文章目录
- 1. CDH 简介
- 1.1 CDH版本
- 2. CDH 集群的优势是什么?
- 3. CDH 集群的部署方式有哪些?
- 4. CDH 集群中如何进行故障排除和监控?
- 5. 你有使用 CDH 部署集群的经验吗?
- 6. CDH 集群如何实现高可用性?
- 7. 在 CDH 集群中,如何进行版本升级?
- 8. CDH 集群中的数据安全如何保障?
- 9. 什么是Kerberos
- 9.1 Kerberos概念
- 9.2 Kerberos 在 CDH 中的主要作用
- 10. Sentry概述
- 10.1 Sentry是什么
- 10.2 Sentry 的主要作用
- 11. SecondaryNameNode不能恢复 NameNode的全部数据,那如何保证 NameNode数据存储安全
- 12. 在 NameNodeHA中,会出现脑裂问题吗?怎么解决脑裂
- 13. 在CDH6.3版本中将 Flink 编译为 Cloudera CDH 集群可以识别的 Parcel 格式,如何实现步骤?
- 步骤 1:下载所需文件
- 步骤 2:安装 Maven
- 步骤 3:修改 Flink 源码
- 步骤 4:编译 Flink
- 步骤 5:创建 Parcel 目录结构
- 步骤 6:拷贝文件
- 步骤 7:生成 Parcel 文件
- 步骤 8:安装 Parcel 到 Cloudera Manager
- 步骤 9:拷贝 CSD 文件
- 步骤 10:重启服务
- 步骤 11:添加 Flink 服务配置和集群规划
- 步骤 12:重启服务
- 14. 阿里云官方对CM的架构描述
- 14.1 CM术语
- 14.2 Cloudera Manager 架构
1. CDH 简介
Cloudera Manager是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具,使得安装集群从几天的时间缩短在几个小时内,运维人员从数十人降低到几人以内,极大的提高集群管理的效率。
CDH 是 Cloudera 提供的一套基于 Hadoop 生态的大数据解决方案。它包括 Hadoop 生态的核心组件,如 HDFS、YARN、Hive、HBase 等,并提供了集成的管理、监控、安全性等功能,使大数据平台的构建和管理更加便捷。除此之外,它还包含了 Cloudera 自家开发的一些工具和服务,如 Cloudera Manager、Impala 等。
以下图片参考来自尚硅谷CDH6.3
1.1 CDH版本
Cloudera Distribution for Hadoop(CDH)是由 Cloudera 公司开发和维护的 Hadoop 生态系统的发行版。CDH 随着时间的推移经历了一些重要的历史节点,包括免费和收费模式的变化。以下是 CDH 几个发行版的历史以及重要时间节点的概述:
-
CDH 3(2010年初)
- CDH 3 是 Cloudera 最早的 Hadoop 发行版之一,最初推出时是免费提供的。这个版本中包含了 Hadoop 核心组件以及一些基本的工具和库。
-
CDH 4(2012年)
- CDH 4 在 Hadoop 2.0 版本发布之后推出,引入了 Hadoop 2.x 的特性,如 YARN 资源管理器。在此之后,CDH 4 也是免费提供的版本。
-
CDH 5(2014年)
- CDH 5 是一个重要的版本,引入了许多新的功能和改进,包括支持 Apache Spark、Apache Impala(前身为 Cloudera Impala)、Apache HBase 的集成等。CDH 5 的核心版本依然是免费的,但 Cloudera 开始推出了付费的企业版,提供了更多的高级功能和支持。
-
CDH 6(2018年)
- CDH 6 继续在之前版本的基础上进行了改进和增强。然而,从 CDH 6 开始,Cloudera 对核心 CDH 版本的免费支持发生了变化。CDH 6 的核心版本开始向企业用户收费,而社区版本仍然是免费的。此外,Cloudera 开始提供一种名为 Cloudera Runtime 的新版本,它将一些高级功能和工具捆绑在一起,形成一个更完整的数据平台,但也需要付费。
-
CDS(Cloudera Data Platform)(2019年)
- Cloudera Data Platform(CDS)是 Cloudera 在 CDH 之上构建的更全面的数据分析和处理平台。它将 CDH 的元素与其他一些重要组件(如 Cloudera Manager)结合在一起,以提供更完整的解决方案。CDS 同样提供免费的社区版本和付费的企业版本。
-
6.3.3 (2021年)
