文章目录
- 概要
- 一、缓存预热
- 二、缓存污染
- 2.1、先更新数据库再更新缓存
- 2.2、先更新缓存再更新数据库
- 2.3、先删除缓存再更新数据库,读时再更新
- 2.4、先更新数据库再删除缓存,读时再更新
- 2.5、缓存污染总结
- 2.6、删除缓存失败了怎么办?
- 2.7、延迟双删
- 2.8、旁路缓存(Cache-Aside)
- 三、缓存淘汰
- 四、缓存失效
- 4.1、缓存雪崩
- 4.2、缓存穿透
- 4.3、缓存击穿
- 五、热点缓存
- 六、多级缓存
- 七、小结
概要
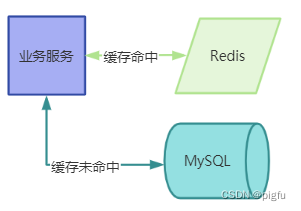
对于服务端同学来说,缓存是一个避不开的话题,相信大多数同学接触缓存是在操作系统的课上。缓存就是将低效存储介质(比如磁盘)的内容,临时在高效存储介质(比如内存)中保存一份,以提高读写效率。当然了,这个高效低效是相对的,比如CPU中还有L1/2/3级别缓存,可以说其是计算机内存的缓存。
在服务端,使用缓存主要目的:
1)降低服务器(通常是数据库)压力,进而提高接口响应速度;
2)降低硬件成本,使用缓存可以替代原本需要多台数据库服务器才能承载的请求量。
但在我们引入缓存的同时提高了软件的复杂性,比如要关注缓存失效、污染、淘汰等问题,因此在维护软件服务端过程中引入缓存也是要慎重的,不能当做银弹,如果可以通过提高硬件(CPU、I/O)性能解决问题的时候,那升级硬件往往是更合适的解决方案。
本文主要聊基于数据库的缓存,当然,也可以举一反三到其它场景。
缓存介质以Redis为例,数据库以MySQL为例
一、缓存预热
缓存预热是指服务上线时,提前将相关的业务数据进行构造后写到缓存介质中,避免由于请求量太大而使刚上线的服务压力太大,甚至打垮。
一般来说我们用户第一次读时加载缓存就足够了,那什么情况下使用预加载合适呢:
- 缓存内容构造复杂,数据量大;
- 热点数据。
二、缓存污染
在聊缓存污染之前,先说下缓存更新的方法:
- 缓存预热+写数据库是更新
- 读时缓存不存在更新,依赖写时删除
- 定时任务,周期性更新缓存,一般适合跑数据的任务,或者列表型的数据,而且不要求绝对实时性。
缓存污染是指缓存与数据库数据不一致。这种不一致常常由开发者更新缓存不规范造成的,更新缓存分为四种:
- 先更新数据库再更新缓存;
- 先更新缓存再更新数据库;
- 先删除缓存再更新数据库,读时再更新;
- 先更新数据库再删除缓存,读时再更新。
注意我们是在更新数据库,更新/删除缓存一定成功的条件下讨论
2.1、先更新数据库再更新缓存
我们考虑先后来了a,b两个写请求,要对数据X进行更新。
- T1:a更新数据库中的X=A;
- T2:b更新数据库中的X=B;
- T3:b更新缓存中的X=B;
- T4:a更新缓存中的X=A;
经过以上的一番操作数据库和缓存出现了不一致,此时缓存中X=A,数据库中X=B。
2.2、先更新缓存再更新数据库
我们考虑先后来了a,b两个写请求,要对数据X进行更新。
- T1:a更新缓存中的X=A;
- T2:b更新缓存中的X=B;
- T3:b更新数据库中的X=B;
- T4:a更新数据库中的X=A;
经过以上的一番操作数据库和缓存出现了不一致,此时缓存中X=B,数据库中X=A。
2.3、先删除缓存再更新数据库,读时再更新
我们考虑当前数据库和缓存中的X=B,先后来了a写请求要对数据X进行更新,b读请求读取X的值。
- T1:a删除缓存中的X=A;
- T2:b读取X,缓存不存在;
- T3:b从数据库读取X=B,并将X=B写入缓存;
- T4:a更新数据库中的X=A;
经过以上的一番操作数据库和缓存出现了不一致,此时缓存中X=B,数据库中X=A。
2.4、先更新数据库再删除缓存,读时再更新
我们考虑当前数据库中的X=A,缓存中X不存在,先后来了a读请求读取X的值,b写请求要对数据X进行更新。
- T1:a读取X,缓存不存在,从数据库读取X=A;
- T2:b更新数据库中的X=B;
- T3:b删除缓存中的X;
- T4:a将X=A写入缓存;
经过以上的一番操作数据库和缓存出现了不一致,此时缓存中X=A,数据库中X=B。
2.5、缓存污染总结
通过对以上四种方案的分析,都有可能导致缓存不一致。这还没考虑数据库和缓存写失败,那怎么办呢?
