文章目录
- 前言
- 使用 Power BI 处理结构化复杂表单数据
- 案例一、处理标题与内容同行的数据表
- 案例二、处理标题与内容同单元格的数据表
- 文末总结
- Power BI 新书推荐
前言
数据处理是数据分析的奠基石,只有使用处理干净的数据,分析才会产生价值。简单而言,数据处理的终极目的是将非结构化数据转换为结构化数据。虽然数据处理自身未必直接产生数据价值,但其过程往往相当耗时,因此如果无法高效完成数据整理任务,必将影响最终的数据分析进程。通过本文内容的学习能帮助大家进一步提高数据整理的能力和效率,达到事半功倍的效果。无论你在使用 Excel 或 Power BI,都可以用本文讲解的技巧。
使用 Power BI 处理结构化复杂表单数据
如何对标题与内容同行的表进行结构化处理?
如果对标题与内容同单元格的表处理?
在日常业务中经常遇到类似图1这种非结构化的数据报表,经过数据处理后,非结构化表将被转换为图2的结构化数据表。
本文将介绍两种常用的表单处理方法。

(图1,非结构化的原始数据表)

(图2,经过结构化处理的数据表)
案例一、处理标题与内容同行的数据表
以【文件夹】类型获取两个示例文件,再用Excel.Workbook函数提取表内容,为了行文方便,我们可以右击展开应用的步骤,选择【重命名】选项简化名称(此处改为GET),见图3。
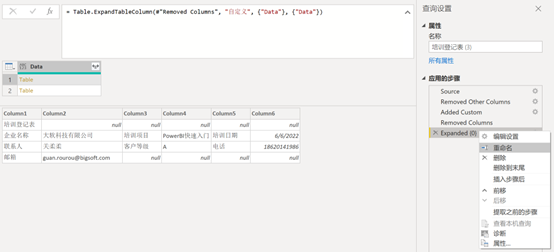
(图3,获取的非结构原始数据)
展示一个示例以方便读者理解,单击fx图标添加一个新步骤,然后添加以下M函数公式,代码的作用是获取GET步骤中的[Data]列数据,{0}代表第一个表,{Column2}{1}对应企业名字内容所在之处,见图4。