cloudera manager 6.3.3和 CDH 6.3.3之后所有产品不再提供社区版。-
社区版不再更新,Cloudera(Cloudera 和Hortonworks 合并后)所有产品不再提供社区版,用户无法获取新的功能。
-
社区版不再免费,2021年1月31日开始,所有Cloudera软件都需要有效的订阅,且订阅费昂贵(50个节点,一年订阅费50万美元)。
-
2. CDH 集群的优势是什么?
CDH(Cloudera Distribution for Hadoop)作为大数据一站式平台管理解决方案,带来了许多改观,解决了自建Hadoop集群中的许多问题。以下是CDH的优势总结:
-
组件兼容性:Hadoop生态中存在许多组件,版本兼容性、编译问题等经常让人头疼。CDH每个版本都经过严格测试,保证了各组件之间的兼容性,用户只需统一CDH版本,就能避免兼容性问题。
-
稳定性与安全性:自建Hadoop集群中,不同版本可能存在不同的漏洞,且升级更新风险较大。CDH基于稳定版本Apache Hadoop,每季度会发布update和每年发布release,应用了最新的Bug修复和特性的patch,提供了更稳定和安全的环境。
-
安装配置管理:CDH提供了统一的网页界面进行安装和配置,附带详细的文档和配置注解,甚至推荐最优配置。相比于自行编写大量配置文件并分发到各节点的复杂过程,CDH极大地简化了集群部署的繁琐步骤。
-
资源监控和运维:CDH内置了管理、监控、诊断、配置修改等工具,使集群的监控和运维变得更加简单高效。不再需要安装第三方软件,如ganglia和nagios,以进行监控和运维。
-
企业服务支持:在自建集群中,问题解决需要依赖社区的帮助,响应速度不稳定。而CDH提供了企业付费服务,可以获得一对一的支持,提供针对性的解决方案,成为用户运维工作的可靠后盾。
综上所述,CDH通过解决组件兼容性、稳定性、安装配置、资源监控和运维等方面的问题,为用户提供了更加便捷、稳定和安全的大数据解决方案。同时,CDH的企业服务支持也为用户的业务提供了可靠的保障。
3. CDH 集群的部署方式有哪些?
CDH 集群可以通过手动部署和使用 Cloudera Manager 部署两种方式。手动部署需要管理员逐个安装和配置各个组件,而 Cloudera Manager 则提供了集中式的集群部署、配置、监控和维护。
4. CDH 集群中如何进行故障排除和监控?
CDH 集群使用 Cloudera Manager 提供的集中式管理和监控功能来进行故障排除和监控。管理员可以通过 Cloudera Manager 的用户界面来查看集群的健康状况、性能指标和日志信息,从而及时发现并解决问题。
5. 你有使用 CDH 部署集群的经验吗?
如果有,可以分享一下你在使用 CDH 部署和管理集群时的经验,如如何添加节点、配置服务、监控集群状态等。如果没有直接使用经验,可以提及自己对 CDH 的了解和学习计划。
6. CDH 集群如何实现高可用性?
CDH 集群可以通过多种方式实现高可用性,比如使用 HDFS 的 NameNode HA 机制,使用 YARN 的 ResourceManager HA,以及使用 Cloudera Manager 高可用等。这些机制可以确保在组件出现故障时,集群仍然可以保持可用状态。
7. 在 CDH 集群中,如何进行版本升级?
Cloudera 提供了升级工具来帮助集群进行版本升级。在升级过程中,可以使用 Cloudera Manager 来检查和准备升级,然后按照文档指引逐步完成升级操作。升级前需要备份数据和配置,以及进行必要的测试。
