一、概述
HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是在文件创建时的写入或者在现有文件之后的添加操作。HDFS保证一个文件在一个时刻只被一个调用者执行写操作,而可以被多个调用者执行读操作。
二、HDFS结构
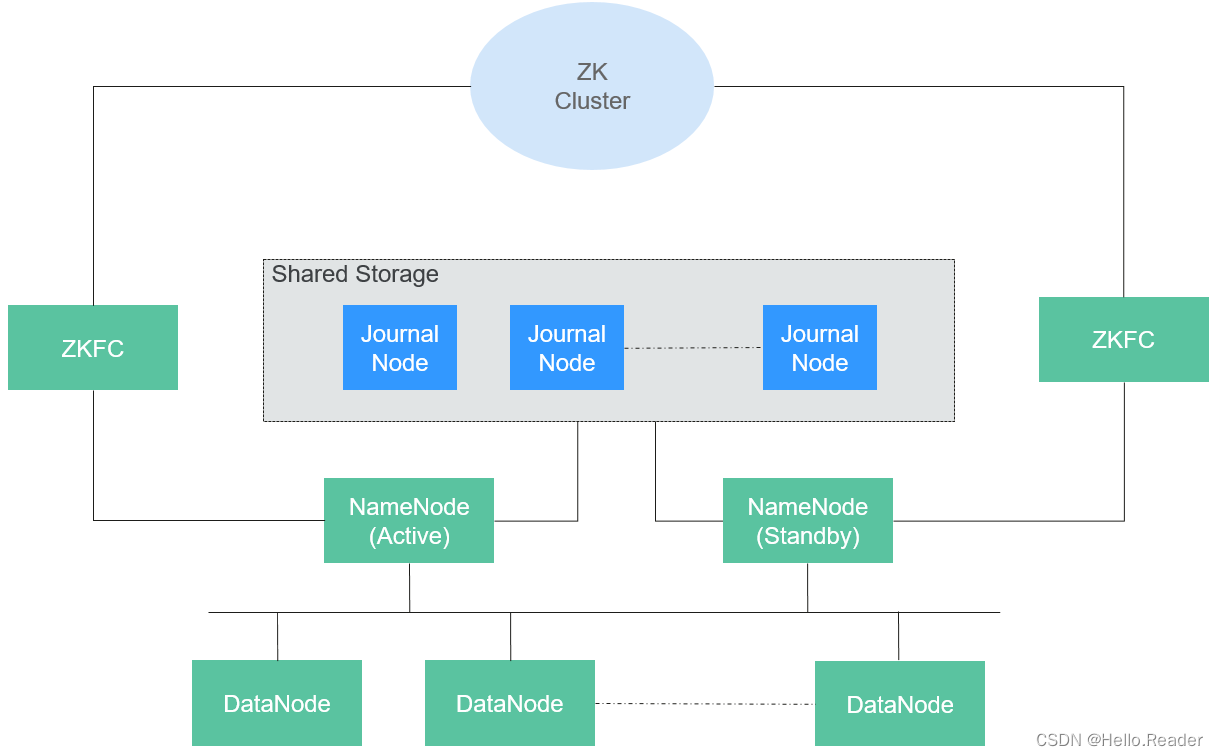
HDFS包含主、备NameNode和多个DataNode,如下图所示。
HDFS是一个Master/Slave的架构,在Master上运行NameNode,而在每一个Slave上运行DataNode,ZKFC需要和NameNode一起运行。
NameNode和DataNode之间的通信都是建立在TCP/IP的基础之上的。NameNode、DataNode、ZKFC和JournalNode能部署在运行Linux的服务器上。
| 名称 | 描述 |
|---|---|
| NameNode | 用于管理文件系统的命名空间、目录结构、元数据信息以及提供备份机制等,分为:1. Active NameNode:管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息;记录写入的每个“数据块”与其归属文件的对应关系。2. Standby NameNode:与Active NameNode中的数据保持同步;随时准备在Active NameNode出现异常时接管其服务。3.Observer NameNode:与Active NameNode中的数据保持同步,处理来自客户端的读请求。 |
| DataNode | 用于存储每个文件的“数据块”数据,并且会周期性地向NameNode报告该DataNode的数据存放情况。 |
