大家好,我是微学AI,今天给大家介绍一下人工智能124种任务大集合,任务集合主要包括4大类:自然语言处理(NLP)、计算机视觉(CV)、语音识别、多模态任务。

我这里整理了124种应用场景任务大集合,每个任务目录如下:
- 句子嵌入(Sentence Embedding):将句子映射到固定维度的向量表示形式。
- 文本排序(Text Ranking):对一组文本进行排序,以确定它们与给定查询的相关性。
- 分词(Word Segmentation):将连续的文本切分成单词或词块的过程。
- 词性标注(Part-of-Speech):对句子中的每个词汇标注其相应的词性。
- 标记分类(Token Classification):将输入的文本序列中的每个标记分类为预定义的类别。
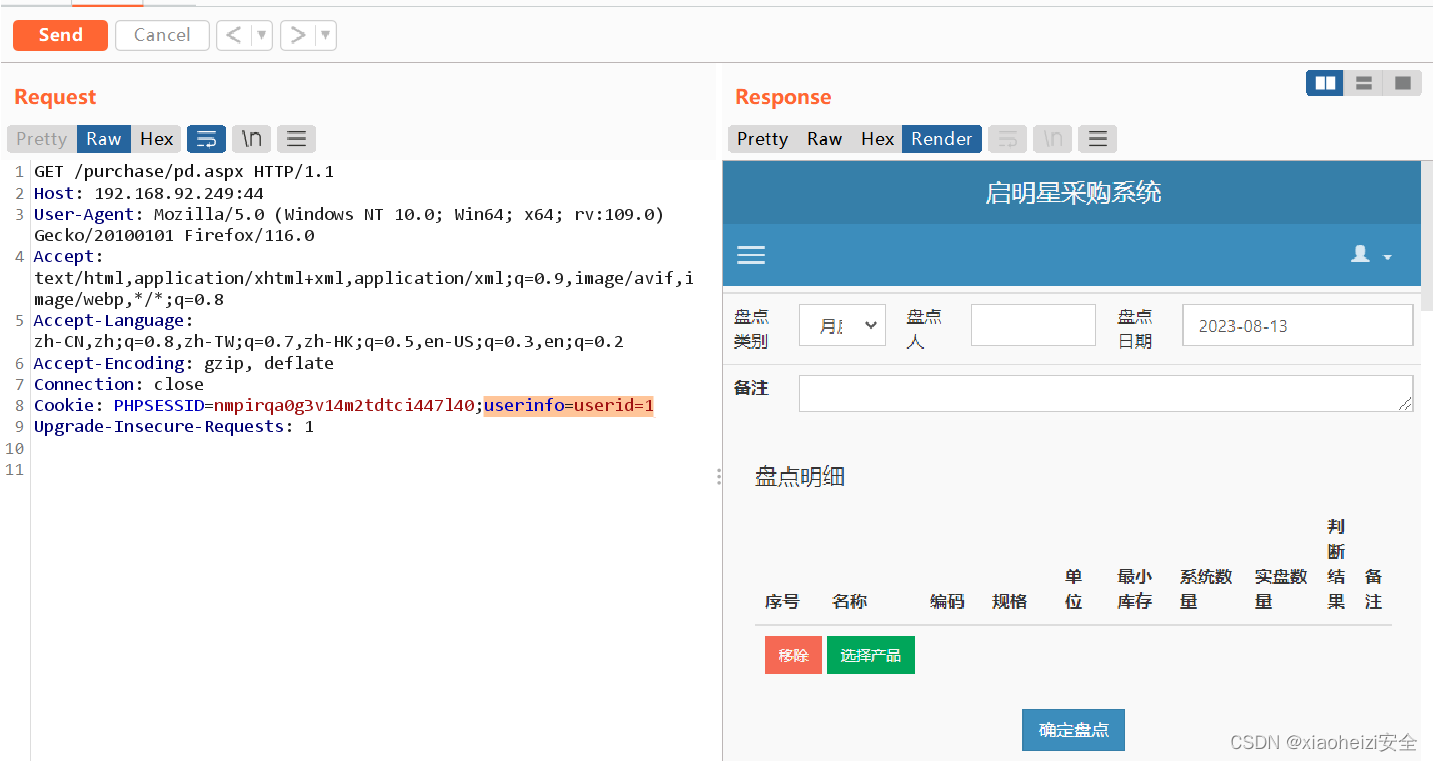
- 命名实体识别(Named Entity Recognition):识别文本中具有特定意义的命名实体,如人名、地点、组织等。
- 关系抽取(Relation Extraction):从文本中抽取出实体之间的关系或联系。
- 信息抽取(Information Extraction):从非结构化文本中提取结构化的信息,如实体、关系和属性等。
- 句子相似度(Sentence Similarity):衡量两个句子之间的语义相似度或相关性。
- 文本翻译(Translation):将一种语言的文本转换为另一种语言的过程。
- 自然语言推理(NLI:Natural Language Inference):判断给定的前提和假设之间的逻辑关系,包括蕴含、矛盾和中立等。
- 情感分类(Sentiment Classification):将文本分为积极、消极或中性等情感类别。
- 人像抠图(Portrait Matting):从图像中准确地分离人物主体与背景。
- 通用抠图(Universal Matting):从图像中准确地分离目标物体与背景,不限于人像。
- 人体检测(Human Detection):检测图像或视频中的人体位置。
- 图像目标检测(Image Object Detection):在图像中检测和定位多个目标对象。
- 图像去噪(Image Denoising):降低图像中的噪声水平,改善图像质量。
- 图像去模糊(Image Deblurring):恢复模糊图像的清晰度和细节。
- 视频稳定化(Video Stabilization):对视频进行抖动校正,使其稳定且平滑。
- 视频超分辨率(Video Super-Resolution):通过增加视频的像素级别细节来提高其分辨率。
- 文本分类(Text Classification):将文本分类为预定义的类别或标签。
- 文本生成(Text Generation):根据给定输入生成连续文本的过程。
- 零样本分类(Zero-Shot Classification):将数据分类为模型从未在训练阶段见过的类别。
- 任务导向对话(Task-Oriented Conversation):进行与特定任务相关的对话和问答。
- 对话状态跟踪(Dialog State Tracking):跟踪多轮对话中的用户意图和系统状态的变化。
- 表格问答(Table Question Answering):根据表格数据回答相关问题。
- 文档导向对话生成(Document-Grounded Dialog Generation):基于文档内容生成相关对话回复。
- 文档导向对话重新排序(Document-Grounded Dialog Rerank):对生成的对话回复进行排序,以选择最佳回复。
- 文档导向对话检索(Document-Grounded Dialog Retrieval):从候选对话中检索与文档相关的最佳对话。
- 文本纠错(Text Error Correction):自动纠正文本中的拼写错误或语法错误。
- 图像字幕生成(Image Captioning):根据图像内容生成对图像的描述性文字。
