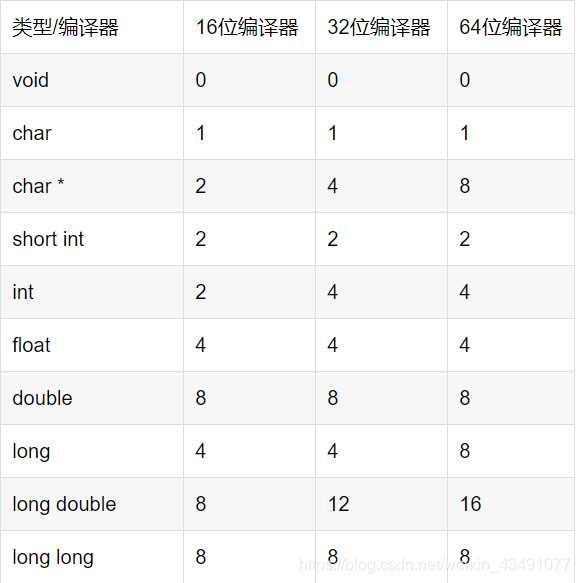
文章目录
- 写在前面
- 步骤
- 打开CSDN质量分页面
- 粘贴查询文章url
- 按F12打开调试工具,点击Network,点击清空按钮
- 点击查询
- 是调了这个接口`https://bizapi.csdn.net/trends/api/v1/get-article-score`
- 用postman测试调用这个接口(不行,认证不通过)
- 我查了一下,这种认证方式貌似是阿里云的API认证
- 这里有一篇巨好的参考文章
- 参考上面参考文章中的获取质量分java代码部分,用python代码实现获取博文质量分(可以成功查询)
- 读取我们上一篇文章中的博客列表articles.json,逐个获取质量分,最后把结果保存到processed_articles.json★★★
- 编写代码处理processed_articles.json,提取原创文章,根据url去重,并按质量分由小到大排序,生成original_sorted_articles.json★★★
- 编写代码统计original_sorted_articles.json中原创文章数量,计算平均质量分★★★