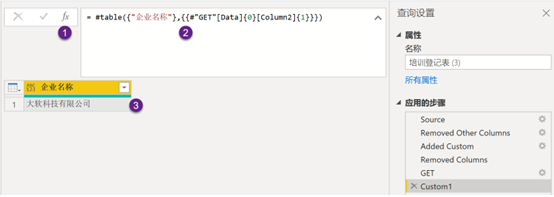
(图4,直接通过M函数获取对应的单元格信息)
#table({"企业名称"},{{#"GET"[Data]{0}[Column2]{1}}})
通过以上方法,便可按规律获取其他相对应字段信息,删除GET之后的步骤,点击【自定义列】选项并添加以下完整的M代码,代码中的 [Data]是对上一步中的相关列引用,用户可在快照中观察提取的数据内容,见图5。
#table(
{"企业名称","培训项目","培训日期","联系人","培训费用","电话","邮箱"},
{{
[Data][Column2]{1},[Data][Column4]{1},[Data][Column6]{1},[Data][Column2]{2},
[Data][Column4]{2},[Data][Column6]{2},[Data][Column2]{3}
}})
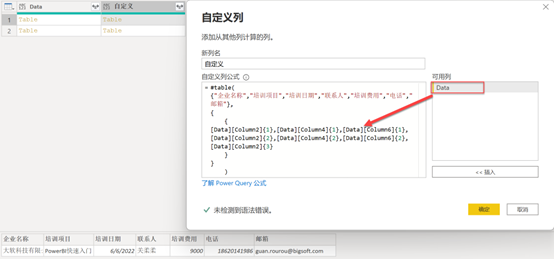
(图5,添加自定义列中的M公式)
生成自定义列后,我们便可以删除【Data】列,并将【自定义】列展开,见图 6。最终的结果见图 2。
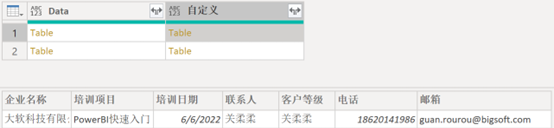
(图6,查看自定义列中的Table结构数据)
案例二、处理标题与内容同单元格的数据表
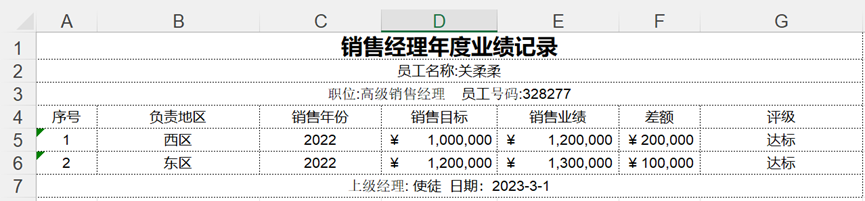
另外一种典型的非结构化表结构是标题与内容处于同一单元格中。 在图7中,行2和行3为合并单元格,本例介绍将员工数据进行结构化处理,见图8。解题思路是将表头与表身进行分别的处理,然后将它们合并。

