- 消息队列
- kafka基本介绍
- 基本概念
- 整体架构
- 高吞吐量实现
- 分区分段
- 顺序写磁盘
- 零拷贝技术
- DMA(Direct Memory Access)
- 传统传输
- 零拷贝传输
- 批量发送
消息队列
- 解耦合
耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
- 异步处理
异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可。
- 流量削峰
高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。
| kafka | rabbitmq | rocketmq | mysql | |
|---|---|---|---|---|
| 优点 | 是一个高吞吐量的消息队列系统,可以处理大量数据。支持实时数据存储和大规模数据处理。具有高度可靠性和可扩展性,可以轻松地扩展到更大的规模。 | 是一个相对简单的消息队列系统,易于使用和部署。支持多种消息协议,例如 AMQP、MQTT 和 STOMP 等。具有高度可靠性和可扩展性,可以轻松地扩展到更大的规模。 | RocketMQ 是一款由阿里巴巴开发的分布式流处理平台和消息队列软件。它支持多种消息协议和存储模式,可以处理大规模的数据事件。RocketMQ 具有高可靠性、高可用性和高性能的特点,可以在多个节点之间进行复制和负载均衡。 | 是一个非常流行的数据库系统,具有强大的查询和存储能力。支持事务处理和 ACID 属性 (原子性、一致性、隔离性和持久性)。可以存储大量数据,并且可以快速检索和更新数据。 |
| 对比 | 只支持主要的MQ功能,以高吞吐量闻名。并没有类似延迟队列,死信队列相关场景,吞吐量 百万级 | 支持多种消息模式和大规模场景,社区完善,吞吐量上不如kafka跟rocket。吞吐量 万级 | 支持分布式事务,mq的优点它几乎都有,最大的缺点:商业版收费。一些功能不对外提供。社区可能有突然黄掉的风险,吞吐量10万级 | 不适合处理大量并发请求,因为它的事务处理和 ACID 属性可能会限制其性能。 |
kafka基本介绍
基本概念
- Producer:消息生产者,向Kafka中发布消息的角色。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- zookeeper:动物管理员,负责配置管理、领导者选举、分布式协调和存储元数据等关键功能,以确保Kafka集群的稳定运行和一致性
整体架构
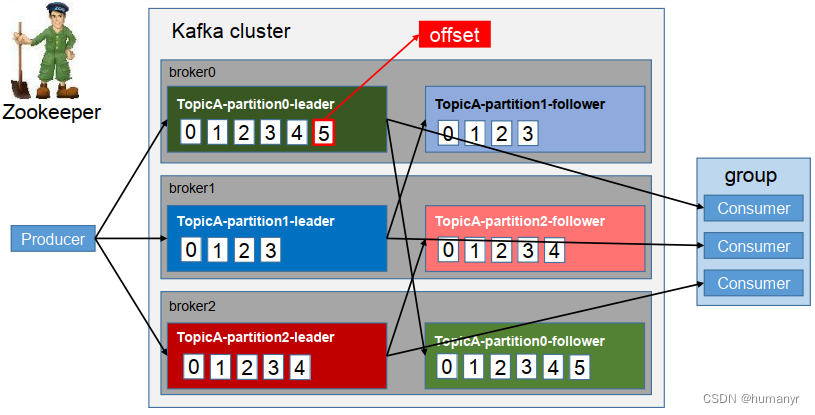

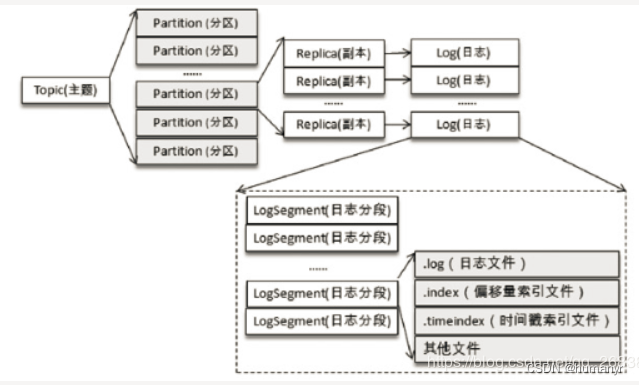
Topic是逻辑上的概念,Partition是物理上的概念,每个Partition对应着一个log文件,该log文件中存储的就是producer生产的数据,topic=N*partition;partition=log
offset是一个long型的数字,通过这个offset可以确定一条在该partition下的唯一消息。在partition下是保证有序的,但是在topic下面没有保证有序性
