写在前面
本文是K8S系列第四篇,主要面向对k8s新手同学。阅读本文需要读者对k8s的基本概念,比如Pod、Deployment、Service、Namespace等基础概念有所了解,尚且不了解的同学推荐先阅读本系列的第一篇文章《K8S系列一:概念入门》[1];阅读本文还需要读者对k8s的服务部署有一定深入的了解,特别是怎么通过Pod部署自己的服务,尚且不熟悉的同学推荐阅读本系列前一篇文章《K8S系列三:单服务部署》[2]。
本文旨在讲述如何基于k8s集群管理一群服务,包括如何做高可用(Hight Available,HA)部署和管理、如何做服务平滑升级、如何隔离不同业务的服务等。因此,本文将重点介绍以下的k8s对象/资源(API Resource):
- Deployment:无状态、多服务管理
- StatefulSet:有状态、多服务管理
- Namespace:不同服务资源隔离
0. 为什么需要服务管理?
正文开始之前,我们需要统一一个观点:日常生产中所说的“服务”,或者说是传统的“服务”,对应的是k8s的Pod对象(因为k8s有一个Service对象,经常被翻译和理解为服务,其实也没啥毛病)。
在上一篇文章《K8S系列三:单服务部署》[2]中,详细介绍了如何在k8s集群中部署一个可用的服务,包括容器环境的使用、数据卷的挂载、配置文件的使用、服务网络的配置。k8s会根据提交的Pod的yaml文件自动拉取镜像、挂载数据和配置文件、流量负载均衡器等以确保镜像容器内的服务正常运行。
这个难道还不足够么?还需要做什么呢?
答案是不够,因为还需要把部署在k8s集群上的服务更有效地管理起来,即服务管理。于是问题又来了:什么是服务管理?或者说,为什么需要服务管理?
我们来考虑几个场景:
场景一
高可用(Hight Available,HA)。虽然在实际生产中,后台服务架构设计原则没有统一的标准,不过,大部分后台服务必须考虑“三高”的问题:高并发、高性能、高可用。前两天看到一个非常有趣的话题:
面试官问:“如果线上请求量大,服务扛不住了怎么办?
” 我毫不犹豫:“加机器!”
话糙理不糙啊,加机器扩充服务实例绝对是首选(正经来说,面试官实际想听到的是对“三高”的理解、具体解决措施等)!仔细分析“加机器”这个操作,其实就是高可用的一种很有效的解决手段,而且在实际生产中往往一个程序也会部署几个服务实例,并且为了做有效容灾,服务实例会分布在不同的机器、机房、区域。
那么,“部署多个服务实例”的事情,仅仅用Pod不能完成么?
显然是可以的,做法也挺简单的:准备好N份Pod的yaml文件,设置好正确的镜像地址、挂载的数据卷、配置,以及配置好网络,只需要确保这N份yaml文件除了名字之外其余内容完全相同,譬如pod_1,pod_2,…,pod_n;接着用kubectl工具提交给k8s集群,N个服务实例就部署好了。
完美!
但是,上述操作存在问题:不方便。
比如,部署后发现分配的CPU和内存资源太少了,需要修改Pod的yaml文件。这个时候就是灾难了,因为你得人为修改这N份yaml文件。且不说损耗人力,更重要的是极易出错!就算是用shell脚本,你也会发现用起来没那么顺畅。
场景二
其次,实际生产中,服务发布上线之后,总是免不了迭代(谁还不会写一两个Bug了;客户/产品经理的需求单岂是一两次就提完了的)。这就意味着必须升级线上服务。
还是一样的问题:替换升级线上的服务,仅仅用Pod不能完成么?
也是可以的。做法也不复杂:首先把k8s集群中已经部署的Pod服务删除,然后再把修改好的N份Pod的yaml文件提交给k8s完成部署;或者直接修改(kubectl edit pod xxx)线上服务的配置信息,k8s会先删除老Pod再创建新的Pod。
不过,这种操作会有个很大的问题:在删除Pod和新建Pod中间,会有一段时间无法正常服务,客户端请求全部失败。 这就需要衡量你的服务是否能够接受这样子的“缺陷”;当然,你可以通过选择请求流量最小(譬如晚上)操作,也可以提前告知用户接下来某个时间段要更新服务、这个时间内不要向我发送请求。
但是在更多的实际生产场景中,上面的“缺陷”是不会被允许的。
其实,你也可以选择这么部署:再准备N份Pod的yaml文件,名字换另一组,譬如pod_n+1,pod_n+2,…,pod_n+n,然后,先提交部署新的N份yaml,紧接着再删除老的N个Pod。
不过,我们可以看到上面的做法:更加不方便了!
场景三
实际生产中,往往会管理多条业务线的服务,于是一个非常合理的需求自然而然就提出了:能否把不同业务线的服务分开管理?,一方面防止不同服务互相干扰,另一方面方便做资源隔离和管理。
一个很自然的想法是:对于每一条业务线部署一套k8s集群。
但是,这种做法太重了,首先是部署k8s是一件相对耗时耗力的事情;其次,实际生产环境也不一定有这么多的机器。最佳的方案是能够在一套k8s集群中完成(当然不排除在一些项目中,会要求部署多套k8s集群)。
综上,我们可以发现,仅仅使用Pod(Volume,ConfigMap,Secret和Service包括其中)一种对象无法满足更多的常见的、可能更复杂的实际生产场景。 但是,我们不应该责怪Pod,因为Pod的设计是合理的:
Pod是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
但是,上述几个场景中怎么解决呢?
k8s自然有解决办法和机制,这也是本文讨论的服务管理,这也是本文要重点讨论的几个API对象,概括来说:
- 管理无状态的服务,用Deployment;
- 管理有状态服务,用StatefulSet;
- 隔离服务资源,用Namespace;
接下来,我们来看Deployment、StatefulSet和Namespace分别是怎么使用的吧!
I. Deployment:无状态、多服务管理
Deployment是管理无状态服务的利器,官网[3]描述:
一个 Deployment 为 Pods 和 ReplicaSets 提供声明式的更新能力。
官方文档总是说些听不懂的话,而且这里又引入了新的名词:ReplicaSet。这个是什么?