参考文献:运维实战CDH5.16.2升级至CDH6.3.2 - 知乎
8. CDH 集群中的数据安全如何保障?
CDH 提供了多种数据安全功能,包括 Kerberos 认证、角色授权、数据加密等。管理员可以通过配置安全选项来保护
9. 什么是Kerberos
Kerberos是一种计算机网络授权协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。这个词又指麻省理工学院为这个协议开发的一套计算机软件。软件设计上采用客户端/服务器结构,并且能够进行相互认证,即客户端和服务器端均可对对方进行身份认证。可以用于防止窃听、防止重放攻击、保护数据完整性等场合,是一种应用对称密钥体制进行密钥管理的系统。
9.1 Kerberos概念
Kerberos中有以下一些概念需要了解:
(1)KDC:密钥分发中心,负责管理发放票据,记录授权。
(2)Realm:Kerberos管理领域的标识。
(3)principal:当每添加一个用户或服务的时候都需要向kdc添加一条principal,principl的形式为:主名称/实例名@领域名。
(4)主名称:主名称可以是用户名或服务名,表示是用于提供各种网络服务(如hdfs,yarn,hive)的主体。
(5)实例名:实例名简单理解为主机名。
9.2 Kerberos 在 CDH 中的主要作用
Kerberos 在 Cloudera Distribution for Hadoop (CDH) 中扮演着重要的角色,主要用于集群中的身份验证和安全通信。以下是 Kerberos 在 CDH 中的主要作用:
-
身份验证:Kerberos 为 CDH 集群中的用户、服务和组件提供强大的身份验证。每个用户和服务都有一个唯一的 Kerberos 主体,用于标识其身份。当用户或服务尝试访问集群资源时,他们需要通过 Kerberos 进行身份验证,确保只有经过授权的用户和服务可以访问。
-
单点登录 (Single Sign-On, SSO):Kerberos 允许用户在集群中的不同组件之间进行单点登录。一旦用户通过 Kerberos 身份验证,他们可以在不需要重新输入凭证的情况下访问其他组件。
-
安全通信:Kerberos 为 CDH 集群中的组件之间的通信提供了安全保障。它使用票据 (ticket) 和密钥来加密和解密通信数据,确保数据在传输过程中不会被恶意第三方截取或篡改。
-
授权和访问控制:Kerberos 身份验证为授权和访问控制提供了基础。一旦用户被身份验证,CDH 可以基于其 Kerberos 主体来管理用户对不同资源的访问权限。
-
加密数据存储:CDH 中的一些组件支持对数据进行加密存储,以保护数据在磁盘上的安全性。Kerberos 在加密密钥管理方面起到关键作用,确保只有经过授权的用户和服务可以解密和访问存储的数据。
-
集成安全性:CDH 使用 Kerberos 作为其集成安全性的基础。它可以与其他安全协议和机制(如 LDAP、Active Directory 等)结合使用,为集群提供更加全面和复杂的身份验证和访问控制机制。
总的来说,Kerberos 在 CDH 中用于确保集群中的身份验证、通信和数据存储的安全性。它是建立在 CDH 安全性基础之上的核心组件,为企业级大数据解决方案提供了可信赖的安全保护。
10. Sentry概述
cdh版本的hadoop在对数据安全上的处理通常采用Kerberos+Sentry的结构。
kerberos主要负责平台用户的权限管理,sentry则负责数据的权限管理。
10.1 Sentry是什么
Apache Sentry是Cloudera公司发布的一个Hadoop开源组件,它提供了细粒度级、基于角色的授权以及多租户的管理模式。
Sentry提供了对Hadoop集群上经过身份验证的用户和应用程序的数据控制和强制执行精确级别权限的功能。Sentry目前可以与Apache Hive,Hive Metastore / HCatalog,Apache Solr,Impala和HDFS(仅限于Hive表数据)一起使用。
Sentry旨在成为Hadoop组件的可插拔授权引擎。它允许自定义授权规则以验证用户或应用程序对Hadoop资源的访问请求。Sentry是高度模块化的,可以支持Hadoop中各种数据模型的授权。
10.2 Sentry 的主要作用
Sentry 是一个开源的权限和访问控制解决方案,主要用于大数据生态系统中的安全性管理。在 Cloudera Distribution for Hadoop (CDH) 中,Sentry 扮演着重要的角色,具有以下主要作用:
-
细粒度的权限控制:Sentry 允许管理员在集群中定义和管理细粒度的权限,控制用户和组对数据和操作的访问权限。这种细粒度的权限控制使得管理员可以精确地限制用户能够执行的操作,以及可以访问的数据。
-
跨多个组件的统一权限管理:Sentry 不仅仅适用于 Hadoop 生态系统的核心组件,还可以应用于关系数据库、Solr 等其他与 Hadoop 集成的组件。这使得管理员能够在整个生态系统中保持一致的权限策略,无论数据存储在哪里。
-
动态权限管理:Sentry 允许管理员根据需要随时修改权限,而无需停止集群。这使得在应对变化的访问需求或安全事件时,能够迅速响应并做出必要的调整。
-
