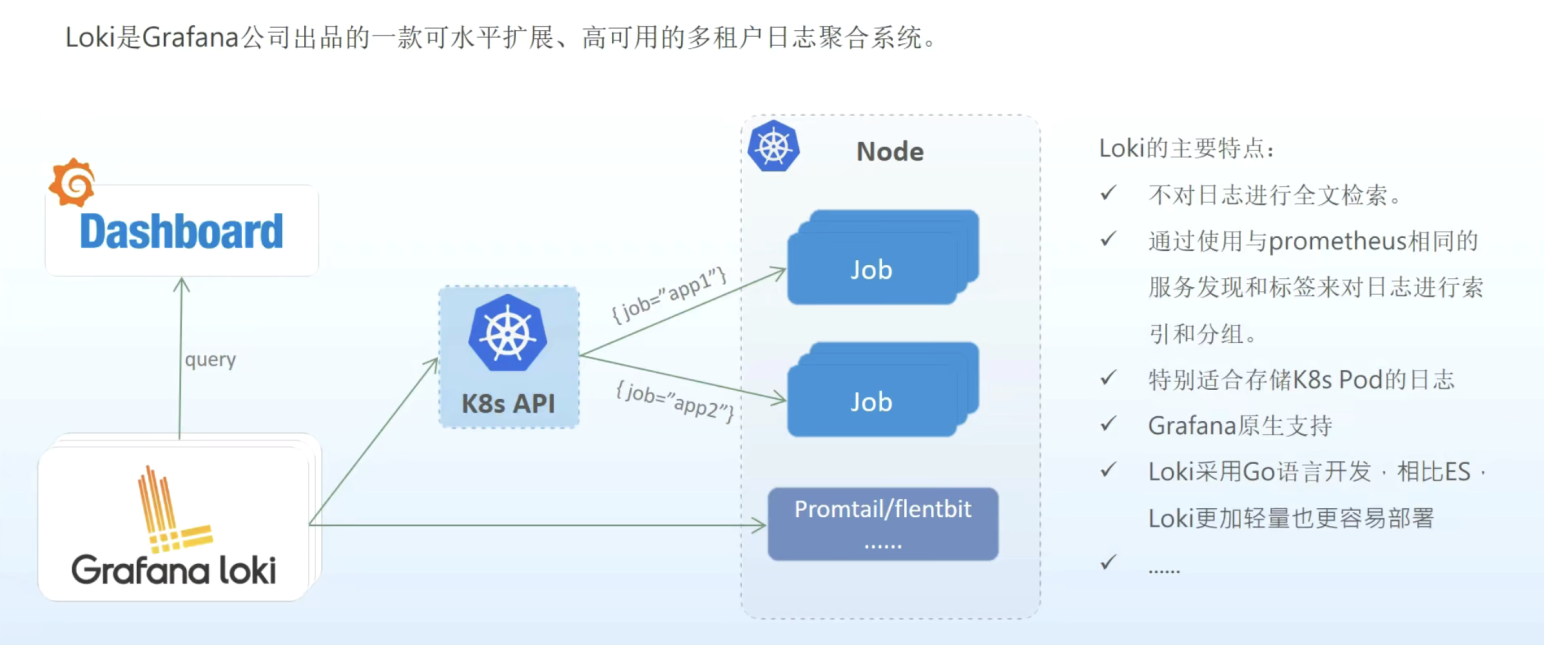
Loki是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。项目受 Prometheus 启发,官方的介绍就是:Like Prometheus, but for logs.,类似于 Prometheus 的日志系统。
1. 介绍
与其他日志聚合系统相比,Loki具有下面的一些特性:
- 不对日志进行全文索引。Loki中存储的是压缩后的非结构化日志,并且只对元数据建立索引,因此Loki 具有操作简单、低成本的优势。
- 使用与 Prometheus 相同的标签。Loki通过标签对日志进行索引和分组,这使得日志的扩展和操作效率更高。
- 特别适合储存 Kubernetes Pod 日志。诸如 Pod 标签之类的元数据会被自动删除和编入索引。
- Grafana 原生支持。
Loki 日志系统由以下3个部分组成:
- loki是主服务器,负责存储日志和处理查询。
- promtail是专为loki定制的代理,负责收集日志并将其发送给 loki 。
- Grafana用于 UI展示。
2. 工作原理
loki是直接面向k8s的,通过在每个节点上运行一个日志收集代理来收集日志,并于k8s的API进行交互,以找出日志的正确元数据,并将他们发送给loki,最后从grafana中可以查询日志数据。
3. 架构
