文章目录
- 概述
- 分页方案
- from-size
- 内部执行过程
- 【Query】阶段
- 【fetch】阶段
- 潜在问题
- 注意事项
- 深度分页
- Scroll (Scroll遍历数据)
- Scroll Scan
- Sliced Scroll
- Search After
- 基于pit机制的search after
- 小结

概述
ElasticSearch是一款强大的搜索引擎,它能够帮助我们快速地搜索海量数据。然而,在处理大量数据时,ElasticSearch的性能可能会受到影响。其中一个常见的问题是深度分页,也就是当我们需要获取大量数据时,ElasticSearch需要处理的数据量太大,导致性能下降。
Elasticsearch 深度分页问题的本质是在进行分页查询时,由于每个分片都需要生成大量的数据,并将这些数据发送到协调节点进行汇总,因此随着查询深度的增加,每个分片需要生成的数据条数也越来越大,从而导致查询效率降低。
先说结论: 在 Elasticsearch 中,也应该尽量避免使用深度分页 。就如同在使用关系型数据库中,也是不能很好地解决深度分页的问题,因此要注意甚至明确禁止使用深度分页
今天闲聊一下 Elasticsearch 中分页的相关知识点
…

分页方案
https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html
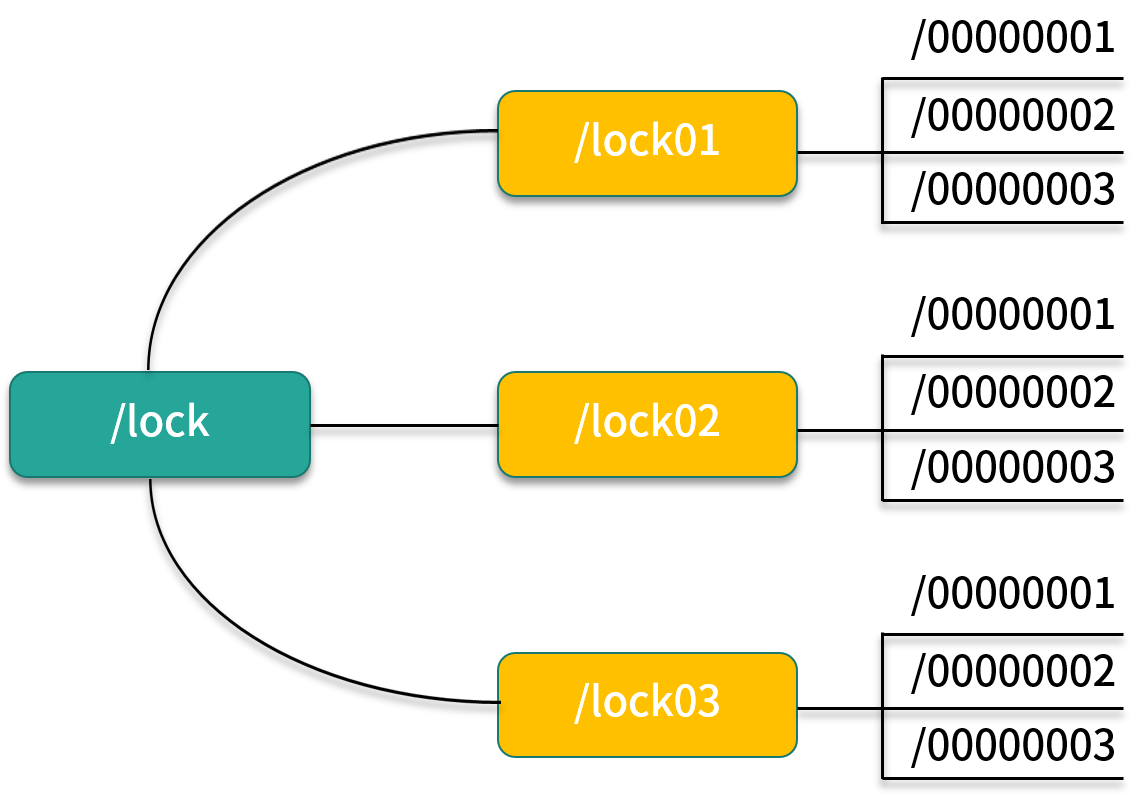
我们也看看BBOSS的深度分页解决方案
https://esdoc.bbossgroups.com/#/README

from-size
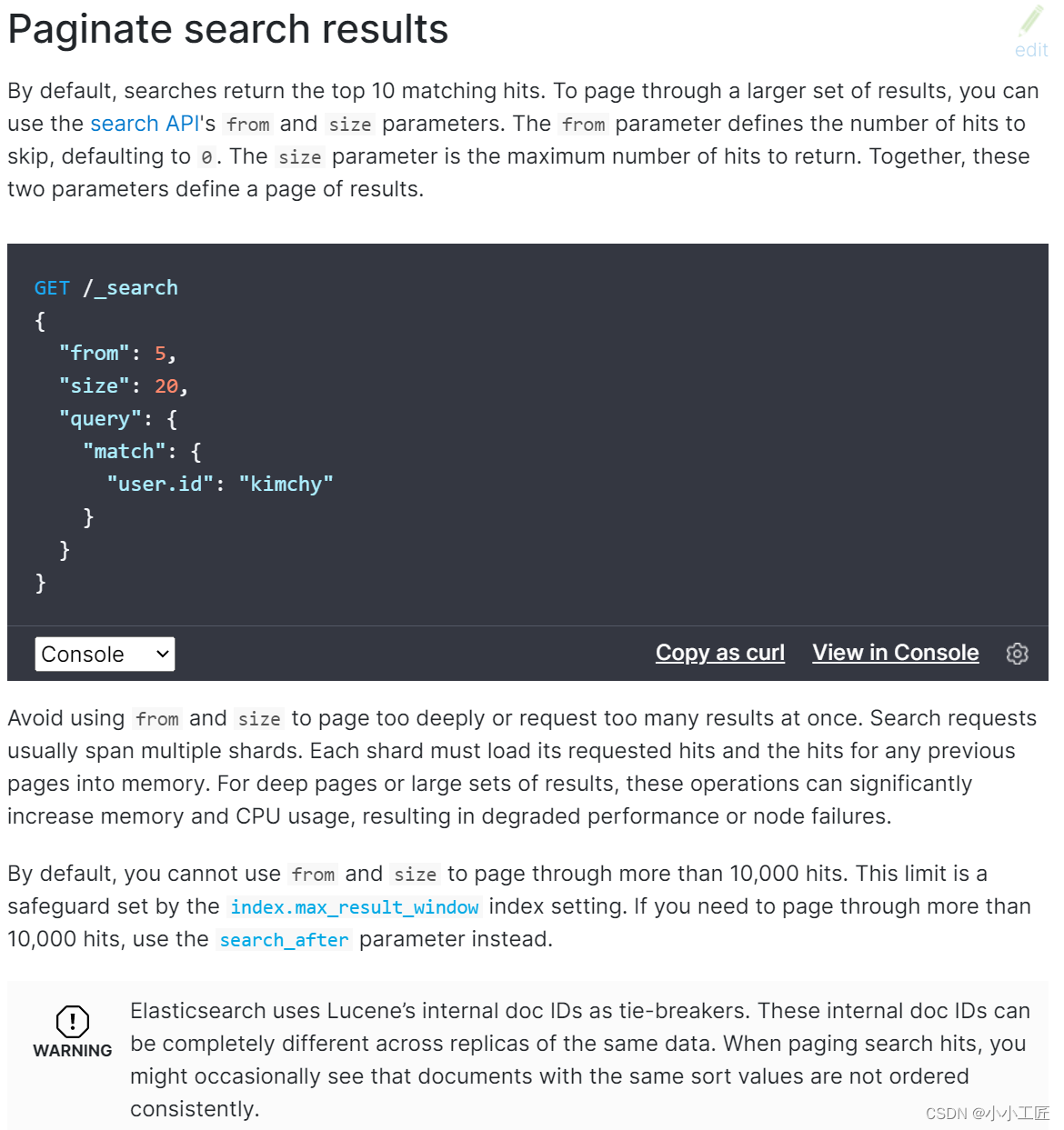
在ES中,分页查询默认返回最顶端的10条匹配hits。