基于角色的访问控制:Sentry 支持基于角色的访问控制,管理员可以为用户分配角色,而不必为每个用户单独设置权限。这简化了权限管理,使得用户组织更加灵活。
-
审计和监控:Sentry 可以记录和跟踪用户的操作历史,以便审计和监控。这有助于满足合规性要求,同时也能够追踪和调查任何潜在的安全问题。
-
多租户支持:对于共享集群,Sentry 支持多租户模型,允许不同的用户和组在同一集群中使用不同的数据和资源,而不会相互干扰。
-
数据层次的权限控制:Sentry 可以实现数据层次的权限控制,管理员可以定义哪些用户可以访问特定的数据库、表格、列等数据元素。
-
与其他安全解决方案集成:Sentry 可以与其他安全机制和认证体系(如 Kerberos、LDAP、Active Directory 等)结合使用,实现更强大的安全性和身份验证。
总之,Sentry 在 CDH 中的主要作用是提供灵活、精细和统一的权限管理,帮助管理员保护数据和集群资源的安全,满足合规性要求,降低安全风险。
11. SecondaryNameNode不能恢复 NameNode的全部数据,那如何保证 NameNode数据存储安全
这个问题就要说 NameNode 的高可用了,即 NameNode HA。一个 NameNode 有单点故障的问题,那就配置双 NameNode,配置有两个关键点,一是必须要保证这两个 NN 的元数据信息必须要同步的,二是一个 NN 挂掉之后另一个要立马补上。
-
元数据信息同步在 HA方案中采用的是“共享存储”。每次写文件时,需要将日志同步写入共享存储,这个步骤成功才能认定写文件成功。然后备份节点定期从共享存储同步日志,以便进行主备切换。
-
监控 NN 状态采用 zookeeper,两个 NN节点的状态存放在 ZK中,另外两个 NN节点分别有一个进程监控程序,实施读取 ZK中有 NN的状态,来判断当前的 NN是不是已经 down机。如果 standby的 NN节点的 ZKFC发现主节点已经挂掉,那么就会强制给原本的 activeNN节点发送强制关闭请求,之后将备用的 NN设置为 active。
-
如果面试官再问HA中的 共享存储 是怎么实现的知道吗?
可以进行解释下:NameNode共享存储方案有很多,比如 LinuxHA, VMwareFT, QJM等,目前社区已经把由 Clouderea公司实现的基于 QJM(QuorumJournalManager)的方案合并到HDFS的 trunk 之中并且作为默认的共享存储实现 。
基于 QJM的共享存储系统主要用于保存 EditLog,并不保存 FSImage文件。FSImage文件还是在 NameNode的本地磁盘上。QJM共享存储的基本思想来自于 Paxos算法,采用多个称为JournalNode的节点组成的 JournalNode集群来存储 EditLog。每个 JournalNode保存同样的 EditLog 副本。每次 NameNode写 EditLog的时候,除了向本地磁盘写入 EditLog之外,也会并行地向 JournalNode集群之中的每一个 JournalNode发送写请求,只要大多数 (majority) 的 JournalNode节点返回成功就认为向 JournalNode集群写入 EditLog成功。如果有 2N+1台 JournalNode,那么根据大多数的原则,最多可以容忍有 N台JournalNode节点挂掉
12. 在 NameNodeHA中,会出现脑裂问题吗?怎么解决脑裂
假设 NameNode1当前为 Active状态,NameNode2当前为 Standby状态。如果某一时刻NameNode1对应的 ZKFailoverController进程发生了“假死”现象,那么 Zookeeper服务端会认为 NameNode1挂掉了,根据前面的主备切换逻辑,NameNode2 会替代
NameNode1 进入 Active 状态。但是此时 NameNode1 可能仍然处于 Active 状态正常运行,这样 NameNode1和 NameNode2都处于 Active状态,都可以对外提供服务。这种情况称为脑裂
脑裂对于 NameNode 这类对数据一致性要求非常高的系统来说是灾难性的,数据会发生错乱且无法恢复。Zookeeper 社区对这种问题的解决方法叫做 fencing, 中文翻译为隔离,也就是想办法把旧的 Active NameNode 隔离起来,使它不能正常对外提供服务。
在进行 fencing 的时候,会执行以下的操作:
- 首先尝试调用这个旧 ActiveNameNode的 HAServiceProtocolRPC接口的
transitionToStandby 方法,看能不能把它转换为 Standby 状态。 - 如果 transitionToStandby方法调用失败,那么就执行 Hadoop配置文件之中预定义的隔离措施,Hadoop目前主要提供两种隔离措施,通常会选择 sshfence:
(1) sshfence:通过 SSH登录到目标机器上,执行命令 fuser将对应的进程杀死
(2) shellfence:执行一个用户自定义的 shell脚本来将对应的进程隔离
13. 在CDH6.3版本中将 Flink 编译为 Cloudera CDH 集群可以识别的 Parcel 格式,如何实现步骤?
