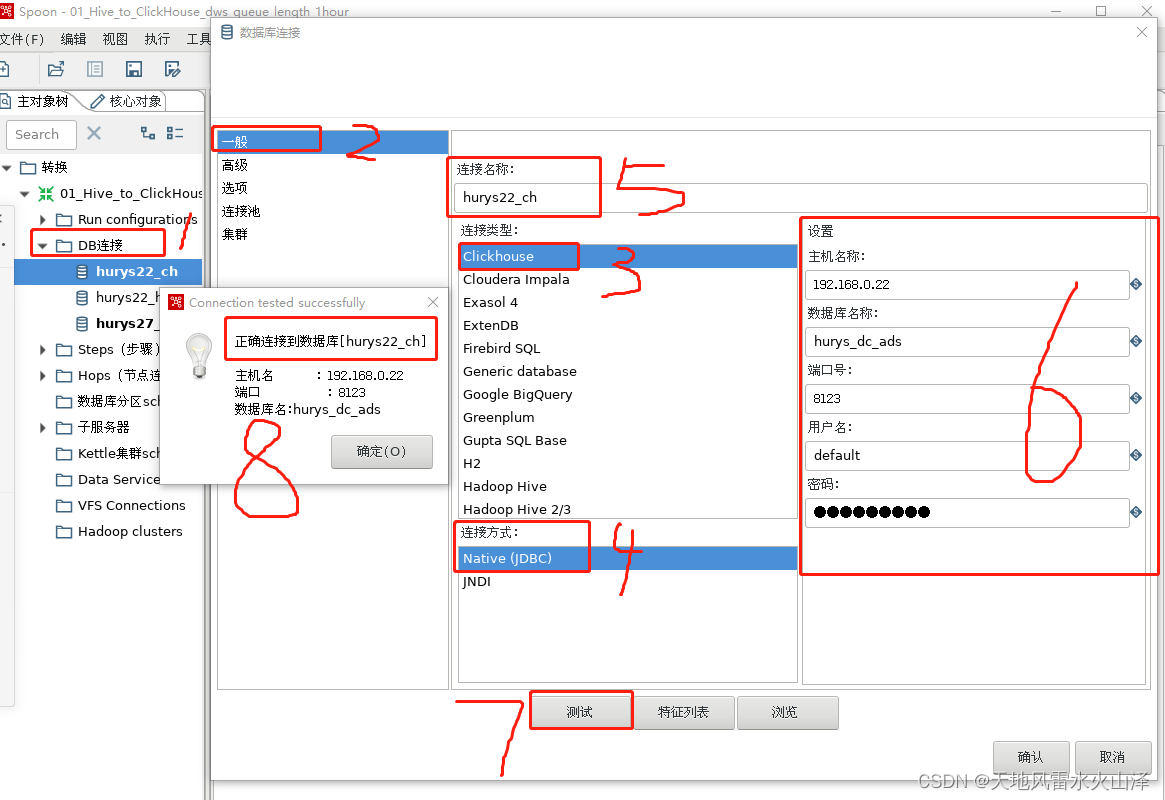
本文参考 ChatGLM2-6B 官方文档,在矩池云复现了对于 ChatGLM2-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
官方文档地址:https://github.com/THUDM/ChatGLM2-6B/tree/main/ptuning
下面以 ADGEN (广告生成) 数据集为例介绍代码的使用方法。
租用机器
我们所使用的环境是矩池云 ChatGLM2-6B 环境,该环境预装好了运行 ChatGLM2-6B 需要的 Python 依赖,并包含了 ChatGLM2-6B 文件。
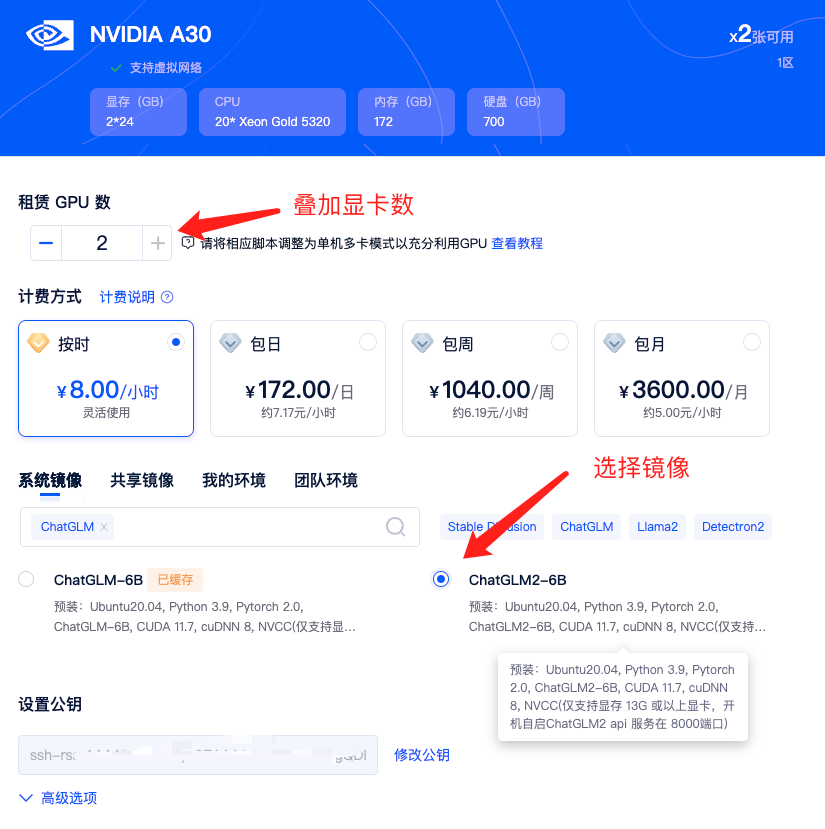
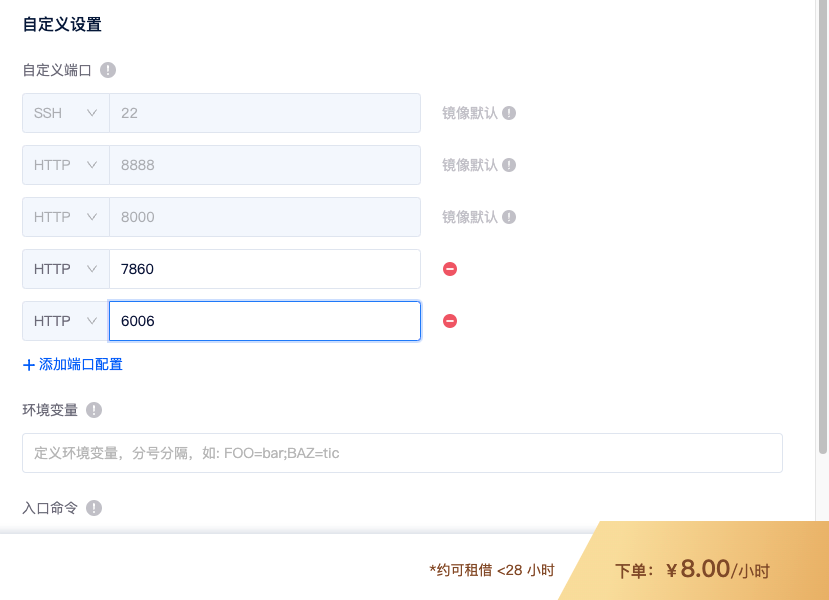
租用机器的时候还可以在高级选项-自定义端口里添加2个自定义端口:
- 7860 用于部署 web 服务,测试训练模型效果
