一、说明
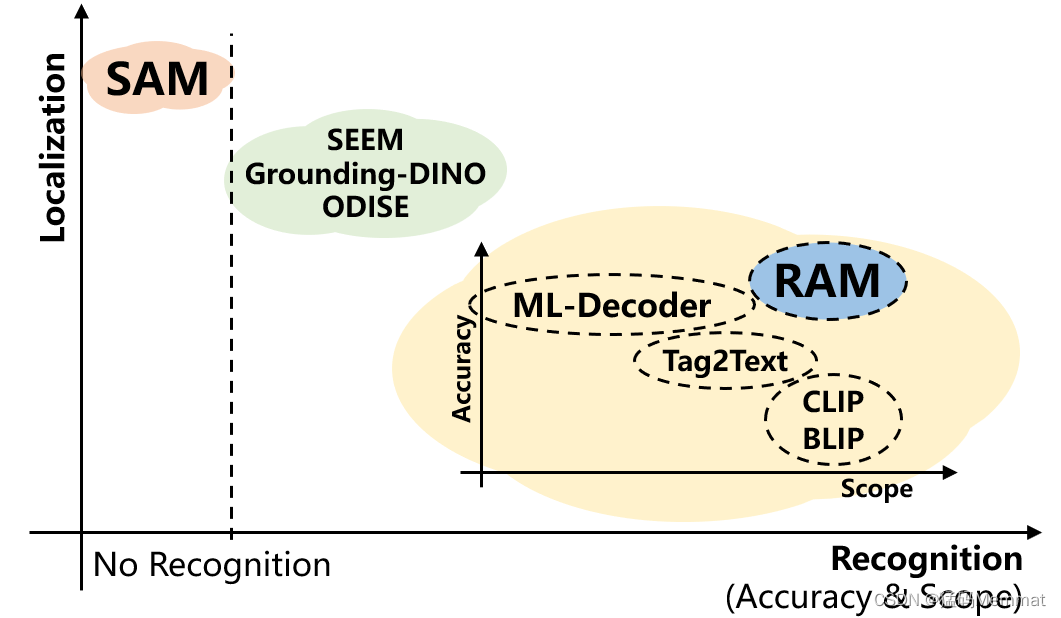
目前在文本和图像领域中,统治江湖的有六大门派,他们是:OpenAI,Google,Microsoft,Midjounery,StabilityAI,CharecterAI. 每个人都在竞相为文本到文本,文本到图像,图像到图像和图像到文本模型带来最佳解决方案。然而,如何扎根于客户,那将是另一个棘手问题。
OpenAI,Google,Microsoft,Midjourney,StabilityAI,CharacterAI
原因很简单——空间提供了广阔的机会;毕竟,解锁的不仅是娱乐,还有实用性。从更好的搜索引擎到更令人印象深刻和个性化的广告活动和聊天机器人,如 Snap 的 MyAI。
虽然这个空间非常不稳定,每隔几天就会发布许多活动部件和模型检查点,但每个使用生成式人工智能的公司都在寻求解决挑战。
在这里,我将讨论在生产中部署生成模型时的主要挑战以及如何解决这些挑战。虽然有许多不同类型的生成模型,但在本文中,我将重点介绍扩散和基于 GPT 的模型的最新进展。但是,此处讨论的许多主题也适用于其他模型。
二、什么是生成式 AI?
