collect_set函数
今天又get到一个小技能,掌握了hive一个关于列转行专用函数 collect_set函数。
在这里做个学习笔记。
collect_set是Hive内置的一个聚合函数, 结果返回一个消除了重复元素的对象集合, 其返回值类型是 array 。
和collect_set相似的还有另一个函数collect_list,这个我们后面再谈。
在实际应用中,我们可能会遇到需要类似这样的一个需求,就是需要查出各个品牌对应的所有分类,
品牌分类表数据结构大概是这样的:
brand_name,brand_classify
品牌1 家电
品牌1 家具
品牌1 数码
品牌2 空调
品牌2 饮水机
期望的结果是:
品牌1 家电,家具,数码
品牌2 空调,饮水机
这时候我们就可以使用collect_set函数来实现我们的需求。
select
brand_name,
concat_ws(',', collect_set(brand_classify)) as brand_classify
from tb_brand_classify
group by brand_name;使用了collect_set函数,是不是感觉很容易就实现了需求。
下面我们来实践操作下,这样印象会更深刻些。
1.创建原始表 品牌分类表 tb_brand_classify
drop table if exists tb_brand_classify;create table if not exists tb_brand_classify (brand_name string, brand_classify string);2.初始化数据
insert into table tb_brand_classify values('品牌1','家电');
insert into table tb_brand_classify values('品牌1','家具');
insert into table tb_brand_classify values('品牌1','数码');
insert into table tb_brand_classify values('品牌2','空调');
insert into table tb_brand_classify values('品牌2','饮水机');3.查询表的数据
select * from tb_brand_classify执行结果:
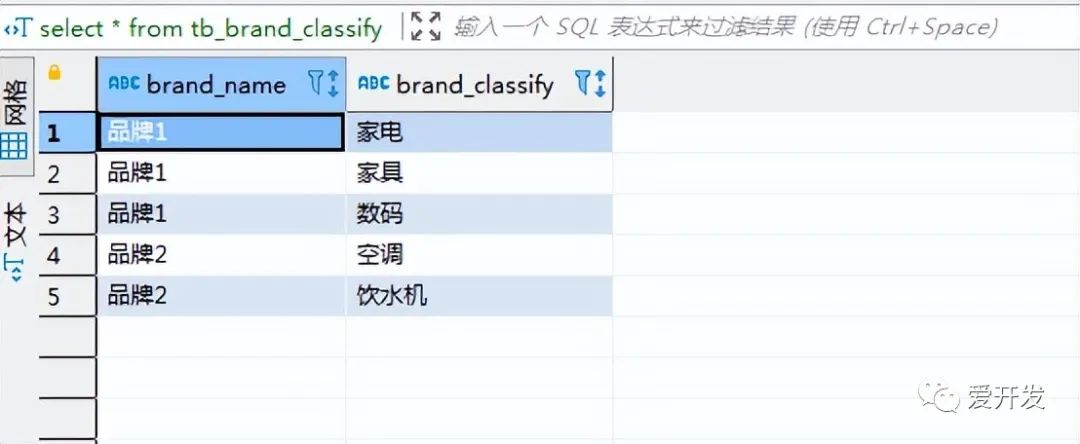
4.上述的需求我就可以使用 collect_set 函数来实现, 具体sql如下:
select
brand_name,
concat_ws(',', collect_set(brand_classify)) as brand_classify
from tb_brand_classify
group by brand_name;执行结果:
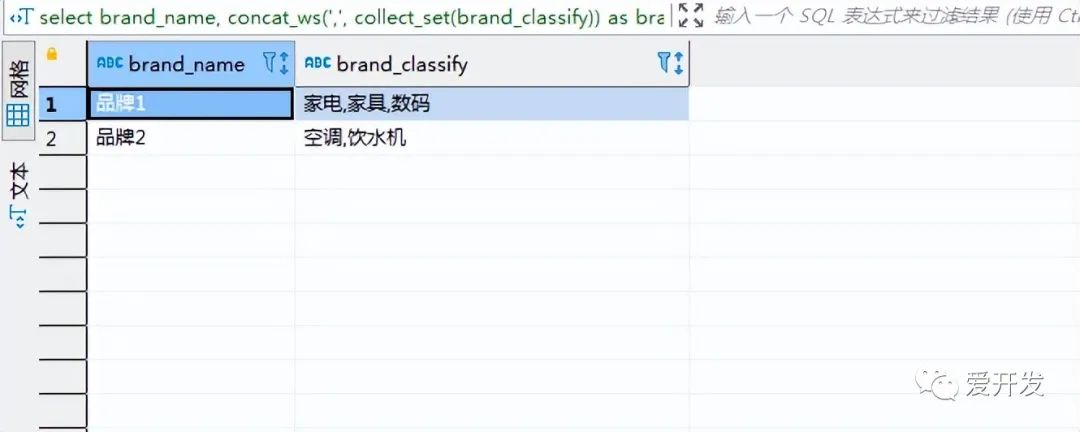
拓展:
还可以用下标可以取具体某一个
select
brand_name,
collect_set(brand_classify)[0]
from tb_brand_classify
group by brand_name;执行结果:
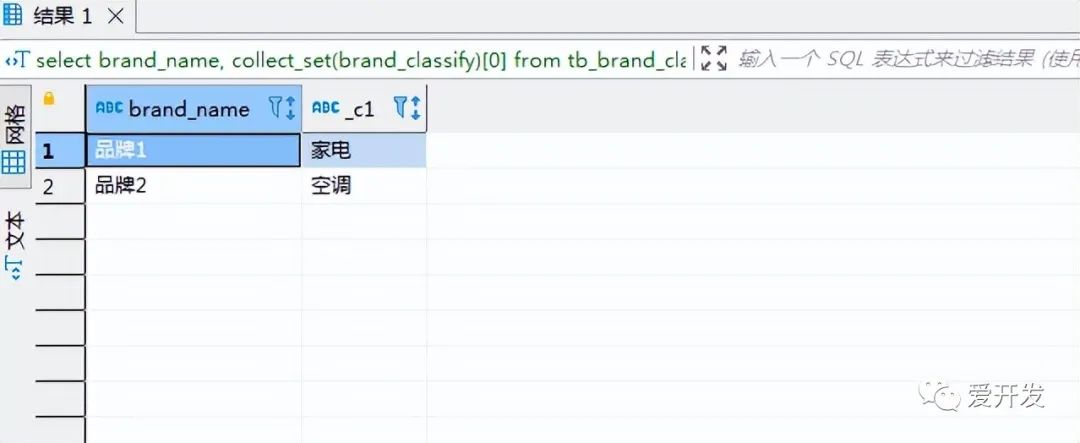
文章开头我们提到了collect_list函数,collect_list与collect_set最大的区别就是列的值不去重;我们把collect_set换成collect_list 执行看下。
select
brand_name,
concat_ws(',', collect_list(brand_classify))
from tb_brand_classify group by brand_name;发现跟之前是一样的,那是因为我们的类目中没有重复,要是有重复,使用collect_list就会重复了。
需要注意的是collect_set是无序集合,如果需要排序我们可以改成collect_list或sort_array进行排序。
concat_ws(',', sort_array(collect_set(brand_classify), false))sort_array(e: column, asc: boolean)将array中元素排序(自然排序),默认asc。
好了,今天的分享就先到这。
由于水平有限,文中纰漏之处在所难免,欢迎大家批评指正。



![[附源码]Python计算机毕业设计SSM基于web的火车订票管理系统(程序+LW)](https://img-blog.csdnimg.cn/98782335e5ce46b0b4fd1295b0b0d7c3.png)