- 6006 用于部署 tensorboard 服务,查看训练可视化日志
配置依赖和数据集
机器启动成功后,我们点击租用页面 Jupyterlab 点击打开。
在 Jupyterlab 新建一个 Terminal,然后执行下面指令安装训练需要的依赖。
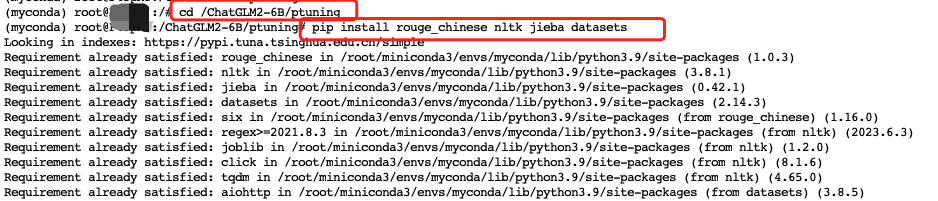
cd /ChatGLM2-6B/ptuning
pip install rouge_chinese nltk jieba datasets
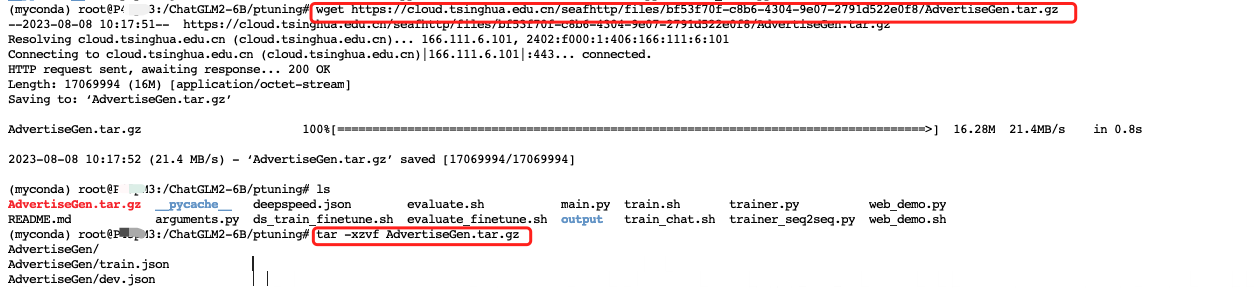
然后输入下面指令下载并解压测试数据 AdvertiseGen 。
wget https://cloud.tsinghua.edu.cn/seafhttp/files/bf53f70f-c8b6-4304-9e07-2791d522e0f8/AdvertiseGen.tar.gz
tar -xzvf AdvertiseGen.tar.gz
开始训练
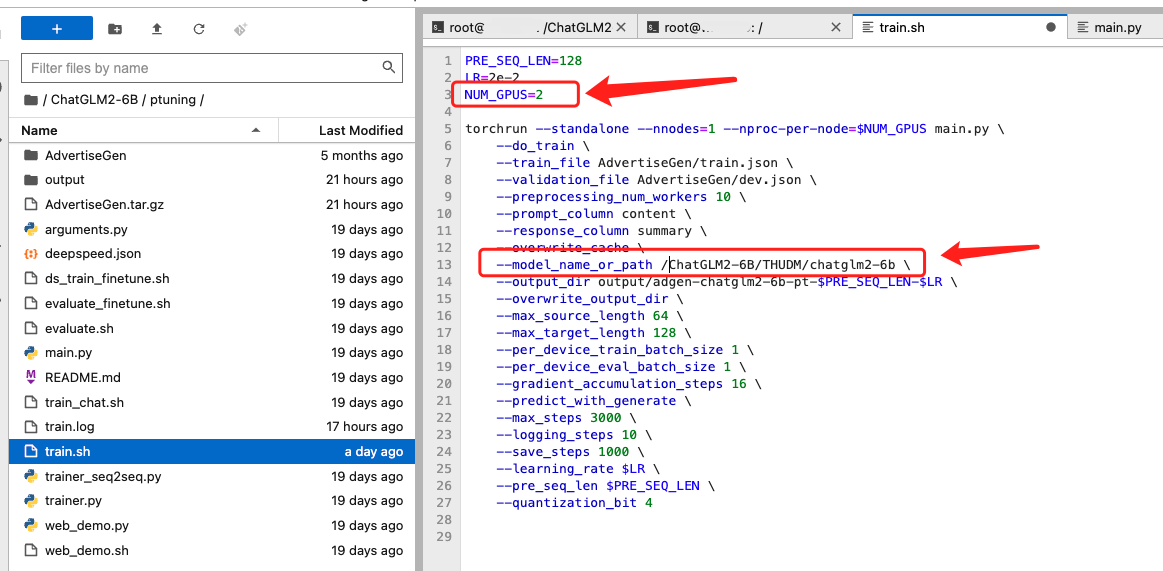