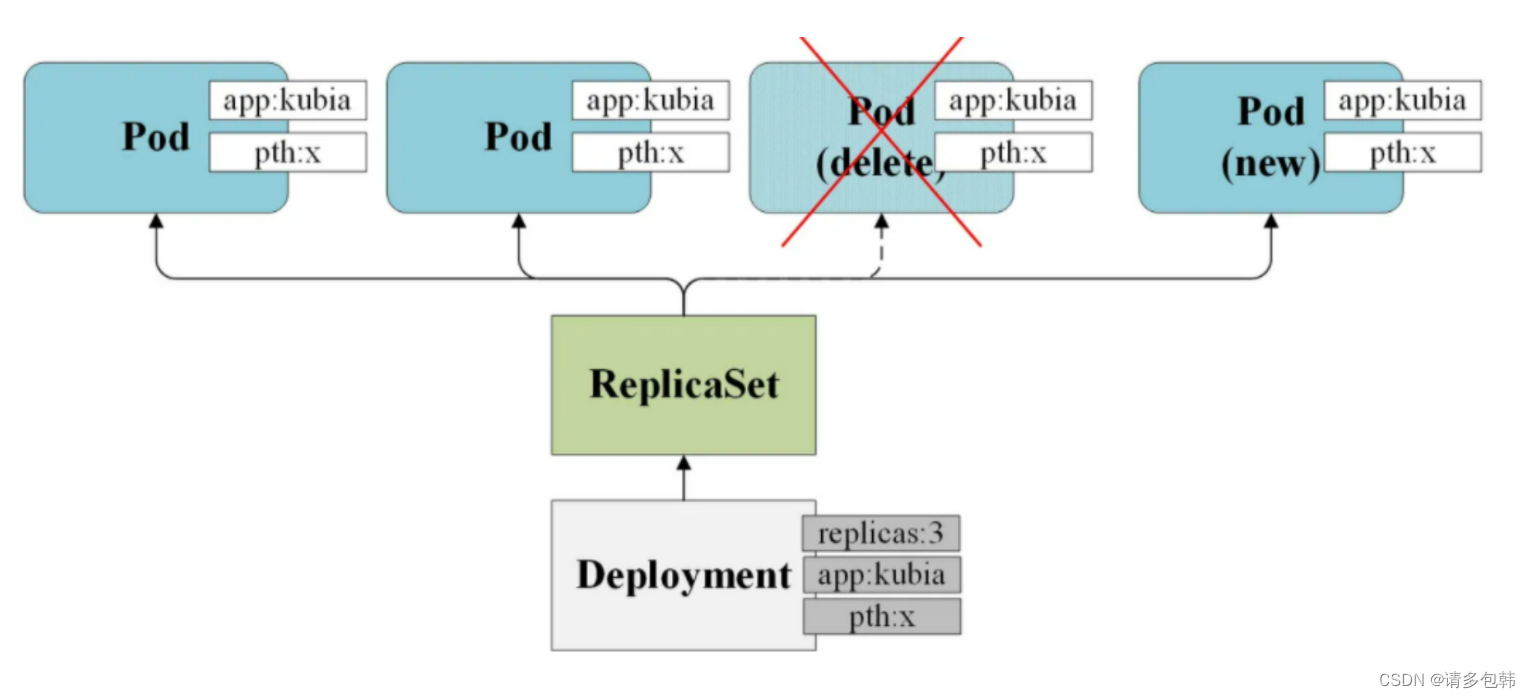
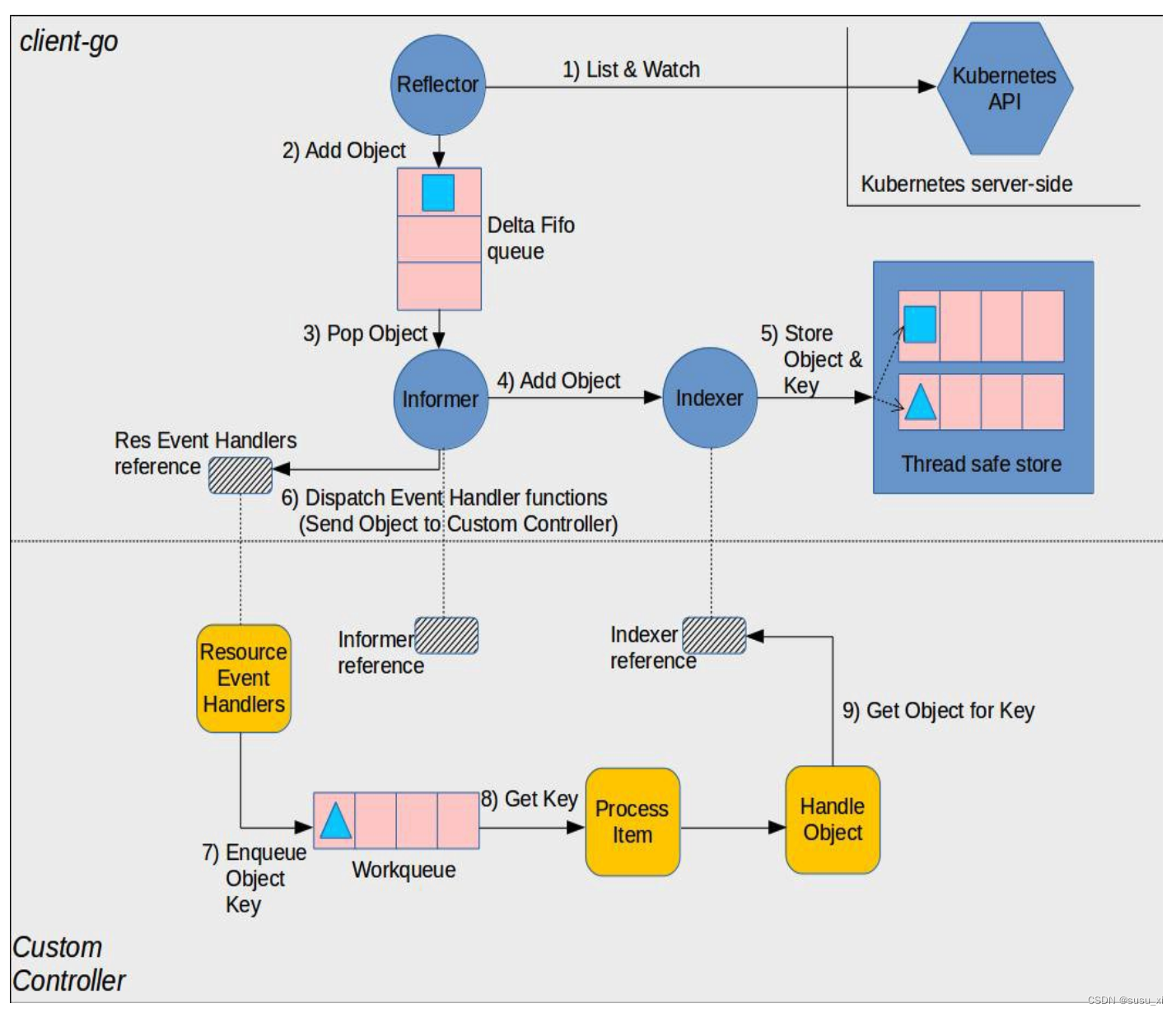
首先,Deployment、ReplicaSet和Pod之间的关系如下(图片引自书籍《k8s-in-action》[4]):
其次,在《K8S系列一:概念入门》[1]文中对Deployment、ReplicaSet和Pod三者之间的关系有过介绍:
ReplicaSet的作用就是管理和控制Pod,管控他们好好干活。但是,ReplicaSet受控于Deployment。形象来说,ReplicaSet就是总包工头Deployment手下的小包工头。
但是,上面的描述会有点小问题。严格来说,ReplicaSet是一个独立的API对象,所谓的“ReplicaSet受控于Deployment”是:当创建了Deployment对象后,它会自动创建ReplicaSet来管理Pod。
这就好像你准备装修你的房子,Deployment就是一个非常棒的装修公司,而ReplicaSet则是实际干活的包工头,而Pod则是每个干活的工人。装修公司只需要告诉包工头这个工程需要多少个工人干活,之后包工头就会实时监控每个工人,如果有M个工人请假,包工头会马上再雇佣M个工人参与进来。如果你觉得说:这批工人做工质量不行啊,我需要升级更好的。那么装修公司会马上撤走这个工程队,包括包工头和他手下所有工人,再雇佣新的工程队,包括新的包工头和新的工人。
可以看到,**Deployment的高可用实际上是ReplicaSet的特性,Deployment实际特性则是做服务的平滑升级,**也就对应了上面例子提到的“更换工程队”。
好的,那就让我们一起来看看Deployment的yaml文件(来自官网[3]):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
对比Pod的yaml文件,我们会发现:Deployment比Pod多了几个字段:
- ‘replicas’:控制实际在运行的Pod数量;
- ‘selector’:通过该label管理对应的Pod(请留意’template.metadata.labels’);