如果需要分页,需要使用from和size参数。
- from参数定义了需要跳过的hits数,默认为0;
- size参数定义了需要返回的hits数目的最大值。
GET /_search
{
"from": 5,
"size": 20,
"query": {
"match": {
"user.id": "kimchy"
}
}
}
上面的查询表示从搜索结果中取第5条开始的20条数据。
内部执行过程
在ES中,搜索是一个典型的两阶段过程,query 和 fetch 阶段。
简单来说
- query 阶段确定要取哪些doc
- fetch 阶段取出具体的 doc
【Query】阶段
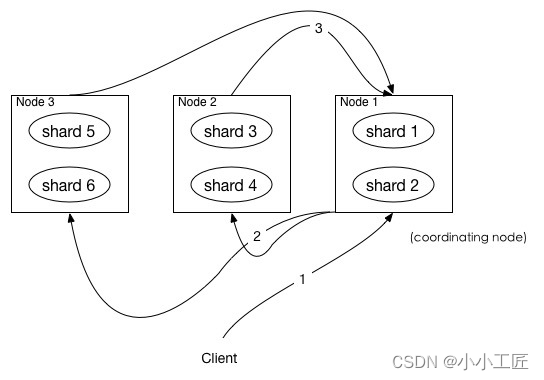
如图所示,描述了一次搜索请求的 query 阶段:·
- Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为
from + size的优先级队列用来存结果,我们称 node1 为coordinating node协调节点。 coordinating node将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为from + size 的优先级队列里,可以把优先级队列理解为一个包含top N结果的列表。- 每个 shard 把暂存在自身优先级队列里的数据返回给
coordinating node,coordinating node拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。
比如上面的例子, 6个shard , 那么 coordinating node 就会拿到(from + size) * 6条数据,然后合并并排序后选择前面的from + size条数据存到优先级队列,以便 fetch 阶段使用。