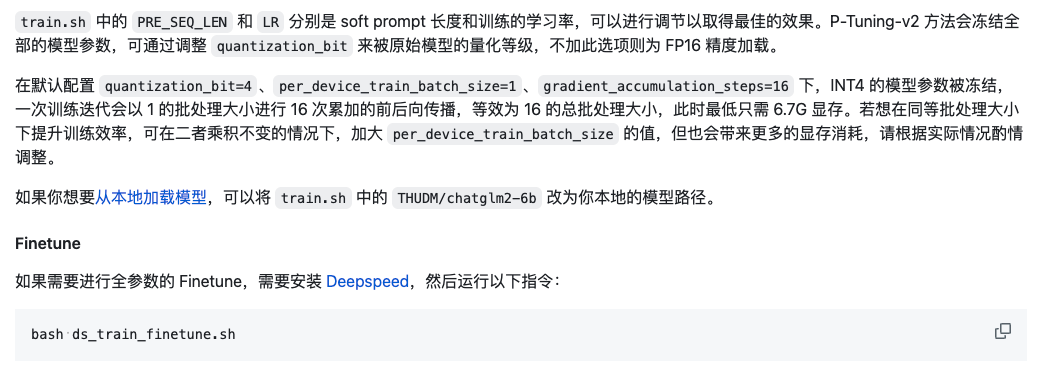
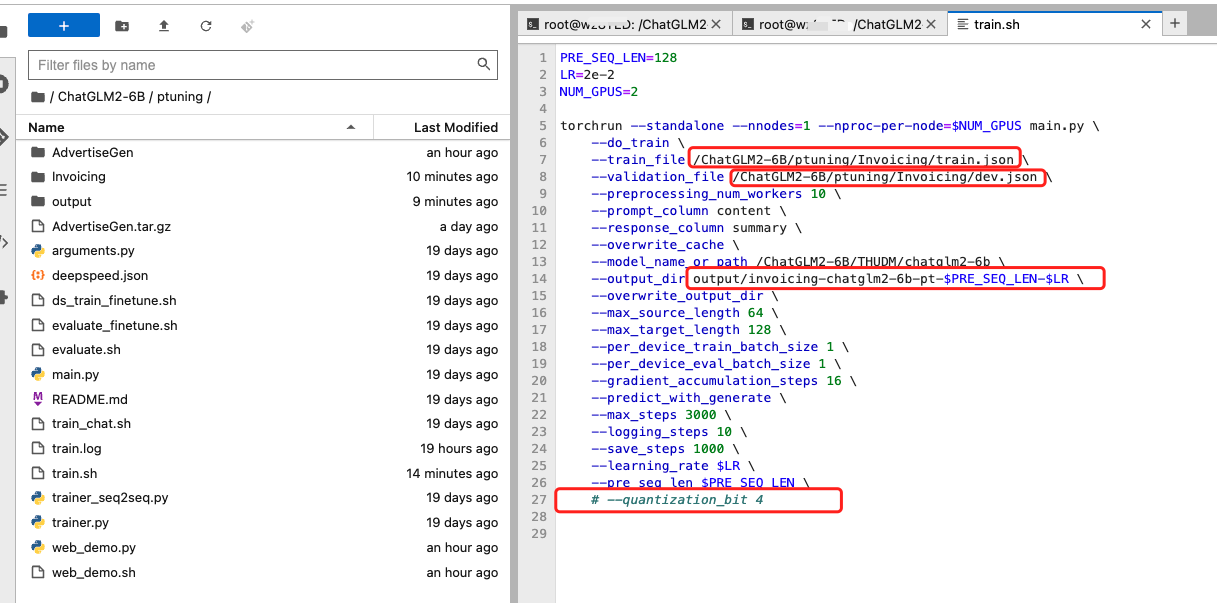
打开/ChatGLM2-6B/ptuning/train.sh文件,因为我们租用的是2卡 A30,所以将NUM_GPUS设置成2即可,其余路径默认设置即可。(数据集路径是官方代码设置好的,使用AdvertiseGen数据集时不需要修改,使用自己数据集请改成对应数据集目录)
另外模型目录需要从THUDM/chatglm2-6b改为 /ChatGLM2-6B/THUDM/chatglm2-6b。
更多参数可以查看官方文档介绍:
官方文档地址:https://github.com/THUDM/ChatGLM2-6B/tree/main/ptuning
再回到 Terminal 输入以下指令开始训练:
# 注意,此时你在 /ChatGLM2-6B/ptuning 目录下
# 如果不在,请先运行 cd /ChatGLM2-6B/ptuning 进入对应目录
nohup bash train.sh > train.log 2>&1 &