| JournalNode | HA集群下,用于同步主备NameNode之间的元数据信息。 |
| ZKFC | ZKFC是需要和NameNode一一对应的服务,即每个NameNode都需要部署ZKFC。它负责监控NameNode的状态,并及时把状态写入ZooKeeper。ZKFC也有选择谁作为Active NameNode的权利。 |
| ZK Cluster | ZooKeeper是一个协调服务,帮助ZKFC执行主NameNode的选举。 |
| HttpFS gateway | HttpFS是个单独无状态的gateway进程,对外提供webHDFS接口,对HDFS使用FileSystem接口对接。可用于不同Hadoop版本间的数据传输,及用于访问在防火墙后的HDFS(HttpFS用作gateway)。 |
HttpFS是个单独无状态的gateway进程,对外提供webHDFS接口,对HDFS使用FileSystem接口对接。可用于不同Hadoop版本间的数据传输,及用于访问在防火墙后的HDFS(HttpFS用作gateway)。
三、HDFS原理
使用HDFS的副本机制来保证数据的可靠性,HDFS中每保存一个文件则自动生成1个备份文件,即共2个副本。HDFS副本数可通过“dfs.replication”参数查询。
- 当集群中Core节点规格选择为非本地盘(hdd)时,若集群中只有一个Core节点,则HDFS默认副本数为1。若集群中Core节点数大于等于2,则HDFS默认副本数为2。
- 当集群中Core节点规格选择为本地盘(hdd)时,若集群中只有一个Core节点,则HDFS默认副本数为1。若集群中有两个Core节点,则HDFS默认副本数为2。若集群中Core节点数大于等于3,则HDFS默认副本数为3。
HDFS组件支持以下部分特性:
