前言
做自然语言处理(Natural Language Processing,NLP)这个领域的小伙伴们肯定对word2vec这个模型很熟悉了,它就是一种最为常见的文本表示的算法,是将文本数据转换成计算机能够运算的数字或者向量。在自然语言处理领域,文本表示是处理流程的第一步,主要是将文本转换为计算机可以运算的数字。
最传统的文本表示方法就是大名鼎鼎的One-Hot编码,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量中只有一个1, 其他全为 0,1 的位置对应该词在词典中的位置。举个例子:I like writing code,那么转换成独热编码就是:
I —[1 0 0 0], like—[0 1 0 0], writing—[0 0 1 0], code—[0 0 0 1]
One-Hot编码的文本表示方法,确实非常简单易懂,但是以下4个缺点:
(1)实际工业上词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示,简直是内存的灾难。
(2)这样表示数据,数据非常稀疏,稀疏数据的训练效率比较低,我们通常需要更多地数据来训练。
维度高且稀疏的数据常常会导致训练过程中梯度消失,模型无法收敛。
(3)无法体现出词之间的关系,所有转化后的向量都只存在相互正交的关系,无法用余弦相似度的方法求解词之间的相似关系。
(4)这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,本质上来说就是这个向量包含的信息太少了,因为这个文本表示的向量就是用来表达文本信息,这显然不是最好的文本表示的方法。
正是因为One-Hot编码的方式存在各种问题,nlp界各位大佬们又提出了word2vec的文本表示算法,这里的word2vec算法其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。
word2vec算法的背景
任何经典算法的提出,在之前肯定都有无数大佬的努力,大佬们思想的碰撞,灵感的激发,最后成就一个经典的算法,流传于世,被后人敬仰,膜拜,然后封装成接口,内置于框架中,方便地被大家使用。比如CV领域经典的模型alexnet,在alexnet提出之前,卷积操作早就被广泛的用于图像处理领域,而神经网络也早就在上世纪七八十年底被人提出并使用。后来受益于硬件领域的技术发展,Alex Krizhevsky 等人在前人的基础上创造性的提出这个alexnet,并一举在夺下了2012 年 ImageNet LSVRC 的冠军,引 起了很大的轰动,也就开创后来的人工智能领域的盛况。
说回到word2vec这个算法,对这个算法有一些影响的基础研究主要包含以下几个部分:
统计语言模型
统计语言模型是用来计算一个句子的概率的概率模型,它通常基于一个语料库来构建。那什么叫做一个句子的概率呢?假设
W
=
(
w
1
,
w
1
,
.
.
.
.
w
T
)
W = (w_{1}, w_{1},.... w_{T} )
W=(w1,w1,....wT)表示由T个词
w
1
,
w
1
,
.
.
.
.
w
T
w_{1}, w_{1},.... w_{T}
w1,w1,....wT按顺序构成的一个句子,则
w
1
,
w
1
,
.
.
.
.
w
T
w_{1}, w_{1},.... w_{T}
w1,w1,....wT 的联合概率为:
p
(
W
)
=
p
(
w
1
,
w
1
,
.
.
.
.
w
T
)
p(W) = p(w_{1}, w_{1},.... w_{T} )
p(W)=p(w1,w1,....wT)
p(W)被称为语言模型,即用来计算这个句子概率的模型。而根据利用Bayes公式,上式可以被链式地分解为:
p
(
W
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
,
w
2
)
.
.
.
p
(
w
T
∣
w
1
,
w
2
,
.
.
.
w
T
−
1
)
p(W) = p(w_{1})p(w_{2}\mid w_{1})p(w_{3}\mid w_{1},w_{2})...p(w_{T}\mid w_{1},w_{2},...w_{T-1})
p(W)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wT∣w1,w2,...wT−1)
其中的条件概率
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
,
w
2
)
.
.
.
p
(
w
T
∣
w
1
,
w
2
,
.
.
.