Producer生产的数据会被不断的追加到该log文件的末端,且每条数据都有自己的offset,consumer组中的每个consumer,都会实时记录自己消费到了哪个offset,以便出错恢复的时候,可以从上次的位置继续消费。流程:Producer => Topic(Log with offset)=> Consume
一个topic下有多个分区,类似于多路
生产者不断的向log文件追加消息文件,为了防止log文件过大导致定位效率低下,Kafka的log文件以1G为一个分界点,当.log文件大小超过1G的时候,此时会创建一个新的.log文件。
每个partition(目录)相当于一个巨型文件被平均分配到多个大小相等的segment(片段)数据文件中(每个segment文件中消息数量不一定相等),这种特性也方便old segment的删除,即方便已被消费的消息的清理,提高磁盘的利用率。每个partition只需要支持顺序读写就行,segment的文件生命周期由服务端配置参数(log.segment.bytes,log.roll.{ms,hours}等若干参数)决定
高吞吐量实现
分区分段
Kafka的队列被分为多个分区partition,每个partition又分为多个段segment。所以队列中的消息实际上是保存在N多个片段文件中。通过分段方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加并行处理能力。
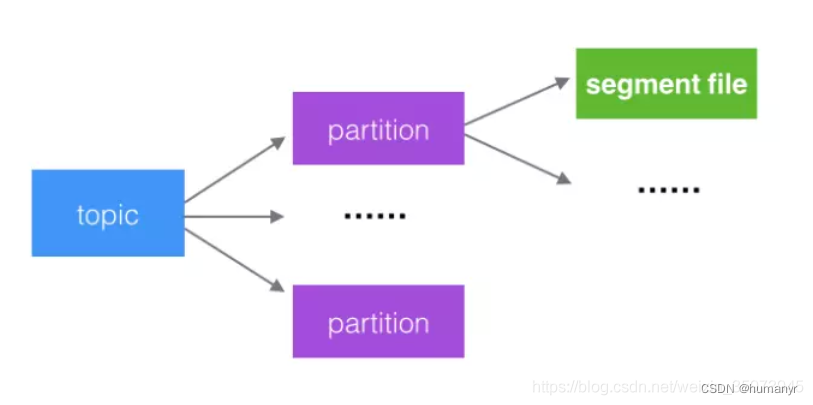
kafka中的topic中的内容可以被分为多个partition,每个partition又分为多段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力。
顺序写磁盘
Kafka的producer生产数据,需要写入到log文件中,写的过程是追加到文件末端,顺序写的方式,官网有数据表明,同样的磁盘,顺序写能够到600M/s,而随机写只有200K/s,这与磁盘的机械结构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
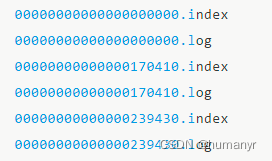
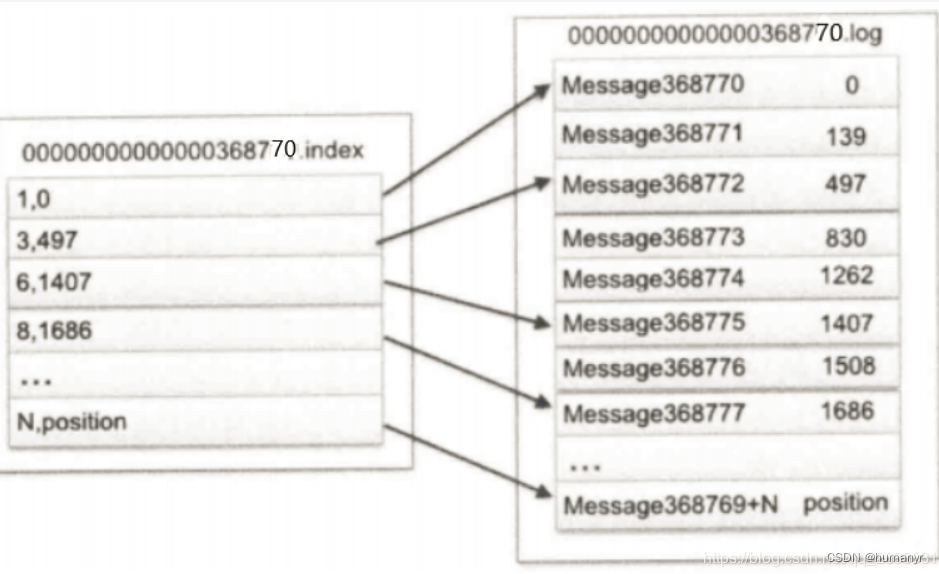
在Kafka中,每个主题都会被划分为多个分区。每个分区都有一个日志文件,用于存储该分区的消息。日志文件是一个追加写入的文件,当生产者发送消息到Kafka时,Kafka会将消息按照到达的顺序追加到对应分区的日志文件中。这种连续写入的方式就是顺序写。每个segment对应两个文件----“.index”和“.log”文件。分别表示为segment索引文件和数据文件(引入索引文件的目的就是便于利用二分查找快速定位message位置)。这两个文件的命名规则为:
partition全局的第一个segment从0开始,后续每个segment文件名以当前segment的第一条消息的offset命名,数值大小为64位,20位数字字符长度,没有数字用0填充。