生成式 AI 广泛描述了一组可以生成新内容的模型。广为人知的生成对抗网络通过学习真实数据的分布并从增加的噪声中产生可变性来实现这一点。
最近生成式人工智能的繁荣来自大规模达到人类水平质量的模型。解锁这种转变的原因很简单——我们现在才有足够的计算能力(因此 NVIDIA 股价暴涨)来训练和维护具有足够容量的模型,以实现高质量的结果。当前的进步是由两个基本架构推动的——变压器和扩散模型。
也许最近一年最重要的突破是OpenAI的ChatGPT——一个基于文本的生成模型,最新的ChatGPT-175.3版本之一有5亿个,它有一个足够的知识库来维持各种主题的对话。虽然 ChatGPT 是一个单一模态模型,因为它只能支持文本,但多模态模型可以将多种输入作为输入和输出,例如文本和图像。
图像到文本和文本到图像的多模式架构在文本和图像概念共享的潜在空间中运行。潜在空间是通过对需要两个概念(例如,图像标题)的任务进行训练而获得的,方法是惩罚两种不同模态中同一概念之间潜在空间中的距离。一旦获得这个潜在空间,就可以将其重新用于其他任务。

图像到文本模型的示例。图片由作者提供。
今年发布的值得注意的生成模型是DALLE / Stable-Diffusion(文本到图像/图像到图像)和BLIP(图像到文本实现)。DALLE模型将提示或图像作为输入,提示生成图像作为响应,而基于BLIP的模型可以回答有关图片内容的问题。
三、挑战与解决方案
不幸的是,在机器学习方面没有免费的午餐,大规模生成模型在生产中部署时偶然发现了一些挑战——大小和延迟、偏见和公平性,以及生成结果的质量。
3.1 挑战1:模型大小和延迟
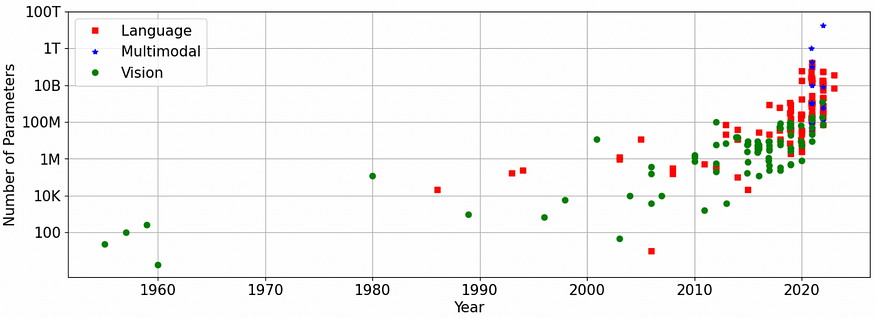
模型大小趋势。数据来自P. Villalobos。
最先进的GenAI模型是巨大的。例如,文本到文本 Meta 的 LLaMA 模型范围在 7 到 65 亿个参数之间,而 ChatGPT-3.5 是 175B 参数。这些数字是合理的——在简化的世界中,经验法则是模型越大,用于训练的数据越多,质量就越好。
文本到图像模型虽然较小,但仍然比它们的生成对抗网络前辈大得多——稳定扩散 1.5 检查点略低于 1B 参数(占用超过 2GB 的空间),而 DALLE 0.3 具有 5.<>B 参数。很少有 GPU 有足够的内存来维护这些模型,通常您需要一个队列来维护单个大型模型,这可能很快就会变得非常昂贵,更不用说在移动设备上部署这些模型了。
生成模型需要时间来生成输出。对于某些人来说,延迟是由于它们的大小——即使在一组 GPU 上,通过数十亿个参数传播信号也需要时间,而对于其他人来说,这是由于产生高质量结果的迭代性质。扩散模型在其默认配置中需要 50 个步骤来生成图像,步骤数越少会降低输出图像的质量。
解决 方案: 使模型变小通常有助于使其更快 - 提炼,压缩和量化模型也可以减少延迟。高通公司通过压缩稳定的扩散模型来铺平道路,足以部署在移动设备上。最近发布了更小,蒸馏和更快的稳定扩散版本(微小和小型)。
特定于模型的优化也有助于加快推理速度——对于扩散模型;一个人可能会生成低分辨率输出,然后对其进行放大,或者使用较少的步骤和不同的调度程序,因为有些步骤在步骤数较少的情况下效果最好,而另一些则为更多的迭代生成卓越的质量。例如,Snap 最近表明,八个步骤足以在训练时采用各种优化,使用 Stable Diffusion 1.5 创建高质量的结果。
3.2 挑战2:偏见、公平和安全
你有没有尝试过打破ChatGPT?许多人已经成功地发现了偏见和公平问题,而OpenAI在解决这些问题方面做得很好。如果没有大规模的修复,聊天机器人可以通过传播有害和不安全的想法和行为来制造现实世界的问题。
人们设法打破模式的例子,是在政治中;例如,ChatGPT拒绝创作关于特朗普的诗歌,但会创作一首关于拜登、性别平等和就业的诗歌——这意味着有些职业是男性的,有些是女性和种族的。
与文本到文本模型一样,文本到图像和图像到文本模型也包含偏见和公平性问题。当要求生成医生和护士的图像时,稳定扩散2.1模型为前者生成白人男性,为后者生成白人女性。有趣的是,这种偏见取决于提示中指定的国家 - 例如,日本医生或巴西护士。