另外,各个分片返回给 coordinating node 的数据用于选出前from + size条数据,所以,只需要返回唯一标记 doc 的_id以及用于排序的_score即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
【fetch】阶段
query 阶段知道了要取哪些数据,但是并没有取具体的数据, fetch 阶段要做的就是去根据返回的doc的_id取数据。
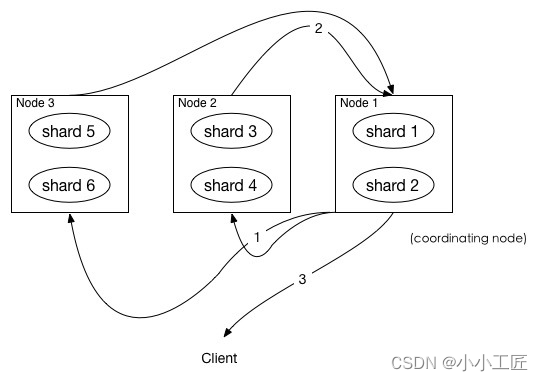
coordinating node发送 GET 请求到相关shards。- shard 根据 doc 的
_id取到数据详情,然后返回给coordinating node。 coordinating node返回数据给 Client。
coordinating node 的优先级队列里有from + size 个_doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前100条数据是不需要取的,只需要取优先级队列里的第101到110条数据即可。
需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 multi-get 来避免多次去同一分片取数据,从而提高性能。
潜在问题
假设在一个有 5 个主分片的索引中搜索。当请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
当我们请求第 1000 页—结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
注意事项
-
size的大小不能超过
index.max_result_window这个参数的设置,默认为10000。如果搜索size大于10000,需要设置