- 视频字幕生成(Video Captioning):根据视频内容生成对视频的描述性文字。
- 图像人像风格化(Image Portrait Stylization):将图像中的人物主体应用艺术风格转换。
- 光学字符识别(OCR Detection):从图像中检测和识别文字。
- 表格识别(Table Recognition):从图像中自动识别表格结构和内容。
- 无线表格识别(Lineless Table Recognition):从无线表格图像中自动识别表格结构和内容。
- 文档视觉语义嵌入(Document-VL Embedding):将文档映射到视觉语义空间的向量表示形式。
- 车牌检测(License Plate Detection):在图像中检测和定位车辆的车牌区域。
- 填充掩码(Fill-Mask):根据上下文和部分信息填充给定的掩码。
- 特征提取(Feature Extraction):从输入数据中提取有意义的特征表示。
- 动作识别(Action Recognition):识别视频中的动作或行为。
- 动作检测(Action Detection):在视频中检测和定位特定动作或行为。
- 直播分类(Live Category):对直播视频进行分类,如体育、新闻、游戏等。
- 视频分类(Video Category):对视频进行分类,如电影、音乐、体育等。
- 多模态嵌入(Multi-Modal Embedding):将多种不同模态的数据映射到共享的向量空间。
- 生成式多模态嵌入(Generative Multi-Modal Embedding):将多模态数据映射到向量表示,并且能够生成与之相关的数据。
- 多模态相似度(Multi-Modal Similarity):衡量多模态数据(例如图像和文本)之间的相似性或相关性。
- 视觉问答(Visual Question Answering):根据给定的图像和问题回答相关问题。
- 视频问答(Video Question Answering):根据给定的视频和问题回答相关问题。
- 视频嵌入(Video Embedding):将视频序列映射到固定维度的向量表示形式。
- 文本到图像合成(Text-to-Image Synthesis):根据给定的文本描述合成相应的图像。
- 文本到视频合成(Text-to-Video Synthesis):根据给定的文本描述合成相应的视频。
- 人体二维关键点(Body 2D Keypoints):检测和跟踪图像中的人体关键点。
- 人体三维关键点(Body 3D Keypoints):在三维空间中检测和跟踪人体关键点。
- 手部二维关键点(Hand 2D Keypoints):检测和跟踪图像中的手部关键点。
- 卡片检测(Card Detection):在图像中检测和定位特定类型的卡片。
- 内容检查(Content Check):检查文本或图像中是否存在不良、敏感或违法内容。
- 人脸检测(Face Detection):检测图像或视频中的人脸位置。
- 人脸活体检测(Face Liveness):判断图像或视频中的人脸是否为真实的活体,而非照片或视频。
- 人脸识别(Face Recognition):识别图像或视频中的人脸,并将其与已知的身份进行匹配。
- 面部表情识别(Facial Expression Recognition):识别图像或视频中人脸的表情状态,如快乐、悲伤、愤怒等。
- 面部属性识别(Face Attribute Recognition):识别图像或视频中人脸的属性,如年龄、性别、种族等。
- 面部二维关键点(Face 2D Keypoints):检测和跟踪图像中的面部关键点。
- 面部质量评估(Face Quality Assessment):评估图像或视频中人脸图像的质量。
- 视频多模态嵌入(Video Multi-Modal Embedding):将多模态数据(如图像和文本)映射到共享的向量空间。
- 图像色彩增强(Image Color Enhancement):增强图像的色彩饱和度、对比度和亮度等。
