一、中心线提取
1、离散文字平面:
离散文字平面,构建一个二维矩阵数组(实际操作时用的一维数组)
1.1最小边界盒子:
可以计算文字平面的最小边界盒子,然后按步距在平面上采点,优点是点距比较均匀,缺点是速度比较慢。
1.2UV曲线:
可以利用面的UV曲线的交点,构建二维矩阵,这样可以拓展到曲面文字,此处需要注意的是,使用UFUN函数提取UV线,在边界的极限位置会有偏差,导致矩阵数值不连续。具体见博客:
http://t.csdn.cn/wLhc0![]() http://t.csdn.cn/wLhc0使用NXopen的话,速度会很慢,此处建议使用PK函数,我是按照面的U方向取500个点,V方向按照U方向点距,自适应,大概一个面用时0.2~0.5s左右。
http://t.csdn.cn/wLhc0使用NXopen的话,速度会很慢,此处建议使用PK函数,我是按照面的U方向取500个点,V方向按照U方向点距,自适应,大概一个面用时0.2~0.5s左右。
2、提取中心线点位:
使用提取骨干线算法,也有交细化算法的,此处建议使用“Zhang-Suen”提取(K3M算法在验证过程中出现双侧点位的情况,可以自行尝试)。可以参考如下博客
http://t.csdn.cn/AfwmT![]() http://t.csdn.cn/AfwmT
http://t.csdn.cn/AfwmT
3、获取交点:
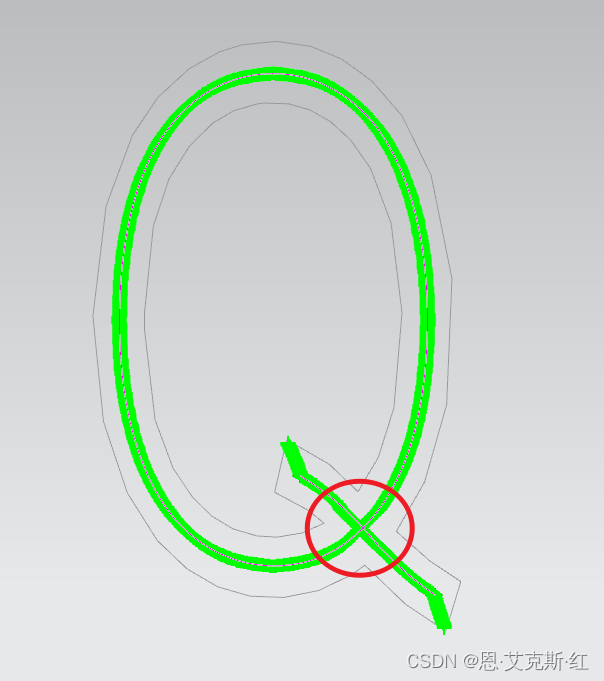
细化后的点位存在三岔口、四岔口,其中四岔口存在异形,即其中一个封闭,比如Q:
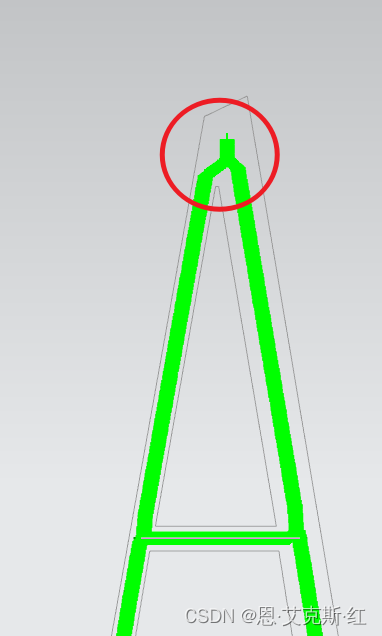
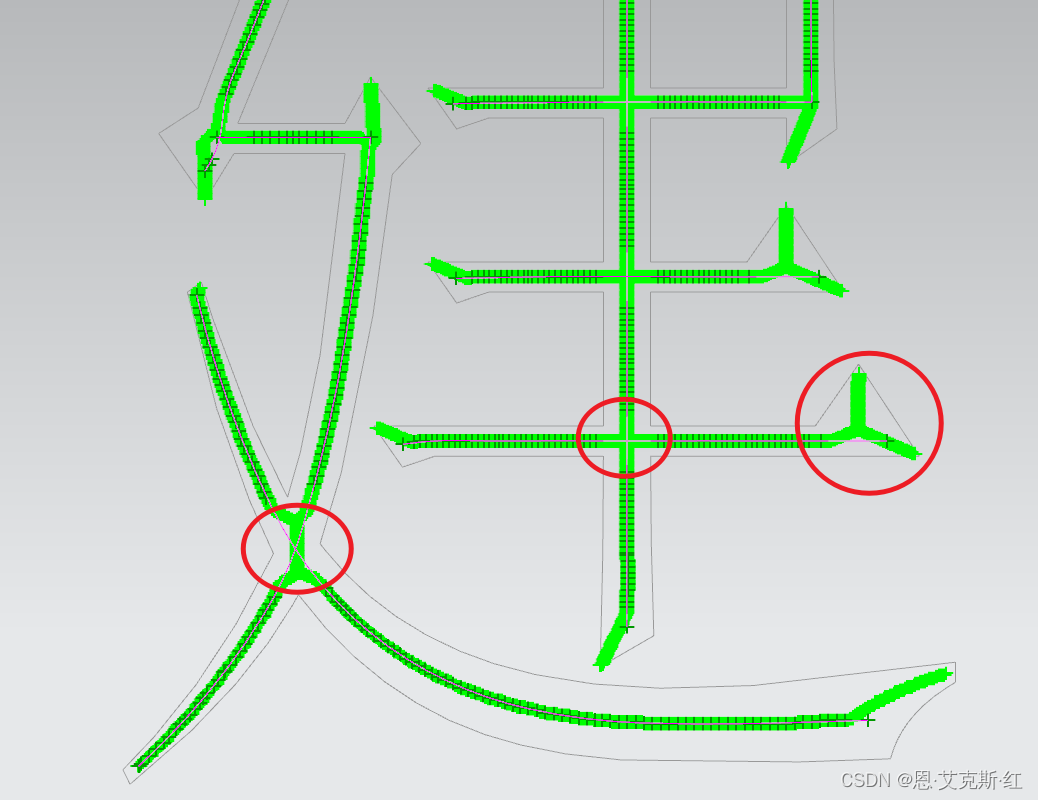
4、分割笔画:
以交点为起始终止点,来划分每条笔画,没有交点的地方使用终点替代;
其中对于仿宋的小写的g,存在一个封闭曲线与两处笔画相交,注意此处可以打断一根根线。