由此也可以窥探到Deployment通过ReplicaSet管理Pod的内在机制:创建’replicas’个Pod,并且赋予Pod用户指定的label和一个名为’pod-template-hash’的label,内容为一个随机生成9位数的hash值;通过’selector’实时匹配在运行的Pod数量,不足则创建、非Running状态的杀死后重建、超过则杀死多余的。管理过程如下图:
接下来,让我们分别来看Deployment的两个特性:高可用和平滑升级。
特性一:高可用
在维基百科[5]上对高可用的定义是:
高可用性(英语:high availability,缩写为
HA),IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统与构成该系统的各个组件相比可以更长时间运行。
高可用性通常通过提高系统的容错能力来实现。
高可用的核心是:无中断提供服务。因此,提升高可用可以从几个方面入手:
- 提升程序的鲁棒性(减少crash);
- 增加服务实例,如采取主从(冷热)和双主(双热),甚至是多主的集群工作方式;
实际生产中,最佳手段还是增加服务实例,毕竟,谁也不能保证自己写的程序没有Bug。而Deployment的就可以做到确保k8s集群中实时存在用户需要的N个服务在正常工作。
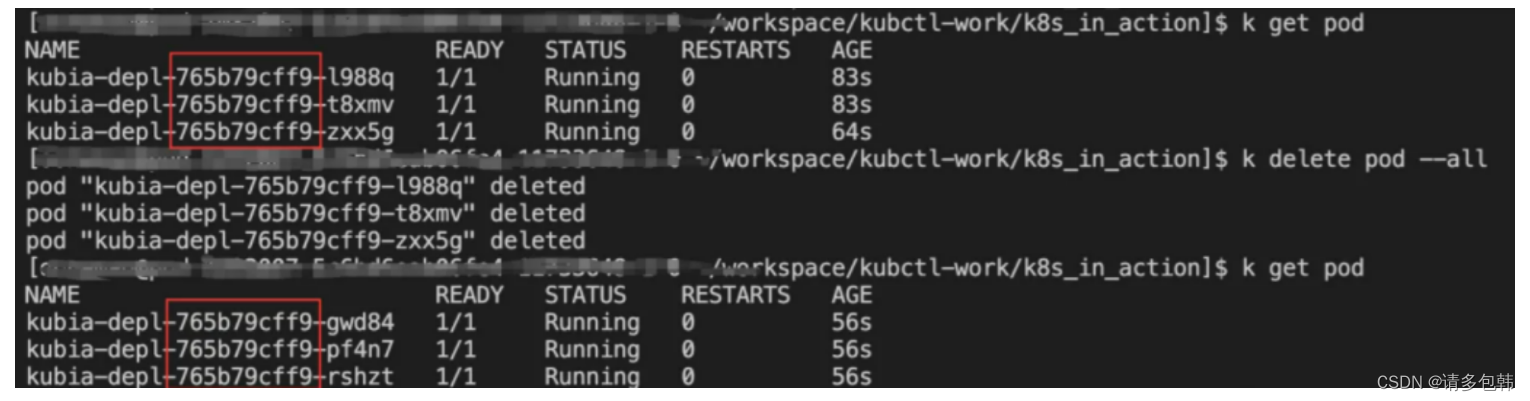
笔者做了一个实验,假设我需要的是3个服务实例,那么只需要设置Deployment的yaml文件的’replicas: 3’即可,提交后发现集群上确实启动了三个Pod。紧接着,模拟线上服务挂了的状态,手动删除了其中一个Pod,再来看k8s中Pod的情况,发现马上有新的Pod被拉起。下图展示了整个过程,删除的Pod名字为’kubia-depl-765b79cff9-grzbm’,而被Deployment新拉起来的Pod名字为’‘kubia-depl-765b79cff9-zxx5g’:

前文已经说过:Deployment的高可用实际上是ReplicaSet的特性。这个怎么理解呢?