与前面示例相似,我们以【文件夹】类型获取两个示例文件,这里的唯一特殊地方是我们会保持工作簿【Name】字段作为后边的合并之用,见图9。
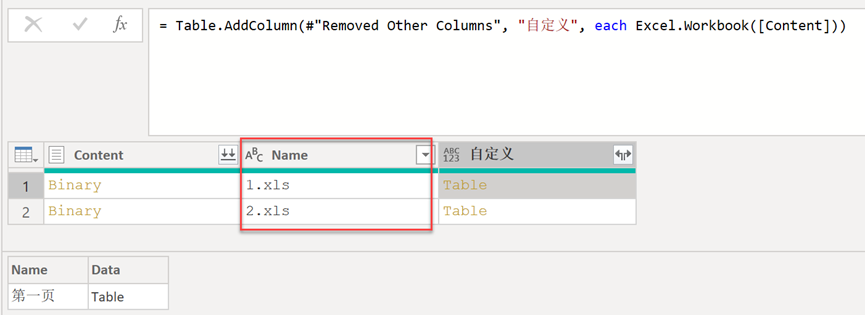
此处会把原来的表改名为【Body】,并进行复制并改名为【Headers】,见图10(读者可自行改名)。
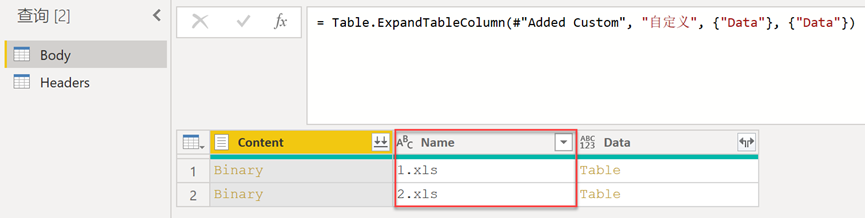
继续处理【Body】查询,为其添加【自定义列】并添加以下M函数公式,处理结果快照见图11。
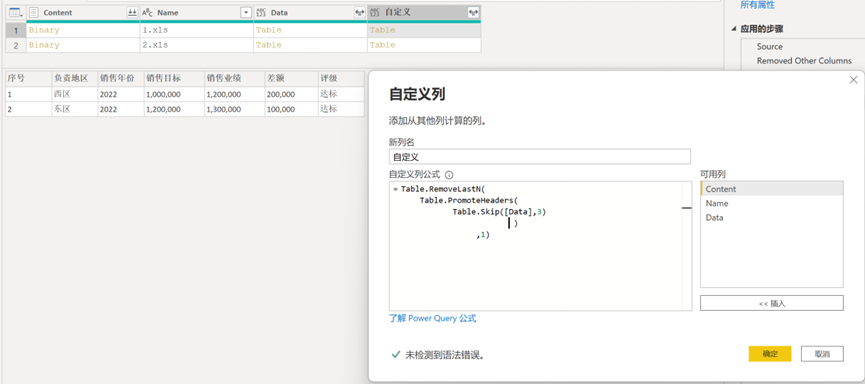
Table.RemoveLastN(Table.PromoteHeaders(Table.Skip([Data],3) ) ,1)
/*自定义列其实是有3个M函数的嵌套组合而成,最内侧Table.Skip表示将表头进行剔除、中间层的第2个Table.PromoteHeaders表示将表头提升、最外围的Table.RemoveLastN是去除第7行的冗余信息.*/
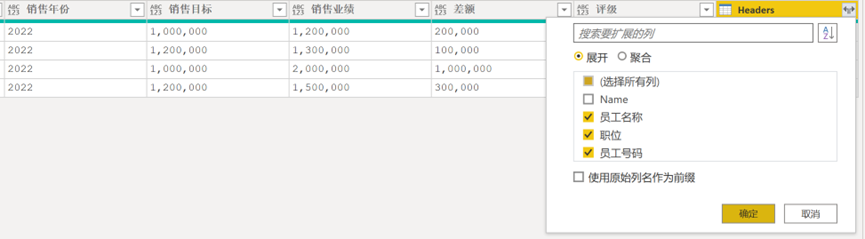
将自定义列展开并且保留始终保留【Name】字段,见图12。至此,已经完成了表身的数据处理。
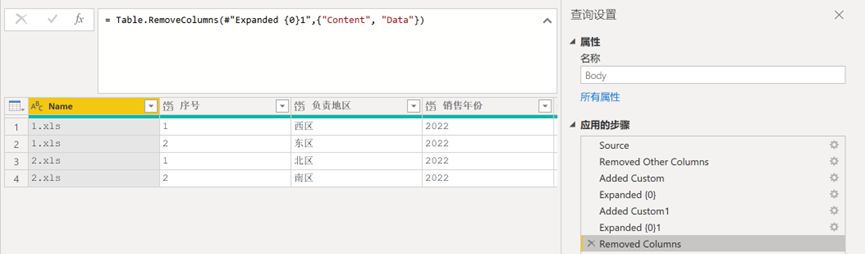
接下来我们要处理表头的数据,返回前面复制的【Headers】并选中该查询,为其添加【自定义列】,并添加以下M函数公式,见图13。
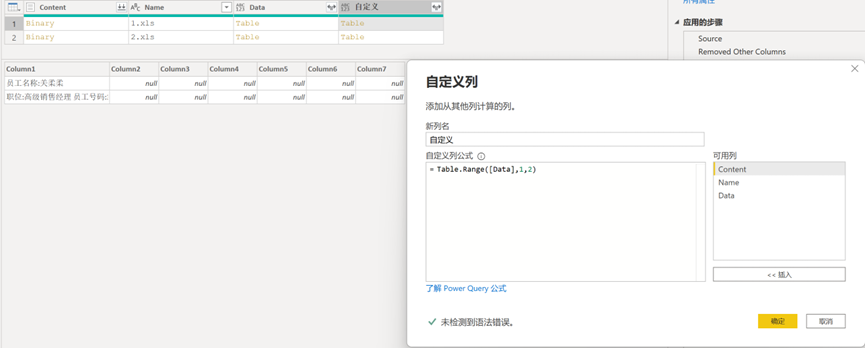
Table.Range([Data],1,2)
