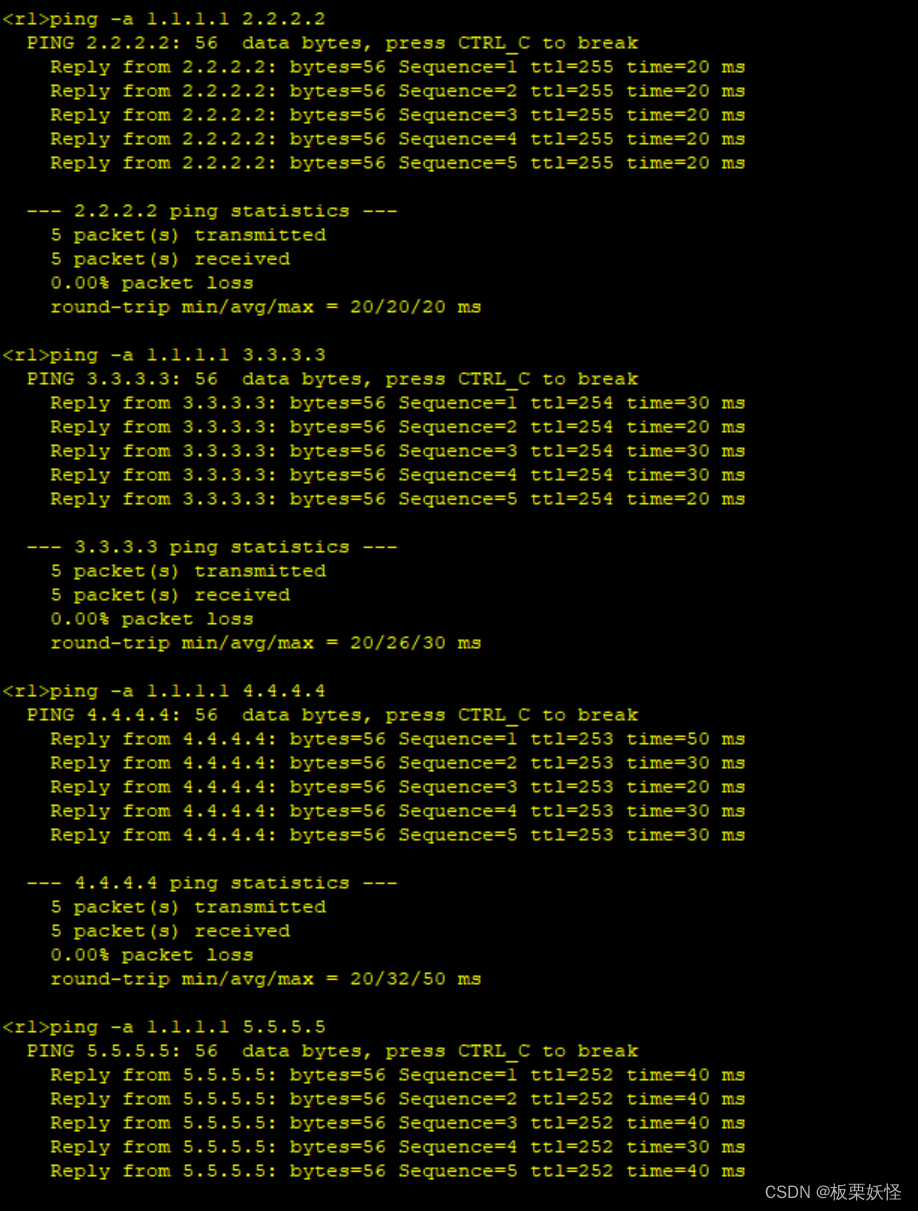
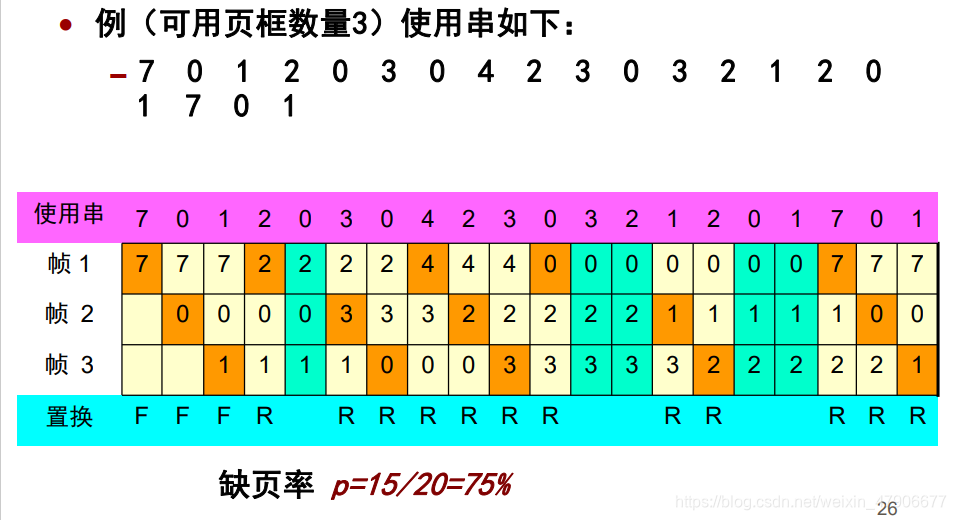
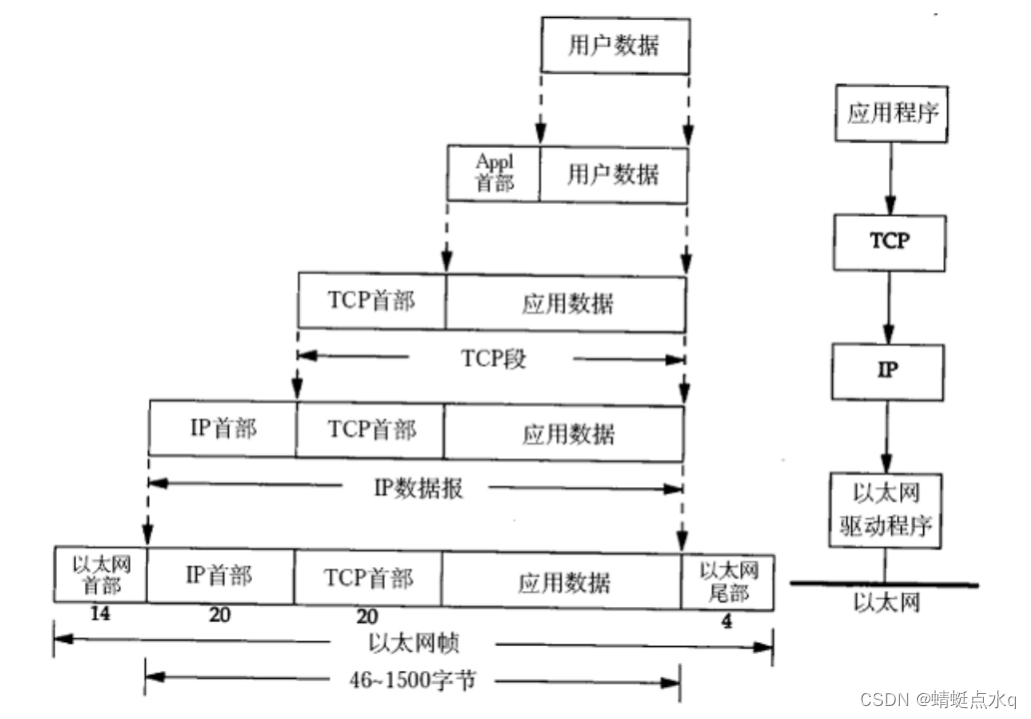
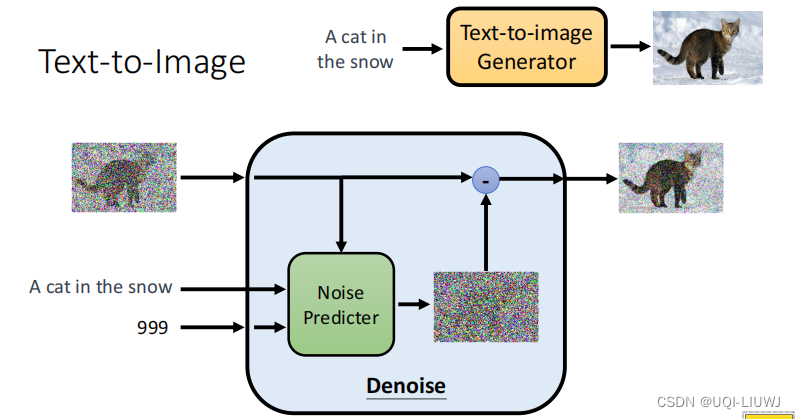
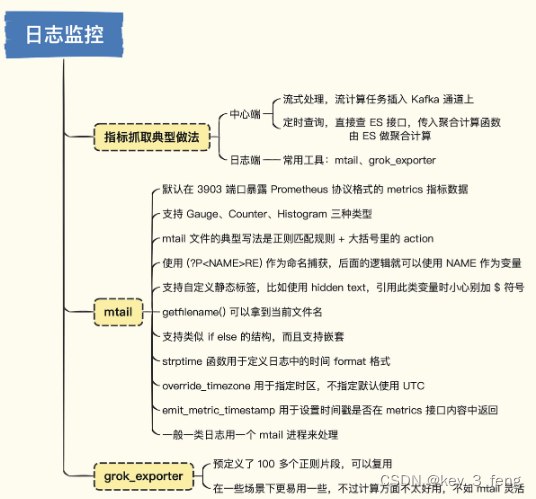
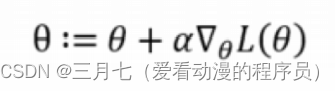根据提取规则运行的位置可以分为两类做法,一个是在中心端,一个是在日志端。
中心端就是把要处理的所有机器的日志都统一传到中心,比如通过 Kafka 传输,最终落到 Elasticsearch,指标提取规则可以作为流计算任务插到 Kafka 通道上,性能和实时性都相对更好。或者直接写个定时任务,调用 Elasticsearch 的接口查询日志,同时给出聚合计算函数,让 Elasticsearch 返回指标数据,然后写入时序库,实时性会差一些,但也基本够用。