index.max_result_window参数PUT _settings { "index": { "max_result_window": "10000000" } } -
_doc将在未来的版本移除
https://www.elastic.co/cn/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0
https://elasticsearch.cn/article/158

深度分页
深度分页问题大致可以分为两类:
- 随机跳转页面----> 随机深度分
- 只能一页一页往下查询 -----> 滚动深度分页
Scroll (Scroll遍历数据)

我们可以把scroll理解为数据库里的cursor, 所以 scroll并不适合用来做实时搜索,而更适合用于后台批处理任务 ,所以它的主要用途是 不是为了实时查询数据,而是为了一次性查询大量甚至是全部的数据。
scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个scroll查询时的快照。在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。
但是它相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
scroll可以分为初始化和遍历两部,初始化时将所有符合搜索条件的搜索结果缓存起来(
这里只是缓存的doc_id,而并不是真的缓存了所有的文档数据,取数据是在fetch阶段完成的),可以理解成快照。
在遍历时,从这个快照里取数据,也就是说,在初始化后,对索引插入、删除、更新数据都不会影响遍历结果。
用法如下:
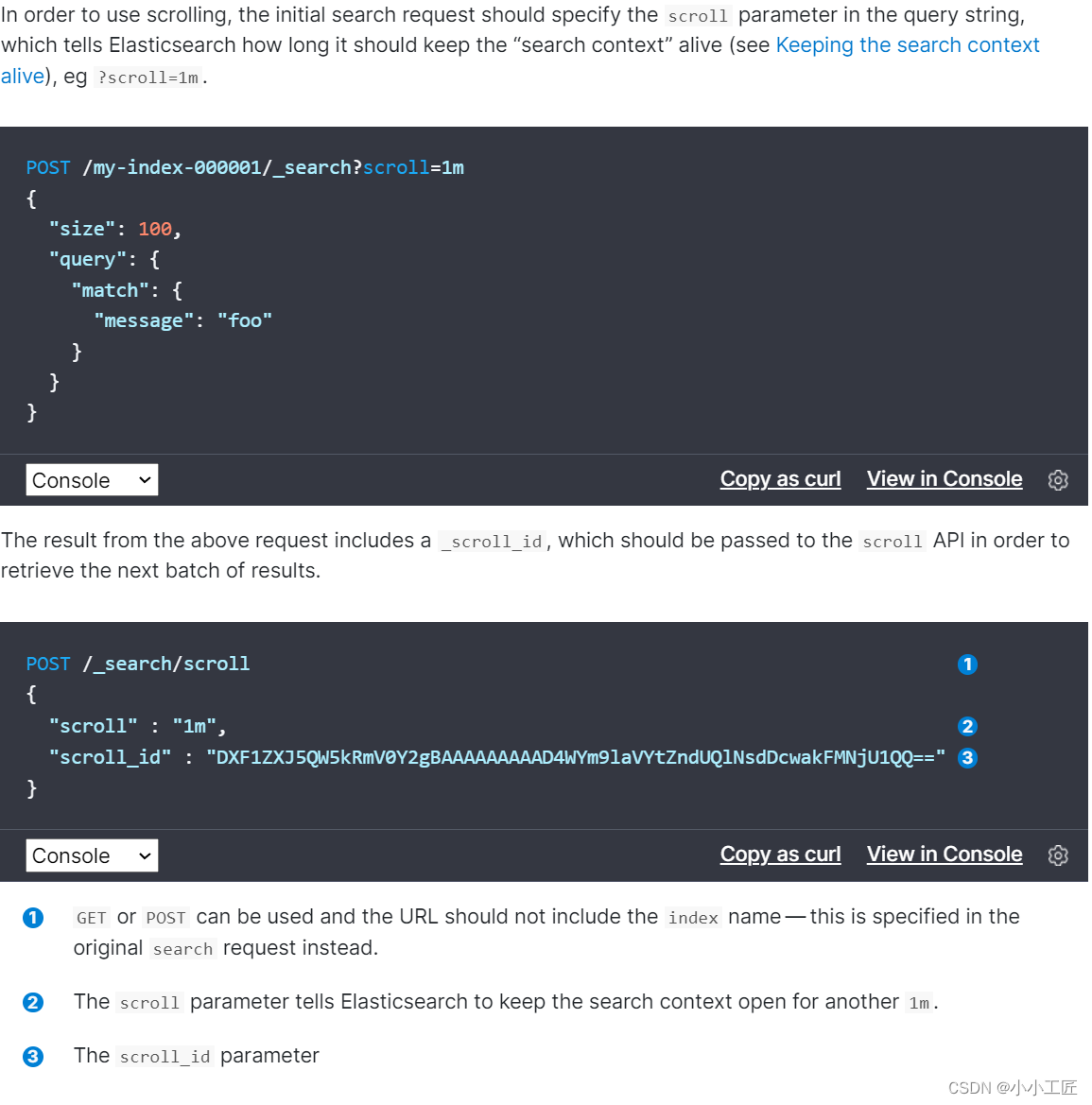