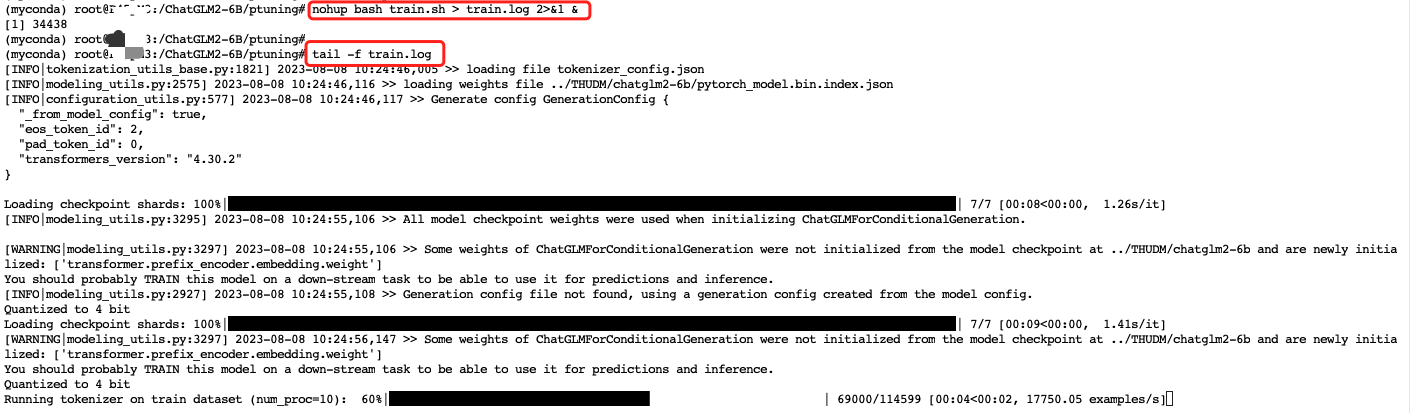
输入上面指令挂后台训练后,即使本地网络波动也不会影响程序运行,在 Terminal 里输入tail -f train.log即可看到程序运行日志,正常训练~
tail -f train.log
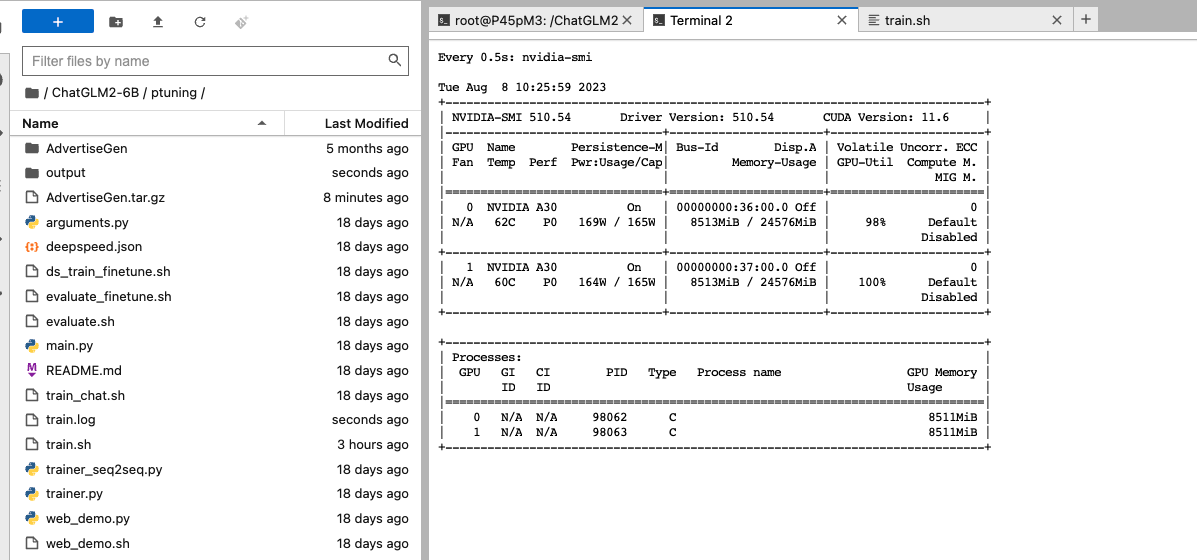
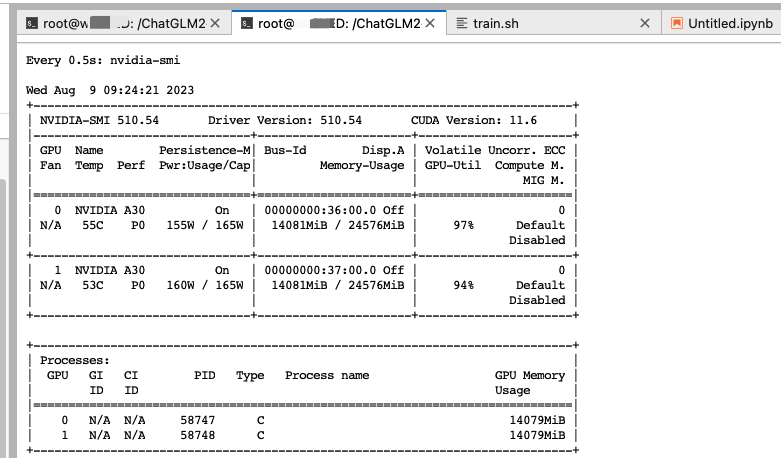
训练时显存占用和GPU利用率情况。
watch -n 0.5 nvidia-smi
查看训练数据
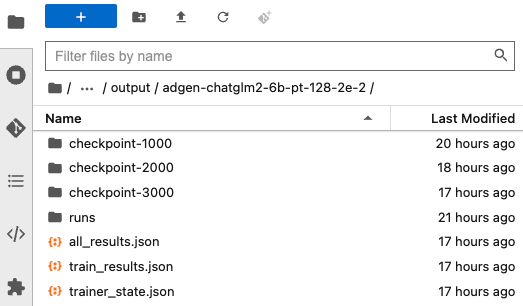
训练完成后,所有输出会存放在/ChatGLM2-6B/ptuning/output目录下,包括训练保存的模型和运行日志、其他结果数据。
我们可以使用 tensorboard 查看日志可视化图,在 Terminal 输入下面指令即可开启 tensorboard 。