- 虚拟试衣(Virtual Try-On):通过计算机生成的技术,将虚拟服装应用到真实人体图像上,以实现在线试穿效果。
- 图像上色(Image Colorization):将灰度图像恢复为彩色图像的过程。
- 视频上色(Video Colorization):将黑白视频恢复为彩色视频的过程。
- 图像分割(Image Segmentation):将图像分成多个不同的区域或对象。
- 图像驾驶感知(Image Driving Perception):利用计算机视觉技术提取图像中与驾驶相关的信息,如车道线、交通标志等。
- 图像深度估计(Image Depth Estimation):根据单目或双目图像估计场景中物体的深度或距离。
- 室内布局估计(Indoor Layout Estimation):根据室内图像估计房间的布局结构。
- 视频深度估计(Video Depth Estimation):根据视频中的帧间信息估计场景中物体的深度或距离。
- 全景深度估计(Panorama Depth Estimation):在全景图像中估计场景中物体的深度或距离。
- 图像风格迁移(Image Style Transfer):将一个图像的风格应用到另一个图像上,以生成具有新风格的图像。
- 面部图像生成(Face Image Generation):生成逼真的面部图像,可以用于人脸数据增强、数据生成等应用。
- 图像超分辨率(Image Super-Resolution):通过增加图像的像素级细节来提高其分辨率。
- 图像去块效应(Image Debanding):减少图像中由压缩引起的块状伪影或条纹噪声。
- 图像人像增强(Image Portrait Enhancement):改善图像中人物主体的外观、肤色等特征。
- 商品检索嵌入(Product Retrieval Embedding):将商品映射到向量表示形式,以支持商品相关性检索。
- 图像到图像生成(Image-to-Image Generation):根据给定的输入图像生成相应的输出图像。
- 图像分类(Image Classification):将图像分类为预定义的类别或标签。
- 光学字符识别(OCR Recognition):从图像中检测和识别印刷体或手写体的文字。
- 美肤(Skin Retouching):对人脸图像进行美化处理,去除皮肤瑕疵、磨皮等。
- 常见问题解答(FAQ Question Answering):根据常见问题回答用户的提问。
- 人群计数(Crowd Counting):根据图像或视频中的人群密度估计人数。
- 视频单目标跟踪(Video Single Object Tracking):在视频序列中跟踪单个目标对象。
- 图像人物再识别(Image ReID - Person):根据图像中的人物外观特征进行身份再识别。
- 文本驱动分割(Text-Driven Segmentation):根据给定的文本描述,对图像或视频中的对象进行分割。
- 电影场景分割(Movie Scene Segmentation):将电影或视频分割为不同的场景,每个场景代表一个独立的情节或事件。
- 商店分割(Shop Segmentation):将商店内的物体或区域从图像或视频中分割出来,用于商品展示、智能监控等应用。
- 图像修复(Image Inpainting):根据已有的图像内容,填补缺失或损坏的部分,恢复原始图像的完整性。
- 图像按范例绘制(Image Paint-By-Example):根据给定的范例图像,将其他图像修改为具有相似绘画风格或效果的图像。
- 可控图像生成(Controllable Image Generation):通过控制输入参数或向量,生成具有特定属性、风格或特征的图像。
- 视频修复(Video Inpainting):根据已有的视频内容,填补缺失或损坏的帧或区域,恢复原始视频的完整性。
- 视频人像抠像(Video Human Matting):将视频中的人物从背景中分割出来,以便进行后续的编辑或特效处理。