日志端处理是指提取规则直接运行在产生日志的机器上,流式读取日志,匹配正则表达式。对于命中的日志,提取其中的数字部分作为指标上报,或者不提取任何数字,只统计一下命中的日志行数有时也很有价值,比如统计一下 Error 或 Exception 关键字出现的次数,我们就知道系统是不是报错了。
日志端处理的方式,倒是有很多开源方案,比较有名的是 mtail 和 grok_exporter。
mtail、grok_exporter 等工具就像是对日志文件执行 tail -f,然后每收到一条日志,就去匹配预定义的正则表达式,如果匹配成功,就执行某些动作,否则跳过等待下一条日志。
mtail 的部署,如果一个机器上有 5 个应用程序都要用 mtail 来提取指标,各个应用的日志格式又不一样,建议启动 5 个 mtail 进程分别来处理。虽然管理起来麻烦,但是性能好,相互之间没有影响。
如果把所有提取规则都放到一个目录下,然后通过多次 -logs 参数的方式同时指定这多个应用的日志路径,一个 mtail 进程也能处理,但是对于每一行日志,mtail 要把所有提取规则都跑一遍,十分浪费性能,而且正则提取,速度本来就不快。另外有些指标可能是所有应用都可以复用的,如果放在一起处理,还容易相互干扰,导致统计数据不准。从这两点来看,尽量还是要拆开分别处理,虽然管理起来麻烦一些,但也是值得的。
在容器场景中就没有这个问题,容器场景直接使用 sidecar 部署就好了,每个 Pod 必然只有一个应用,伴生的 mtail 就专注去处理这个应用的日志就好了。
指标提取的几种方式,总体上来看就是中心端和日志端两种,由于中心端的处理方式多见于商业软件,没有看到开源解决方案。日志端的处理核心逻辑都是一样的,通过类似 tail -f 的方式不断读取日志内容,然后对每行日志做正则匹配提取,由于日志格式不固定,很难有结构化的处理手段,所以这些工具都是选择使用正则的方式来提取过滤指标。
此文章为8月Day13学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。