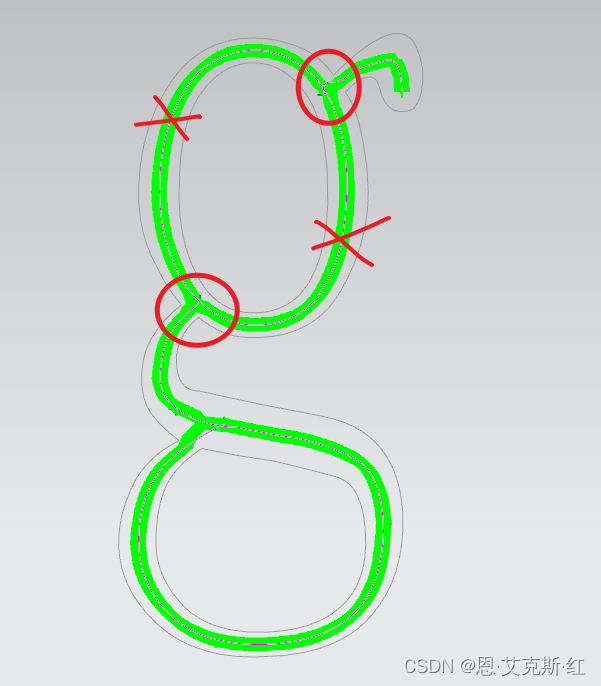
5、处理交点、优化交点:
此处提供两个参考方法:
a、测量交点到边界的距离,以最近的边界走势,摆正点位。
b、以交点为起点,获取一定范围内的点,获取波峰,此处需要一些经验参数,来判断优化走势。
6、去除端部分支:
参考方法:
a、如果存在两个端部分支,长度近似,则可以去除一条角度最小的;
b、或者从端部分中缩短交点半径,没有剩余的线肯定是端部分支;
c、利用交点和端部点位到边界距离比值,大于一定范围的肯定是角线,但存在一些需要保留的角线。
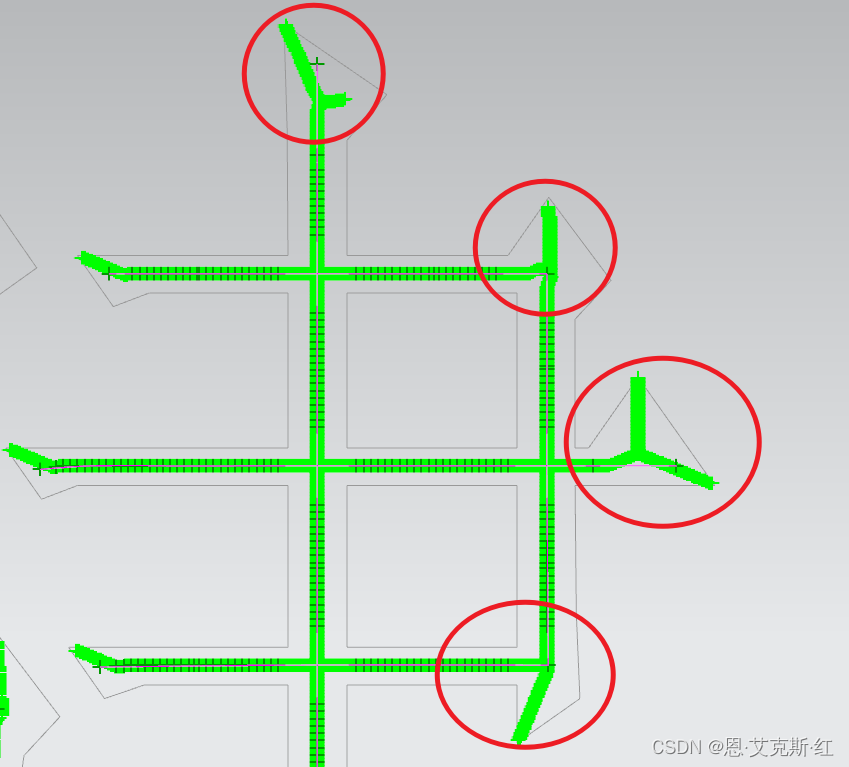
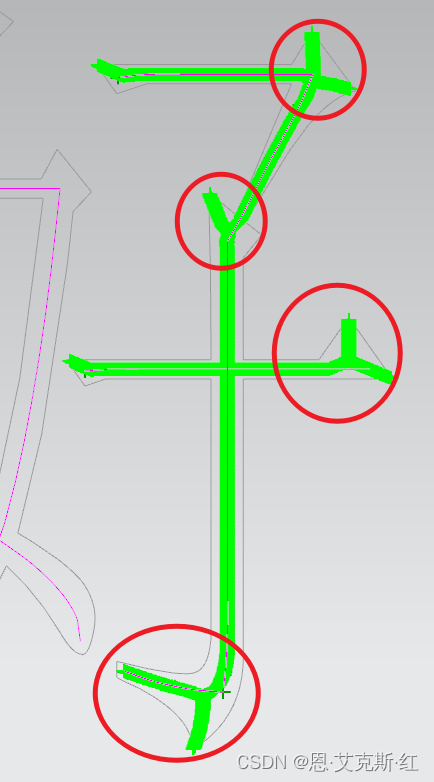
7、合并相连且角度小于一定角度的线:
比如字母A、W、M、V,数字4,此处建议使用55度,作为分界线。除此还要判断延长交点是否在面外,如果超过曲面,需要用第三个交线裁断。
