gearman基础
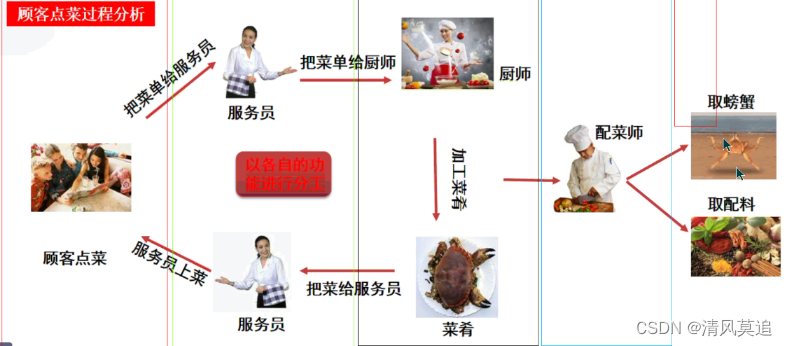
工作原理

部署架构
本质上,gearman可以认为是一个分布式任务队列,client是生产者,worker则是消费者。gearman并不主动分发任务,而是由worker到它那里去取任务执行,所以它采用的是类似kafka的pull消费模式。
启动、停止服务
service gearmand start
service gearmand restart
service gearmand stop
修改gearmand启动参数
配置文件路径在:
/etc/init.d/gearmand
管理命令
(echo status; sleep 0.1) | nc 127.0.0.1 4730
结果形如:
simu 0 0 2
msg 0 0 0
test 0 0 6
每列说明如下:
函数名: job的函数名
Number in queue:队列里该函数下的job总数,包含当前正在运行的job
Number of jobs running: 该函数当前正在运行的job数
Number of capable workers: 可以做该job的worker总数
如果系统比较繁忙的话,Number of jobs running的数值会接近Number of capable workers;Number in queue可能会大于Number of capable workers。此时我们应该增加Worker的数量,反之则应该考虑减少Worker的数量。
gearman优势
- 跨语言的调用,worker可以用多种语言来写。
- 跨平台,client可以在linux上,而worker甚至可以在windows上。
进阶
持久化
对于任务队列持久化的问题,是一个值得考虑的问题。持久化必然影响高性能。gearman支持后台工作任务的持久化,支持drizzle、mysql、memcached的持久化。对于client提交的background job,Job server除了将其放在内存队列中进行派发之外,还会将其持久化到外部的持久化队列中。一旦Job server发生问题重启,外部持久化队列中的background job将会被恢复到内存中,参与Job server新的派发当中。这保证了已提交未执行的background job不会由于Job server发生异常而丢失。并且我测试发现如果开启了持久化,那么background工作任务会先将工作任务写到持久化介质,然后再入内存队列,再执行。非background工作任务,由于client与job server是保持长连接的状态,如果工作任务执行异常,client可以灵活处理,所以无须持久化。
background任务的状态获取
一个background任务的查询结果形如:
<GearmanJobRequest task='simu', unique='bfa0751a74bb0b38b01e07bc90557757', priority=None, background=True, state='CREATED', timed_out=False>
Job bfa0751a74bb0b38b01e07bc90557757 finished! Result: CREATED - None, Data:deque([]), Status:{'numerator': 0, 'time_received': 1587369989.1067996, 'running': True, 'known': True, 'denominator': 0, 'handle': 'H:camera-vm68:217'}
Job bfa0751a74bb0b38b01e07bc90557757 finished! Result: CREATED - None, Data:deque([]), Status:{'numerator': 0, 'time_received': 1587369991.1361463, 'running': False, 'known': False, 'denominator': 0, 'handle': 'H:camera-vm68:217'}
可见,一个任务一旦被设置为background执行,最后只能了解它是否执行完了,结果成功与否及中间进度都无法获得,client的get_job_status接口仅能用于非background任务的状态查询。
worker踢出
现象:
某个worker出现快速失败,然后又不停的到队列里拿任务,最后导致任务的大面积失败。
由于gearman server不主动分发,而是由worker“任性自为”,所以gearman server自身并无一个踢出快速失败worker的机制,需依赖于gearman client或worker来做这个事情。
具体说来,gearman client可以统计worker在一段时间内的失败次数、查询worker失败信息,来发现可能是快速失败的机器。另一方面,worker自己也可以根据错误信息来进行自我隔离。
tcp保活
起因:TCP对于非正常断开的连接并不能侦测到(比如网线断掉)。
我们先说一下TCP关闭连接时的动作,比如A和B通信,A向B发送一个FIN,B返回一个FIN,双方各自把单边的连接断开,整个TCP连接就结束了。如果,A突然崩溃了,这个FIN发不出去,没有保活机制,B可能就永远发现不了。
一般情况下,我们重启机器或者kill进程,socket文件句柄关闭,底层的TCP协议栈会为我们自动发送FIN,但接收端不一定能收到,比如下面的例子:
We are seeing some TCP behavior that we have not seen before. Normally when we kill a task that has a link over the local interface to another local task, in tcpdump we see that TCP sends a [FIN, ACK] from the side that died to the running task. The running task sends an [ACK] back. Then the side that died sends an [RST] back to the running task, and the running task is notified via normal socket ops that the link has disappeared.
Occasionally when the link has been up for a number of days, when we kill a task we are not seeing any traffic in tcpdump between the two sides. The task that is killed disappears. The link in netstat going to the running task has no client process listed and is in the FIN_WAIT1 state. The link in the other direction from the running task to the killed task is still in ESTABLISHED. The socket layer in the running task is never notified that the link has disappeared.
