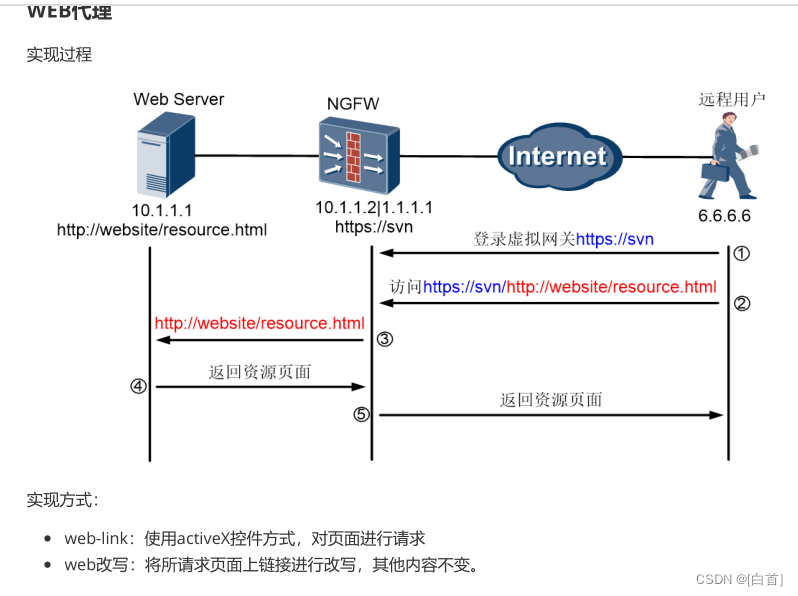
LangChain-ChatGLM在WIndows10下的部署
参考资料
1、LangChain + ChatGLM2-6B 搭建个人专属知识库中的LangChain + ChatGLM2-6B 构建知识库这一节:基本的逻辑和步骤是对的,但要根据Windows和现状做很多调整。
2、没有动过model_config.py中的“LORA_MODEL_PATH_BAICHUAN”这一项内容,却报错:对报错“LORA_MODEL_PATH_BAICHUAN”提供了重要解决思路,虽然还不是完全按文中的方式解决的。
3、[已解决ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。: ‘e:\anaconda\install_r])(https://blog.csdn.net/yuan2019035055/article/details/127078460)
解决方案
一、下载源码
采用git clone方式一直不成功,建议直接到github上搜索langchain-chatglm,在https://github.com/chatchat-space/langchain-ChatGLM页面,点击“CODE”->点击“Download ZIP”,直接下载源码,然后将文件夹改为名LangChain-ChatGLM,放到D:\_ChatGPT\langchain-chatglm_test目录下:
二、安装依赖
1、进入Anaconda Powershell Prompt
2、进入虚拟环境
conda activate langchain-chatglm_test
3、进入目录
cd D:\_ChatGPT\langchain-chatglm_test\langchain-ChatGLM
4、安装依赖
pip install -r requirements.txt --user
pip install peft
pip install timm
pip install scikit-image
pip install torch==1.13.1+cu116 torchvision torchaudio -f https://download.pytorch.org/whl/cu116/torch_stable.html
三、下载模型
3.1、下载chatglm2-6b模型
1、进入Anaconda Powershell Prompt
2、创建保存chatglm2-6b的huggingface模型的公共目录。之所以创建一个公共目录,是因为这个模型文件是可以被各种应用共用的。注意创建目录所在磁盘至少要有30GB的空间,因为chatglm2-6b的模型文件至少有23GB大小。并进入该目录
mkdir -p D:\_ChatGPT\_common
cd D:\_ChatGPT\_common
3、安装 git lfs
git lfs install
4、在这里下载chatglm2-6b的huggingface模型文件。
git clone https://huggingface.co/THUDM/chatglm2-6b
5、下载完成后,将模型文件的目录名改为chatglm2-6b,因为Windows下目录如果有减号,后续应用处理会出错。
6、如果之前已下载该模型,则不必重复下载。
3.2、下载text2vec模型
1、进入Anaconda Powershell Prompt,进入公共目录
cd D:\_ChatGPT\_common
2、安装 git lfs
git lfs install
3、在这里下载text2vec的huggingface模型文件。
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
4、下载完成后,将目录改为text2vev,因为Windows下目录如果有减号,后续应用处理会出错。
四、参数调整
4.1、model_config.py文件
1、进入configs目录,修改其下的model_config.py文件,
对embedding_model_dict的参数
embedding_model_dict = {
...
"text2vec": r"D:\_ChatGPT\_common\text2vec",
...
}
修改llm_model_dict参数。
llm_model_dict = {
...
"chatglm-6b": {
...
"pretrained_model_name": r"D:\_ChatGPT\_common\chatglm2_6b",
"...
},
...
