Linux 性能分析之iostat命令详解
iostat命令是IO性能分析的常用工具,其是input/output statistics的缩写。本文将着重于下面几个方面介绍iostat命令:
- iostat的安装
- iostat命令行选项说明
- iostat输出内容分析
- 如何确定磁盘IO的瓶颈
- iostat实际案例
命令的安装
iostat位于sysstat包中,使用yum可以对其进行安装。
yum install sysstat -y
iostat命令行选项说明
iostat命令的基本格式如下所示:
iostat <options> <device name>
- -c: 显示CPU使用情况
- -d: 显示磁盘使用情况
- –dec={ 0 | 1 | 2 }: 指定要使用的小数位数,默认为 2
- -g GROUP_NAME { DEVICE […] | ALL } 显示一组设备的统计信息
- -H 此选项必须与选项 -g 一起使用,指示只显示组的全局统计信息,而不显示组中单个设备的统计信息
- -h 以可读格式打印大小
- -j { ID | LABEL | PATH | UUID | … } [ DEVICE […] | ALL ] 显示永久设备名。选项 ID、LABEL 等用于指定持久名称的类型
- -k 以 KB 为单位显示
- -m 以 MB 为单位显示
- -N 显示磁盘阵列(LVM) 信息
- -n 显示NFS 使用情况
- -p [ { DEVICE [,…] | ALL } ] 显示磁盘和分区的情况
- -t 打印时间戳。时间戳格式可能取决于 S_TIME_FORMAT 环境变量
- -V 显示版本信息并退出
- -x 显示详细信息(显示一些扩展列的数据)
- -y 如果在给定的时间间隔内显示多个记录,则忽略自系统启动以来的第一个统计信息
- -z 省略在采样期间没有活动的任何设备的输出
常见的命令行的使用如下所示:
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盘读写速度单位为KB),每1s收集1次数据,共收集10次
iostat -d -m 2 #查看TPS和吞吐量信息(磁盘读写速度单位为MB),每2s收集1次数据
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)等详细数据, 每1s收集1次数据,总共收集10次
iostat -c 1 10 #查看cpu状态,每1s收集1次数据,总共收集10次
iostat输出内容分析
在linux命令行中输入iostat,通常将会出现下面的输出:
[root@localhost ~]# iostat
Linux 5.14.0-284.11.1.el9_2.x86_64 (localhost.localdomain) 08/07/2023 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.31 0.01 0.44 0.02 0.00 99.22
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 3.19 72.63 35.90 0.00 202007 99835 0
dm-1 0.04 0.84 0.00 0.00 2348 0 0
nvme0n1 3.36 93.22 36.64 0.00 259264 101903 0
sr0 0.02 0.75 0.00 0.00 2096 0 0
首先第一行:
Linux 5.14.0-284.11.1.el9_2.x86_64 (localhost.localdomain) 08/07/2023 _x86_64_ (4 CPU)
Linux 5.14.0-284.11.1.el9_2.x86_64是内核的版本号,localhost.localdomain则是主机的名字, 08/07/2023当前的日期, _x86_64_是CPU的架构, (4 CPU)显示了当前系统的CPU的数量。
接着看第二部分,这部分是CPU的相关信息,其实和top命令的输出是类似的。
avg-cpu: %user %nice %system %iowait %steal %idle
0.31 0.01 0.44 0.02 0.00 99.22
cpu属性值说明:
- %user:CPU处在用户模式下的时间百分比。
- %nice:CPU处在带NICE值的用户模式下的时间百分比。
- %system:CPU处在系统模式下的时间百分比。
- %iowait:CPU等待输入输出完成时间的百分比。
- %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