我们在通过Deployment部署Pod服务之后,到k8s分别查看Deployment、ReplicaSet和Pod,会发现一个有趣的现象:ReplicaSet的名字是则Deployment名字基础上加了一个’-9位hash值’生成的,并且其’selector’的label=用户自定义的label+‘pod-template-hash:9位hash值’;而Pod的名字则是ReplicaSet名字基础上再增加一个’-5位hash值’生成的,并且其label严格等于ReplicaSet的’selector’的label。如下图所示:

因此,确保’replicas’数量的Pod运行的特性的提供者,就是ReplicaSet!不信?你可以尝试一口气把所有的Pod都删除了,最后发现还是会被ReplicaSet拉起来。该过程如下图:
实践出真知啊。
特性二:平滑升级
上面我们已经看到,其实用ReplicaSet也能够管理多个服务,并且k8s最早开源的时候,也没有Deployment对象。但是之后发现,在实际生产中,程序版本迭代是一件常见且相对高频的操作。于是就推出了Deployment(早前有ReplicationController,自动Deployment推出之后就不被推荐使用了)。
我们现在来看看Deployment是怎么做服务的平滑升级。
在《k8s-in-action》[4]中第九章专门介绍了Deployment的升级,书中有一幅描述Deployment升级的示意图:
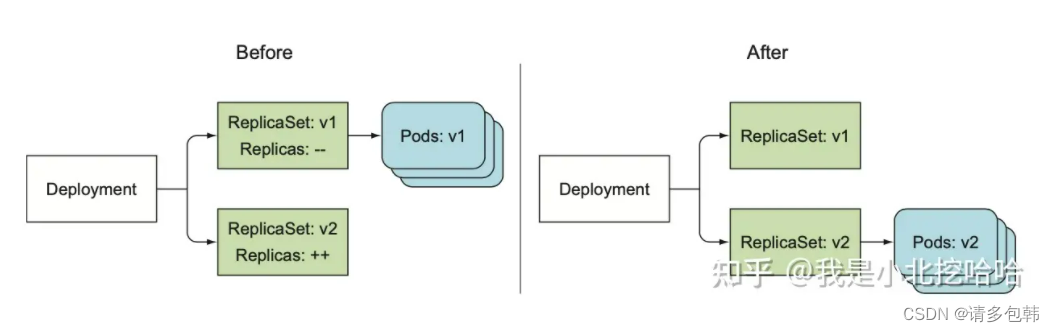
更具体的升级过程应该如下图:

可以看到,升级过程和上一节高可用提到的实时确保’replicas’个Pod在运行是不一样的:后者是依靠ReplicaSet完成的;而前者则是Deployment的功能特性。