要求稳定扩散模型生成医生图像和护士图像。由作者使用 SD 2.1 界面生成的图像。
玩弄 BLIP 图像到文本模型并输入超重者和男性和女性医生的图像,我得到了判断和偏见的图像描述——“一个胖子”、“一个男医生”、“一个穿着实验室外套拿着听诊器的女人”。



作者使用稳定扩散 2.1 生成的图像和从左到右使用 BLIP 模型生成的标题 [1] 一个胖子吃冰淇淋甜筒;[2] 一名身穿白大褂和领带的男医生;[3] 一个穿着白色实验室外套的女人,脖子上戴着听诊器。图像由作者使用 SD 2.1 接口生成,并通过 BLIP 传递。
如何测试问题: 这是一个相当难以诊断的问题——在许多情况下,您需要知道要寻找什么。拥有一个单独的基准数据集,其中包含各种各样的提示,其中可能会或可能不会出错,我们将检测到的每个答案的模板响应和危险信号,以及来自不同背景和多个场景的人的数据集存储有关图片中人的所有可能属性会有所帮助。这些数据集需要有数十万个条目才能获得可靠的统计数据。
溶液:几乎所有的偏见、公平性和安全问题都来自训练数据。我喜欢这样的类比,即人工智能模型是人类的一面镜子,加剧了我们所有的偏见。对干净、公正的数据进行训练将极大地改善结果。然而,即使有这些,模型也会犯错误。
结果后处理和过滤是另一种可能的解决方案;例如,在包含裸体图像的数据上训练的稳定扩散具有NSFW内容检测器来捕获潜在问题。类似的筛选器可以应用于文本到文本模型的输出。
3.3 挑战3:输出质量、相关性和正确性
生成模型在解释用户请求方面可以非常有创意,虽然最近的大型模型达到了人类水平的质量,但对于每个用例,它们不会开箱即用,需要额外的调整和及时的工程。
在早期非常有限的图像到文本和文本到文本模型中评估质量相对简单 - 毕竟,对胡言乱语的改进是显而易见的。高质量的生成模型开始表现出更难检测的行为;例如,文本到文本模型可能会变得回避,自信地吐出不正确和过时的信息。
扩散模型在其他方面表现出输出缺陷。基于图像的模型的典型问题是几何形状损坏、解剖结构突变、提示与图像结果不匹配、图像传输情况下的肤色和性别不匹配。美学和现实主义的自动评估滞后,典型的指标(如 FID)无法捕获这些变化。



从左到右:[1]两个人拥抱;[2] 一个竖起大拇指的男人;[3] 一只狗在公园里奔跑。作者生成的稳定扩散 1.5 中的图像
如何测试问题:测试生成模型的质量具有挑战性;毕竟,这些模型没有基本事实——它们是为了提供新颖的输出而制作的。因此,到目前为止,没有任何指标能够可靠地捕获质量方面。最可靠的指标是人工评估。
就像在偏见和公平性评估中一样,最好的方法是拥有一个大型的提示和图像数据集来测试质量。随着文本到文本模型变得更加个性化并针对每个用户进行调整,除了对话的连贯性、正确性和相关性之外,我们还希望评估他们记住对话信息的能力。
溶液: 许多质量问题可以归因于模型的训练数据和大小;它们可能有点太小了,无法实现另一个质量飞跃(想想 GPT-3.5 与 GPT-4)——当前的潜在空间是一种抽象,并不是为了存储精确的信息而设计的。 许多问题可以通过更好的提示工程来解决 - 文本到文本和文本到图像的提示增强以及文本到图像模型的负面提示。
文本到图像和图像到图像模型可以有额外的工具来提高质量 - 图像增强,无论是通过传统的深度学习方法还是基于扩散的精简程序。像ControlNet这样的附加模块以及与扩散架构正交的模块可以帮助对生成的结果进行额外的控制。用于微调特定应用程序的模型的Dreambooth技术也将有助于在结果中获得优势。使用其他参数(如调度程序、CFG 和扩散步骤的数量)会极大地影响质量。
四、总结
生成模型开辟了新的应用范围,既有有趣的,如人工智能镜头,也有商业的,如更好的搜索引擎、副驾驶和广告。与此同时,公司急于推出产品,消费者对新功能的兴奋有时会使技术中的明显流动被忽视。
虽然人们普遍推动通过发布大规模开源数据集、训练代码和评估结果来提高模型基准测试的透明度,但也有人推动对大规模人工智能模型进行更严格的监管。在一个理想的世界里,两者都不会走向极端,并且会互相帮助,使人工智能更安全、更有趣。