基于WIN10的64位系统演示
一、写在前面
由于不少模型使用的是Pytorch,因此这一期补上基于Pytorch实现CNN可视化的教程和代码,以SqueezeNet模型为例。
二、CNN可视化实战
继续使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)SqueezeNet建模
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as np
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
import os
# 数据集路径
data_dir = "./MTB"
# 图像的大小
img_height = 100
img_width = 100
# 数据预处理
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(img_height),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize((img_height, img_width)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 加载数据集
full_dataset = datasets.ImageFolder(data_dir)
# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占80%
val_size = full_size - train_size # 验证集的大小
# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])
# 将数据增强应用到训练集
train_dataset.dataset.transform = data_transforms['train']
# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes
###############################定义ShuffleNet模型################################
# 定义SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 这里以SqueezeNet 1.1版本为例
num_ftrs = model.classifier[1].in_channels
# 根据分类任务修改最后一层
model.classifier[1] = nn.Conv2d(num_ftrs, len(class_names), kernel_size=(1,1))
# 修改模型最后的输出层为我们需要的类别数
model.num_classes = len(class_names)
model = model.to(device)
# 打印模型摘要
print(model)
#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(model.parameters())
# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 开始训练模型
num_epochs = 20
# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每个epoch都有一个训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置模型为训练模式
else:
model.eval() # 设置模型为评估模式
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 零参数梯度
optimizer.zero_grad()
# 前向
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 只在训练模式下进行反向和优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()
# 记录每个epoch的loss和accuracy
if phase == 'train':
train_loss_history.append(epoch_loss)
train_acc_history.append(epoch_acc)
else:
val_loss_history.append(epoch_loss)
val_acc_history.append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
print()
# 保存模型
torch.save(model.state_dict(), 'squeezenet.pth')(b)可视化卷积神经网络的中间输出
import torch
from torchvision import models, transforms
import matplotlib.pyplot as plt
from torch import nn
from PIL import Image
# 定义图像的大小
img_height = 100
img_width = 100
# 1. 加载模型
model = models.squeezenet1_1(pretrained=False)
num_ftrs = model.classifier[1].in_channels
num_classes = 2
model.classifier[1] = nn.Conv2d(num_ftrs, num_classes, kernel_size=(1,1))
model.num_classes = num_classes
model.load_state_dict(torch.load('squeezenet.pth'))
model.eval()
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')
# 2. 加载图片并进行预处理
img = Image.open('./MTB/Tuberculosis/Tuberculosis-203.png')
transform = transforms.Compose([
transforms.Resize((img_height, img_width)),
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
img_tensor = transform(img).unsqueeze(0)
img_tensor = img_tensor.to('cuda' if torch.cuda.is_available() else 'cpu')
# 3. 提取前N层的输出
N = 25
activations = []
x = img_tensor
for i, layer in enumerate(model.features):
x = layer(x)
if i < N:
activations.append(x)
# 4. 将每个中间激活的所有通道可视化,但最多只显示前9个通道
max_channels_to_show = 9
for i, activation in enumerate(activations):
num_channels = min(max_channels_to_show, activation.shape[1])
fig, axs = plt.subplots(1, num_channels, figsize=(num_channels*2, 2))
for j in range(num_channels):
axs[j].imshow(activation[0, j].detach().cpu().numpy(), cmap='viridis')
axs[j].axis('off')
plt.tight_layout()
plt.show()
# 清空当前图像
plt.clf()结果输出如下:

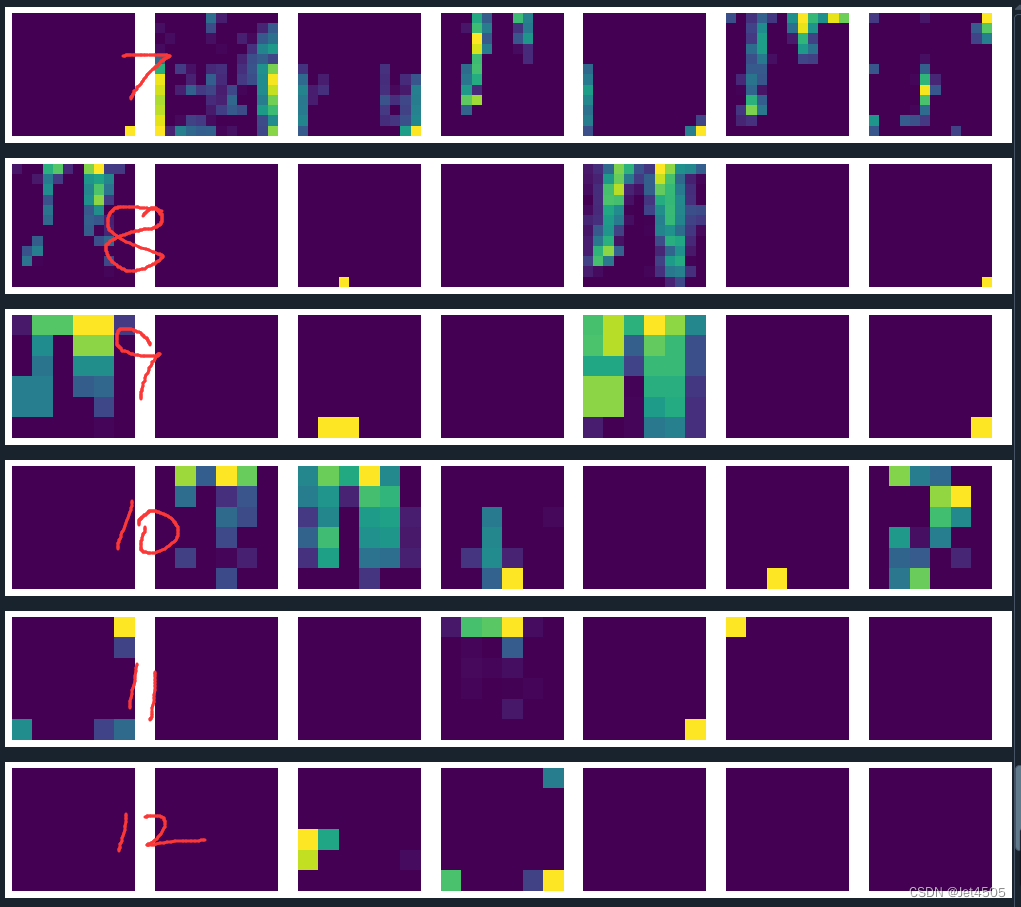

由于SqueezeNet只有13层,所以即使我们在代码中要求输出25层,那也只能输出13层。从第一层到最后一层,可以看到逐渐抽象化。
(c)可视化过滤器
import matplotlib.pyplot as plt
def visualize_filters(model):
# 获取第一个卷积层的权重
first_conv_layer = model.features[0]
weights = first_conv_layer.weight.data.cpu().numpy()
# 取绝对值以便于观察所有权重
weights = np.abs(weights)
# 归一化权重
weights -= weights.min()
weights /= weights.max()
# 计算子图网格大小
num_filters = weights.shape[0]
num_cols = 12
num_rows = num_filters // num_cols
if num_filters % num_cols != 0:
num_rows += 1
# 创建子图
fig, axs = plt.subplots(num_rows, num_cols, figsize=(num_cols*2, num_rows*2))
# 绘制过滤器
for filter_index, ax in enumerate(axs.flat):
if filter_index < num_filters:
ax.imshow(weights[filter_index].transpose(1, 2, 0))
ax.axis('off')
plt.tight_layout()
plt.show()
# 调用函数来显示过滤器
visualize_filters(model)这个更加抽象:

(d)Grad-CAM绘制特征热力图
import torch
from torchvision import models, transforms
from torch.nn import functional as F
from torch.autograd import Variable
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm
# 模型路径
model_path = 'squeezenet.pth'
# 图像路径
image_path = './MTB/Tuberculosis/Tuberculosis-203.png'
# 加载模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 创建一个SqueezeNet模型
model = models.squeezenet1_1(pretrained=False)
# 修改最后一层为二分类
model.classifier[1] = torch.nn.Conv2d(512, 2, kernel_size=(1,1), stride=(1,1))
# 这行代码用于在模型全连接层输出后添加一个softmax函数,使得模型输出可以解释为概率
model.num_classes = 2
model = model.to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.feature = None
self.gradient = None
# 定义钩子
self.hooks = self.target_layer.register_forward_hook(self.save_feature_map)
self.hooks = self.target_layer.register_backward_hook(self.save_gradient)
# 保存feature
def save_feature_map(self, module, input, output):
self.feature = output
# 保存梯度
def save_gradient(self, module, grad_in, grad_out):
self.gradient = grad_out[0]
# 计算权重
def compute_weight(self):
return F.adaptive_avg_pool2d(self.gradient, 1)
def remove_hooks(self):
self.hooks.remove()
def __call__(self, inputs, index=None):
self.model.zero_grad()
output = self.model(inputs)
if index == None:
index = np.argmax(output.cpu().data.numpy())
target = output[0][index]
target.backward()
weight = self.compute_weight()
cam = weight * self.feature
cam = cam.cpu().data.numpy()
cam = np.sum(cam, axis=1)
cam = np.maximum(cam, 0)
# 归一化处理
cam -= np.min(cam)
cam /= np.max(cam)
self.remove_hooks()
return cam
# 图像处理
img = Image.open(image_path).convert("RGB")
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
img_tensor = img_transforms(img)
img_tensor = img_tensor.unsqueeze(0).to(device)
# 获取预测类别
outputs = model(img_tensor)
_, pred = torch.max(outputs, 1)
pred_class = pred.item()
# 获取最后一个卷积层
target_layer = model.features[12]
# Grad-CAM
grad_cam = GradCAM(model=model, target_layer=target_layer)
# 获取输入图像的Grad-CAM图像
cam_img = grad_cam(img_tensor, index=pred_class)
# 重新调整尺寸以匹配原始图像
cam_img = Image.fromarray(np.uint8(255 * cam_img[0]))
cam_img = cam_img.resize((img.width, img.height), Image.BICUBIC)
# 将CAM图像转换为Heatmap
cmap = cm.get_cmap('jet')
cam_img = cmap(np.float32(cam_img))
# 将RGBA图像转换为RGB
cam_img = Image.fromarray(np.uint8(cam_img[:, :, :3] * 255))
cam_img = Image.blend(img, cam_img, alpha=0.5)
# 显示图像
plt.imshow(cam_img)
plt.axis('off') # 不显示坐标轴
plt.show()
print(pred_class)输出如下,分别是第一、二、六、十二层的卷积层的输出:
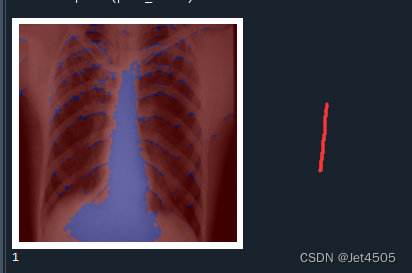
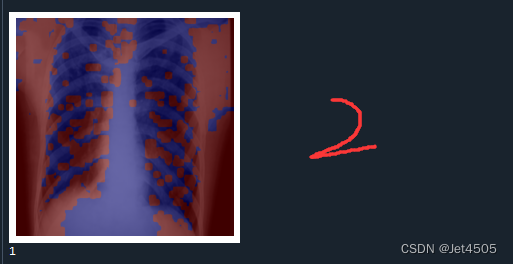

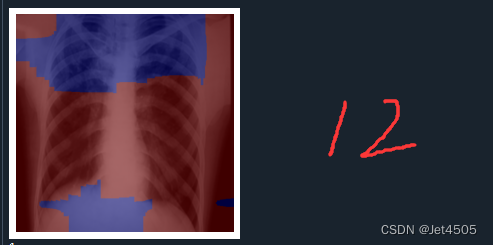
结果解读:
在Grad-CAM热图中,颜色的深浅表示了模型在做出预测时,对输入图像中的哪些部分赋予了更多的重要性。红色区域代表了模型认为最重要的部分,这些区域在模型做出其预测时起到了主要的决定性作用。而蓝色区域则是对预测贡献较少的部分。
具体来说:
红色区域:这些是模型在进行预测时,权重较高的部分。也就是说,这些区域对模型的预测结果影响最大。在理想情况下,这些区域应该对应于图像中的目标对象或者是对象的重要特征。
蓝色区域:这些是模型在进行预测时,权重较低的部分。也就是说,这些区域对模型的预测结果影响较小。在理想情况下,这些区域通常对应于图像的背景或无关信息。
这种可视化方法可以帮助我们理解卷积神经网络模型是如何看待图像的,也能提供一种评估模型是否正确关注到图像中重要部分的方法。
三、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf




![用友-NC-Cloud远程代码执行漏洞[2023-HW]](https://img-blog.csdnimg.cn/9b24f3fbde1a424aba649844ee6acecc.png)