怎么才能触发Deployment的升级呢?
但凡修改Deployment中非’replicas’的其他有效字段(镜像地址’image’、资源’resources’),都会触发Deployment的升级。笔者做了一个实验,修改了’resources’,可以看到:

然而,实际生产中仅仅知道Deployment会做平滑升级还不足够,还需要掌握选择升级策略和控制升级频率。关于这块,希望做更详细了解的同学建议阅读《Deployment Strategies》[6]和《Kubernetes部署策略详解》[7]。
- Deployment升级策略
Deployment有两种升级策略:Recreate和RollingUpdate。前者是先把所有旧的/已有的Pod全部销毁,然后再拉起新的;后者则是一个一个销毁旧的/已有的Pod,同时再一个一个拉起新的。RollingUpdate是默认的。 - Deployment升级频率
这里重点介绍RollingUpdate策略的参数,主要原因它是大部分实际生产中最佳的选择。
首先来看yaml文件中与之相关的部分:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
敲重点:maxSurge和maxUnavailable是相对比较重要,且理解不直观的两个参数!网上关于这俩参数的解读有很多,大部分的解释仍旧不直观。笔者结合实验,在这里尝试解释:
核心理解点在于:maxSurge关系到启动新的Pod的速度;而maxUnavailable则关联到杀死旧的Pod的速度。RollingUpdate的任务就是一个一个销毁旧的/已有的Pod,同时再一个一个拉起新的。
