文章目录
- 1. 背景介绍
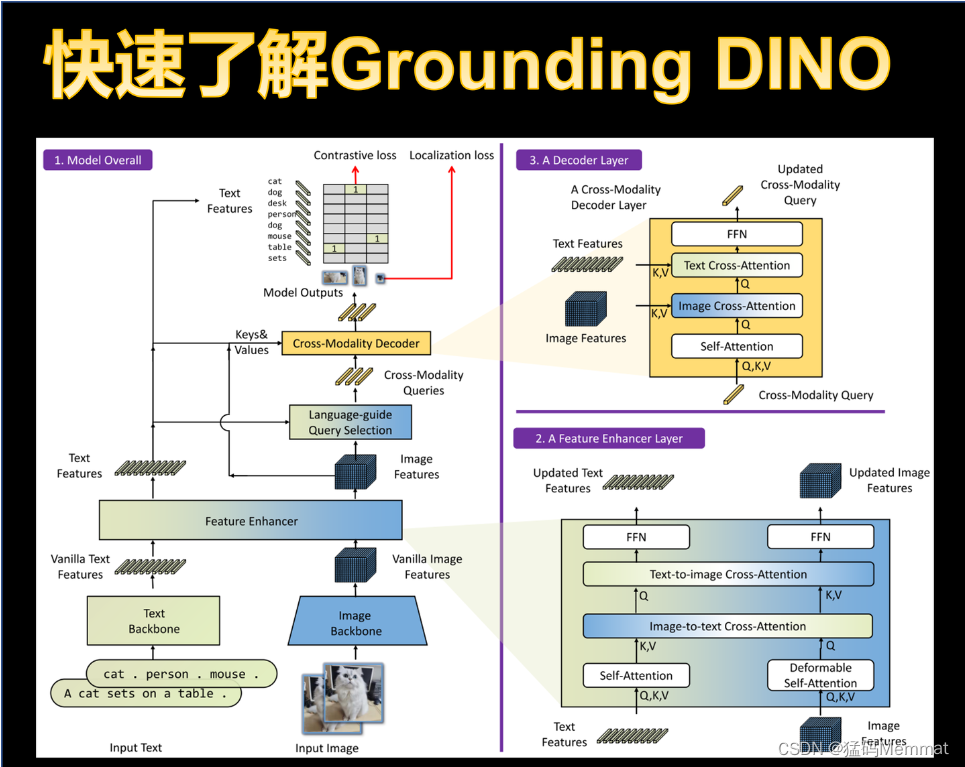
- 2. 方法创新
-
- 2.1 Feature Extraction and Enhancer
- 2.2 Language-Guided Query Selection
- 2.3 Cross-Modality Decoder
- 2.4 Sub-Sentence Level Text Feature
- 2.5 Loss Function
- 3. 实验结果
-
- 3.1 Zero-Shot Transfer of Grounding DINO
- 3.2 Referring Object Detection Settings
- 3.3 Ablation
- 参考文献
既CLIP打破文字和图像之间的壁垒、DINO提高了目标检测精度的上限之后,又一力作横空出世,它就是 Grounding DINO。
简单来说,Grounding DINO可以根据文字描述检测指定目标。例如下图左侧,你告诉它:“检测左边的狮子!”,它就会只把左边的狮子框选出来,是不是很神奇?当Grounding DINO和stable diffusion结合时,就会出现更加神奇的功能:自动P图。如下图右侧,你告诉它:“将左侧的狮子变成狗”,它就会帮你把左边的狮子P成狗。

在不需要任何COCO训练集的情况下,Grounding DINO就在COCO minival测试集中达到了52.5AP,经过微调之后达到了63.0AP。这样的结果可以说是非常的Amazing了,下面我将详细介绍Grounding DINO的原理。
1. 背景介绍
在视觉领域,要