# 注意,此时你在 /ChatGLM2-6B/ptuning 目录下
# 如果不在,请先运行 cd /ChatGLM2-6B/ptuning 进入对应目录
tensorboard --logdir ./output/adgen-chatglm2-6b-pt-128-2e-2/runs --bind_all

tensorboard 启动成功后,再访问租用页面 6006 端口链接即可查看 tensorboard 可视化结果了。
-
点击打开页面
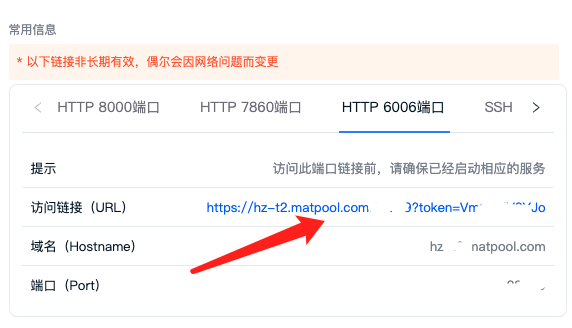
-
看训练数据可视化图
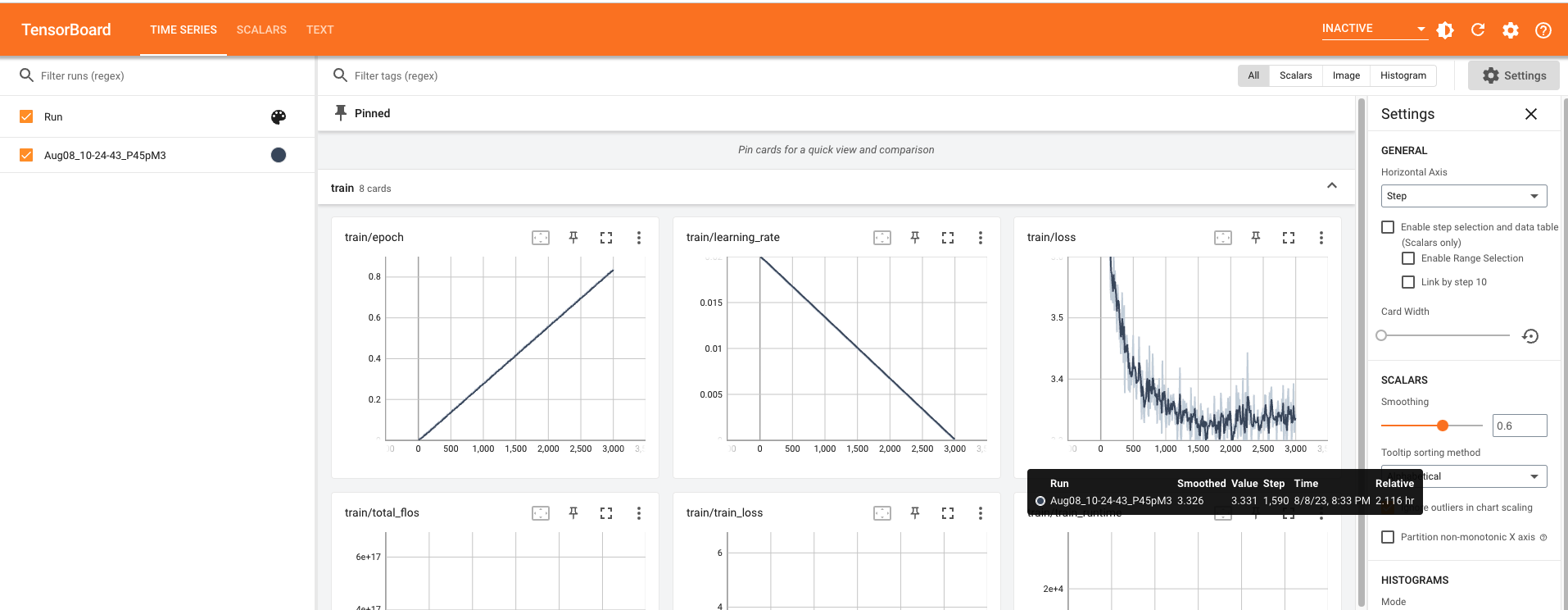
模型部署
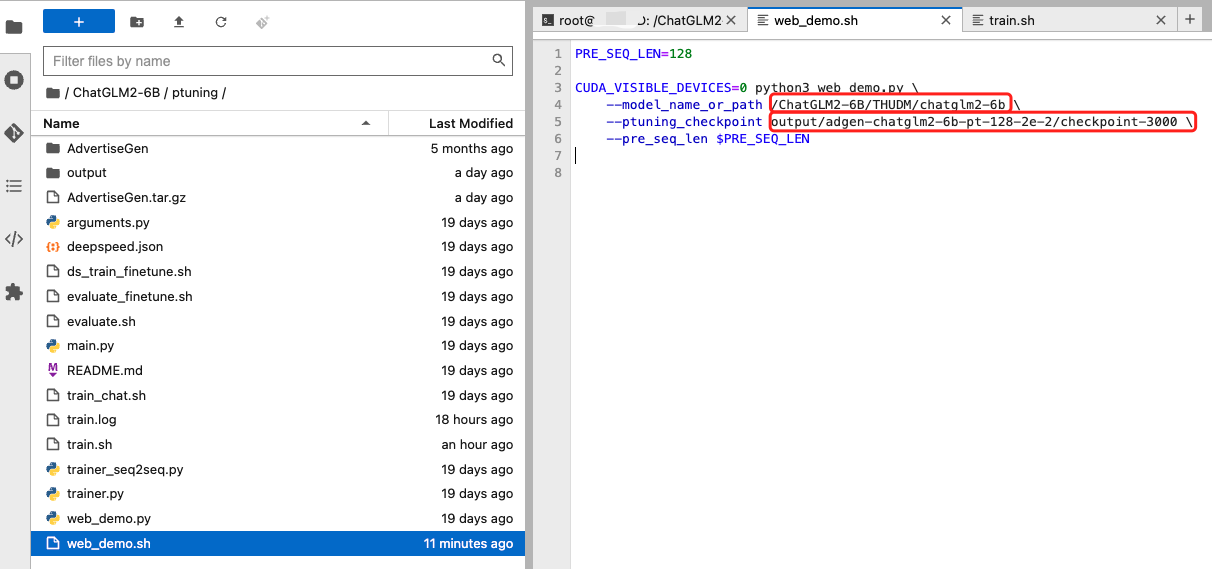
官方提供了一个脚本web_demo.sh,我们打开这个文件,只需要修改下model_name_or_path和ptuning_checkpoint即可。