我们假设’replica’为rp,maxSurge为ms(绝对值),而maxUnavailable为mu(绝对值)。实际上,RollingUpdate是先拉起mu个新的Pod,同时销毁min{ms+mu,剩余的}个旧的/已有的;(确保旧的/已有的被销毁了,而新的被拉起了)之后再拉起mu个新的Pod,同时销毁min{ms+mu,剩余的}个旧的/已有的。借用《k8s-in-action》[4]的过程图来说明:
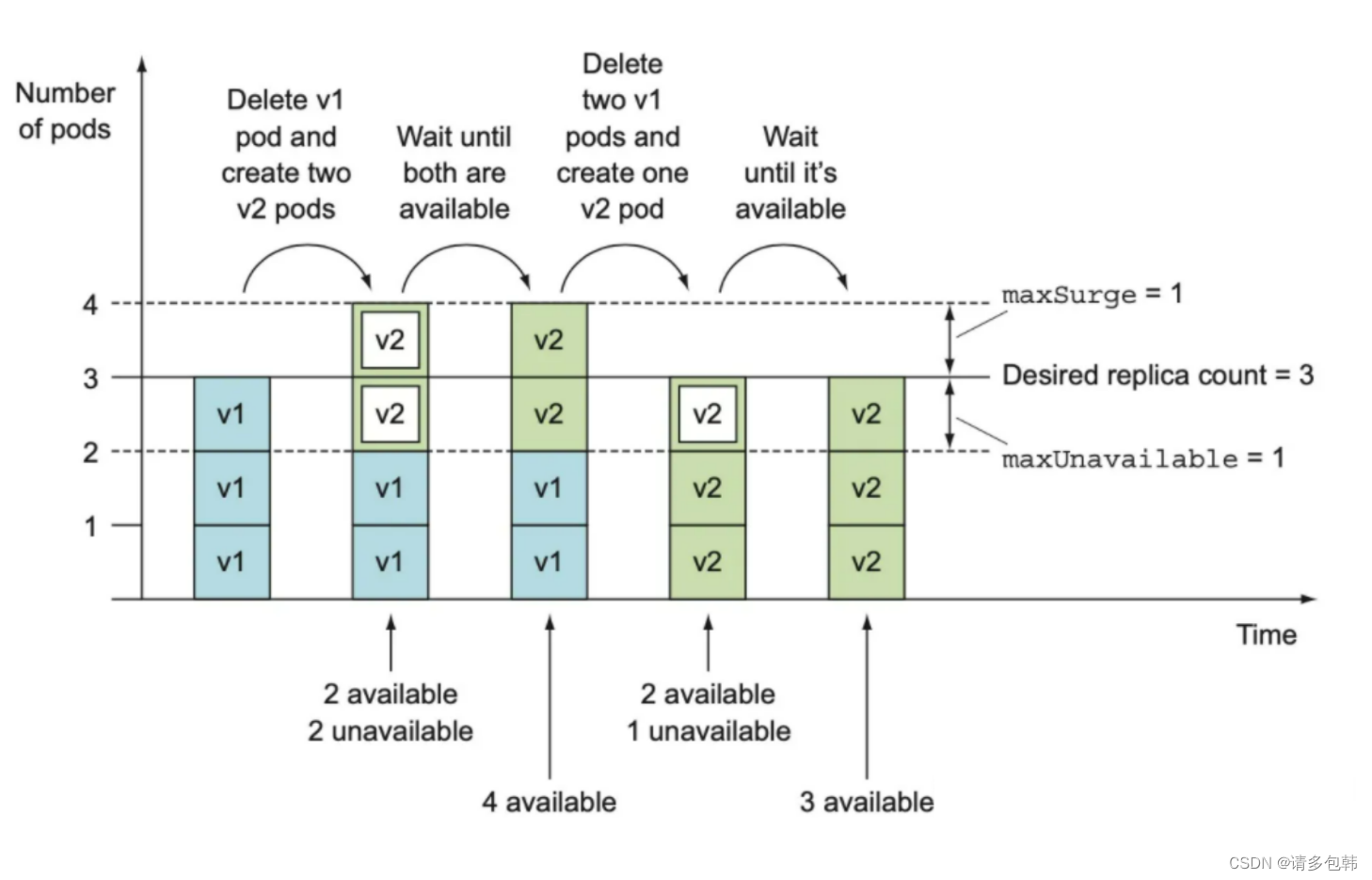
由此可见,maxSurge和maxUnavailable越大,更新越快;反之,更新会越慢。并且,k8s要求maxSurge和maxUnavailable不能同时为0,为什么? 因为都为0的话,根本没办法更新了!那么,到底要怎么设置这两个值,这就要视实际生产要求而定。
笔者也做了下实验,和大家分享:
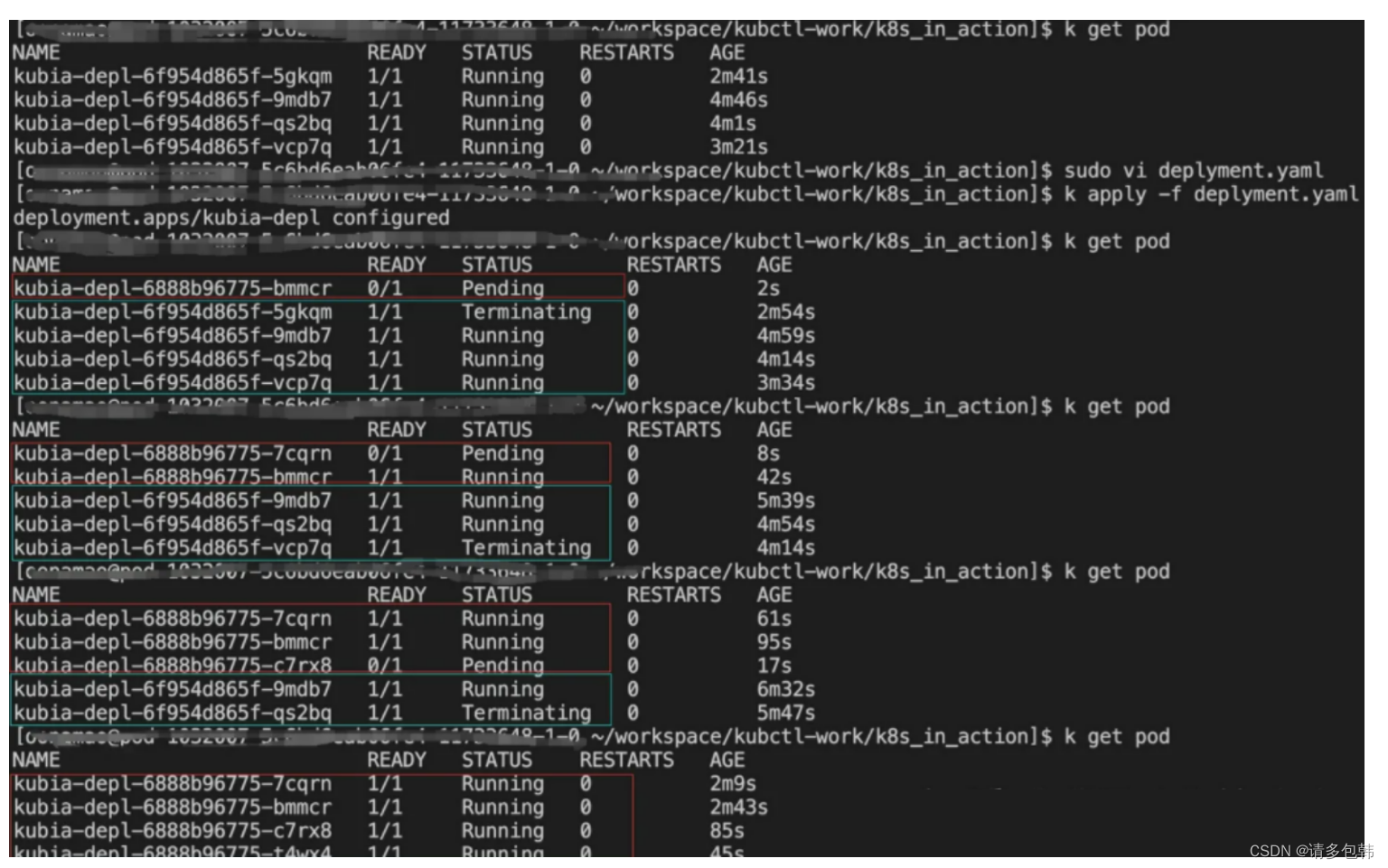
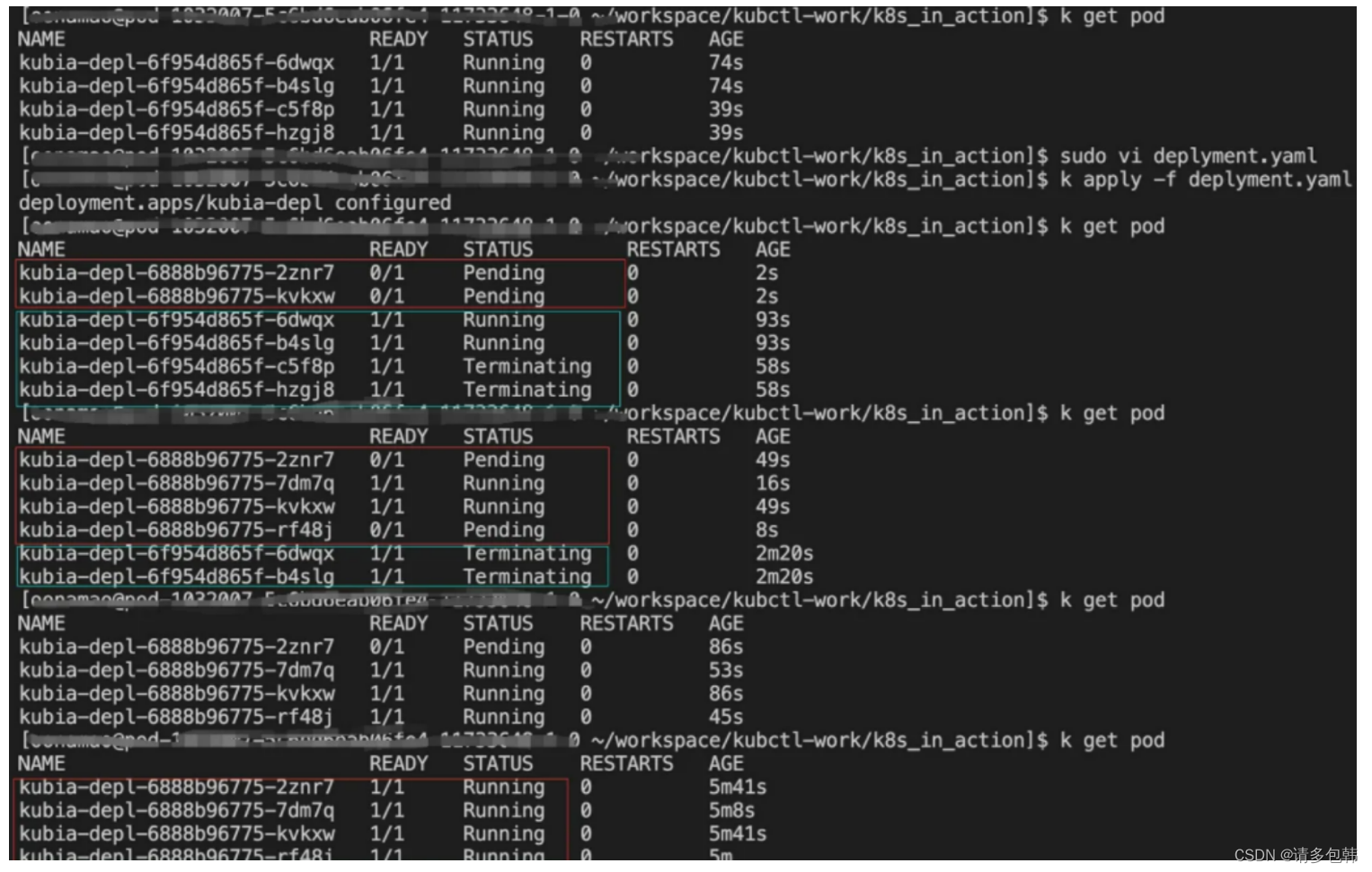
- 实验一:replicas=4,maxSurge=0,maxUnavailable=1,2,4。
结论:升级速度越来越快。

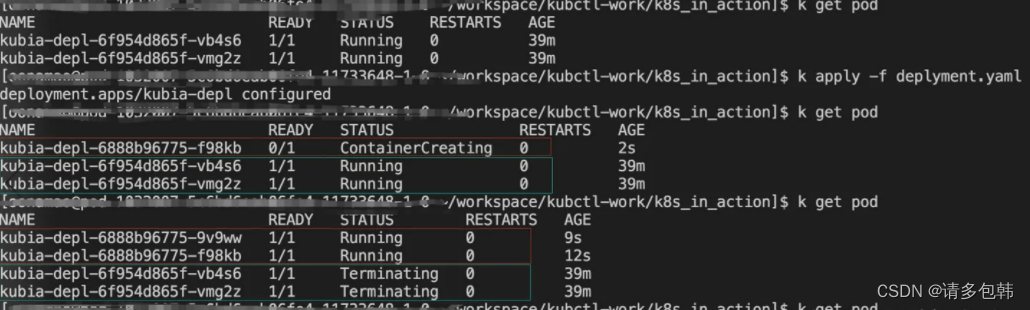
- 实验二:replicas=2,maxUnavailable=0,maxSurge=1,2
但是由于笔者试用的k8s集群资源有限(一次至多4个Pod在跑,而且时不时会被抢占资源),因此只能做replicas=2的实验,再大一点就会跑不起来。大家可以自行实验。
结论:升级速度越来越快。

不知道会不会有同学在想:如果我追求快速升级迭代,那是不是把maxSurge设置跟’replicas’一样最好?一次性就升级好了!