上一篇:1. 如何爬取自己的CSDN博客文章列表(获取列表)(博客列表)(手动+python代码方式)
写在前面
上一篇文章中,我们已经成功获取到了自己的CSDN已发布博文列表:
(articles.json)
本篇文章将实现获取每篇原创文章的质量分,并由小到大排序。
步骤
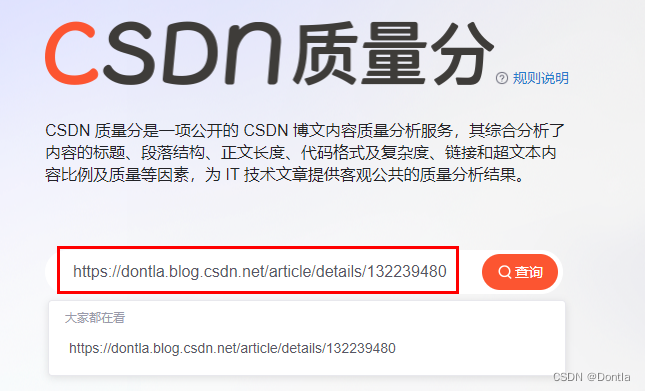
打开CSDN质量分页面
https://www.csdn.net/qc?utm_source=1966961068
粘贴查询文章url
按F12打开调试工具,点击Network,点击清空按钮
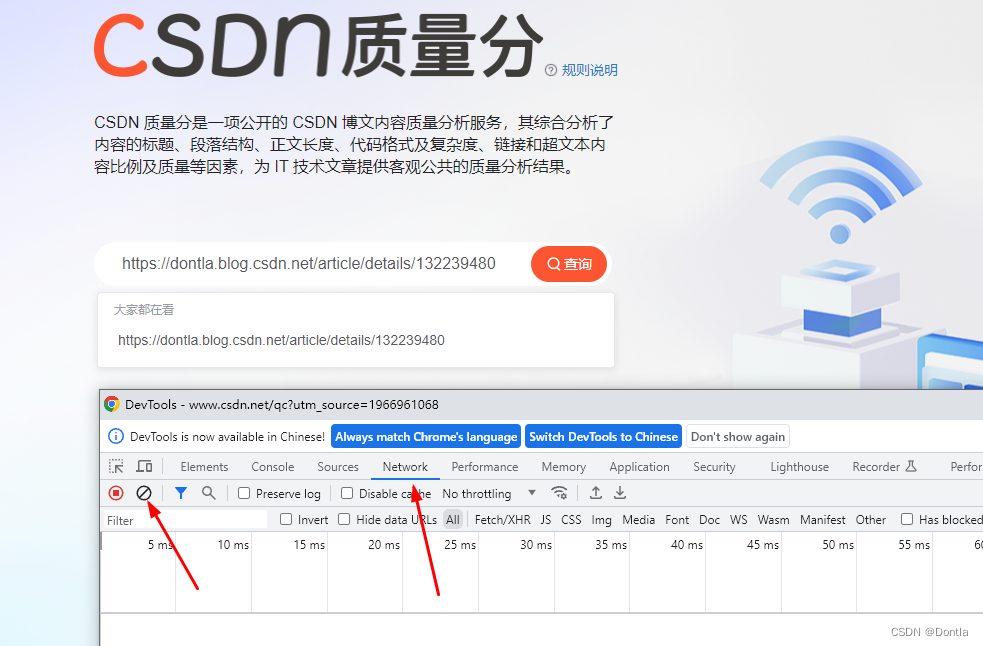
点击查询
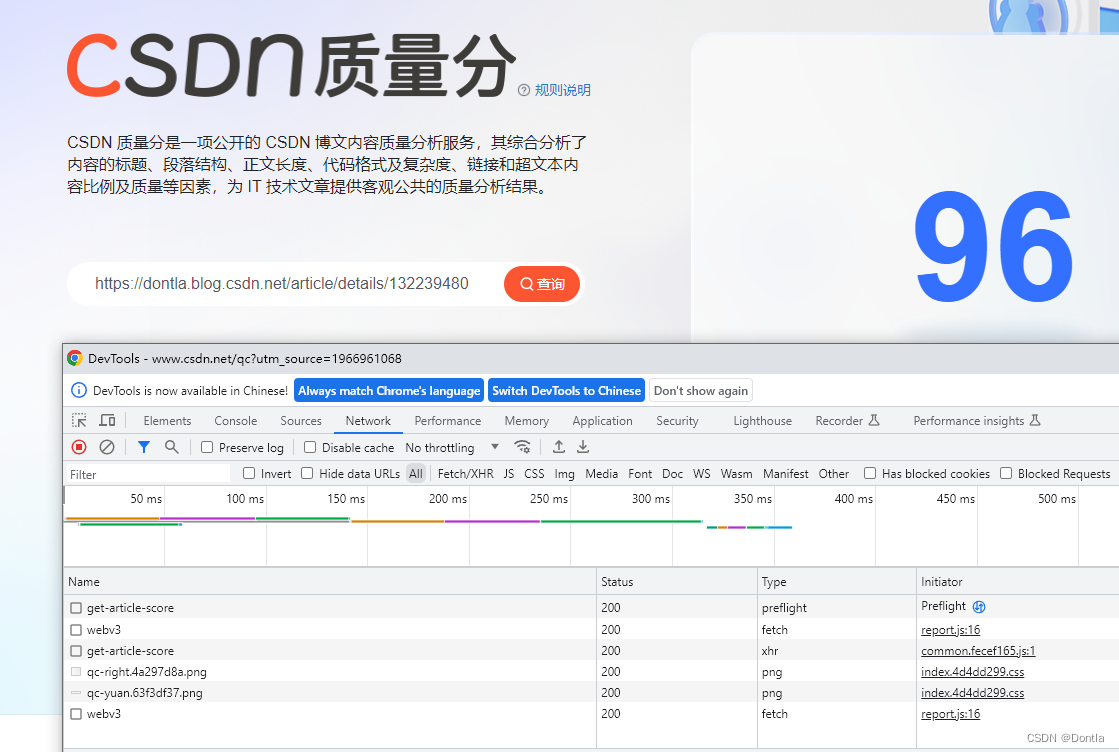
是调了这个接口https://bizapi.csdn.net/trends/api/v1/get-article-score
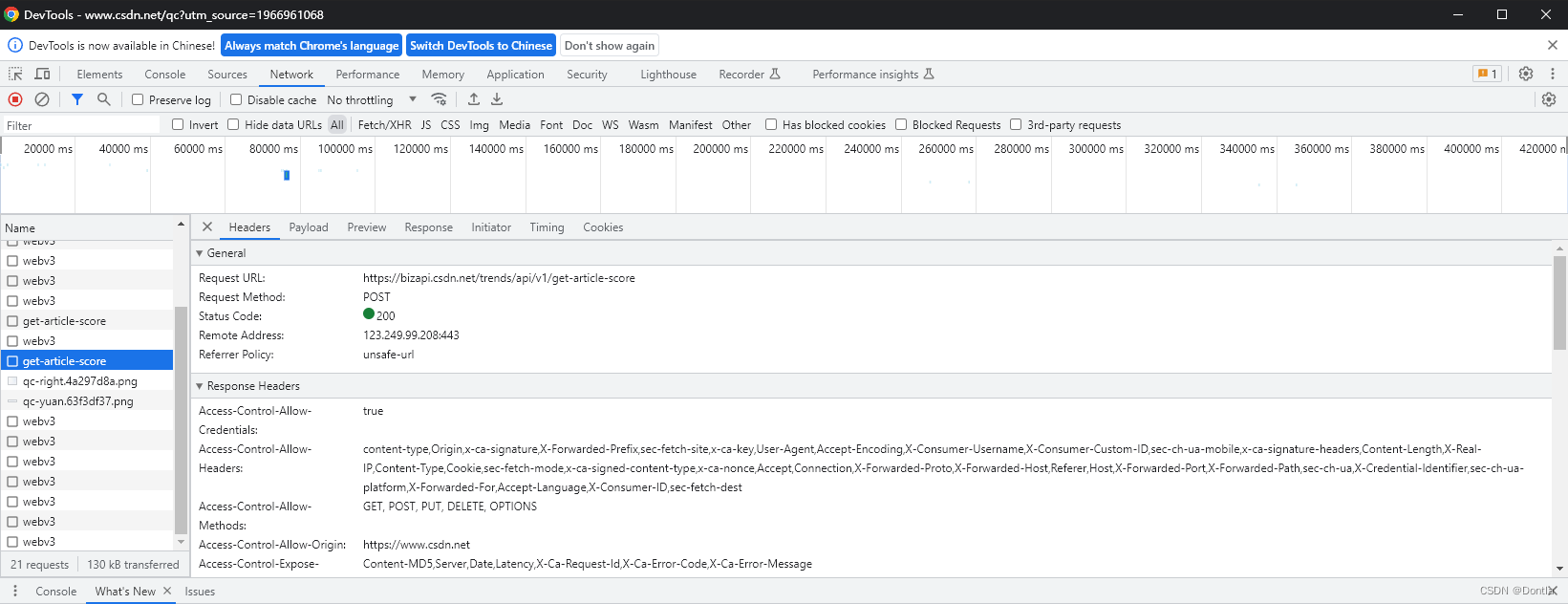
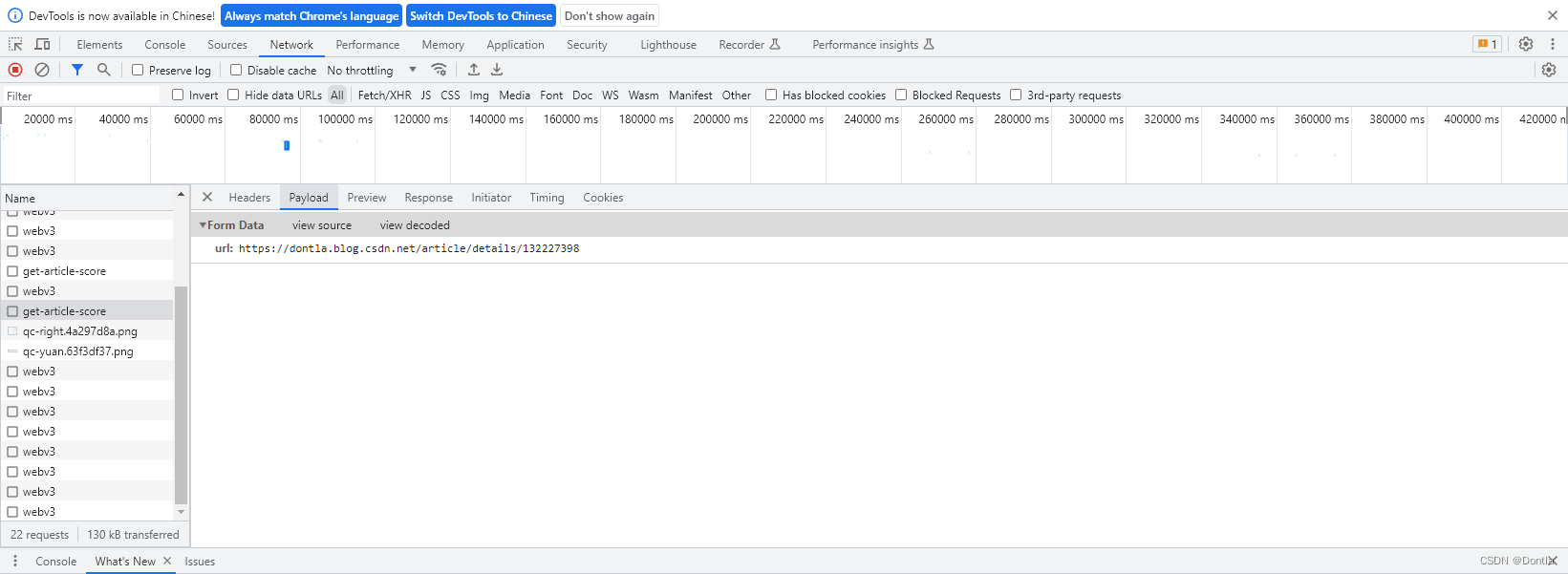
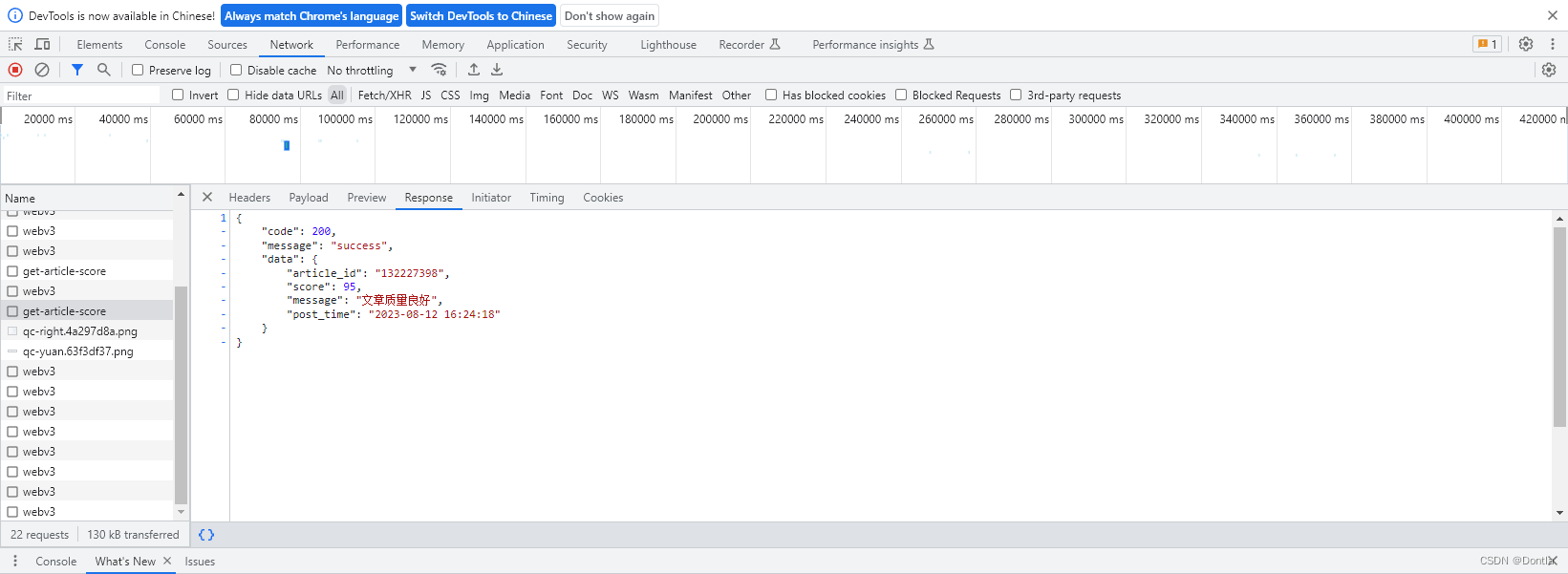
用postman测试调用这个接口(不行,认证不通过)