该步骤整理参考:下硅谷大数据CDH6.3.2教程
当编译 Flink 并制作为 Cloudera CDH 可识别的 Parcel 时,您可以按照以下详细步骤操作:
步骤 1:下载所需文件
-
在 Linux 终端中,创建一个用于存放下载文件的文件夹,如
/opt/software:mkdir /opt/software cd /opt/software -
下载 Flink 1.13.6 的二进制包和源码包:
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.11.tgz wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-src.tgz -
下载 Maven 3.6.3 的二进制包:
wget https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
步骤 2:安装 Maven
-
解压 Maven 并配置环境变量:
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module echo "export MAVEN_HOME=/opt/module/apache-maven-3.6.3" >> /etc/profile.d/my_env.sh echo "export PATH=\$PATH:\$MAVEN_HOME/bin" >> /etc/profile.d/my_env.sh source /etc/profile.d/my_env.sh -
验证 Maven 安装:
mvn -v -
修改 Maven 镜像源(可选):
在
/opt/module/apache-maven-3.6.3/conf/settings.xml中添加合适的镜像源。
步骤 3:修改 Flink 源码
-
解压 Flink 源码包:
tar -zxvf flink-1.13.6-src.tgz -C /opt/module mv flink-1.13.6/ flink-1.13.6-src -
修改 Flink 源码中的
pom.xml文件:- 修改 Hadoop 版本:在
<hadoop.version>中设置为3.0.0-cdh6.3.2。 - 修改 Hive 版本:在
<hive.version>和<hivemetastore.hadoop.version>中设置为2.1.1-cdh6.3.2。 - 添加 Cloudera 和 Confluent 仓库地址:在
<repositories>中添加相应仓库。
- 修改 Hadoop 版本:在
-
修改