但是请注意,笔者分享自己实际遇到的坑:k8s集群总归会有资源不足的情况(比如cpu、gpu甚至是ip资源),因此在资源非常紧张的时候,如果maxSurge越大,升级反而不见得越快;并且在资源恰好足够的时候,maxSurge大于零,就会造成升级卡主!!!因为,RollingUpdate实际升级过程是先拉起maxSurge新实例,紧接着销毁maxUnavailable个旧的/已有的实例。切忌小心升级,别以为用了k8s就万事大吉!
II. StatefulSet:有状态、多服务管理
在讨论StatefulSet之前,笔者先说明:实际生产中笔者所用业务并没有使用到该类管理器API对象,所有的知识都是从《k8s-in-action》[4]学习的。
首先,我们要知道:为什么需要StatefulSet?或者说,它和Deployment不同点在哪?
《k8s-in-action》[4]在第十章一开头,花了很大的篇幅在描述这个问题,笔者通过书籍、网上博客和实验,感觉文章《StatefulSet和Deployment的区别 》[8]总结得很好:
- 稳定的、唯一的网络标识。
- 稳定的、持久的存储。
- 有序的、优雅的部署和伸缩。
- 有序的、优雅的删除和停止。
- 有序的、自动的滚动更新。
而在文章《Kubernetes服务之StatefulSets简介》[9]则对于StatefulSet的用法细节总结得很好:
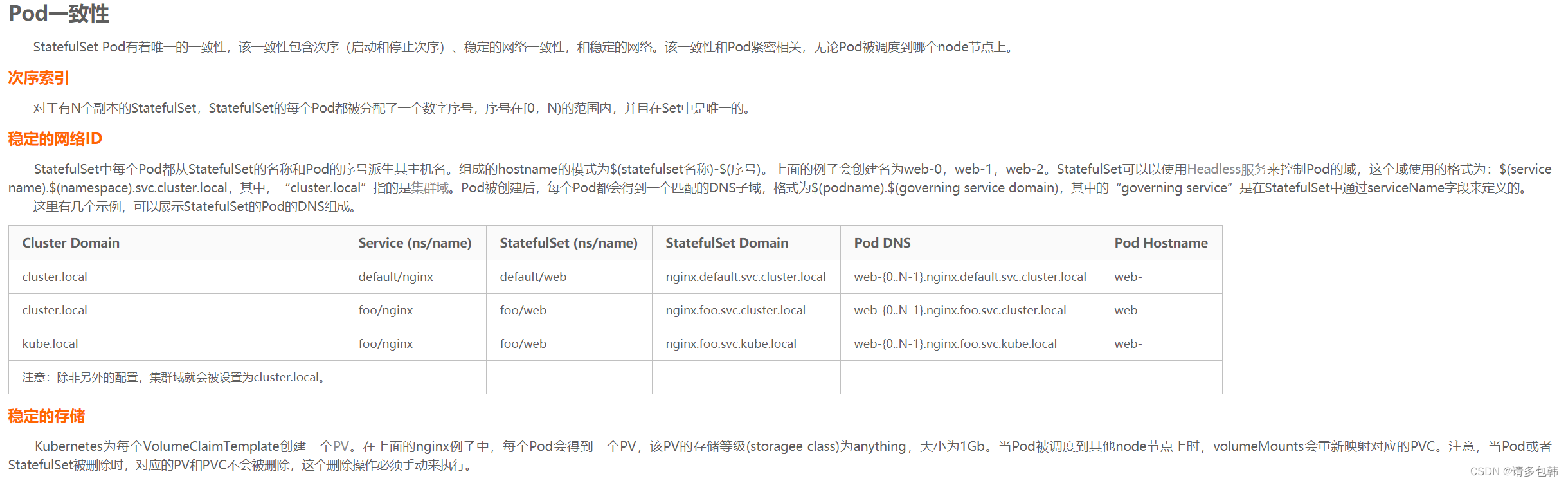

笔者试验了StatefulSet的CURD,发现其创建和扩缩容确实都是按顺序扩增、缩小;但是如果直接把StatefulSet删除的话,那么所有的Pod也就被删除了:
-
创建:可以看到Pod是逐个被创建,并且以StatefulSet的名字+id(从0开始递增)的形式为其名字。
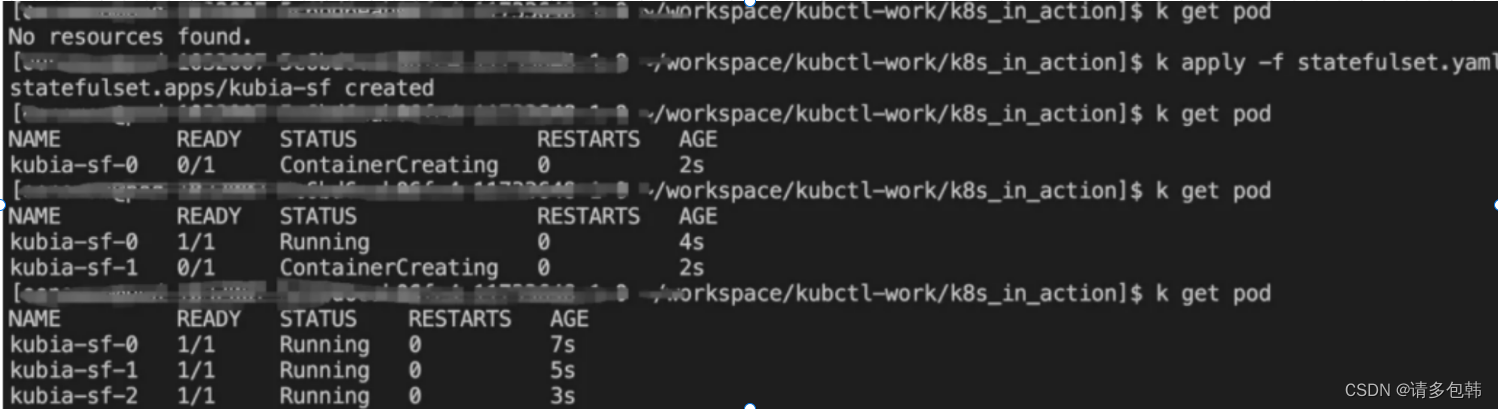
-
扩容:可以看到,扩增的Pod是在已有的id基础上继续递增,并且也是逐个创建。
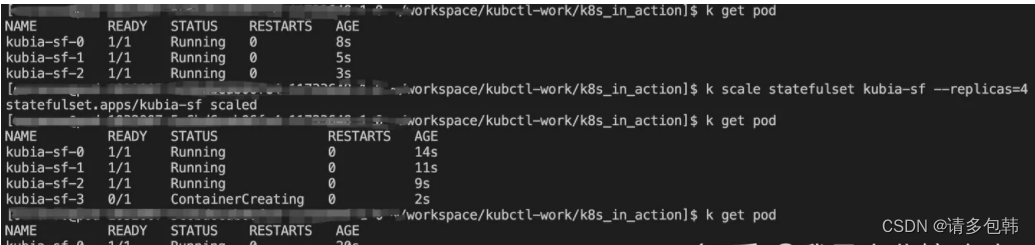