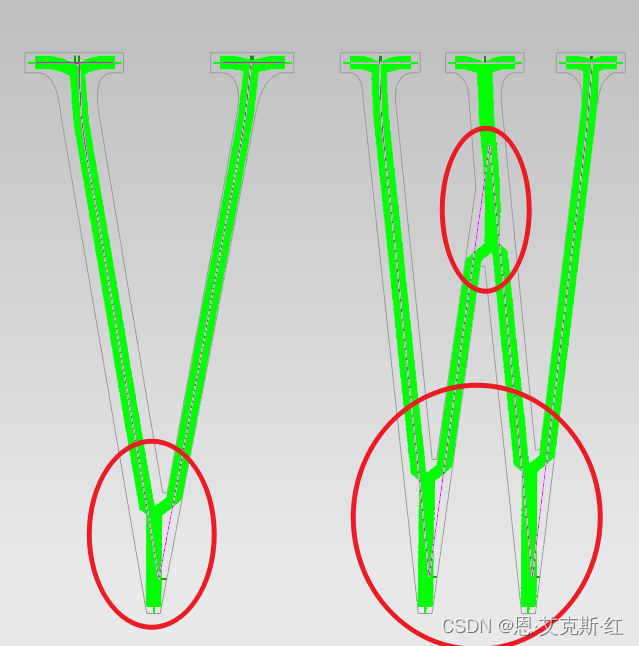
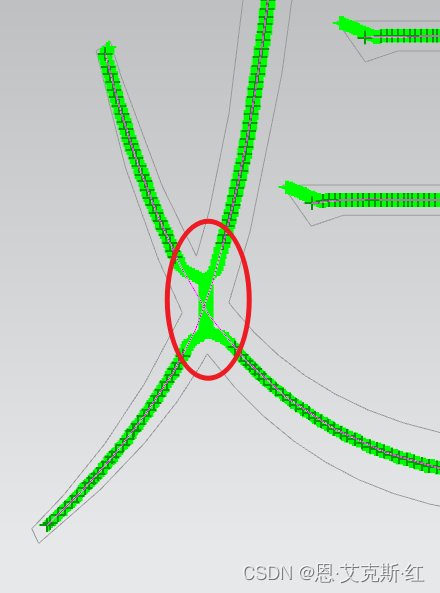
8、合并短连接线左右两侧的笔画:
比如一些交叉笔画,注意合并后,应及时去除中间连接的笔画,放置后面误连接其他笔画
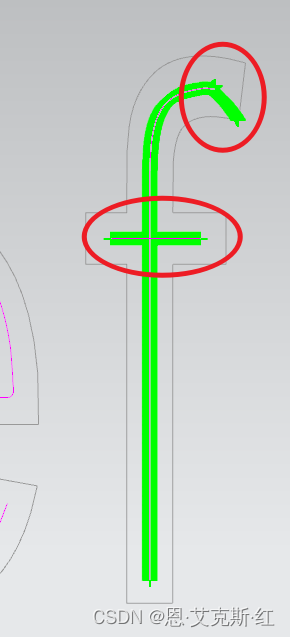
9、特殊笔画处理:
比如黑体的小f:
黑体的小k:
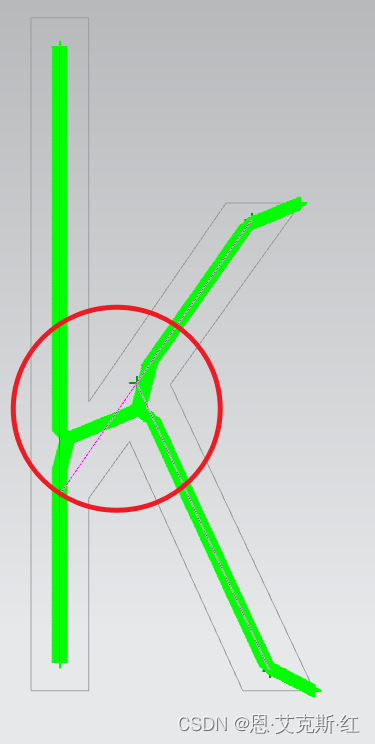
仿宋的米、木、木字旁的文字等:
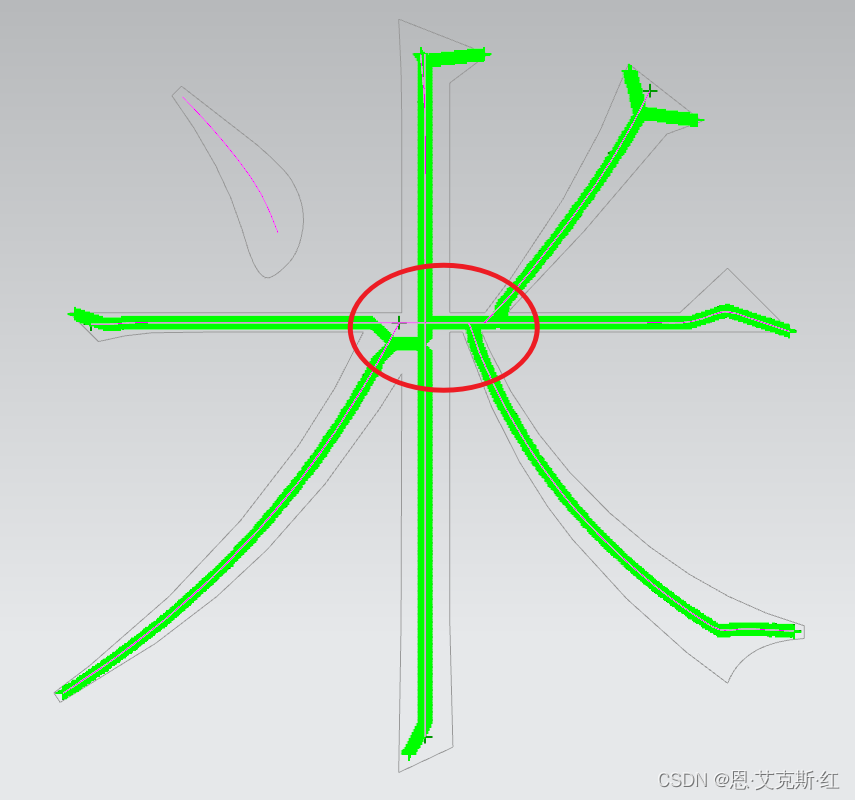
以上处理顺序,尽可能不要打乱,优先处理汉字和字母文字经常出现的交叉情况,对于特殊情况,在最后统一处理,由于米字存在多线交叉,给出参考算法描述:
1、优先处理两根长线+一根短连接线,求交两根长线,并将与连接线角度最小的,设为端线,不在处理,继续迭代。
2、处理一根长线+两根短连接线,获取与长线角度最大的连接线,并将剩余的两根线的起点设为连接线的端部序号,继续迭代。
3、最后在迭代中,加一个判断,即出现两根线相连的情况,直接合并,完成迭代。
如下提取效果:

刻字中心线提取-CSDN直播刻字中心线提取https://live.csdn.net/v/319539



![[Leetcode] [Tutorial] 多维动态规划(未完待续)](https://img-blog.csdnimg.cn/4e9a390120534b0286f50e517ad0aad8.png#pic_center)





![[vscode]vscode运行cmake时候exe不执行而且前面多一些字符](https://img-blog.csdnimg.cn/img_convert/88f4d7ac42ebb154c1698e9de4e76106.png)