0.概述
-
目的:创建一个可以改变门把手形状、类型、位置、环境颜色、照明条件、机械臂结构的仿真环境,以训练出鲁棒性更高、更能关注到任务本质特征、容易迁移到现实的模型


-
网址:环境下载,
1.领域随机化DR
- 假设很难对目标域进行完美建模,但很容易创建许多不同的模拟来近似目标域
2.引擎
- Unity:用来为视觉提供渲染画面
- Mujoco:使用对应框架和接口
3.环境
- 组成:机械臂、门、门把手、门框、墙;其中前三者的物理特性在一定范围内随机(3种执行器、6种机械臂、推和拉2种动作方向)
- 门把手:pull:无需旋转、level:各向异性需旋转开锁、round:各向同性需旋转开锁,难度依次上升。
- 机械臂:默认使用Berkeley BLUE机械臂。可从6自由度的浮动钩到全10自由度的抓手手臂和移动平台变化。
- 最简单环境配置:浮动钩开启pull门把手
- 最困难环境配置:BLUE用抓手打开round门把手
- 默认奖赏函数:

- 评估指标:100次的平均开门成功率和平均开门时间
4.基线策略
- 异策略:SAC
- 同策略:PPO
- 整体框架:
- 视觉部分:通过俯视的手外摄像头和在手的正视摄像头来学习出把手的位置
- 观测信息:方向向量(把手位置与末端位置的差)、机械臂关节角度、关节速度
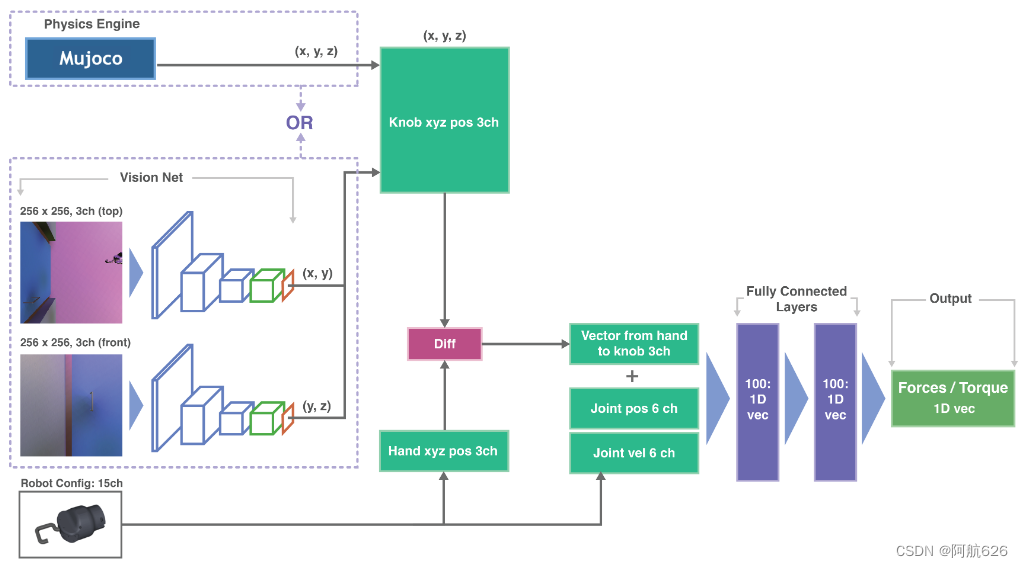
- PPO缓冲区策略:8线程,每线程8轮,每轮512时间步(10.2秒),每次更新使用全部的64轮
- SAC缓冲区策略:10轮,1000000时间步
- PPO预训练策略:
- 使用环境中的把手位置真值预训练视觉网络
- 使用把手位置真值训练策略网络
- 使用把手位置真值和高斯噪声模拟视觉网络输出来训练策略网络
5.结论
- 可以0样本泛化到现实世界,但耗时和成功率都变差
- PPO比SAC效果更好,SAC训练时候的探索性更强
- 门把手位置估计对PPO影响很大