-
缩容:是从当前最大id逐个销毁。

-
删除:直接全部删除了。

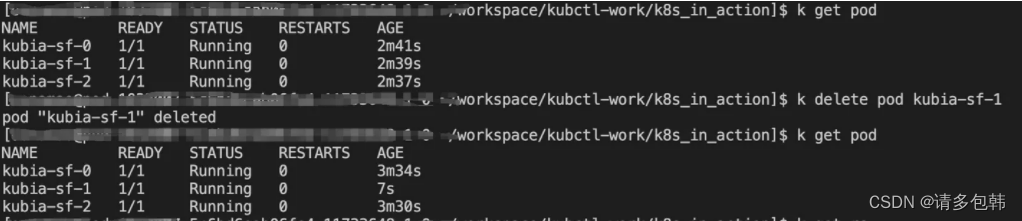
笔者这个时候在思考,如果仅仅是其中一个Pod挂了会怎么样?实验后发现:StatefulSet会拉起!并且,StatefulSet并没有中间创建ReplicaSet或者ReplicationController,因此有理由相信StatefulSet自己实现了实时监督Pod和拉起失败Pod的能力(可能复用了StatefulSet的代码)。
仅仅从CURD层面看,StatefulSet和Deployment是完全不一样的。至于其他方面的特性,笔者还没来得及深入了解,挖个坑吧!
III. Namespace:不同服务资源隔离
Namespace可就太基本,而且使用起来也非常简单:
# 创建
$ kubectl create namespace ${name}
# 删除
$ kubectl delete namespace ${name}
# 查看
$ kubectl get namespace
那么为什么要特别为它设立一个章节呢?因为越是基础,越是重要,也越是容易被忽略!请一定合理为不同的项目创建Namespace!
写在后面
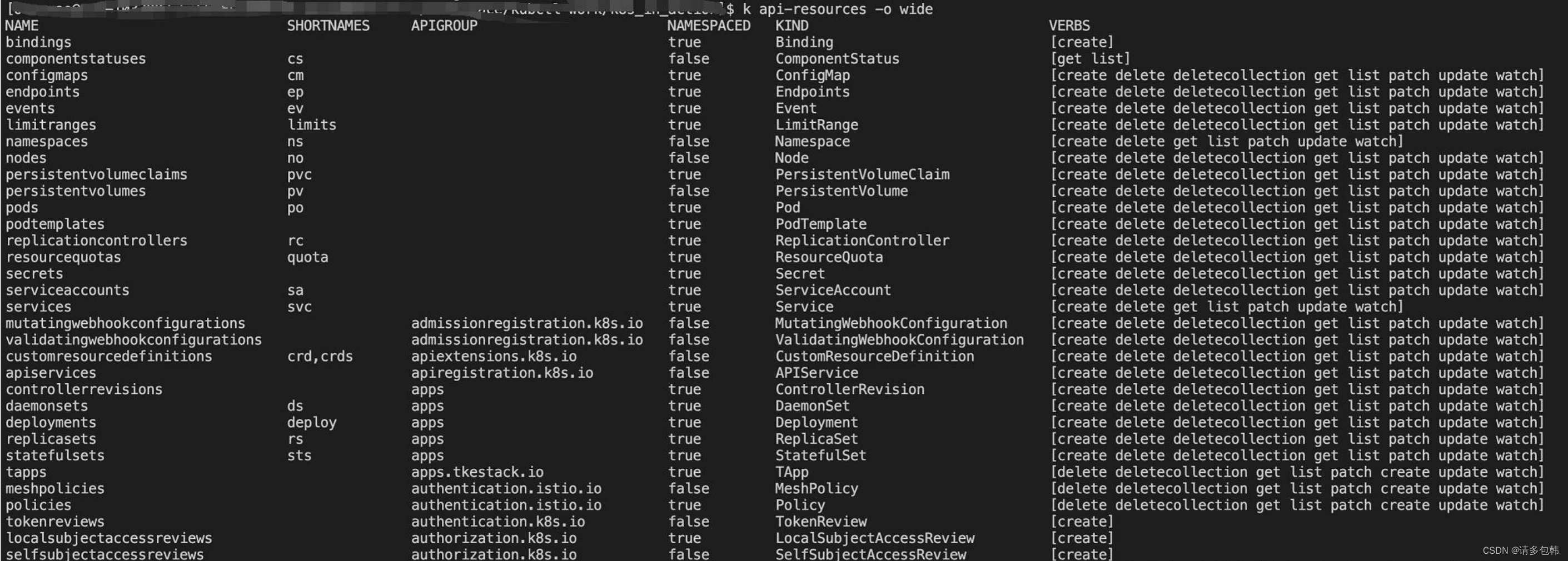
k8s实践tip1: 实际生产中使用kubectl工具时,会发现有些API对象有缩写,比如pod是po,replicaset就写rs。怎么查看呢?
kubectl api-resources非常重要!可以看到当前k8s的所有API对象、其缩写、它是否可以被Namespace隔离等:
最后,如果文章中有纰漏,非常欢迎留言或者私信指出;有理解错误的地方,更是欢迎留言或者私信告知。总之,非常欢迎大家留言或者私信交流更多k8s的问题。






![C语言——自定义类型详解[结构体][枚举][联合体]](https://img-blog.csdnimg.cn/93dfbb0570224aa9a33ef33edc02b948.png)