初始化指明 index 和 type,然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的search请求一样。
结果中会返回一个_scroll_id,_scroll_id用来下次取数据用。
这里的scroll_id即 上一次遍历取回的_scroll_id或者是初始化返回的_scroll_id,同样的,需要带 scroll 参数。
重复这一步骤,直到返回的数据为空,即遍历完成。
注意,每次都要传参数 scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。
设置scroll的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长,毕竟空间有限。
缺点:
- scroll_id会占用大量的资源(特别是排序的请求)
- 同样的,scroll后接超时时间,频繁的发起scroll请求,会出现一些列问题。
- 是生成的历史快照,对于数据的变更不会反映到快照上。
优点:
- 适用于非实时处理大量数据的情况,比如要进行数据迁移或者索引变更之类的。
Scroll Scan
ES提供了scroll scan方式进一步提高遍历性能,但是scroll scan不支持排序,因此scroll scan适合不需要排序的场景
不考虑排序的时候,可以结合SearchType.SCAN使用。
POST /my_index/my_type/_search?search_type=scan&scroll=1m&size=50
{
"query": { "match_all": {}}
}
需要指明参数:
- search_type:赋值为scan,表示采用 Scroll Scan 的方式遍历,同时告诉 Elasticsearch 搜索结果不需要排序。
- scroll:同上,传时间。