flink-sql-connector-hive-2.2.0的pom.xml文件:- 修改
hive-exec版本为2.1.1-cdh6.3.2。
- 修改
步骤 4:编译 Flink
-
编译 Flink 项目(可以跳过测试):
cd /opt/module/flink-1.13.6-src/ mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.3.2 -Dinclude-hadoop -Dscala-2.11 -T10C
步骤 5:创建 Parcel 目录结构
- 创建 Parcel 目录结构,包括
meta、lib、bin、etc等文件夹。
步骤 6:拷贝文件
- 将编译好的 Flink JAR 包和所需的依赖库拷贝到
lib文件夹中。 - 拷贝 Hive 相关的 JAR 包和其他依赖到
lib文件夹。
步骤 7:生成 Parcel 文件
-
使用 Cloudera Parcels 工具生成 Parcel 文件:
./build.sh parcel

步骤 8:安装 Parcel 到 Cloudera Manager
- 将生成的 Parcel 文件拷贝到 Cloudera Manager 的
parcel-repo目录中。 - 修改
manifest.json文件,添加 Flink.parcel 相关的加载依赖配置。
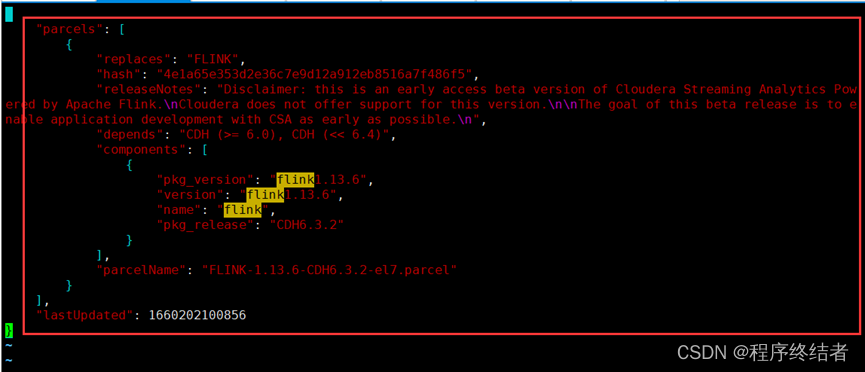
步骤 9:拷贝 CSD 文件
- 将生成的
FLINK_ON_YARN-1.13.6.jar文件拷贝到 Cloudera Manager 的csd目录中。
步骤 10:重启服务
- 重启 Cloudera Manager 服务,使其加载新的 Parcel 和 CSD 文件。
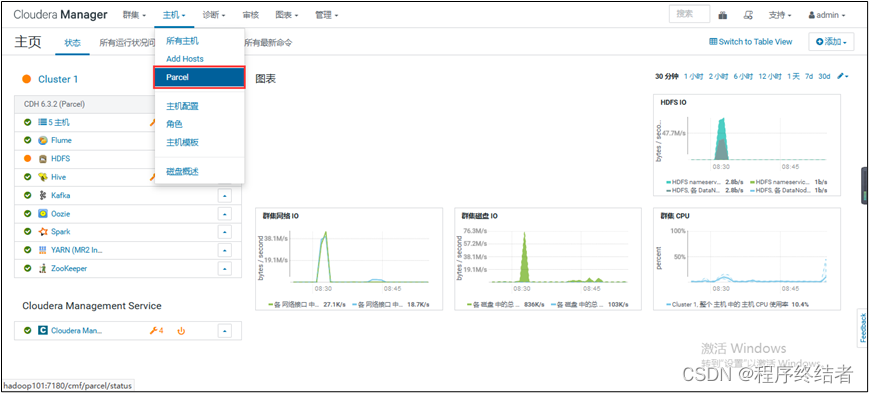
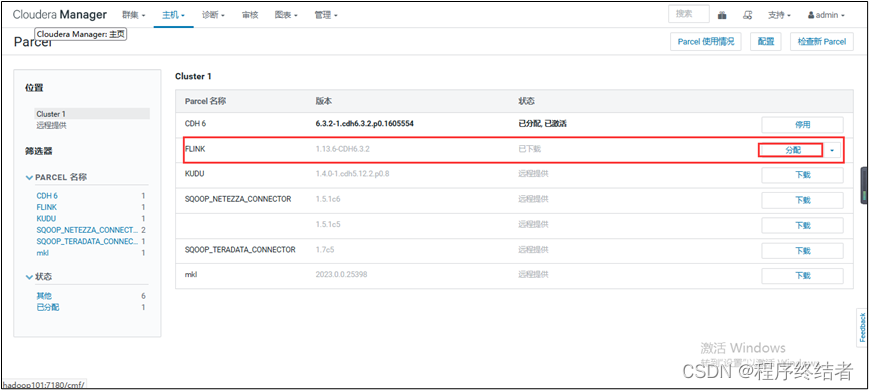
步骤 11:添加 Flink 服务配置和集群规划
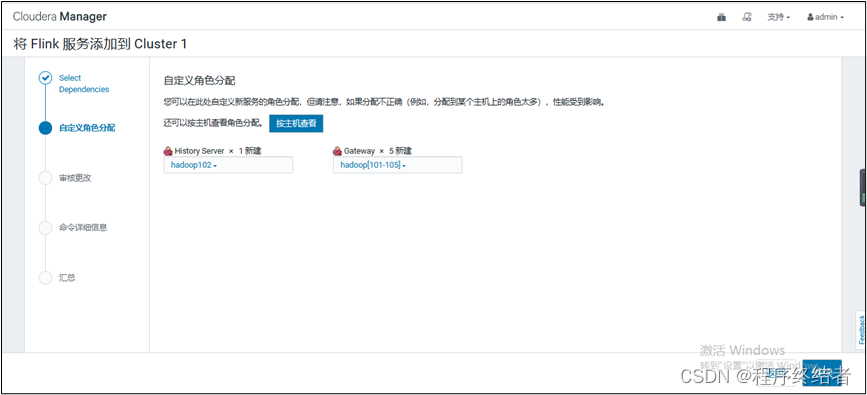
- 在 Cloudera Manager 界面中添加 Flink 服务配置和集群规划信息。
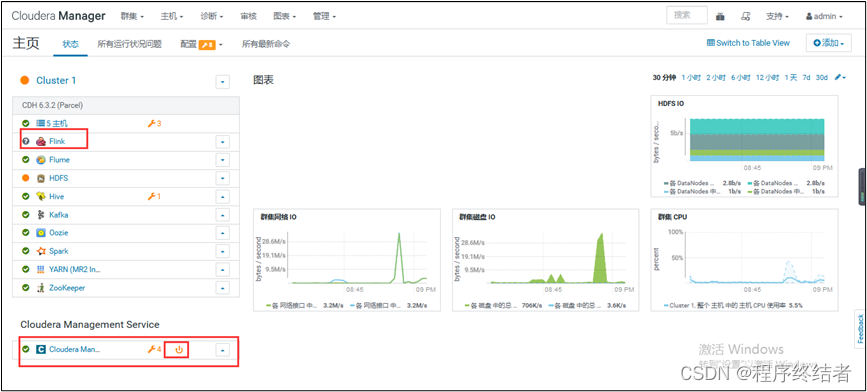
步骤 12:重启服务
- 在 Cloudera Manager 界面中重启 Flink 服务,使配置生效。
14. 阿里云官方对CM的架构描述
原文链接:跳转阿里云官方
14.1 CM术语
部署
Cloudera Manager 及其管理的所有集群的配置。
动态资源池