- HDFS组件支持纠删码,使得数据冗余减少到50%,且可靠性更高,并引入条带化的块存储结构,最大化的利用现有集群单节点多磁盘的能力,使得数据写入性能在引入编码过程后,仍和原来多副本冗余的性能接近。
- 支持HDFS组件上节点均衡调度和单节点内的磁盘均衡调度,有助于扩容节点或扩容磁盘后的HDFS存储性能提升。
关于Hadoop的架构和详细原理介绍,请参见:http://hadoop.apache.org/。
四、HDFS HA方案背景
在Hadoop2.0.0之前,HDFS集群中存在单点故障问题。由于每个集群只有一个NameNode,如果NameNode所在机器发生故障,将导致HDFS集群无法使用,除非NameNode重启或者在另一台机器上启动。这在两个方面影响了HDFS的整体可用性:
- 当异常情况发生时,如机器崩溃,集群将不可用,除非重新启动NameNode。
- 计划性的维护工作,如软硬件升级等,将导致集群停止工作。
针对以上问题,HDFS高可用性方案通过自动或手动(可配置)的方式,在一个集群中为NameNode启动一个热替换的NameNode备份。当一台机器故障时,可以迅速地自动进行NameNode主备切换。或者当主NameNode节点需要进行维护时,通过集群管理员控制,可以手动进行NameNode主备切换,从而保证集群在维护期间的可用性。
有关HDFS自动故障转移功能,请参阅:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoophdfs/HDFSHighAvailabilityWithQJM.html#Automatic_Failover
五、HDFS HA实现方案
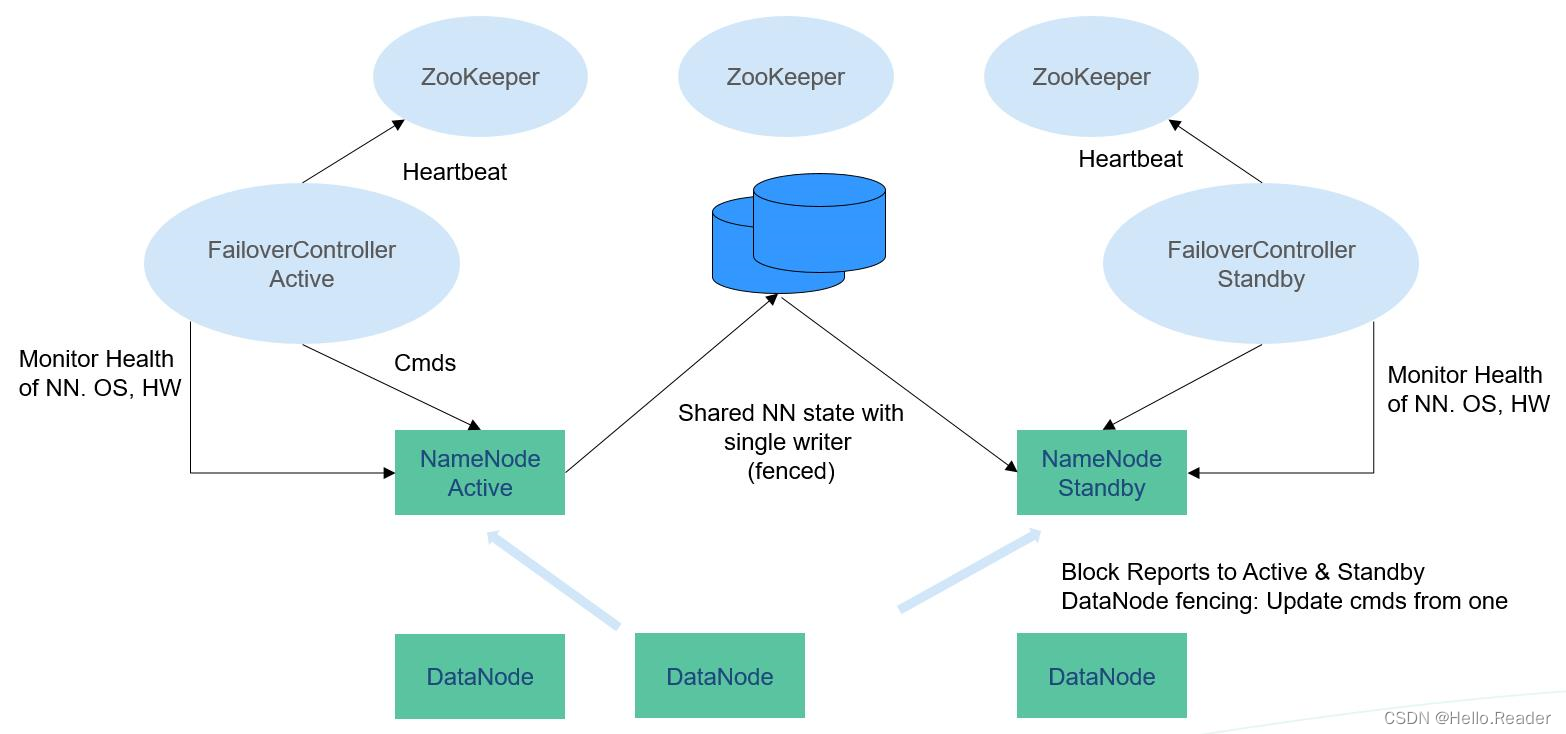