Loki 包含Distributor(客户端)、Ingester、Querier和可选的Query frontend五个组件。每个组件都会起一个用于处理内部请求的 gRPC 服务器和一个用于处理外部 API 请求的 HTTP/1服务器。
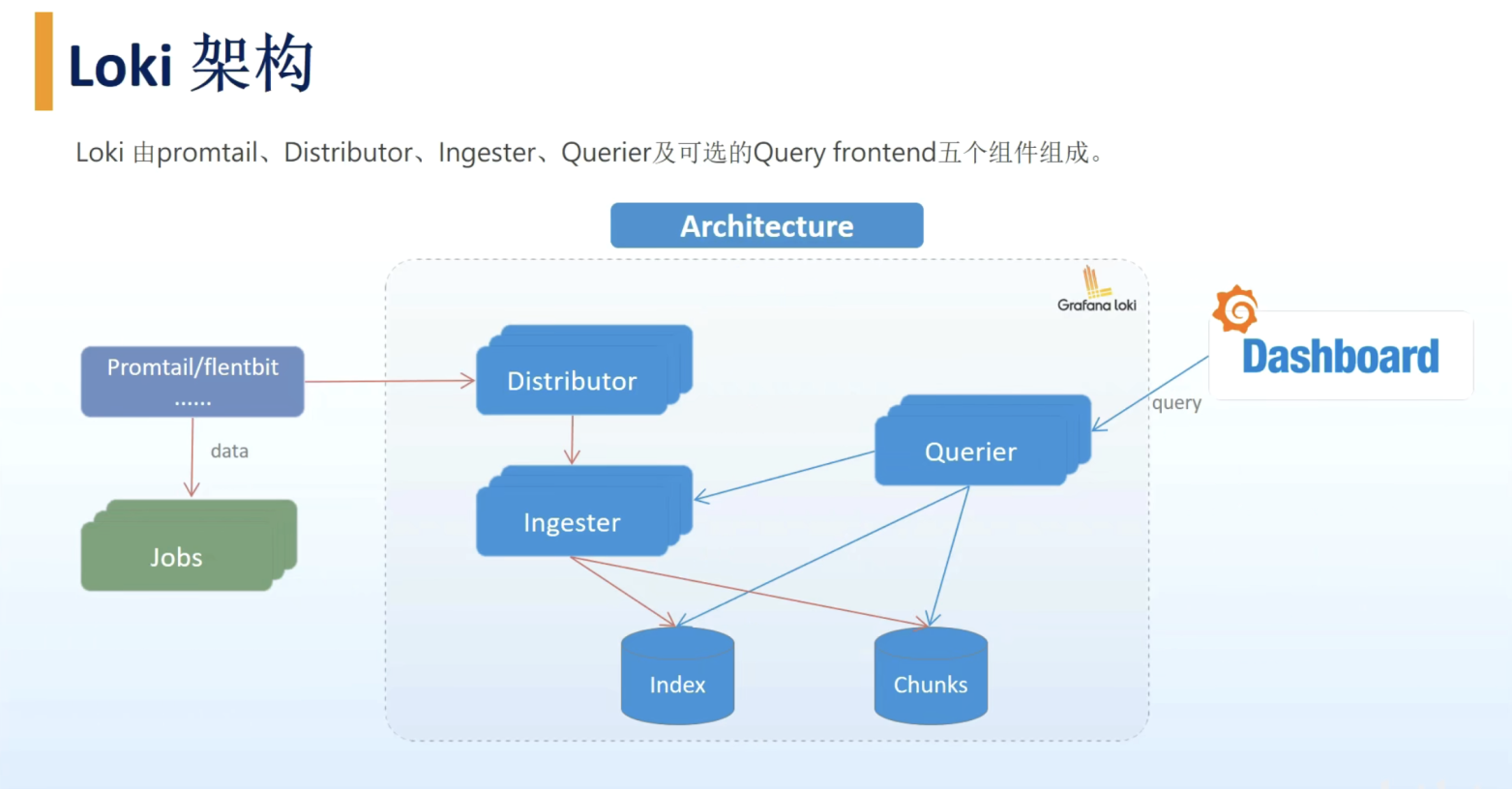
(1)Distributor
Distributor 是客户端连接的组件,用于收集日志。
在 promtail 收集并将日志发送给Loki 之后, Distributor 就是第一个接收它们的组件,每秒可以接收数百万次写入。Distributor会对接收到的日志流进行正确性校验,并将验证后的chunk日志块分批并行发送到Ingester。
Loki使用一致性哈希来保证数据流和Ingester的一致性,他们共同在一个哈希环上,哈希环的信息可以存放到etcd、Consul或者内存中。当使用Consul作为哈希环的实现时,所有Ingester通过一组token注册到环中,每个token是一个随机的32-bit无符号整数,同时Ingester会上报其状态到哈希环中。由于所有的Distributor使用相同的hash环,写请求可以发送至任意节点。为了保证结果的一致性,Distributor会等待收到至少一半加一个Ingester的回复后才响应客户端。
(2)Ingester
Ingester 接收来自Distributor的日志流,并将日志压缩后存放到所连接的存储后端。
Ingester接受日志流并 每个Ingester 的生命周期有PENDING, JOINING, ACTIVE, LEAVING 和 UNHEALTHY 五种状态。处于JOINING和ACTIVE状态的Ingester可以接受写请求,处于ACTIVE和LEAVING状态时可以接受读请求。