在 Cloudera Manager 中,这是资源的命名配置,以及用于在池中运行的 YARN 应用程序或 Impala 查询之间调度资源的策略。
集群
包含 HDFS 文件系统并对该数据运行 MapReduce 和其他进程的一组计算机或计算机机架。
在 Cloudera Manager 中,是一个逻辑实体,包含一组主机,在主机上安装的单个版本的 Cloudera Runtime 以及在主机上运行的服务和角色实例。一台主机只能属于一个集群。Cloudera Manager 可以管理多个集群,但是每个集群只能与一个 Cloudera Manager Server 关联。
主机
在 Cloudera Manager 中,是运行角色实例的物理或虚拟机。一台主机只能属于一个集群。
机架
在 Cloudera Manager 中,是一个物理实体,包含一组通常由同一交换机提供服务的物理主机。
服务
在尽可能可预测的环境中运行在/etc/init.d/定义的 System V 初始化脚本的 Linux 命令 ,删除大多数环境变量并将当前工作目录设置为/。
Cloudera Manager 中的托管功能类别,可以在集群中运行,有时称为服务类型。例如:Hive、HBase、HDFS、YARN 和 Spark。
服务实例
在 Cloudera Manager 中,是在集群上运行的服务的实例。例如:“ HDFS-1”和“yarn”。服务实例跨越许多角色实例。
角色
在 Cloudera Manager 中,服务中的功能类别。例如,HDFS 服务具有以下角色:NameNode、SecondaryNameNode、DataNode 和 Balancer。有时称为角色类型。
角色实例
在 Cloudera Manager 中,是在主机上运行的角色的实例。它通常映射到 Unix 进程。例如:“ NameNode-h1”和“ DataNode-h1”。
角色组
在 Cloudera Manager 中,这是一组角色实例的一组配置属性。
主机模板
Cloudera Manager 中的一组角色组。将模板应用于主机时,将创建每个角色组中的角色实例并将其分配给该主机。
网关
一种角色类型,通常为客户端提供对特定群集服务的访问权限。例如,HDFS、Hive、Kafka、MapReduce、Solr 和 Spark 各自具有网关角色,以为其客户提供对其各自服务的访问。网关角色并非总是在其名称中带有“网关”,也不是专门用于客户端访问。例如,Hue Kerberos Ticket Renewer 是一个网关角色,用于代理 Kerberos 中的票证。