w
T
−
1
)
p(w_{1})p(w_{2}\mid w_{1})p(w_{3}\mid w_{1},w_{2})...p(w_{T}\mid w_{1},w_{2},...w_{T-1})
p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wT∣w1,w2,...wT−1)就是语言模型的参数。
其实这里说到统计语言模型,说到条件概率包括说到语言模型参数,就是想引出来一条结论:一个词出现的概率与它前面的所有词都相关。如果假定一个词出现的概率只与它前面固定数目的词相关呢?这就是n-gram模型的基本思想。至于n-gram模型,这里就不详细介绍了,总之,word2vec模型会用到统计语言模型的结论经验,同时也是简化版本的,一个词的出现的概率和其附近几个词关系最为密切。
向量空间模型
用一个连续的稠密向量去刻画一个词的特征就叫着词的分布式表示。词的分布式表示不仅可以直接刻画词与词之间的相似度,还可以建立一个从向量到概率的平滑函数模型,使得相似的词向量可以映射到相近的概率空间上。
向量空间模型(Vector Space Models)可以将字词转化为连续值向量的分布表示,并且其中意思相近的词将被映射到向量空间中相近的位置。向量空间模型在NLP中主要依赖的假设为Distributional Hypothesis,即在相同语境中出现的词其语义也相近。向量空间模型可以分为两类:
(1)计数模型,比如LSA;计数模型统计在语料库中,相邻出现的词的频率,再把这些计数统计结果转为小而稠密的矩阵;
(2)预测模型(比如Neural Probabilisitc Language Models)。而预测模型则根据一个词周围相邻的词推测出这个词,以及它的向量空间。
神经网络语言模型
2003年,Bengio等人发表了一篇开创性的文章:A neural probabilistic language model。在这篇文章里,作者总结出了一套用神经网络建立统计语言模型的框架(Neural Network Language Model)即神经网络语言模型,并首次提出了word embedding的概念,从而奠定了包括word2vec在内后续研究word representation learning的基础。神经网络语言模型的基本思想可以概括如下:
(1)假定词表中的每一个word都对应着一个连续的特征向量;
(2)假定一个连续平滑的概率模型,输入一段词向量的序列,可以输出这段序列的联合概率;
(3)同时学习词向量的权重和概率模型里的参数。
可以看出,基本上神经网络语言模型,是将向量空间模型和统计语言模型结合起来,并加入了神经网络这个结构,从而达到同时学习词向量的权重以及概率模型的参数的效果。
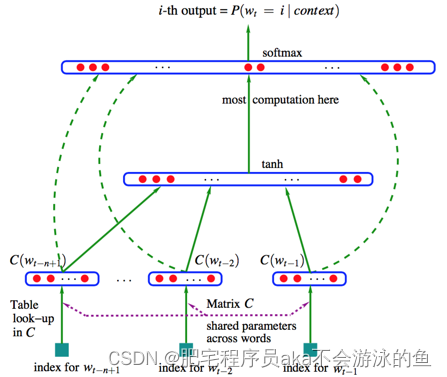
这是神经网络模型的结构图,其中
w
t
−
n
+
1
w_{t-n+1}
wt−n+1,
w
t
−
2
w_{t-2}
wt−2,
w
t
−
1
w_{t-1}
wt−1是输入词,index for
w
t
−
n
+
1
w_{t-n+1}
wt−n+1则是该词的one-hot词向量,Matrix C则是词向量的权重。
word2vec算法
Word2vec主要包含两个模型,连续词袋模型(CBOW)和 Skip-Gram模型。这两个模型非常相似,其区别为CBOW根据源词上下文词汇来预测目标词汇,而Skip-Gram模型做法相反,它通过目标词汇来预测源词汇。举例说明,对同样一个句子:Shenzhen is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。 这里假设滑窗尺寸为1
CBOW可以制造的映射关系为:[Shenzhen,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为 is—>[Shenzhen,a],a—>[is,nice],nice —>[a, city]
这里的映射就在模型中,就是单词的one-hot编码。
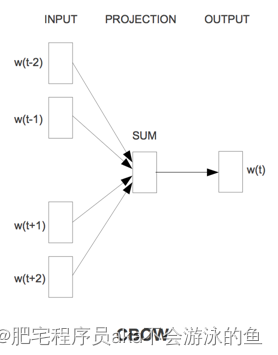
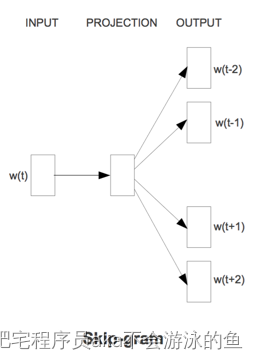
其实这两张图基本上就把word2vec表的很清楚了,就是输入一个词,输出其相邻的词,中间的框就是一个浅的隐藏层,也是我们想要得到的word embedding权重矩阵。对于word2vec这个算法来说,这个设计很巧妙,模型的输入和输出的都是词的one-hot编码,非常简单,而每个词都有多个预测结果来不断的更隐藏层的参数,达到优化权重矩阵的效果,对了,这个模型的损失函数是交叉熵损失,这是比较明显的,而训练保存到权重矩阵是我们想要,而不是整个前向传播的过程。这点和一般的神经网络任务不一样,一般的神经网络任务想要达到的效果就是,给一个输入,经过前向传播,得到想要输出,任务完成。
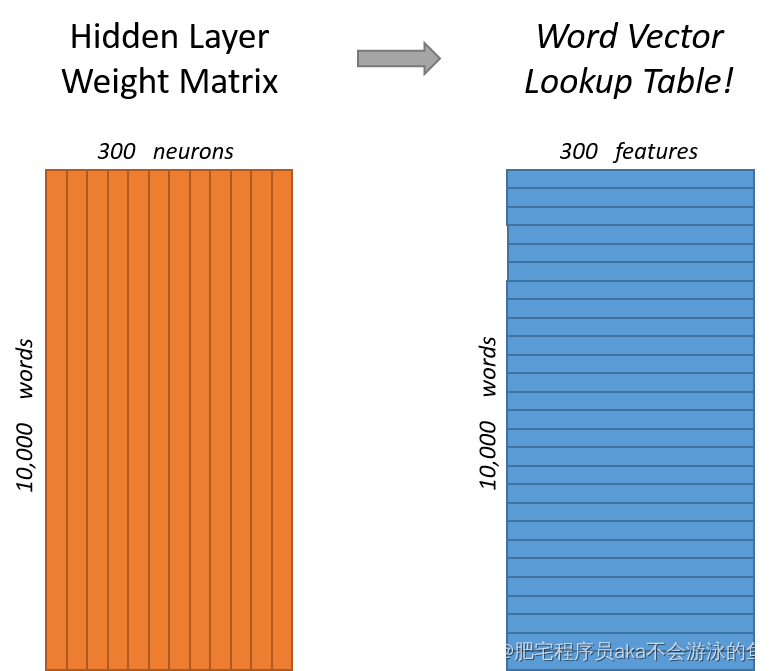
这里还需要说明一下,通过word embedding权重矩阵如何得到想要的词向量表示:

上图中35的矩阵就是权重矩阵,15的矩阵则是输入的词向量编码,通过索引1的位置,就可以获取到这个词的向量表示。当然,如果词向量维度是1000,而我们想要学习到的词向量维度是300的话,那么这个权重矩阵维度则是1000*300,像下图所示:
gensim中word2vec的使用
gensim(generate similarity)是一个简单高效的自然语言处理Python库,用于抽取文档的语义主题(semantic topics)。Gensim的输入是原始的、无结构的数字文本(纯文本),内置的算法包括Word2Vec,FastText,潜在语义分析(Latent Semantic Analysis,LSA),潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)等等。
使用gensim训练英文word2vec模型十分简单,这里用的是gensim中自带的文本数据。
from gensim.test.utils import common_texts