- size:与普通的 size 不同,这个 size 表示的是每个 shard 返回的 size 数,最终结果最大为
number_of_shards * size。
Scroll Scan与Scroll的区别
- Scroll-Scan结果没有排序,按index顺序返回,没有排序,可以提高取数据性能。
- 初始化时只返回 _scroll_id,没有具体的hits结果
- size控制的是每个分片的返回的数据量,而不是整个请求返回的数据量。
Sliced Scroll
如果数据量很大,用Scroll遍历数据那确实是接受不了,现在Scroll接口可以并发来进行数据遍历了。
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,比用Scroll遍历要快很多倍。
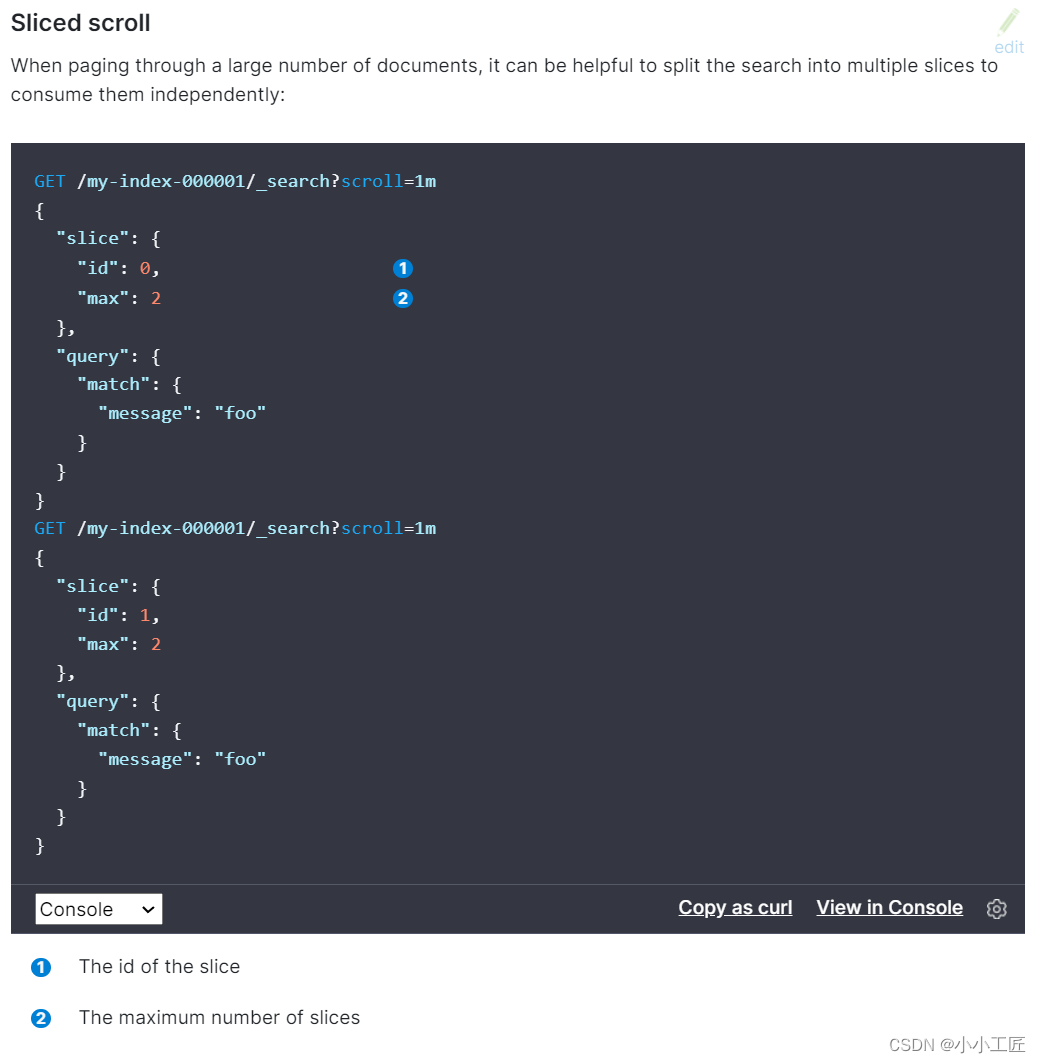
上边的示例可以单独请求两块数据,最终五块数据合并的结果与直接scroll scan相同。
其中max是分块数,id是第几块。
官方文档中建议max的值不要超过shard的数量,否则可能会导致内存爆炸。
Search After
Search_after是 ES 5 新引入的一种分页查询机制,其原理几乎就是和scroll一样,因此代码也几乎是一样的。
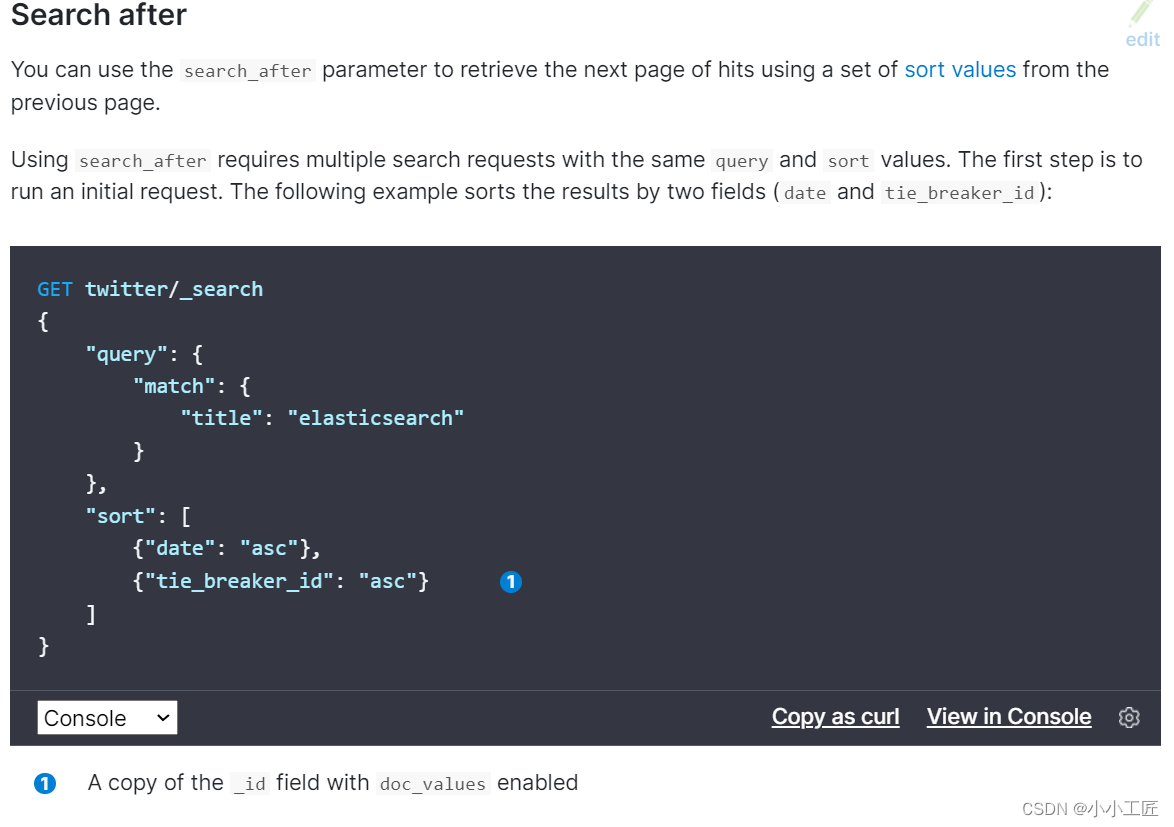
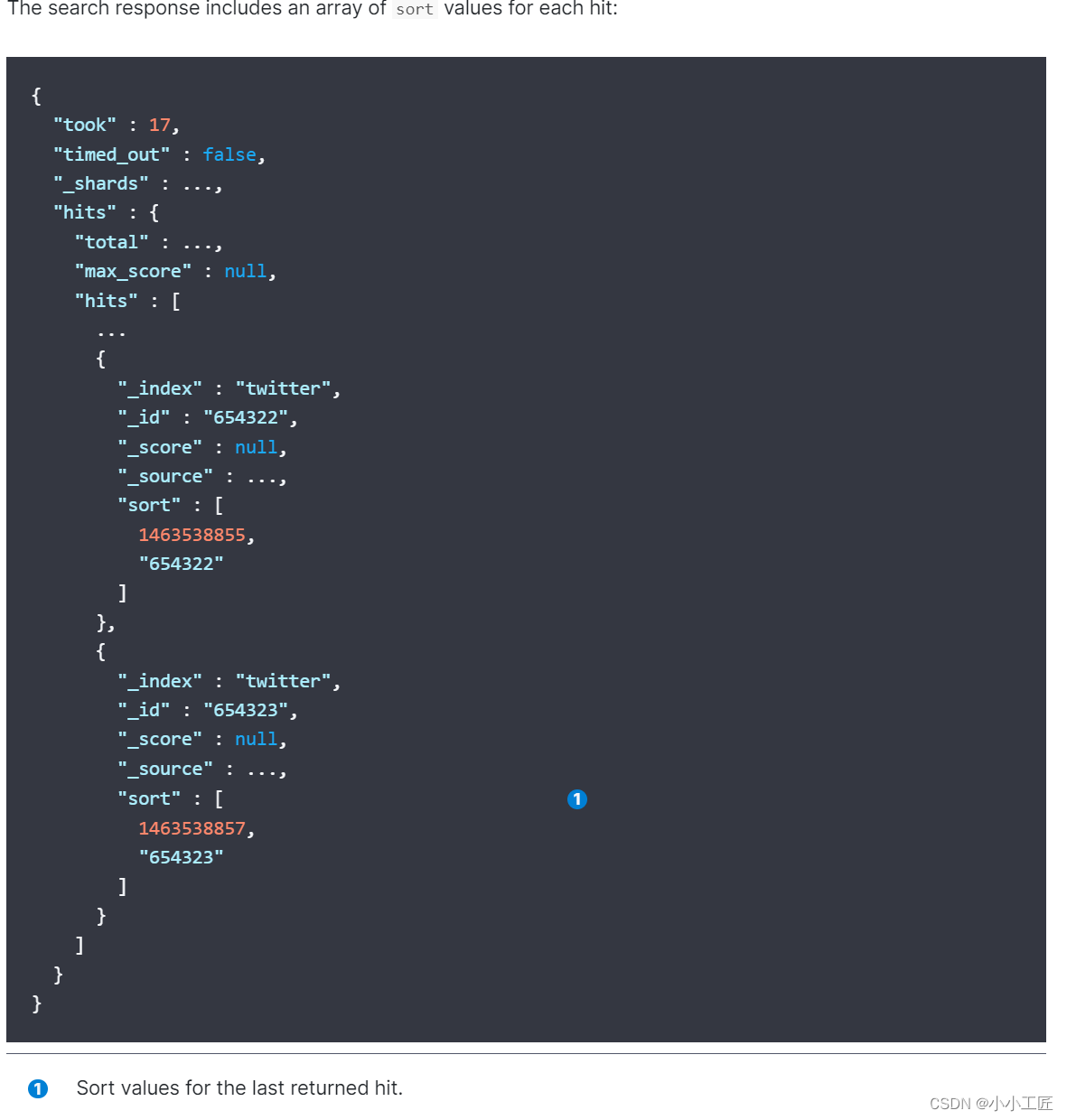
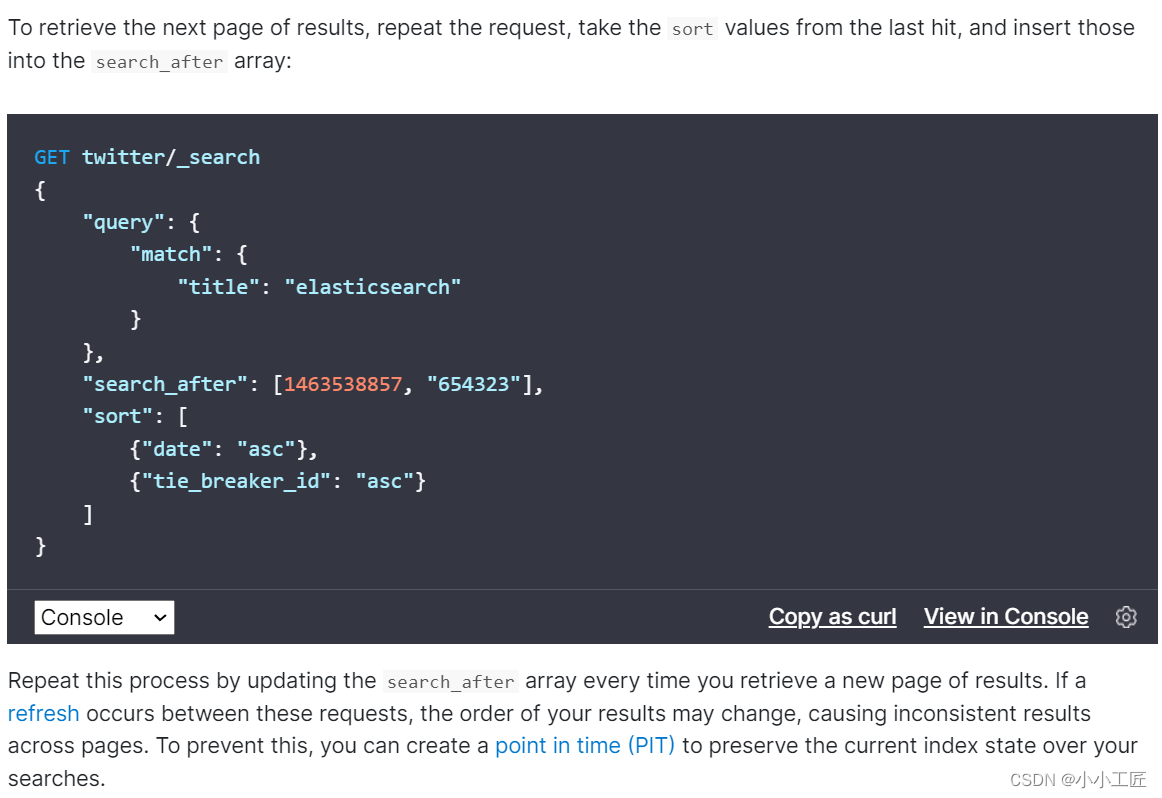
基于pit机制的search after
https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html#search-after
Elasticsearch官方search after dsl案例:
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos"}}
{"_shard_doc": "desc"}
],
"search_after": [
"2021-05-20T05:30:04.832Z",
4294967298
],
"track_total_hits": false
}
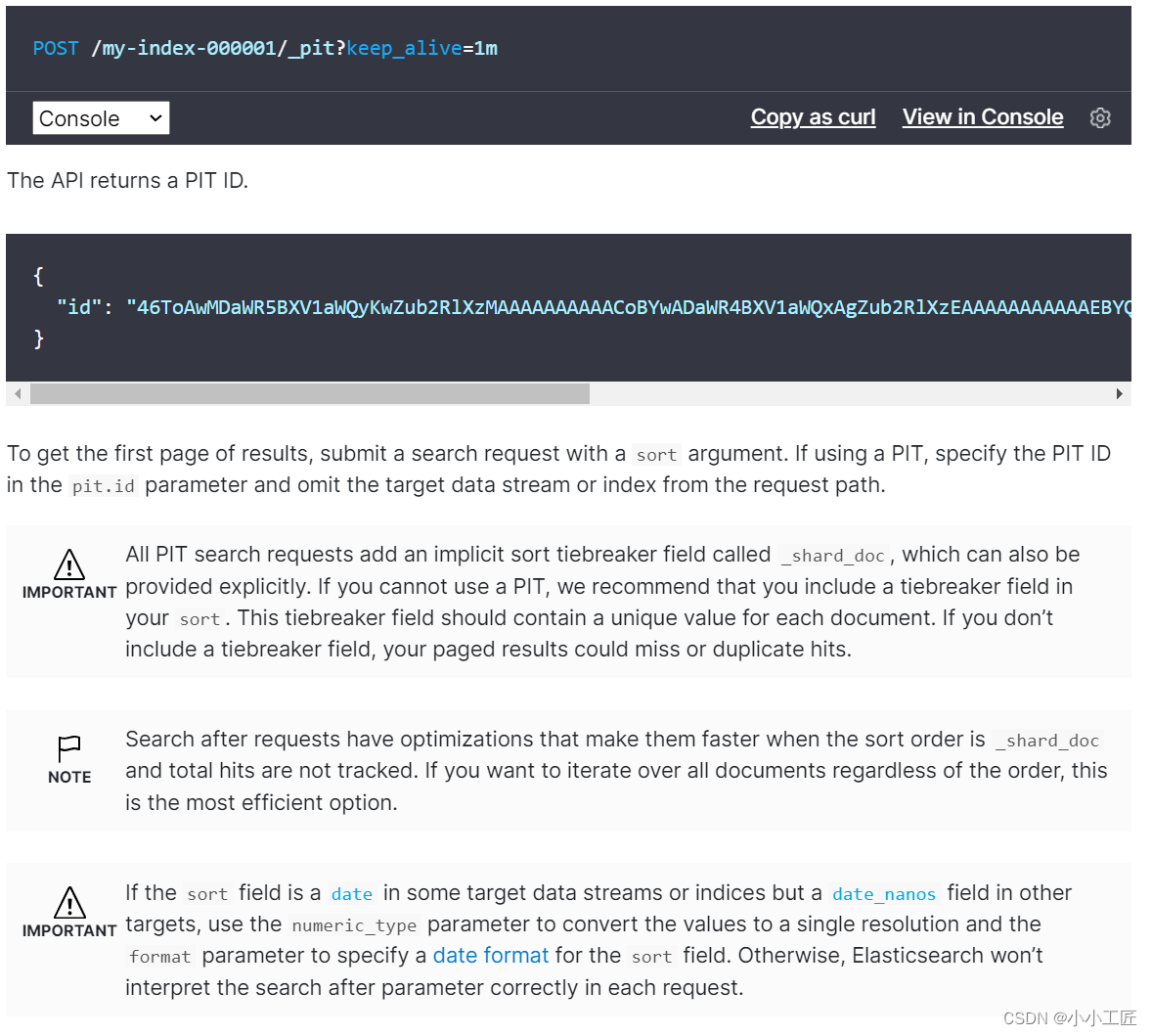
在搜索请求中指定PIT:
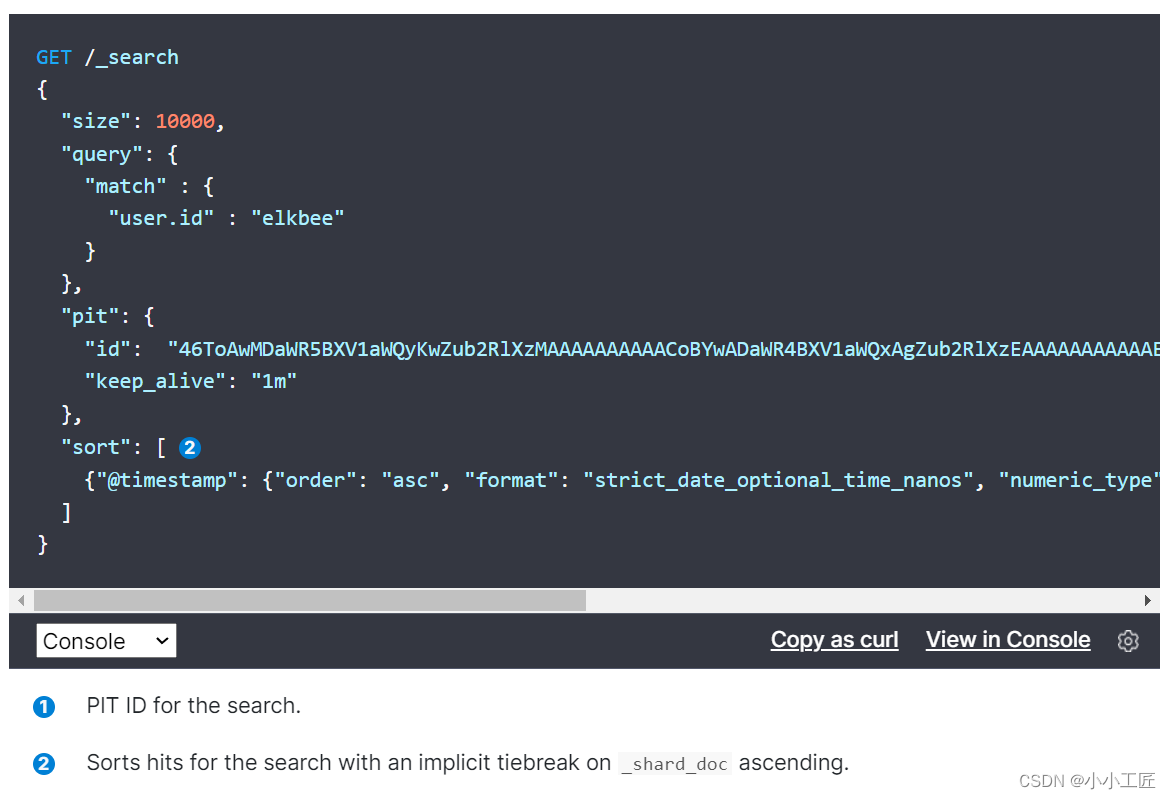
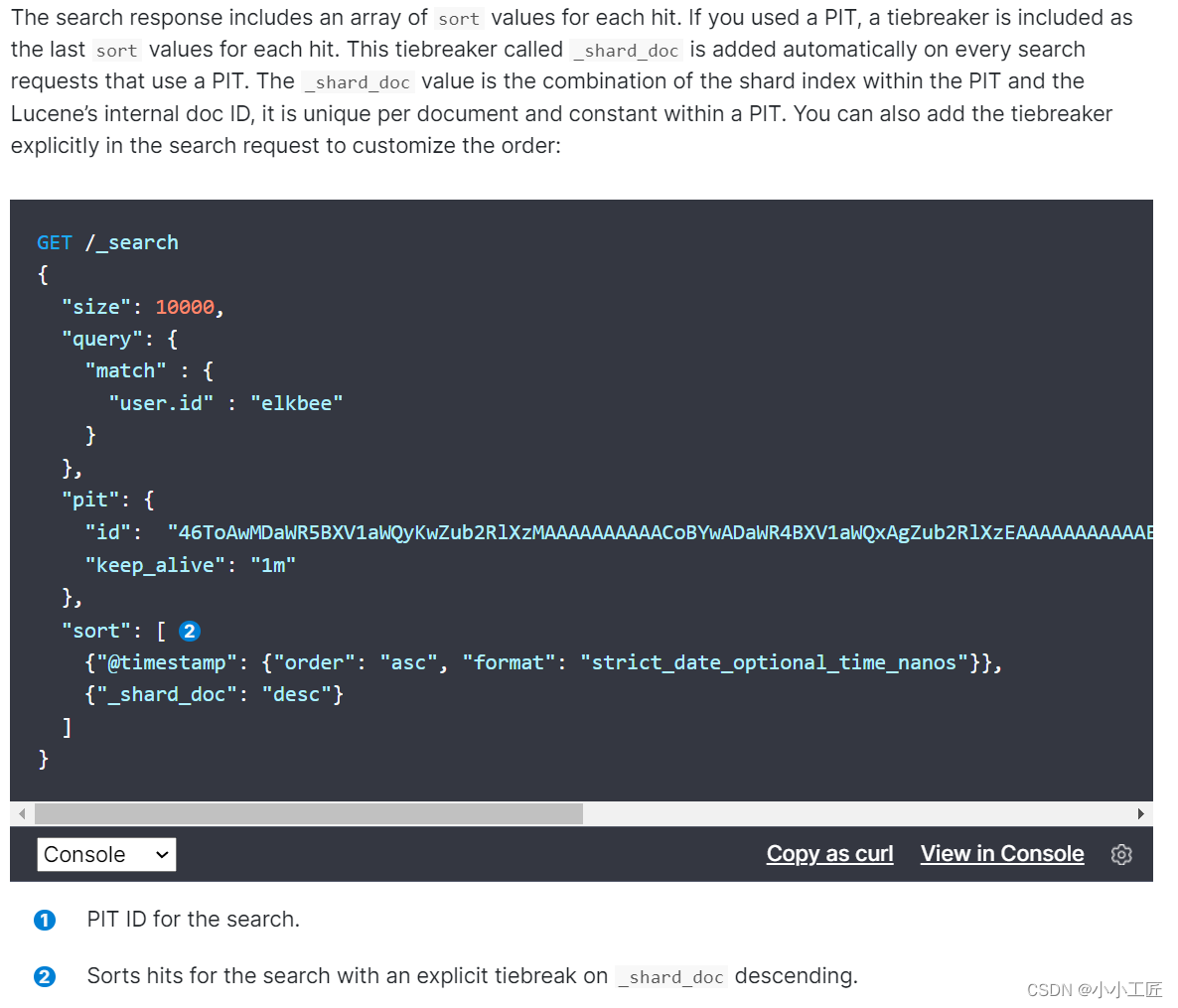
es维护一个实时游标,它以上一次查询的最后一条记录为游标,方便对下一页的查询,它是一个无状态的查询,因此每次查询的都是最新的数据。
由于它采用记录作为游标,因此SearchAfter要求doc中至少有一条全局唯一变量(每个文档具有一个唯一值的字段应该用作排序规范)
优缺点
- 无状态查询,可以防止在查询过程中,数据的变更无法及时反映到查询中。
- 不需要维护scroll_id,不需要维护快照,因此可以避免消耗大量的资源。
缺点:
- 由于无状态查询,因此在查询期间的变更可能会导致跨页面的不一值。
- 排序顺序可能会在执行期间发生变化,具体取决于索引的更新和删除。
- 至少需要制定一个唯一的不重复字段来排序。
- 它不适用于大幅度跳页查询,或者全量导出,对第N页的跳转查询相当于对es不断重复的执行N次search after,而全量导出则是在短时间内执行大量的重复查询。
- SEARCH_AFTER不是自由跳转到任意页面的解决方案,而是并行滚动多个查询的解决方案。
小结
| 分页方式 | 性能 | 推荐场景 | 优点 | 缺点 | 1-10 | 49000-490010 | 99000-99010 |