那么就要结合实际进行分析了:
- 通常来说互联网项目中读的比例远高于写的;
- 通常来说读数据库比写数据库效率高,因为写数据库四会加锁的而读一般不需要;
- 通常来说缓存的写效率远高于数据库。
基于以上三点共识:
- 对于[先更新数据库再更新缓存]来说,先后a,b请求来的时候,通常来说a,b请求操作步骤耗时一样(更新数据库和更新缓存),那么网络稍微一抖动,可能就会出现2.1讨论的情况;
- 对于[先更新缓存再更新数据库]来说,同上,可能就会出现2.2讨论的情况;
- 对于[先删除缓存再更新数据库,读时再更新]来说,先后a,b请求来的时候,a删缓存效率很高,此时b就发现缓存不存在,但a写数据库很慢,b读数据库是快的,所以很容易出现b读完了数据库a还没更新好数据库的情况,也容易出现2.3讨论的情况;
- 对于[先更新数据库再删除缓存,读时再更新]来说,先后a,b请求来的时候,首先a读取X要X不存在,由于【互联网项目中读的比例远高于写的】,所以它的概率很低。就算满足了,然后就是a从数据库读取X值后,其写入缓存的速度要慢于b更新数据库的速度,概率更低了,因为【缓存的写效率远高于数据库】
综上 先更新数据库再删除缓存,读时再更新 方案是最优的,真实项目中往往也采用这种方案。
2.6、删除缓存失败了怎么办?
我们通过2.1-2.5小节讨论都没考虑【更新数据库,更新/删除缓存】的情况,针对最后胜出的 【先更新数据库再删除缓存,读时再更新】讨论下。
更新数据库失败的话,直接报错即可。
删除缓存失败的话:
- 针对缓存,我们往往是会设置过期时间的,如果对数据库与缓存不一致容忍性高的话可以执行安全失败策略,即直接返回成功即可,等待缓存自动过期或被其他请求删除;
- 重试策略。这里列出三种:1)程序内重试若干次(一般3次为宜)。2)解耦,删除失败后放入消息队列,进行异步删除。3)解耦,异步更新缓存,即采用 databus 或者阿里的 canal 监听MySQL binlog 进行更新。
2.7、延迟双删
针对【先更新数据库再删除缓存,读时再更新】方案,为了避免2.4小节讨论的异常情况发生,可以考虑在删除缓存成功后,等待若干时间(一般1s),再执行一次删除缓存操作,这样可以极大的降低异常概率发生,可以当做不可能事件了。当然,这个等待若干时间可以程序内起一个定时任务,也可以使用消息队列延迟队列。
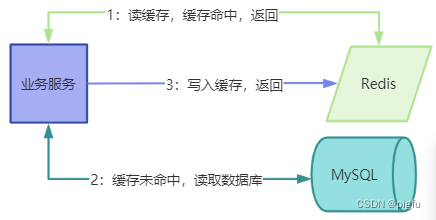
2.8、旁路缓存(Cache-Aside)
旁路缓存就是【先更新数据库再删除缓存,读时再更新】方案。
1:读操作:先读缓存,若命中直接返回,否则读数据库后写入缓存再返回
2:写操作:写数据库,再删除对应的缓存
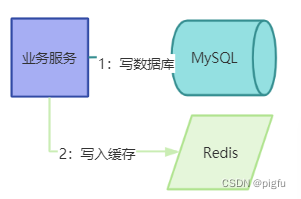
除了旁路缓存策略,还有Read-Through/Write-Through或者Write-Behind(Write-Back),见文章
三、缓存淘汰
缓存的使用主要是为了降低数据库压力,提高响应速度,同时缓存的成本也是高昂的。所以随着缓存机制的运行,一些缓存内容命中率很低或不会再命中,就可以淘汰了。常见的淘汰指标有:
1)基于空间:设置缓存空间大小,到达阈值开始淘汰;
2)基于容量:设置缓存存储记录数,到达阈值开始淘汰;
3)基于时间,到达阈值开始淘汰
TTL(Time To Live,即存活期)缓存数据从创建到过期的时间。
TTI(Time To Idle,即空闲期)缓存数据多久没被访问的时间。
淘汰算法细化有很多:
-
FIFO:先进先出。在这种淘汰算法中,达到阈值(空间大小or记录数),则先进入缓存的会先被淘汰。这种可谓是最简单的了,但是会导致我们命中率很低。试想一下我们如果有个访问频率很高的数据是所有数据第一个访问的,而那些不是很高的是后面再访问的,那这样就会把我们的首个数据但是他的访问频率很高给挤出。
-
LRU:最近最少使用算法。其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。在这种算法中避免了上面的问题,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可。但是这个依然有个问题,如果有个数据在 1 个小时的前 59 分钟访问了 1 万次(可见这是个热点数据),再后一分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
-
LFU:最近最少频率使用。在这种算法中又对上面进行了优化,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。这样就避免了 LRU 不能处理时间段的问题。
-
TTL:设置过期时间,即给缓存key设置过期时间,到期就被淘汰。实现手段有:1)读的时间判断下是否过期,过期就删除缓存记录再返回空、2)定时任务,检查key是否过期,过期就删除(每个key都一个定时任务[时间轮算法]?还是一个定时任务删一批缓存记录)。Redis就是二者结合使用的。
-
TTI: 设置空闲期,即给缓存key设置空闲期,每被访问一次就延期。


![[FPGA IP系列] 2分钟了解FPGA中的BRAM](https://img-blog.csdnimg.cn/b4c99a625a2c4f84a061586a235d883d.png)