- %idle:CPU空闲时间百分比。
这里对iowait这个指标进行讲解,这个指标很容易被误解。
首先要有这样一个概念,%iowait是%idle的一个子集,其计算方法是这样的:
如果 CPU 此时处于 idle 状态,内核会做以下检查
- 1、是否存在从该 CPU 发起的一个未完成的本地磁盘IO请求
- 2、是否存在从该 CPU 发起的网络磁盘挂载的操作
如果存在以上任一情况,则 iowait 的计数器加 1,如果都没有,则 idle 的计数器加 1。
例如假如间隔时间是 1s,则共有 100 个时钟,假如 sys 计数为 2, user 计数为 3,ncie计数为0,iowait 计数为 1 ,steal计数为0, idle 计数为 94,则 它们的百分比依次为:2%、 %3、 0%、 1%、0%、94%。
知道了iowait的计算方法后,下面讲解一下iowait常见的一些误解:
-
iowait 表示等待IO完成,在此期间 CPU 不能接受其他任务
从上面 iowait 的定义可以知道,iowait 表示 CPU 处于空闲状态并且有未完成的磁盘 IO 请求,也就是说,iowait 的首要条件就是 CPU 空闲,既然空闲就能接受任务,只是当前没有可运行的任务,才会处于空闲状态的,为什么没有可运行的任务呢? 有可能是正在等待一些事件,比如:磁盘IO、键盘输入或者等待网络的数据等 -
iowait 高表示 IO 存在瓶颈
由于 Linux 文档对 iowait 的说明不多,这点很容易产生误解,iowait 第一个条件是 CPU 空闲,也即所有的进程都在休眠,第二个条件是 有未完成的 IO 请求。这两个条件放到一起很容易产生下面的理解:进程休眠的原因是为了等待 IO 请求完成,而 %iowait 变高说明进程因等待IO 而休眠的时间变长了,或者因等待IO而休眠的进程数量变多了 初一听,似乎很有道理,但实际是不对的。
iowait 升高并不一定会导致等待IO进程的数量变多,也不一定会导致等待IO的时间变长,我们借助下面的图来理解:

在这三张图的变化中,IO没有发生任何变化,仅仅是CPU的空闲时间发生了变化,iowait的值就发生了很大的变化,因此仅根据 %iowait 不能判断出IO存在瓶颈。
下面回到iostat,看第三部分的输出结果。
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 3.19 72.63 35.90 0.00 202007 99835 0
dm-1 0.04 0.84 0.00 0.00 2348 0 0
nvme0n1 3.36 93.22 36.64 0.00 259264 101903 0
sr0 0.02 0.75 0.00 0.00 2096 0 0
其每一列的含义如下所示:
- Device:/dev 目录下的磁盘(或分区)名称
- tps:该设备每秒的传输次数。一次传输即一次 I/O 请求,多个逻辑请求可能会被合并为一次 I/O 请求。一次传输请求的大小是未知的
- kB_read/s:每秒从磁盘读取数据大小,单位KB/s
- kB_wrtn/s:每秒写入磁盘的数据的大小,单位KB/s
- kB_dscd/s: 每秒磁盘的丢块数,单数KB/s
- kB_read:从磁盘读出的数据总数,单位KB
- kB_wrtn:写入磁盘的的数据总数,单位KB
- kB_dscd: 磁盘总的丢块数量
需要注意的是,如果使用iostat -dk 2这样的命令,每2s收集一次数据,则kB_wrtn的含义是2s内写入磁盘的数据总数,而kB_read的含义是2s内从磁盘读出的数据总数,kB_dscd的含义则是2s内磁盘块的丢块数量。
如果没有时间间隔参数,例如iostat -dk,则kB_wrtn的含义是从开机以来的写入磁盘的数据总量,kB_read的含义是从开机以来的从磁盘读出的数据总数,kB_dscd的含义则是开机以来的磁盘块的丢块数量。
除此以外,iostat 可以使用-x输出一些扩展列,例如下面的输出:
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
dm-0 2.16 47.69 0.00 0.00 0.56 22.06 0.88 25.70 0.00 0.00 2.66 29.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.25
dm-1 0.02 0.49 0.00 0.00 0.30 23.72 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1 2.28 59.76 0.01 0.38 0.54 26.18 0.74 26.13 0.15 17.11 1.89 35.12 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.26