- 人体重建(Human Reconstruction):基于给定的图像、视频或传感器数据,重建人体的三维模型或姿态信息。
- 视频帧插值(Video Frame Interpolation):对给定的两个视频帧之间的帧进行生成,以增加视频的帧率或平滑过渡。
- 视频去隔行(Video Deinterlace):将隔行扫描的视频转换为逐行扫描,提高视频播放的质量和流畅度。
- 全身人体关键点检测(Human Wholebody Keypoint Detection):在图像或视频中检测和定位人体的关键点,例如头部、手、脚等。
- 静态手势识别(Hand Static):通过分析手掌形状、手指姿势等信息,识别图像或视频中的静态手势。
- 人脸、人体和手部检测(Face-Human-Hand Detection):检测和定位图像或视频中的人脸、人体和手部区域。
- 人脸情绪分析(Face Emotion):通过分析人脸表情,判断图像或视频中人脸所表达的情绪状态。
- 商品分割(Product Segmentation):将图像或视频中的商品或产品从背景中分割出来,用于商品识别、广告推荐等应用。
- 参考视频对象分割(Referring Video Object Segmentation):根据给定的参考图像或视频,对图像或视频中的对象进行分割。
- 视频摘要(Video Summarization):根据视频的内容和特征,生成视频的摘要或概览,提供视频浏览和检索的便利性。
- 图像天空变换(Image Sky Change):将图像中的天空部分替换为不同的天空背景,改变图像的氛围和环境。
- 翻译评估(Translation Evaluation):根据给定的翻译结果,评估其质量、准确性以及与原文的一致性。
- 视频对象分割(Video Object Segmentation):将视频中的对象从背景中分割出来,以便进行后续的编辑或特效处理。
- 视频多目标跟踪(Video Multi-Object Tracking):在视频中同时跟踪多个移动目标,实时定位和追踪目标的位置。
- 多视角深度估计(Multi-View Depth Estimation):通过多个视图或图像,估计场景中物体的三维深度信息。
- 少样本检测(Few-Shot Detection):在只有少量标注样本的情况下,进行目标检测任务,提高模型的泛化能力。
- 人体形状重塑(Body Reshaping):根据图像或视频中的人体区域,调整人体的形状、姿态或比例,改变人体外貌。
- 人脸融合(Face Fusion):将一个人的面部特征或表情融合到另一个人的头像上,生成具有两者特点的合成图像。
- 图像匹配(Image Matching):在图像库或数据库中,找到与给定图像最相似或匹配的图像。
- 图像质量评估 - 主观评分(Image Quality Assessment - MOS):通过主观评分的方法,评估图像的质量,反映人眼对图像的感知。
- 图像质量评估 - 降质度量(Image Quality Assessment - Degradation):通过客观度量的方法,评估图像在不同变换或压缩条件下的质量。
- 视觉高效调优(Vision Efficient Tuning):通过自动化的方法,快速调优和优化视觉模型和算法,提升计算效率和准确性。
- 三维目标检测(Object Detection 3D):在三维空间中,检测和定位目标物体的位置、尺寸和姿态。
- 坏图像检测(Bad Image Detecting):识别和检测出图像中存在的噪点、模糊、失真等不良或低质量的图像。
- Nerf重建精度评估(NeRF Reconstruction Accuracy):评估神经辐射场(NeRF)模型在建立3D场景重建时的准确性和质量。
- Siamese UIE:Siamese网络用于UIE任务,即输入用户界面元素识别或生成的相关问题。
- 数学公式识别(LatexOCR):图片中数学公式的latex识别。