// 这段代码是提取Excel行2与行3的员工信息
提取完成后,展开【自定义列】,提取原表头的员工信息、职位、员工号码等信息,参考图 14仅保留相关列。
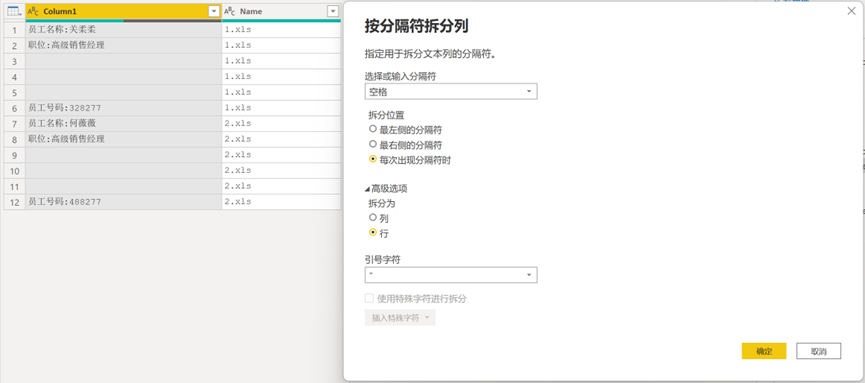
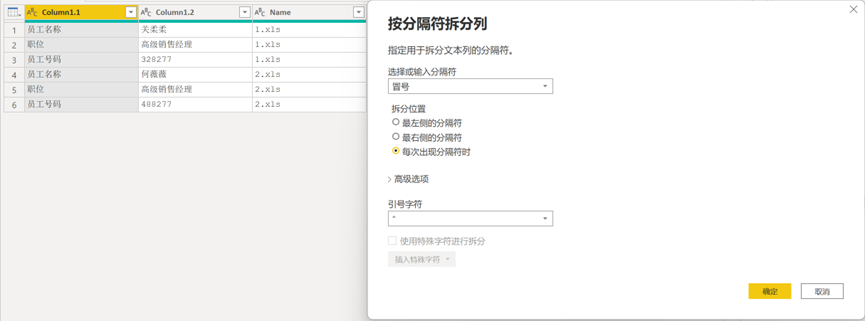
将【Column1】中所有的空值进行筛选后去除,然后进行【按分隔符拆分列】操作,分隔符为【冒号】,这样便将表头信息描述和具体信息名称拆分为两列了,见图 15。
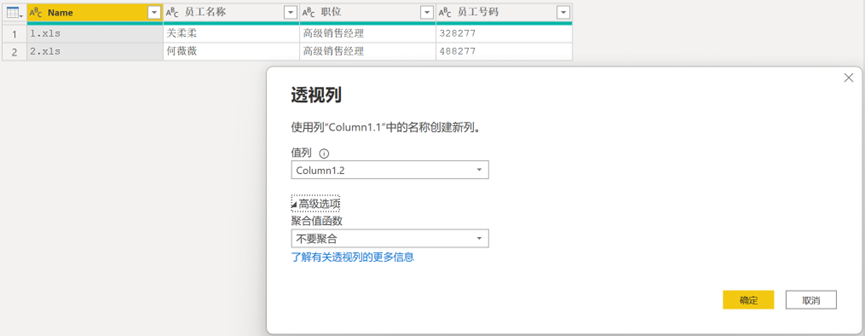
选中【Column1.1】,并对其进行透视操作,【聚合值函数】为【不要聚合】方式,单击【确定】按钮,结果见图 16。至此,完成了对表头的数据处理。
依据【Name】字段,对两个表进行合并操作,在菜单中选择【合并查询】-【将查询合并为新查询】选项,见图17
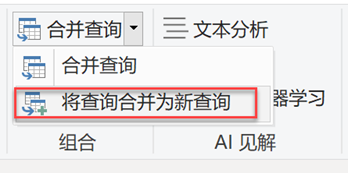
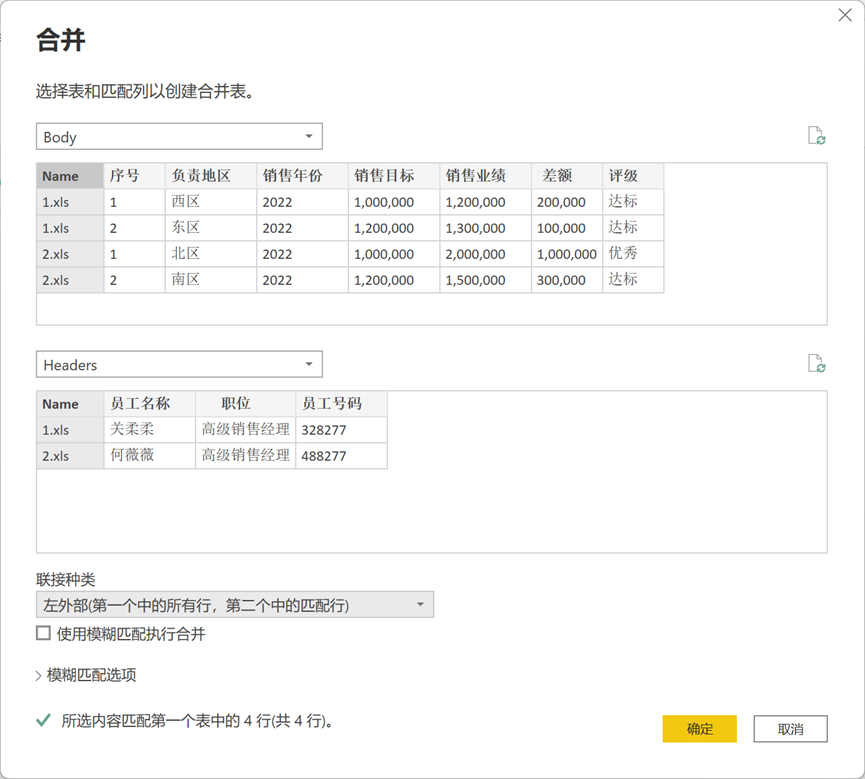
在【合并】对话框中分别选中【Body】和【Headers】中的【Name】字段,然后使用【左外部】联接种类,点击【确定】按钮,见图 18。
文末总结
在本文中,我们深入探讨了如何使用 Power BI 处理结构化复杂表单数据的方法。通过仔细分析和实际操作,我们学会了如何有效地处理标题与内容同行以及同单元格的数据表格。这些技术和方法对于从各种来源收集和整理数据都具有重要意义。通过充分利用 Power BI 提供的强大功能,我们可以更加灵活地处理数据,从而为业务决策提供更准确、可靠的支持。无论是处理大规模数据集还是解决复杂的数据结构,本文介绍的技巧都将帮助读者更好地应对数据处理的挑战。希望本文所提供的见解能够在实际应用中发挥积极作用,提升数据处理和分析的效率与质量。