在一个典型的HA集群中(如上图所示),需要把两个NameNodes配置在两台独立的机器上。在任何一个时间点,只有一个NameNode处于Active状态,另一个处于Standby状态。Active节点负责处理所有客户端操作,Standby节点时刻保持与Active节点同步的状态以便在必要时进行快速主备切换。
为保持Active和Standby节点的数据一致性,两个节点都要与一组称为JournalNode的节点通信。当Active对文件系统元数据进行修改时,会将其修改日志保存到大多数的JournalNode节点中,例如有3个JournalNode,则日志会保存在至少2个节点中。Standby节点监控JournalNodes的变化,并同步来自Active节点的修改。根据修改日志,Standby节点将变动应用到本地文件系统元数据中。一旦发生故障转移,Standby节点能够确保与Active节点的状态是一致的。这保证了文件系统元数据在故障转移时在Active和Standby之间是完全同步的。
为保证故障转移快速进行,Standby需要时刻保持最新的块信息,为此DataNodes同时向两个NameNodes发送块信息和心跳。
对一个HA集群,保证任何时刻只有一个NameNode是Active状态至关重要。否则,命名空间会分为两部分,有数据丢失和产生其他错误的风险。为保证这个属性,防止“split-brain”问题的产生,JournalNodes在任何时刻都只允许一个NameNode写入。在故障转移时,将变为Active状态的NameNode获得写入JournalNodes的权限,这会有效防止其他NameNode的Active状态,使得切换安全进行。
关于HDFS高可用性方案的更多信息,可参考如下链接:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoophdfs/HDFSHighAvailabilityWithQJM.html