Ingester 将收到的日志流在内存中打包成 chunks ,并定期同步到存储后端。由于存储的数据类型不同,Loki 的数据块和索引可以使用不同的存储。
当满足以下条件时,chunks 会被标记为只读:
- 当前 chunk 达到配置的最大容量
- 当前 chunk 长时间没有更新
- 发生了定期同步
当旧的 chunk 经过了压缩并被打上了只读标志后,新的可写的 chunk 就会生成。
(3) Querier
Querier 用来查询日志,可以直接从 Ingester 和后端存储中查询数据。当客户端给定时间区间和标签选择器之后,Querier 就会查找索引来确定所有匹配 chunk ,然后对选中的日志进行 grep并返回查询结果。查询时,Querier先访问所有Ingester用于获取其内存数据,只有当内存中没有符合条件的数据时,才会向存储后端发起同样的查询请求。
需要注意的是,对于每个查询,单个 Querier 会 grep 所有相关的日志。目前 Cortex 中已经实现了并行查询,该功能可以扩展到 Loki,通过分布式的 grep 加速查询。此外,由于副本因子的存在,Querier可能会接收到重复的数据,所以其内置了去重的功能,对拥有同样时间戳、标签组和消息内容的日志进行去重处理。
(4) Query Frontend
Query frontend 是可选组件,其提供了Querier的API并可用于读加速。当系统中有该组件时,所有的读请求都会经由Query frontend而非Querier处理。