Power BI 新书推荐
本文会抽出两位粉丝送出下面的 Power BI 好书
《征服Power BI:提升办公数字化能力的45个实战技巧》是一本关于 Power BI 进阶知识的实战类图书,将 Power BI 的主要功能融入45个高级应用技巧中,每个技巧都以解决实际商业分析或商业分析 BI 方案为导向。
官方购买链接:https://item.jd.com/13984280.html

本书将 Power BI 功能分为六大知识模块:数据处理模块介绍了将非结构化数据转换为结构化数据的相关方法;DAX 模型分析模块介绍了定义数据表之间的关系、创建度量和计算列,以及 DAX 建模等核心知识;可视化应用模块按类介绍了可视化对象个体,以及整体提升报表效果的方法;数据发布与共享模块介绍了分享数据流、数据集、数据市场,创建和管理指标、管道,创建多语言和视角等数据分享功能;Power Platform 与 Microsoft 365 集成模块介绍了 Power BI 与其他工具结合的应用案例;企业应用模块介绍了与 Power BI 报表开发相关的功能。
[ 本文作者 ] bluetata
[ 原文链接 ] https://bluetata.blog.csdn.net/article/details/132258964
[ 最后更新 ] 08/13/2023 16:00
[ 版权声明 ] 如果您在非 CSDN 网站内看到这一行,
说明网络爬虫可能在本人还没有完整发布的时候就抓走了我的文章,
可能导致内容不完整,请去上述的原文链接查看原文。