第二段说的就是kill进程时另一端没有得到FIN通知,从而导致连接残留,至于另一端没有得到FIN通知的原因,在这个案例里是因为防火墙策略,我觉得也不能排除丢包等其他可能。
tcp保活参数,是用下面命令查看:
cd /proc/sys/net/ipv4
cat tcp_keepalive_time
cat tcp_keepalive_intvl
cat tcp_keepalive_probes
三个参数的解释:
tcp_keepalive_time,在TCP保活打开的情况下,最后一次数据交换到TCP发送第一个保活探测包的间隔,即允许的持续空闲时长,或者说每次正常发送心跳的周期,默认值为7200s(2h)。
tcp_keepalive_probes 在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包次数,默认值为9(次)
tcp_keepalive_intvl,在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包的发送频率,默认值为75s。
gearmand上残留垃圾worker问题的解决
我们有时会发现一些worker被kill掉之后,或者某些机器panic了,在gearmand上依然能看到,原因是:gearmand侧因为某种原因未收到FIN通知,而它默认又没开TCP 保活,导致出现残留TCP连接。
我们可用如下选项使能TCP保活,比如下面的例子(案例链接 ):
/usr/local/sbin/gearmand -p 4732 -L0.0.0.0 --log-file /usr/local/var/log/gearmand1.log --verbose=INFO -w 5 --keepalive --keepalive-idle=60 --keepalive-interval=30 --keepalive-count=3
我们可使用netstat -o选项来查看保活定时器是否生效:
netstat -apno | grep 49539
输出结果为:
tcp 0 0 0.0.0.0:4732 0.0.0.0:* LISTEN 49539/gearmand off (0.00/0/0)
tcp 0 0 xx.xx.xx.67:4732 xx.xx.xx.74:39048 ESTABLISHED 49539/gearmand keepalive (0.80/0/0)
第一行表示gearmand监听在4732端口。第二行表示xx.74有一个worker连接上来,且连接是有keepalive定时器的,keepalive括号里的三列数据,第一列是定时器当前剩余时间,第三列是已重试次数。
我们发现,gearmand和worker之间始终是连接上的(相应的,我们会发现第三列"重试次数"始终为0),说明worker端也在做keepalive。
现在,我们在worker所在的xx.74上把39048端口封掉(可用iptables -D OUTPUT 1恢复)
iptables -A OUTPUT -p tcp --sport 39048 -j DROP
意味着worker不能向gearmand发送报文来维持keepalive了,很快,我们发现netstat -o结果的第三列“重试次数”达到最大值,worker连接被gearmand强制关闭。
再看看gearmand不做keepalive是什么现象,使用如下命令启动gearmand:
/usr/local/sbin/gearmand -p 4732 -L0.0.0.0 --log-file /usr/local/var/log/gearmand_4732.log --verbose=DEBUG -w 5
用netstat命令查出worker端口,接着用iptables命令封掉该端口,结果发现,即使我们把worker停掉,gearmand侧始终还是有这个worker连接,亦即gearmand认为这个连接仍然有效,这样客户端就会挂住!
不过,奇怪的是,如果此时我们新增其它worker进来,gearmand就能察觉到这种“连接残留”现象,把无效连接清理出去,并且后续新增的worker连接都会使用间隔为7200s(系统默认值)的keepalive定时器!
如果我们不新增worker连接呢?客户端就会一直挂住。
综上,有几点结论:
- gearmand默认不启动keepalive,但一旦它发现有“连接残留”现象,会对随后新加入的worker连接起一个默认时长(取决于操作系统的tcp_keepalive_time值,一般是7200s)的keepalive定时器;
- 为了能够及时发现挂死worker,需要指定gearmand的keepalive参数到一个合适的值;
- gearman客户端似乎是有keepalive动作的;
- 使用iptables封端口命令可以模拟出“连接残留”现象。
取消任务
gearadmin --cancel-job <job-handle>
This can be used to cancel a job that is not currently being handled by a worker. This will not cancel a job which is already in progress (though if the job fails, it will not be run again).
使用的是gearmand提供的cancel job 管理命令,参考这里
但只能取消还在排队的,若已经执行,则无法取消
gearman占用文件句柄数
一个worker连接就会打开一个文件句柄(socket),所以ulimit的限制对gearmand是有效的。
首先查看gearmand的ulimit限制:
cat /proc/32144/limits | grep "Max open files"
结果可能是:
Limit Soft Limit Hard Limit Units
Max open files 1024 4096 files
接着使用
ulimit -a
查看系统限制,结果可能是:
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 1028104
max locked memory (kbytes, -l) 16384
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 1028104
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
查看open files那一项,为1024,说明每个进程最多只能打开1024个文件句柄。
再看看gearmand占用了多少个文件句柄:
ls -l /proc/34488/fd | wc -l
结果是903.
所以初步怀疑gearmand的卡死跟文件句柄数有关系。调整方法如下,增加-f选项,指定接收的文件句柄数为2048:
/usr/local/sbin/gearmand -d -L0.0.0.0 --log-file /usr/local/var/log/gearmand.log --verbose=INFO -w 5 -f 2048 --keepalive --keepalive-idle=60 --keepalive-interval=30 --keepalive-count=3
顺带说一句,gearmand的文件句柄占用数似乎满足如下的关系:
文件句柄数 > worker总数 + active worker数
所以,worker总数是800,一次批量发送200个任务,就很有可能突破默认的1024的界限。
gearman类似技术
celery:celery是一个分布式的任务调度模块,可以支持多台不同的计算机执行不同的任务或者相同的任务。