|---|---|---|---|---|---|---|---|
| from + size | 低 | 数据量比较小,能容忍深度分页问题 | 实现简单 | 深度分页问题 | 8ms | 30ms | 116ms |
| scroll | 中 | 非实时性的海量数据的查询 | 无深度分页问题 | 1。 越滚越慢,2。 无法反应数据的实时性(快照版本)维护成本高,需要维护一个 scroll_id | 7ms | 66ms | 36ms |
| search_after | 高 | 海量数据的分页 | 性能最好,PIT模式能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果,它不适用于大幅度跳页查询 | 5ms | 8ms | 7ms |
-
Scroll 和 Search_After 都是用于解决深分页问题的游标方式,但它们并不是深分页问题的终极解决方案,因为深分页问题必须避免。
-
Scroll 需要维护 scroll_id 和历史快照,并且必须保证 scroll_id 的存活时间,这对服务器是一个巨大的负荷。此外,Scroll 默认会拉取所有符合条件的数据,并保存在协调节点,每次 scroll 只返回 size 个文档和一个上下文状态,用于告知下一次读取的起点。因此,官方不推荐使用 Scroll 来进行实时的分页查询,而是适合于大批量的拉取数据。
-
Search_After 是一种业务折中方案,不允许指定跳转到页面,而只提供下一页的功能。如果允许用户大幅度跳转页面,会导致短时间内频繁的搜索动作,效率低下,增加服务器负荷。此外,在查询过程中,索引的增删改会导致查询数据不一致或者排序变化,造成结果不准确。
-
因此,深分页问题必须避免,如果需要进行分页查询,可以使用其他更为适合的查询方式,比如限制条件和排序等。