六、HDFS和HBase的关系
HDFS是Apache的Hadoop项目的子项目,HBase利用Hadoop HDFS作为其文件存储系统。HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持。除了HBase产生的一些日志文件,HBase中的所有数据文件都可以存储在Hadoop HDFS文件系统上。
七、HDFS和MapReduce的关系
- HDFS是Hadoop分布式文件系统,具有高容错和高吞吐量的特性,可以部署在价格低廉的硬件上,存储应用程序的数据,适合有超大数据集的应用程序。
- 而MapReduce是一种编程模型,用于大数据集(大于1TB)的并行运算。在MapReduce程序中计算的数据可以来自多个数据源,如Local FileSystem、HDFS、数据库等。最常用的是HDFS,可以利用HDFS的高吞吐性能读取大规模的数据进行计算。同时在计算完成后,也可以将数据存储到HDFS。
八、HDFS和Spark的关系
通常,Spark中计算的数据可以来自多个数据源,如Local File、HDFS等。最常用的是HDFS,用户可以一次读取大规模的数据进行并行计算。在计算完成后,也可以将数据存储到HDFS。
分解来看,Spark分成控制端(Driver)和执行端(Executor)。控制端负责任务调度,执行端负责任务执行。
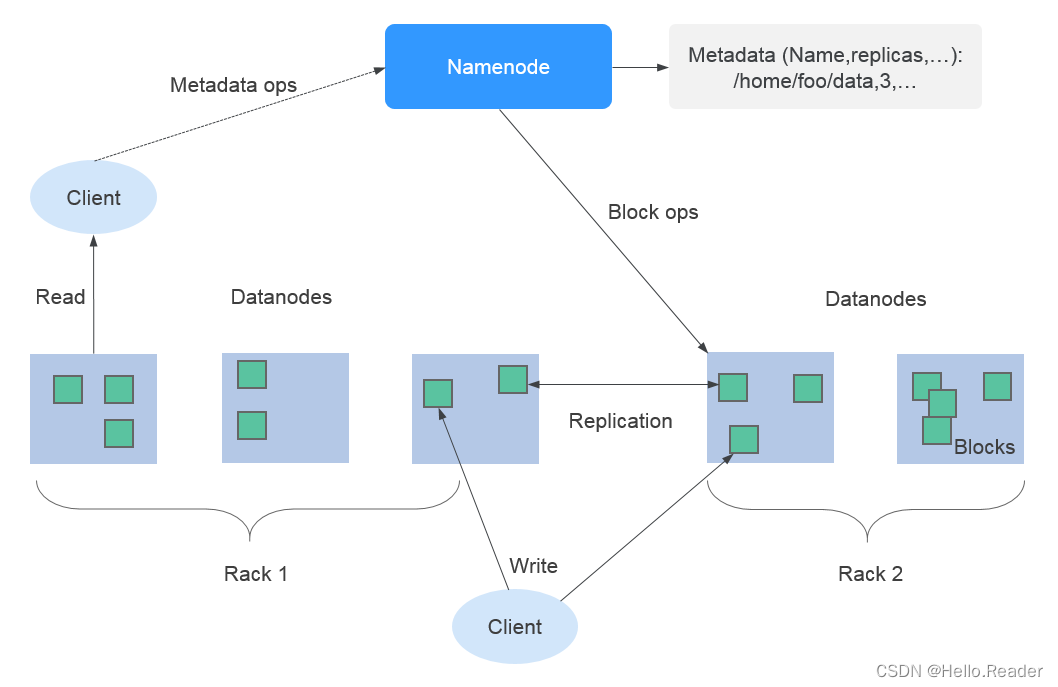
读取文件的过程如下图所示。
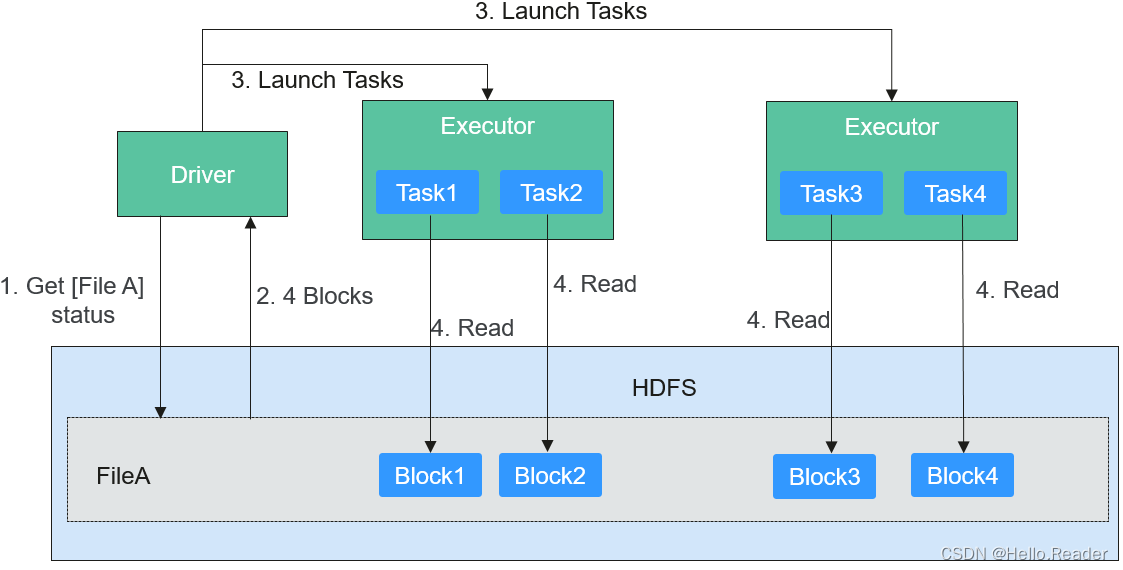
读取文件步骤的详细描述如下所示:
- Driver与HDFS交互获取File A的文件信息。