POST https://bizapi.csdn.net/trends/api/v1/get-article-score
{
"url": "https: //dontla.blog.csdn.net/article/details/132227398"
}
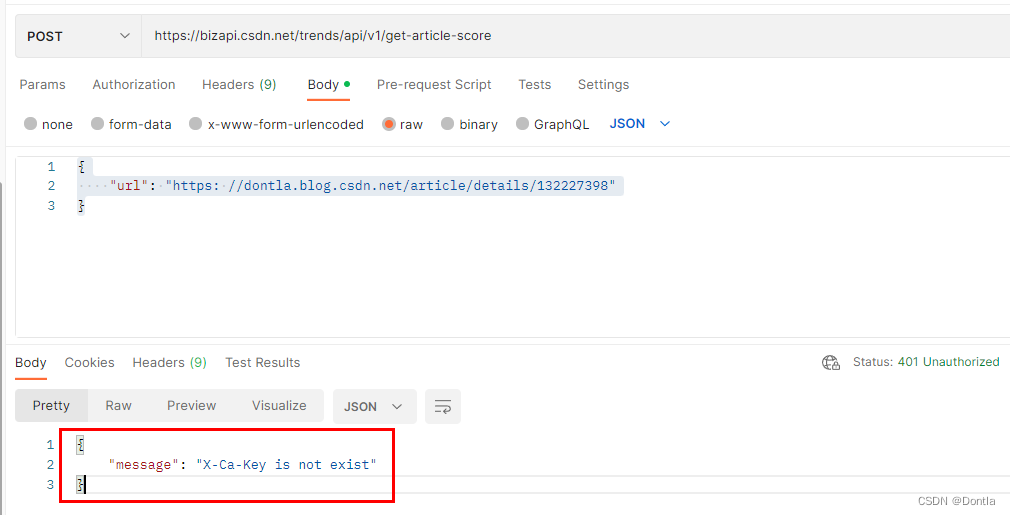
提示:
{
"message": "X-Ca-Key is not exist"
}
然后我把X-Ca-Key从浏览器复制下来,给它加到Headers参数里了:
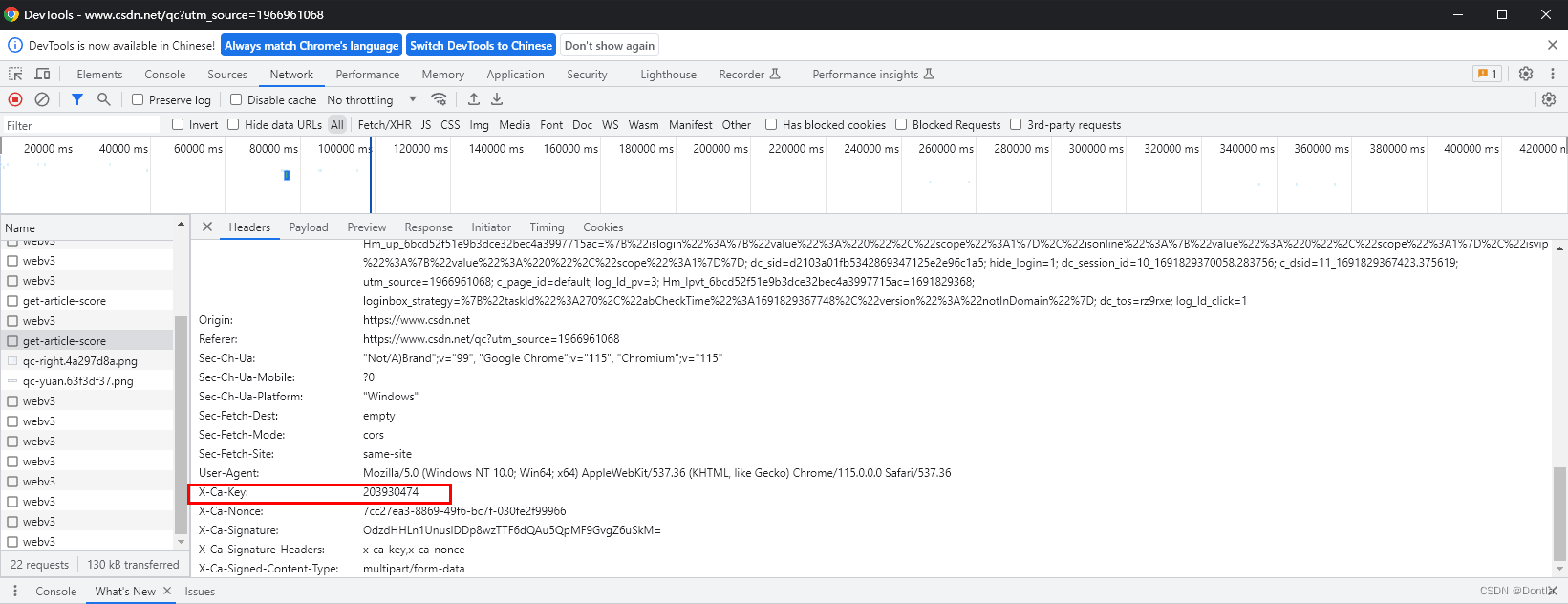
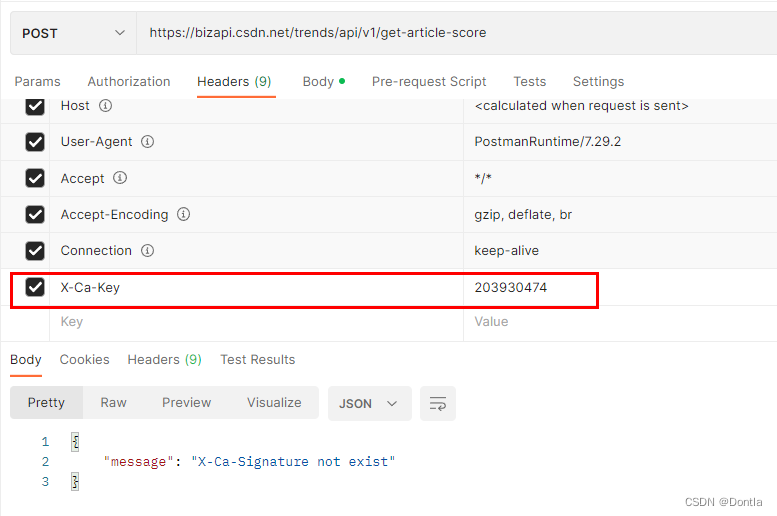
然后它又提示什么:
{
"message": "X-Ca-Signature not exist"
}
然后我故技重施,把那些提示缺少的东西统统从浏览器复制下来给它加上:
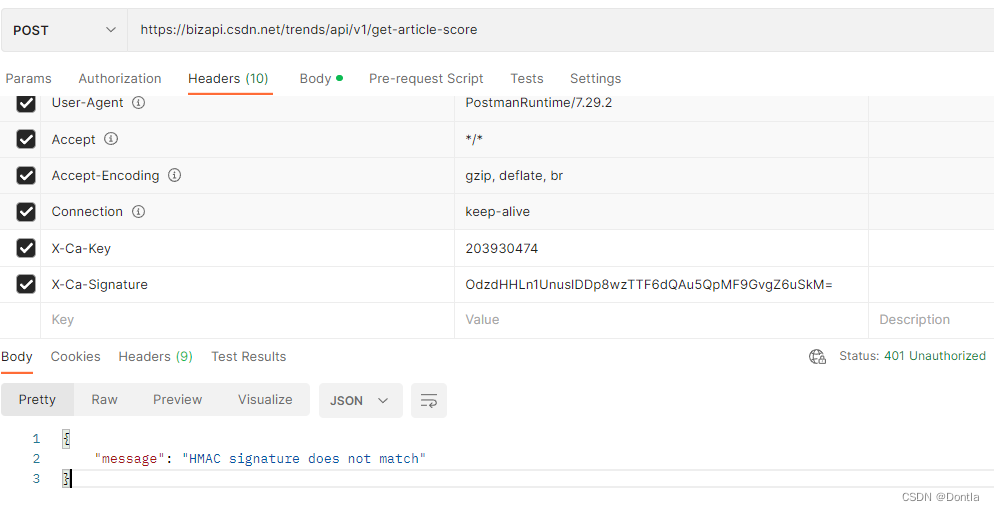
但是最后提示:
{
"message": "HMAC signature does not match"
}
这有点尴尬啊。。。