model_name_or_path值改成/ChatGLM2-6B/THUDM/chatglm2-6bptuning_checkpoint值改成你自己微调保存模型路径
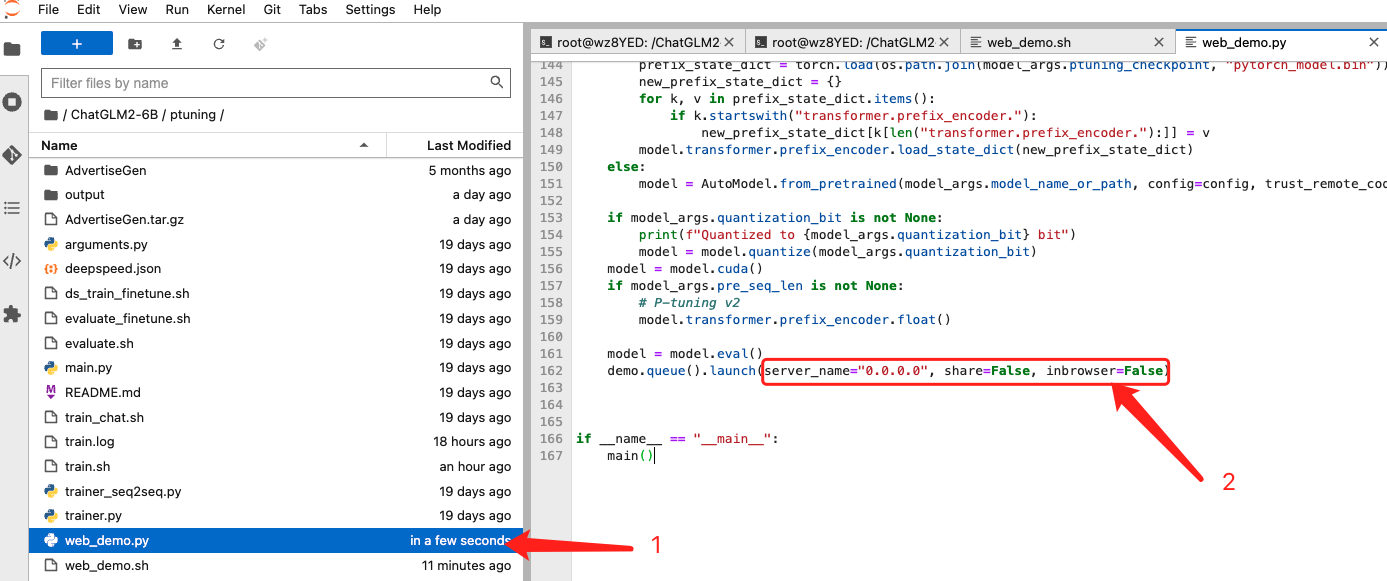
为了能公网正常访问,还需要改下web_demo.py,将该文件162行代码改为:
demo.queue().launch(server_name="0.0.0.0", share=False, inbrowser=False)
然后在 Terminal 里运行以下指令启动服务。
# 注意,此时你在 /ChatGLM2-6B/ptuning 目录下
# 如果不在,请先运行 cd /ChatGLM2-6B/ptuning 进入对应目录
bash web_demo.sh

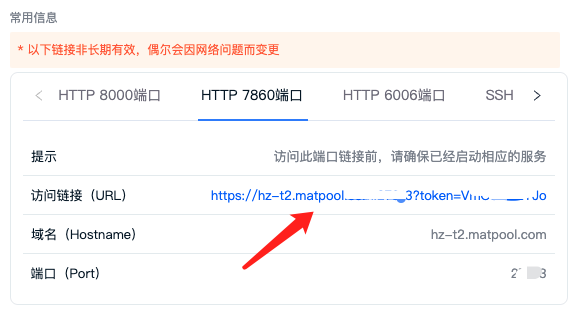
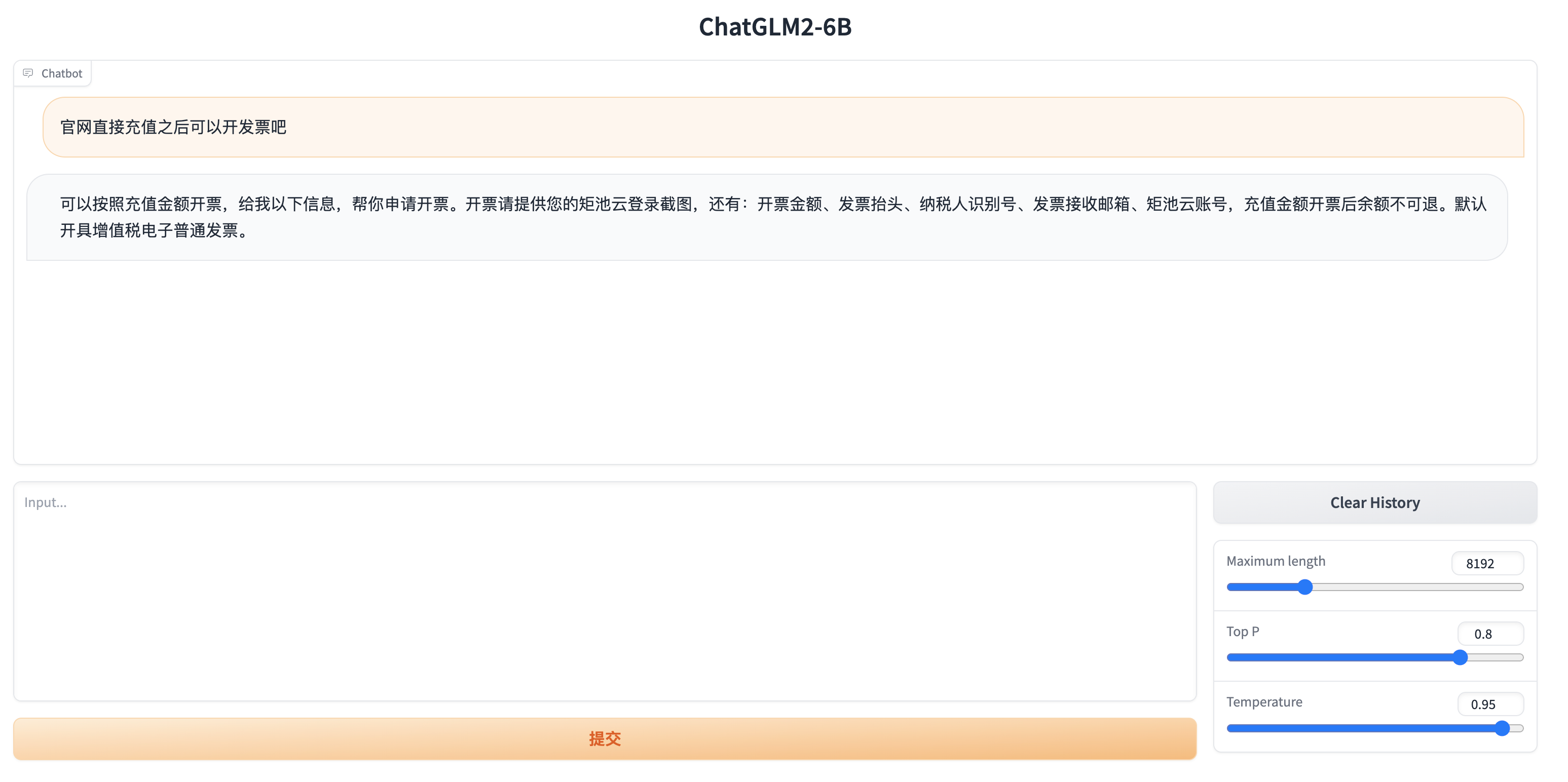
启动成功后,再访问租用页面 7869 端口链接即可访问模型服务了,测试结果如下:
-
