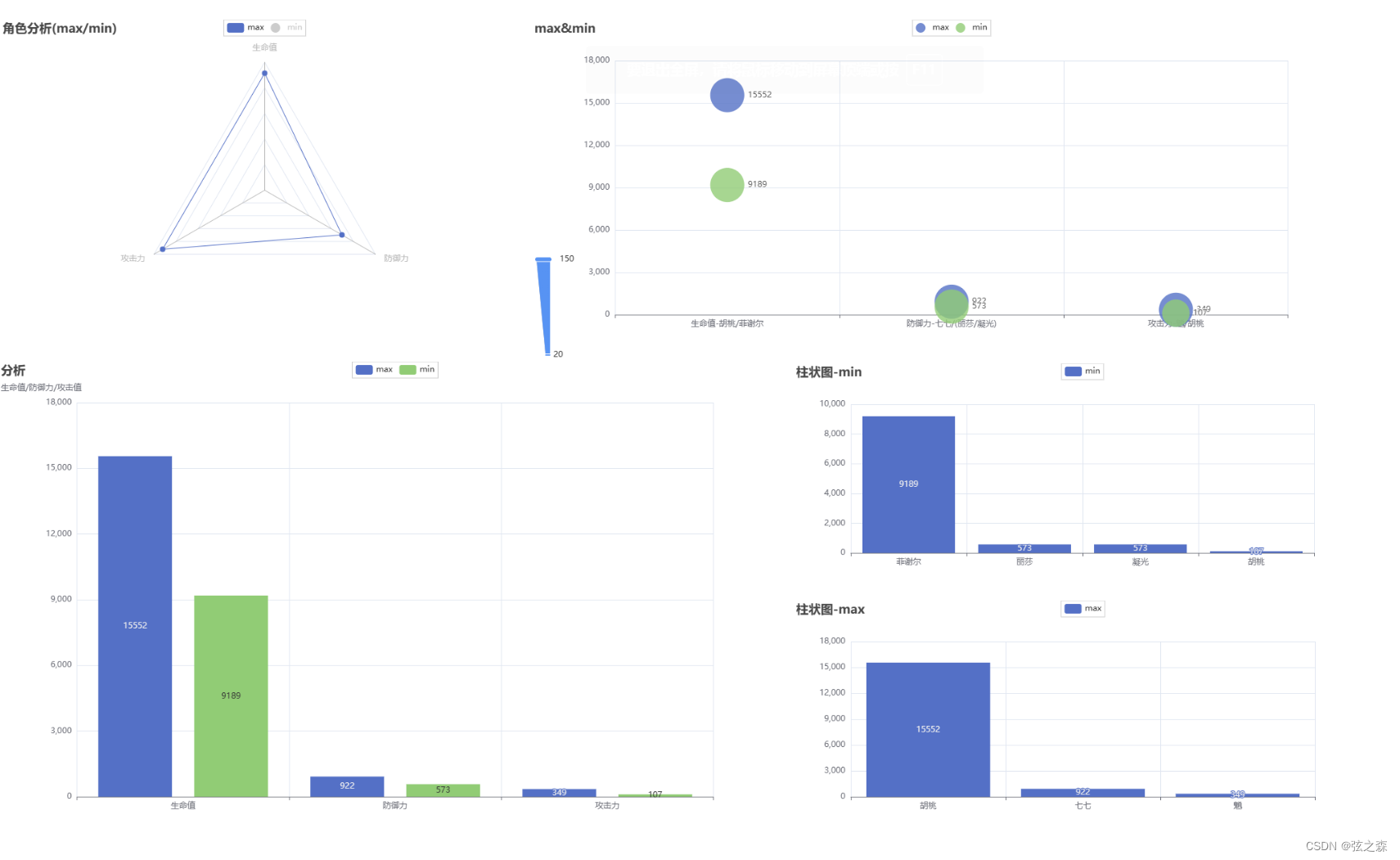
语义分割是一种将标签分配给每个像素的技术,广泛应用于场景理解、自动驾驶、人机交互、视频监控等领域。随着卷积神经网络的不断发展,研究人员提出了基于全卷积网络的语义分割算法,这些算法在语义分割任务中表现出良好的性能。


论文地址:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation (arxiv.org)
Github: https://github.com/CoinCheung/BiSeNet
Get Start
python tools/demo.py --config configs/bisenetv2_city.py --weight-path ./checkpoints/model_final_v2_city.pth --img-path ./456.png

训练自定义数据集
-
参考作者给的自定义数据格式, 生成自定义数据集.
Each line is a pair of training sample and ground truth image path, which are separated by a single comma ,munster_000002_000019_leftImg8bit.png,munster_000002_000019_gtFine_labelIds.png frankfurt_000001_07206_leftImg8bit.png,frankfurt_000001_079206_gtFine_labelIds.png -
configs中创建bisenetv2_test.py( 我的数据集其实是一个类别,加上背景是两个类别. )cfg = dict( model_type='bisenetv2', n_cats=2, # 加背景 num_aux_heads=4, lr_start=5e-3, weight_decay=1e-4, warmup_iters=1000, max_iter=80000, dataset='TestDataset', # 关联 lib/data/ im_root='./datasets/test', train_im_anns='./datasets/test/train.txt', val_im_anns='./datasets/test/val.txt', scales=[0.75, 2.], cropsize=[640, 640], eval_crop=[640, 640], eval_scales=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75], ims_per_gpu=8, eval_ims_per_gpu=2, use_fp16=True, use_sync_bn=False, respth='./res', ) -
创建
lib/data/railway_dataset.py,TestData关联config中dataset, 运行check_dataset_info.py可以得到mean、std、ignore value…import lib.data.transform_cv2 as T from lib.data.base_dataset import BaseDataset import numpy as np class TestDataset(BaseDataset): def __init__(self, dataroot, annpath, trans_func=None, mode='train'): super(TestDataset, self).__init__( dataroot, annpath, trans_func, mode) self.lb_ignore = 255 self.n_cats = 2 # + 背景 self.lb_map = np.arange(256).astype(np.uint8) for i in range(256): if i == 0: self.lb_map[i] = 0 elif i == 229: self.lb_map[i] = 1 else: self.lb_map[i] = 255 # check_dataset.py 中计算 self.to_tensor = T.ToTensor( mean=(0.3974, 0.3863, 0.3898), # city, rgb std=(0.2112, 0.2148, 0.2115), ) -
get_dataloader.py中添加from lib.data.test_dataset import TestDatasetfrom lib.data.cityscapes_cv2 import CityScapes from lib.data.coco import CocoStuff from lib.data.ade20k import ADE20k from lib.data.customer_dataset import CustomerDataset from lib.data.test_dataset import TestDataset ... -
Train自定义数据集export CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 tools/train_amp.py --config ./configs/bisenetv2_test.py export CUDA_VISIBLE_DEVICES=0 torchrun --nproc_per_node=1 tools/train_amp.py --config ./configs/bisenetv2_test.py
END
以上差不多就是我训练全部过程了,如有不对,欢迎指正 , 最后感谢大佬的无私奉献。
Git: https://github.com/CoinCheung/BiSeNet