}
将LLM_MODEL的值做修改:
LLM_MODEL = "chatglm2-6b"
4.2、loader.py文件
1、进入modes\loader目录,修改loader.py文件
2、在if LORA_MODEL_PATH_BAICHUAN:前加一句LORA_MODEL_PATH_BAICHUAN = False,如下所示:
if torch.cuda.is_available() and self.llm_device.lower().startswith("cuda"):
# 根据当前设备GPU数量决定是否进行多卡部署
num_gpus = torch.cuda.device_count()
if num_gpus < 2 and self.device_map is None:
# if LORA_MODEL_PATH_BAICHUAN is not None:
LORA_MODEL_PATH_BAICHUAN = False
if LORA_MODEL_PATH_BAICHUAN:
3、在每一个mode = XXX.from_pretrained(XXX)后面加上.quantize(8).cuda(),对模型进行量化,否则加载会报内存不够的错误。
五、启动
1、关闭fanqiang软件
2、运行如下命令
python .\webui.py
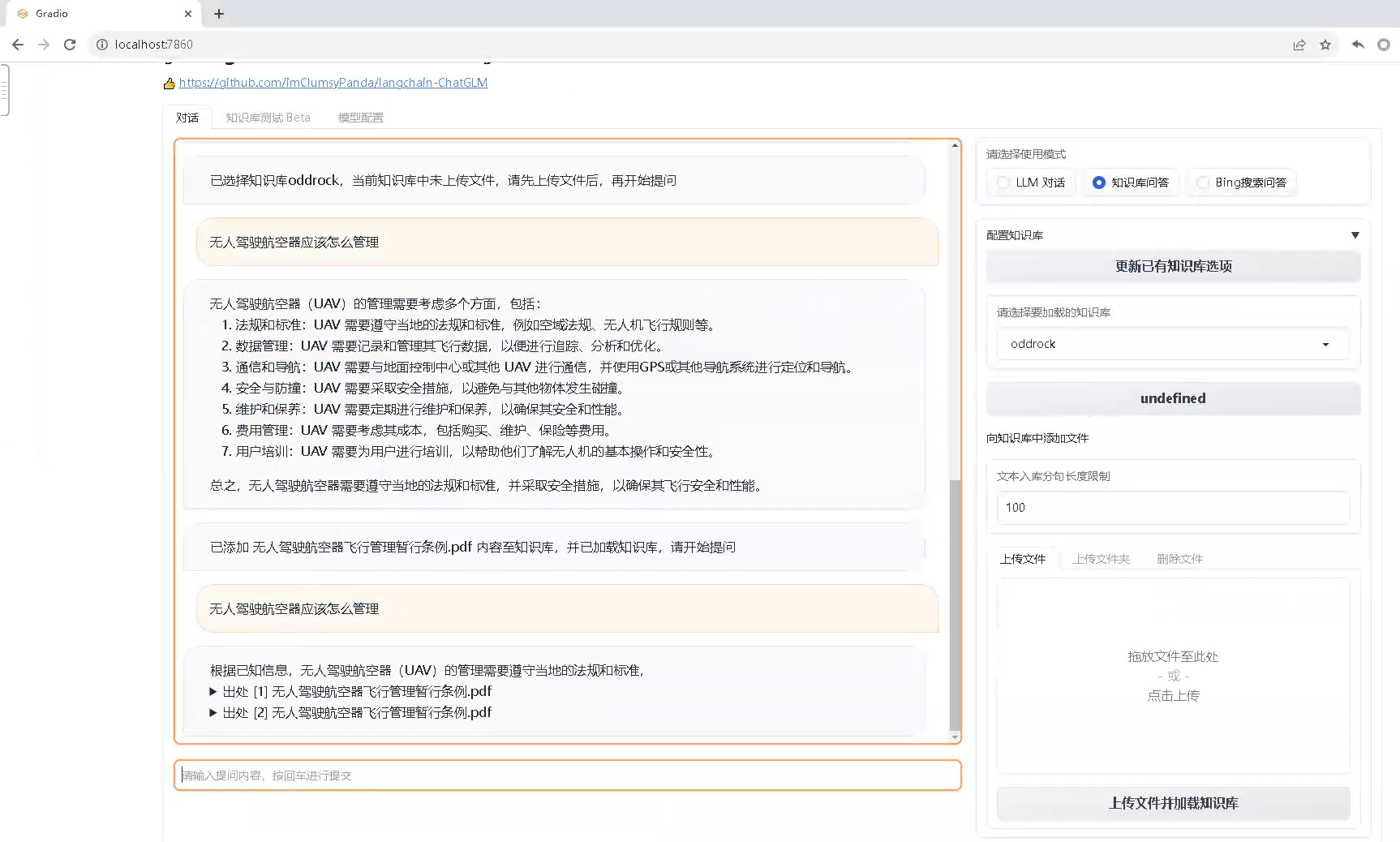
3、访问http://localhost:7860
六、上传文档进行问答
1、在http://localhost:7860界面,在请选择要加载的知识库,选择samples。
2、向知识库中添加一个文件,点击上传文件并加载,等待几分钟以后,模型完成训练,即可针对上传的文件进行问答。