sr0 0.01 0.44 0.00 0.00 0.56 38.81 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
读指标:
- r/s:每秒向磁盘发起的读操作数
- rkB/s:每秒读K字节数
- rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);
- %rrqm: 合并读请求占的百分比
- r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间
- rareq-sz:平均读请求大小
写指标:
- w/s:每秒向磁盘发起的写操作数
- wkB/s:每秒写K字节数
- wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
- %wrqm:合并写请求占的百分比
- w_await:每个写操作平均所需的时间;不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间
- wareq-sz:平均写请求大小
抛弃指标:
- d/s:每秒设备完成的抛弃请求数(合并后)。
- dkB/s:从设备中每秒抛弃的kB数量
- drqm/s: 每秒排队到设备中的合并抛弃请求的数量
- %drqm:抛弃请求在发送到设备之前已合并在一起的百分比。
- d_await: 发出要服务的设备的抛弃请求的平均时间(以毫秒为单位)。 这包括队列中的请求所花费的时间以及为请求服务所花费的时间。
- dareq-sz: 发出给设备的抛弃请求的平均大小(以千字节为单位)。
其他指标:
- aqu-sz:平均请求队列长度
- %util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比,向设备发出I/O请求的经过时间百分比(设备的带宽利用率)。当串行服务请求的设备的该值接近100%时,将发生设备饱和。 但是对于并行处理请求的设备(例如RAID阵列和现代SSD),此数字并不反映其性能限制。这个指标高说明IO基本上就到瓶颈了,但是低也不一定IO就不是瓶颈。一般%util大于70%,I/O压力就比较大. 同时可以结合vmstat查看查看b参数(等待资源的进程数)和wa参数(I/O等待所占用的CPU时间的百分比,高过30%时I/O压力高)
实际测试案列
在测试时,使用dd命令来模拟磁盘的读写
dd if=/dev/zero of=./a.dat bs=8k count=1M oflag=direct
- if=文件名:输入文件名,默认为标准输入。即指定源文件。
- of=文件名:输出文件名,默认为标准输出。即指定目的文件。
- bs=bytes:同时设置读入/输出的块大小为bytes个字节。
- count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
上述命令将向a.dat文件中写入8G的数据。
打开另一个窗口,使用iostat进行监控。
首先看看iostat -kx 1的数据。
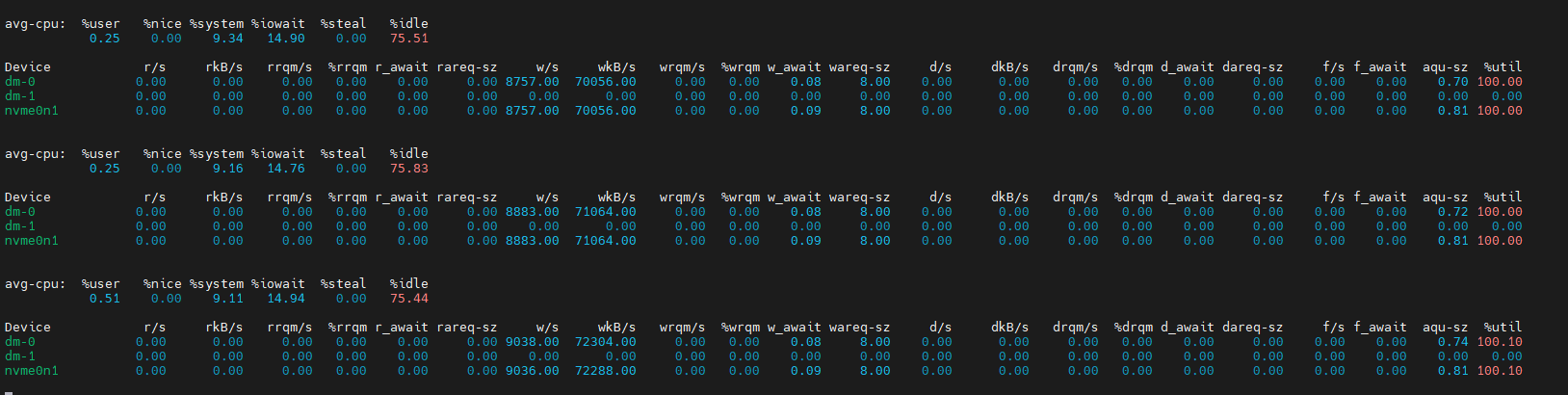
从wkB指标得知,现在磁盘的写入速度在70M左右。从%util指标得知,目前磁盘的使用率已经高达100%,满负荷运行。此时iowait的值为15%左右。
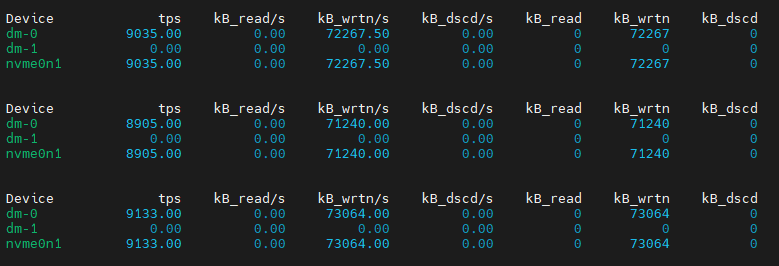
再看看iostat -dk 1的输出:
从kB_read/s指标得知,目前磁盘的写入速度在70M左右。
参考文章
https://blog.csdn.net/qq_35965090/article/details/116503427
https://www.modb.pro/db/46145
https://cloud.tencent.com/developer/article/1843341(iowait的解析)
https://www.cnblogs.com/sparkdev/p/10354947.html(stress命令)




![[保研/考研机试] KY85 二叉树 北京大学复试上机题 C++实现](https://img-blog.csdnimg.cn/2f58798bbd8f4036bc006fcc3c4a7627.png)





![[保研/考研机试] KY96 Fibonacci 上海交通大学复试上机题 C++实现](https://img-blog.csdnimg.cn/028cd93399214b76ae0c0e8ddb320fc9.png)