from gensim.models import Word2Vec
print(common_texts[:200])
model = Word2Vec(sentences=common_texts, vector_size=100,
window=5, min_count=1, workers=4)
print(model)
打印结果如下:
[['human', 'interface', 'computer'], ['survey', 'user', 'computer', 'system', 'response', 'time'], ['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'], ['user', 'response', 'time'], ['trees'], ['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey']]
<gensim.models.word2vec.Word2Vec at 0x7fd9d0c67b20>
模型保存和继续训练的代码如下:
model.save("word2vec.model")
# 先保存,再继续接力训练
model = Word2Vec.load("word2vec.model")
model.train([["hello", "world"]], total_examples=1, epochs=1)
print(model)
打印结果如下:
<gensim.models.word2vec.Word2Vec at 0x7fd9ce7681c0>
获取词向量
vector1 = model.wv['computer'] # get numpy vector of a word
print(vector1)
打印结果如下:
array([-0.00515774, -0.00667028, -0.0077791 , 0.00831315, -0.00198292,
-0.00685696, -0.0041556 , 0.00514562, -0.00286997, -0.00375075,
0.0016219 , -0.0027771 , -0.00158482, 0.0010748 , -0.00297881,
0.00852176, 0.00391207, -0.00996176, 0.00626142, -0.00675622,
0.00076966, 0.00440552, -0.00510486, -0.00211128, 0.00809783,
-0.00424503, -0.00763848, 0.00926061, -0.00215612, -0.00472081,
0.00857329, 0.00428458, 0.0043261 , 0.00928722, -0.00845554,
0.00525685, 0.00203994, 0.0041895 , 0.00169839, 0.00446543,
0.00448759, 0.0061063 , -0.00320303, -0.00457706, -0.00042664,
0.00253447, -0.00326412, 0.00605948, 0.00415534, 0.00776685,
0.00257002, 0.00811904, -0.00138761, 0.00808028, 0.0037181 ,
-0.00804967, -0.00393476, -0.0024726 , 0.00489447, -0.00087241,
-0.00283173, 0.00783599, 0.00932561, -0.0016154 , -0.00516075,
-0.00470313, -0.00484746, -0.00960562, 0.00137242, -0.00422615,
0.00252744, 0.00561612, -0.00406709, -0.00959937, 0.00154715,
-0.00670207, 0.0024959 , -0.00378173, 0.00708048, 0.00064041,
0.00356198, -0.00273993, -0.00171105, 0.00765502, 0.00140809,
-0.00585215, -0.00783678, 0.00123304, 0.00645651, 0.00555797,
-0.00897966, 0.00859466, 0.00404815, 0.00747178, 0.00974917,
-0.0072917 , -0.00904259, 0.0058377 , 0.00939395, 0.00350795],
dtype=float32)
获取相似的词向量:
sims = model.wv.most_similar('computer', topn=10) # get other similar words
print(sims)
打印结果:
[('system', 0.21617142856121063),
('survey', 0.044689200818538666),
('interface', 0.01520337350666523),
('time', 0.0019510575802996755),
('trees', -0.03284314647316933),
('human', -0.0742427185177803),
('response', -0.09317588806152344),
('graph', -0.09575346857309341),
('eps', -0.10513805598020554),
('user', -0.16911622881889343)]
参考文献
word2vec原理及gensim中word2vec的使用
word2vec前世今生
Word2vec Tutorial








![[附源码]Python计算机毕业设计SSM基于web的火车订票管理系统(程序+LW)](https://img-blog.csdnimg.cn/98782335e5ce46b0b4fd1295b0b0d7c3.png)