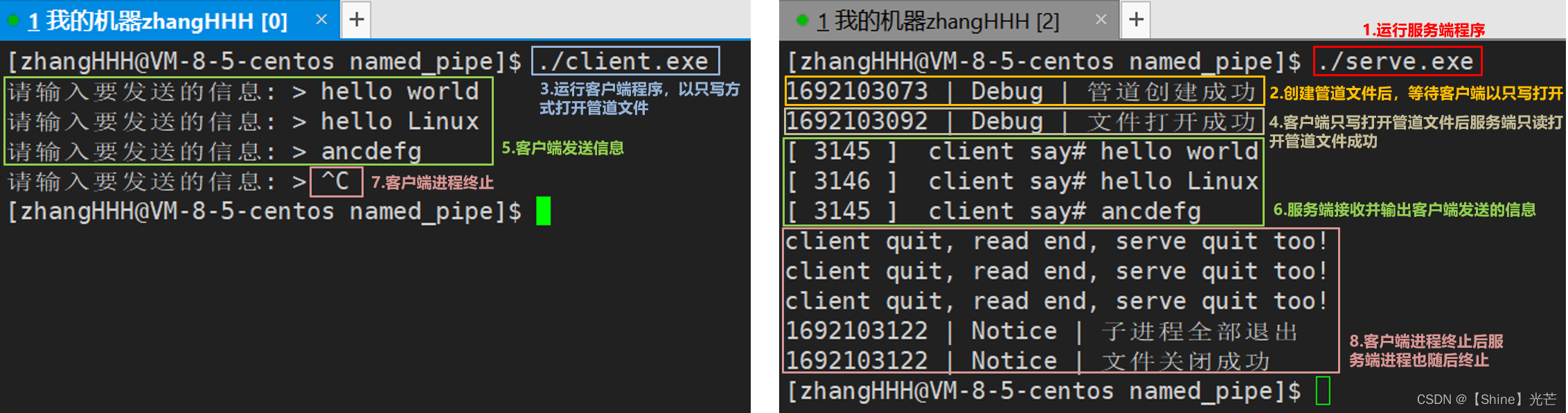
代码5.1通过命名管道,实现服务端进程(serve.exe)和客户端进程(client.exe)之间的进程间通信,serve.cc创建管道文件,并以只读方式打开管道文件,client.cc以只写的方式打开管道文件,执行代码时先运行serve.exe,等待client.exe运行以只写打开管道后,serve.exe才能执行只读打开管道文件的代码,在client中输入的信息,会显示到serve中。
代码5.1:命名管道实现不相关进程间的通信
// log.hpp头文件 -- 日志打印相关声明和实现
// 日志操作
#include <iostream>
#include <string>
#include <ctime>
#ifndef __LOG_DEFINE_
#define __LOG_DEFINE_
#define DEBUG 0
#define NOTICE 1
#define WARNING 2
#define ERROR 3
std::string msg[] = {
"Debug",
"Notice",
"Waring",
"Error"
};
std::ostream& log(const std::string& message, int level)
{
std::cout << (unsigned int)time(NULL) << " | " << msg[level] << " | " << message << std::endl;
}
#endif
// common.hpp头文件 -- 声明宏,包含库文件
#ifndef __COMMON_DEF_
#define __COMMON_DEF_
#include <iostream>
#include <cstdio>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/fcntl.h>
#include <sys/stat.h>
#include "log.hpp"
#define MODE 0666
#define SIZE 1024
#define PROCESS_NUM 3
std::string ipcPath = "fifo.ipc";
#endif
// serve.cc -- 服务端源文件代码
#include "commom.hpp"
// 服务端函数
int main()
{
// 1. 以只写的方式打开管道文件
int fd = open(ipcPath.c_str(), O_WRONLY);
if(fd < 0)
{
perror("client open");
exit(1);
}
// 2. 开始执行进程间通信
std::string send_buffer; // 信息发送缓冲区
while(true)
{
std::cout << "请输入要发送的信息: > ";
std::getline(std::cin, send_buffer); // 逐行读取信息
write(fd, send_buffer.c_str(), send_buffer.size()); //写数据
}
// 3. 关闭文件
close(fd);
return 0;
}
// client.cc -- 客户端源文件代码
#include "commom.hpp"
// 信息读取函数
void GetMessage(int fd)
{
char read_buffer[SIZE] = {0}; //读数据缓冲区
while(true)
{
ssize_t n = read(fd, read_buffer, SIZE - 1); //从管道文件读数据
if(n > 0)
{
read_buffer[n] = '\0';
std::cout << "[ " << getpid() << " ] client say# " << read_buffer << std::endl;
}
else if(n == 0)
{
std::cout << "client quit, read end, serve quit too! " << std::endl;
break;
}
else // n < 0 -- 读取出错
{
perror("read");
break;
}
}
}
int main()
{
// 1. 创建命名管道文件
if(mkfifo(ipcPath.c_str(), MODE) < 0)
{
perror("mkfifo");
exit(1);
}
log("管道创建成功", DEBUG);
// 2. 服务端以只读方式打开文件
int fd = open(ipcPath.c_str(), O_RDONLY);
if(fd < 0) //检验打开是否成功
{
perror("serve fopen");
exit(2);
}
log("文件打开成功", DEBUG);
// 3. 创建子进程,进行进程间通信(读数据)
for(int i = 0; i < PROCESS_NUM; ++i)
{
pid_t id = fork();
if(id == 0) //子进程代码
{
GetMessage(fd); //信息读取函数
exit(0);
}
}
// 4. 阻塞等待子进程退出
for(int i = 0; i < PROCESS_NUM; ++i)
{
waitpid(-1, NULL, 0);
}
log("子进程全部退出", NOTICE);
// 5. 关闭文件,删除命名管道文件
close(fd);
unlink(ipcPath.c_str());
log("文件关闭成功", NOTICE);
// std::cout << "文件关闭成功" << std::endl;
return 0;
}
六. 总结
- 实现进程间通信的方式有三种,分别为管道、System V、POSIX,其中System V用于本地单机进程间通信,POSIX用于网络进程间通信。
- 管道的本质是内存级文件,由OS内核提供,管道一般用于具有亲缘关系的进程间通信,管道通信为单向通信,是面向字节流式的通信,存在访问控制,管道的生命周期随进程的终止而终止。
- 通过命名管道,可以实现不相关进程间的通信。