这些文件位于一个文件夹下(partition目录),改文件夹的命名规则:topic名+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2
index和log文件
.index 索引文件存储大量的索引信息,.log数据文件存储大量消息数据(message),索引文件中的元数据指向对应数据文件中message的物理偏移地址。以index索引文件中的元数据3497为例,依次在数据文件中表示第三个message(在全局Partition中表示第368772个message),以及该消息的物理偏移地址为497
文件存储相关文章:https://blog.csdn.net/hyunbar/article/details/107588593
零拷贝技术
DMA(Direct Memory Access)
在正式介绍零拷贝结束(Zero-Copy)之前,我们先简单介绍一下DMA(Direct Memory Access)技术。DMA,又称之为直接内存访问,是零拷贝技术的基石。DMA 传输将数据从一个地址空间复制到另外一个地址空间。当CPU 初始化这个传输动作,传输动作本身是由 DMA 控制器来实行和完成。因此通过DMA,硬件则可以绕过CPU,自己去直接访问系统主内存。很多硬件都支持DMA,其中就包括网卡、声卡、磁盘驱动控制器等。
有了DMA技术的支持之后,网卡就可以直接区访问内核空间的内存,这样就可以实现内核空间和应用空间之间的零拷贝了,极大地提升传输性能。
传统传输
kafka中的消费者在读取服务端的数据时,需要将服务端的磁盘文件通过网络发送到消费者进程,网络发送需要经过几种网络节点。如下图所示:
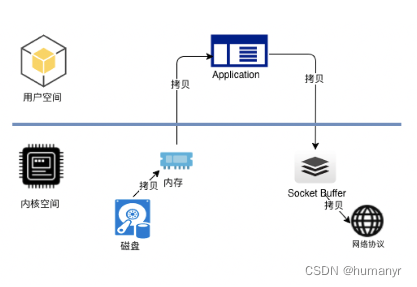
这是常规的读取操作:
- 操作系统将数据从磁盘文件中读取到内核空间的页面缓存
- 应用程序将数据从内核空间读入到用户空间缓冲区
- 应用程序将读到的数据写回内核空间并放入到socket缓冲区
- 操作系统将数据从socket缓冲区复制到网卡接口,此时数据通过网络发送给消费者
零拷贝传输
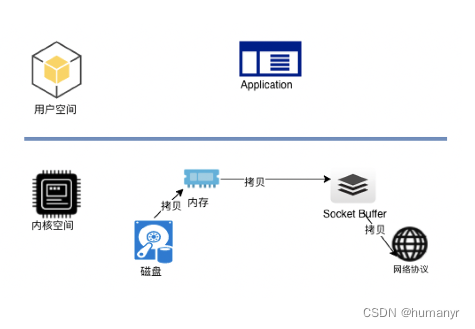
零拷贝技术只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),从而避免了重复复制的操作。
批量发送
kafka允许进行批量发送消息,producer发送消息的时候,可以将消息缓存在本地,等到固定条件再发送到kafka
- 消息条数满足固定条数
- 一段时间发送一次数据压缩
![2023年中国智慧公安行业发展现况及发展趋势分析:数据化建设的覆盖范围不断扩大[图]](https://img-blog.csdnimg.cn/img_convert/952a82a99c8e9866a06138f2228ad6af.png)








![[NOIP2003 普及组] 栈](https://img-blog.csdnimg.cn/img_convert/b8f7b8da75c169f7ba188bbd473ccbee.png)