点击打开页面
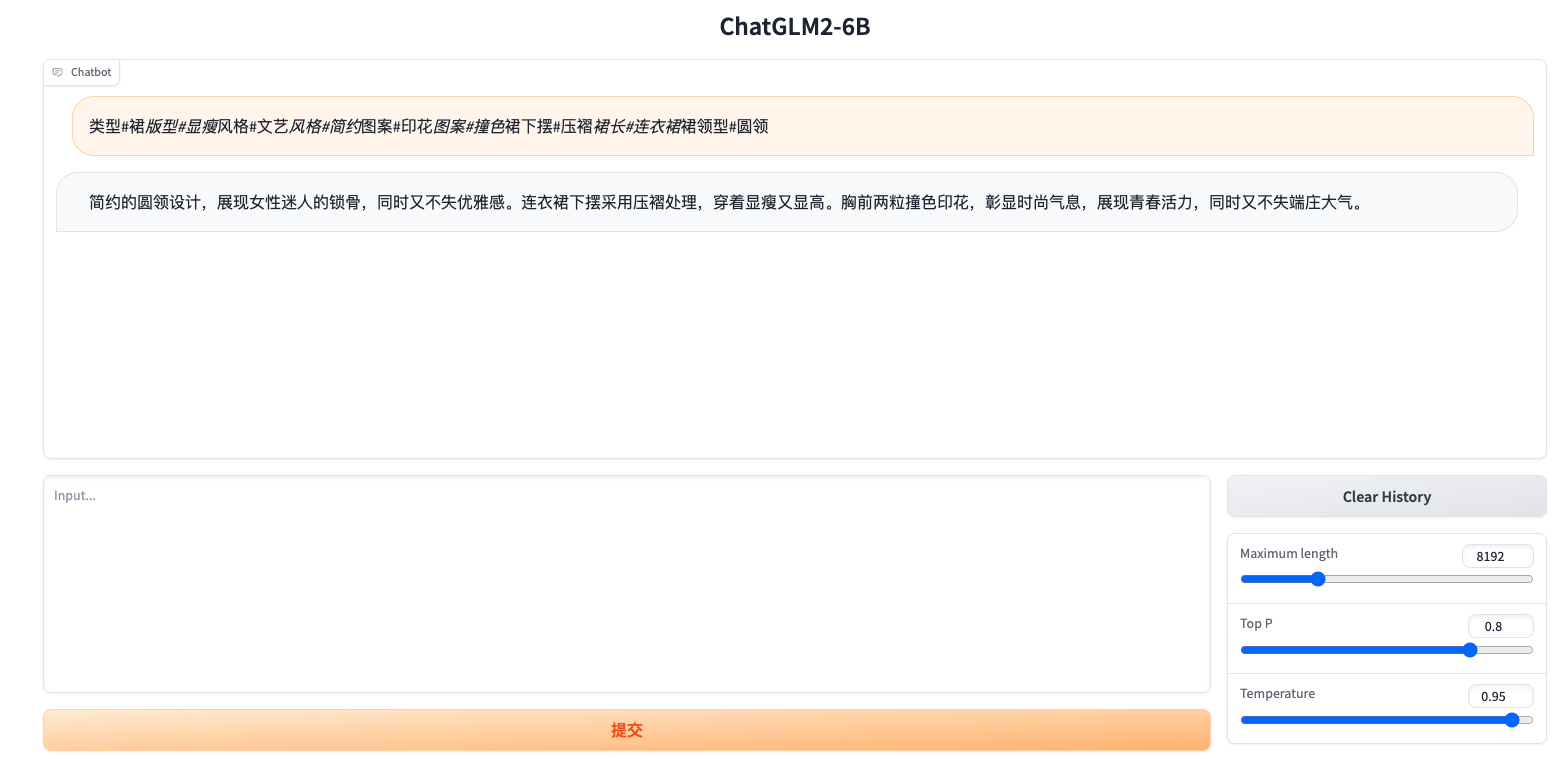
-
测试训练效果
微调自己的数据集
首先需要在/ChatGLM2-6B/ptuning下新建一个目录用于存放训练用的数据,如果你数据已经上传到了矩池云网盘也可以不创建,train.sh 里路径直接指定你网盘路径即可,服务器内网盘对应/mnt目录。

训练需要两个数据集,一个 train.json 训练用,一个 dev.json 验证用。
注意数据格式,每一行是一个字典,键和键值都必须使用"(双引号)包裹,不能使用单引号,不然数据读取会出错。
{"content": "你的问题", "summary": "问题答案"}
数据集都准备好,接下来就是修改train.sh,主要修改以下几个参数,其他大家可以根据需要修改:
- train_file、validation_file 训练、验证数据集路径,需要改成你自己的,最好写绝对路径
- output_dir 训练结果输出目录,可以改下,避免覆盖之前训练结果