Query frontend是无状态的,生产环境中推荐 2 副本来达到调度的均衡。Query frontend会对请求做一些调整,并将请求放入一个内部的队列中。在该场景中,Querier作为workers 不断从队列中获取任务、执行任务,并将结果返回给Query frontend用于聚合。
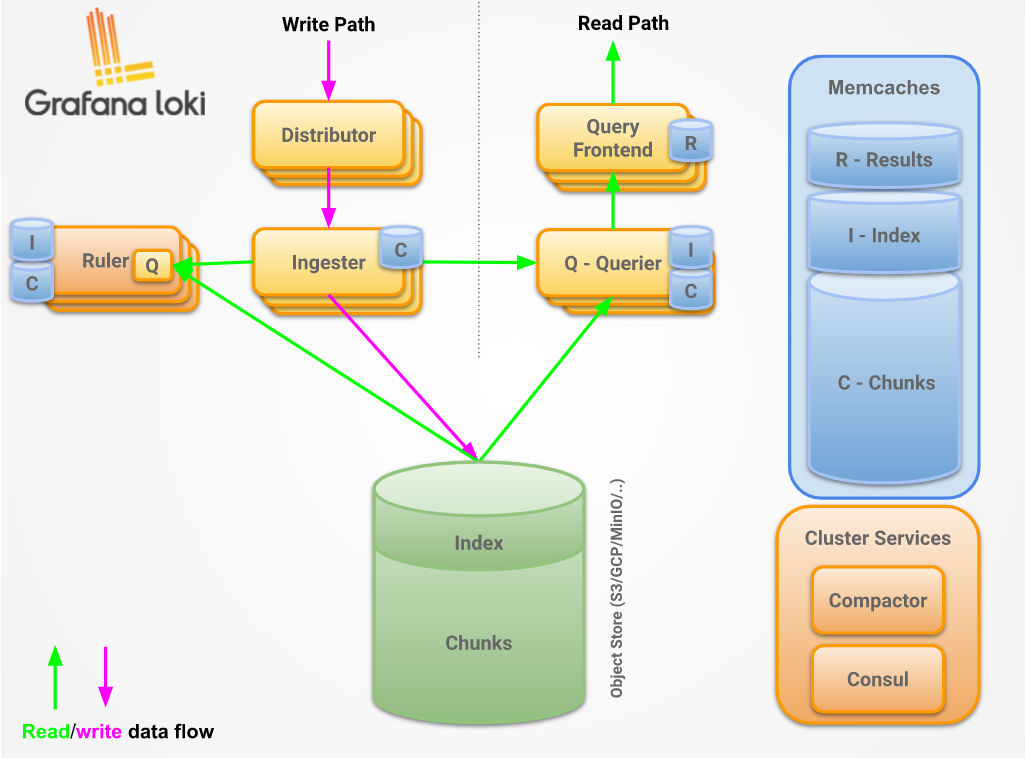
4. 读写流程
(1)Read Path
读操作的流程如下:

- Querier 收到 HTTP 请求
- Querier 将请求发送至Ingester 用以获取内存数据
- Ingester 收到请求后返回符合条件的数据
- 如果没有Ingester 返回数据,Querier 从后端存储加载数据并执行查询
- Querier 遍历所有数据并进行去重处理,通过HTTP连接返回最终结果
(2)Write Path
日志数据的写主要依托的是Distributor和Ingester两个组件,整体流程如下:
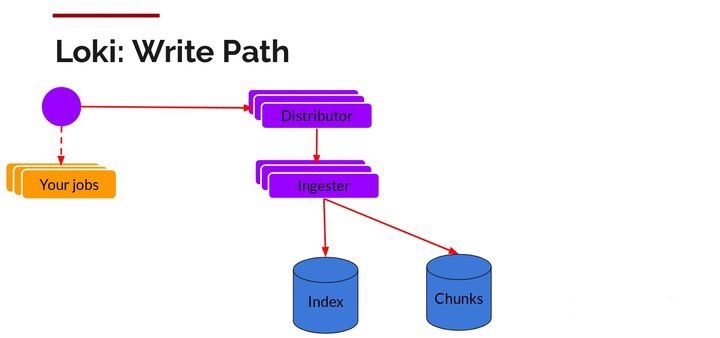
- Distributor 收到 HTTP 请求,用于存储流数据
- 通过 hash 环对数据流进行 hash
- Distributor将数据流发送到对应的Ingester及其副本上
- Ingester 新建 Chunk 或将数据追加到已有Chunk 上
- Distributor通过 HTTP连接发送响应信息