- HDFS返回该文件具体的Block信息。
- Driver根据具体的Block数据量,决定一个并行度,创建多个Task去读取这些文件Block。
- 在Executor端执行Task并读取具体的Block,作为RDD(弹性分布数据集)的一部分。
写入文件的过程如下图所示。
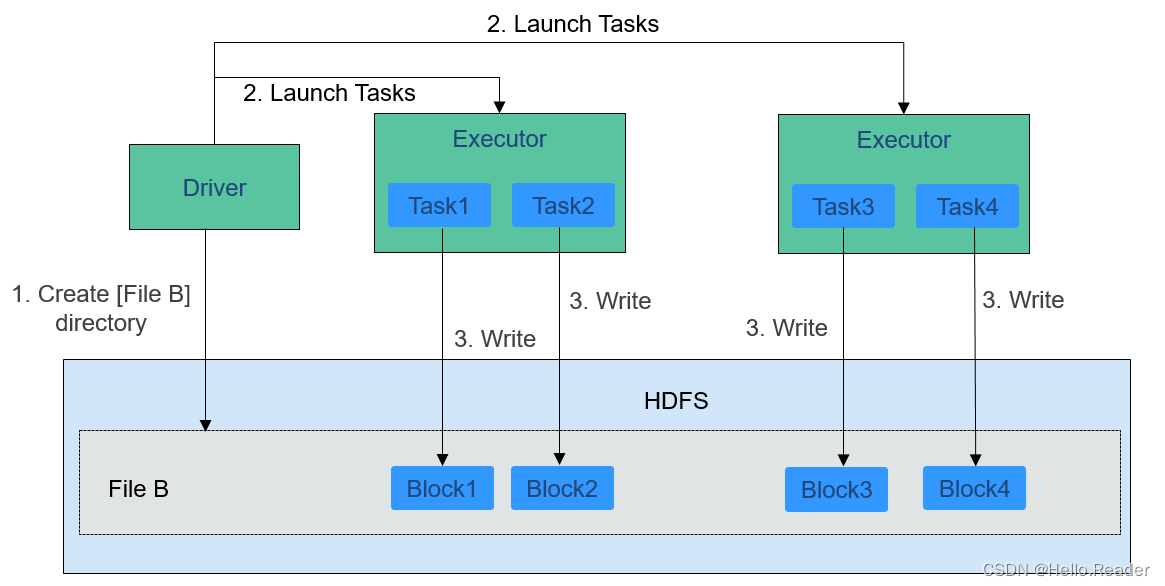
HDFS文件写入的详细步骤如下所示:
- Driver创建要写入文件的目录。
- 根据RDD分区分块情况,计算出写数据的Task数,并下发这些任务到Executor。
- Executor执行这些Task,将具体RDD的数据写入到步骤1创建的目录下。
九、HDFS和ZooKeeper的关系
ZooKeeper与HDFS的关系如下图所示
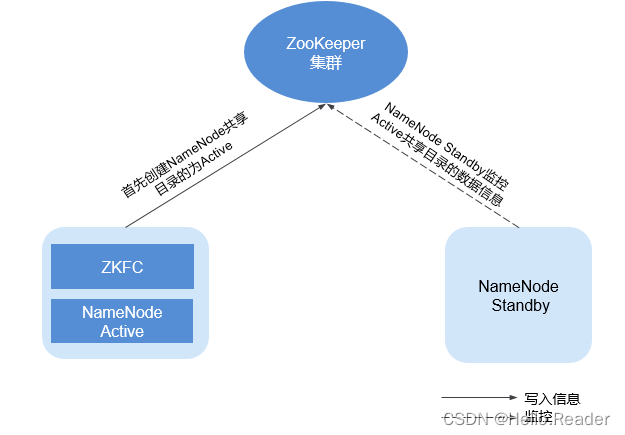
ZKFC(ZKFailoverController)作为一个ZooKeeper集群的客户端,用来监控NameNode的状态信息。ZKFC进程仅在部署了NameNode的节点中存在。HDFS NameNode的Active和Standby节点均部署有zkfc进程。
- HDFS NameNode的ZKFC连接到ZooKeeper,把主机名等信息保存到ZooKeeper中,即“/hadoop-ha”下的znode目录里。先创建znode目录的NameNode节点为主节点,另一个为备节点。HDFS NameNode Standby通过ZooKeeper定时读取NameNode信息。
- 当主节点进程异常结束时,HDFS NameNode Standby通过ZooKeeper感知“/hadoop-ha”目录下发生了变化,NameNode会进行主备切换。