- quantization_bit 如果租用机器显存够(大于13g)可以去掉,无量化训练结果更好,对应需要更大显存
再回到 Terminal 输入以下指令开始训练:
# 注意,此时你在 /ChatGLM2-6B/ptuning 目录下
# 如果不在,请先运行 cd /ChatGLM2-6B/ptuning 进入对应目录
nohup bash train.sh > train_me.log 2>&1 &
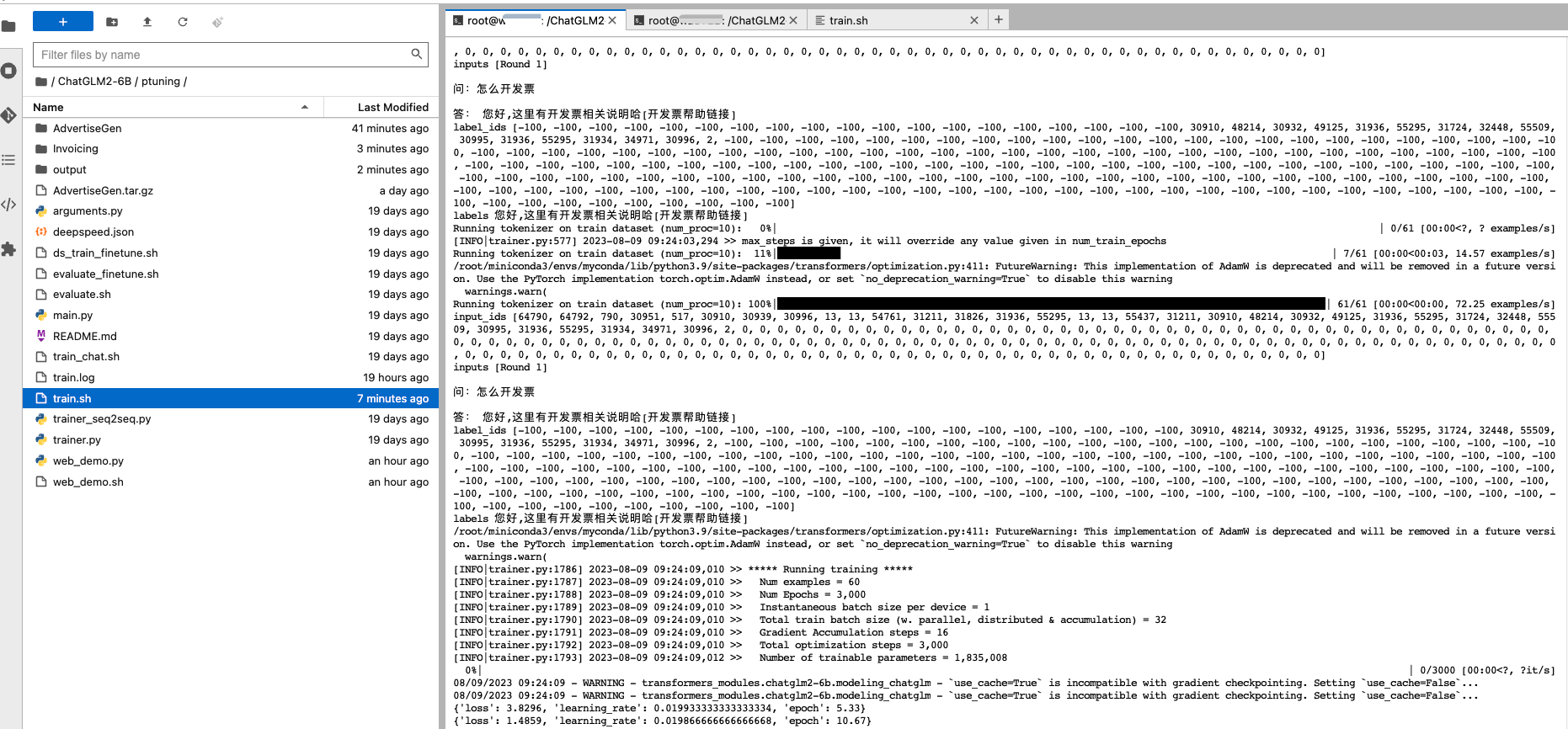
输入上面指令挂后台训练后,即使本地网络波动也不会影响程序运行,在 Terminal 里输入tail -f train.log即可看到程序运行日志,正常训练~
tail -f train_me.log
训练时显存占用和GPU利用率情况,可以看到无量化模型训练显存占用14g多。
watch -n 0.5 nvidia-smi
训练完成后,可以像前面一样使用 tensorboard查看训练数据 和 部署模型web服务,测试效果如下:
Github 还有很多其他微调项目,欢迎大家评论区交流。