支持一个或多个网关角色的节点有时称为网关节点或边缘节点,在网络或云环境中常见“边缘”的概念。对于 Cloudera 集群,当从 Cloudera Manager 管理控制台的“操作”菜单中选择“部署客户端配置”时,群集中的网关节点将接收适当的客户端配置文件。
Parcel
二进制分发格式,包含编译的代码和元信息,例如程序包描述、版本和依赖项。
静态服务池
在 Cloudera Manager 中,是跨一组服务的总群集资源(CPU,内存和I / O权重)的静态分区。
14.2 Cloudera Manager 架构
如下所示,Cloudera Manager 的核心是 Cloudera Manager Server。服务器托管Cloudera Manager 管理控制台、Cloudera Manager API 和应用程序逻辑、并负责安装软件、配置、启动和停止服务以及管理在其上运行服务的集群。
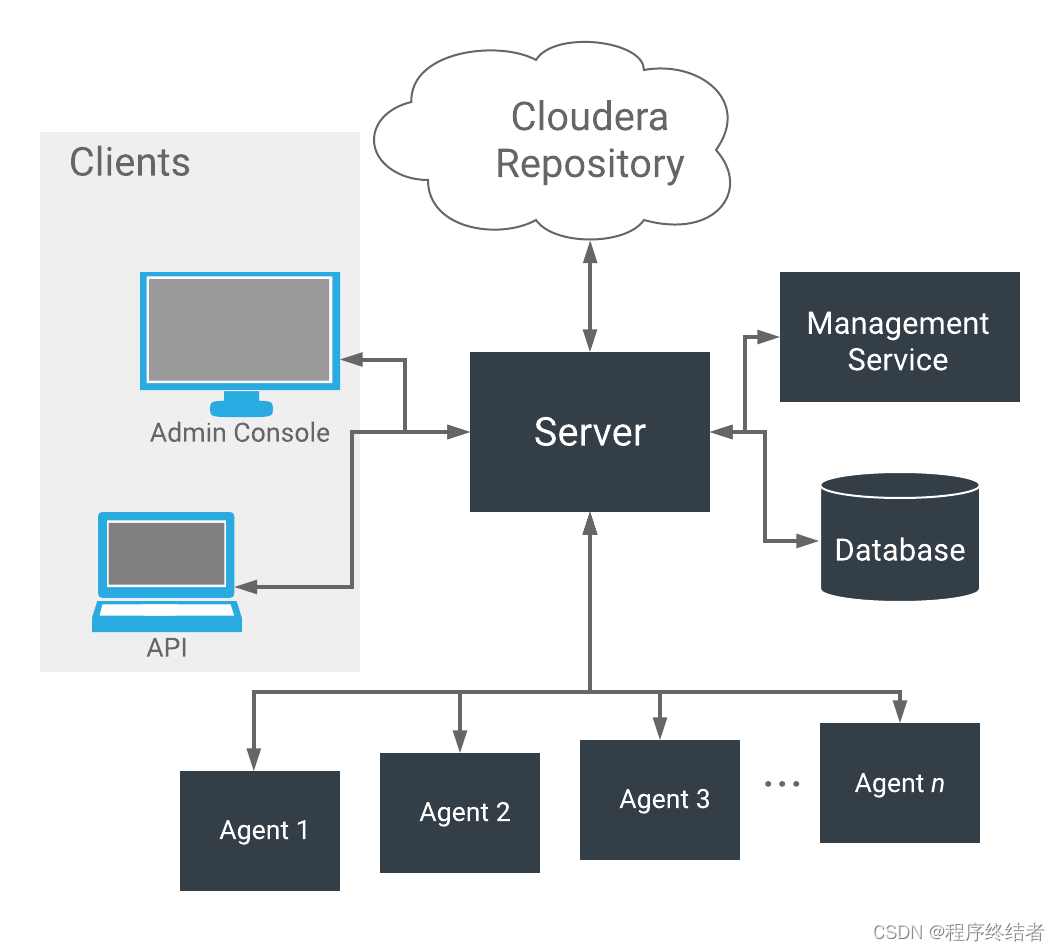
Cloudera Manager Server 与其他几个组件一起使用:
代理
安装在每台主机上。该代理负责启动和停止进程、解包配置、触发安装以及监控主机。
管理服务
由一组角色组成的服务,这些角色执行各种监控、警报和报告功能。
数据库
存储配置和监控信息。通常,多个逻辑数据库跨一个或多个数据库服务器运行。例如,Cloudera Manager Server 和监控角色使用不同的逻辑数据库。
Cloudera 存储库
由 Cloudera Manager 分发的软件存储库。
客户端
是与服务器交互的接口。
Cloudera Manager 管理控制台
基于Web的用户界面,管理员用于管理集群和Cloudera Manager。
Cloudera Manager API
API 开发人员用于创建自定义 Cloudera Manager 应用程序。
心跳
心跳是 Cloudera Manager 中的主要通信机制。默认情况下,代理每15秒将心跳发送一次到 Cloudera Manager Server。但是,为减少用户等待时间,在状态更改时增加了频率。
在心跳交换期间,代理会将其活动通知给 Cloudera Manager Server。反过来,Cloudera Manager Server 响应代理应执行的操作。代理和 Cloudera Manager Server 最终都进行了一些协调。例如,如果您启动服务,则代理将尝试启动相关进程;否则,代理将尝试启动相关进程。如果进程无法启动,则 Cloudera Manager Server 会将启动命令标记为失败。





![[LitCTF 2023]1zjs](https://img-blog.csdnimg.cn/be73913232ae444bafe79c5f9a99c018.png)