我查了一下,这种认证方式貌似是阿里云的API认证
有亿点复杂,一时半会搞不懂
这里有一篇巨好的参考文章
如何批量查询自己的CSDN博客质量分
参考上面参考文章中的获取质量分java代码部分,用python代码实现获取博文质量分(可以成功查询)
就是这一段:
// //循环调用csdn接口查询所有的博客质量分
String urlScore = “https://bizapi.csdn.net/trends/api/v1/get-article-score”;
//
//请求头
HttpHeaders headers = new HttpHeaders();
headers.set(“accept”,“application/json, text/plain, /”);
headers.set(“x-ca-key”,“203930474”);
headers.set(“x-ca-nonce”,“22cd11a0-760a-45c1-8089-14e53123a852”);
headers.set(“x-ca-signature”,“RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=”);
headers.set(“x-ca-signature-headers”,“x-ca-key,x-ca-nonce”);
headers.set(“x-ca-signed-content-type”,“multipart/form-data”);
headers.setContentType(MediaType.MULTIPART_FORM_DATA);
//调用接口获取数据
List scoreModels = new ArrayList<>();
for (String bkUrl : urlList) {
MultiValueMap<String,String> requestBody = new LinkedMultiValueMap<>();
requestBody.put(“url”, Collections.singletonList(bkUrl));
HttpEntity<MultiValueMap<String, String>> requestEntity = new HttpEntity<>(requestBody, headers);
URI uri = URI.create(urlScore);
ResponseEntity responseEntity = restTemplate.postForEntity(uri, requestEntity, String.class);
JSONObject data1 = JSON.parseObject(responseEntity.getBody(),JSONObject.class) ;
ScoreModel scoreModel = JSONObject.parseObject(data1.get(“data”).toString(),ScoreModel.class);
scoreModels.add(scoreModel);
System.out.println("名称: "+scoreModel.getTitle() +"分数: " + scoreModel.getScore() +"时间: " + scoreModel.getPost_time());
}
return scoreModels;
}
传入参数为urlList:
import requests
from requests.models import PreparedRequest
def get_score_models(url_list):
url_score = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
headers = {
"accept": "application/json, text/plain, */*",
"x-ca-key": "203930474",
"x-ca-nonce": "22cd11a0-760a-45c1-8089-14e53123a852",
"x-ca-signature": "RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=",
"x-ca-signature-headers": "x-ca-key,x-ca-nonce",
"x-ca-signed-content-type": "multipart/form-data"
}
score_models = []
for bk_url in url_list:
data = {"url": [bk_url]}
response = send_request(url_score, data, headers)
data1 = response.json()
print(data1)
'''
{
'code': 200,
'message': 'success',
'data': {
'article_id': '132240693',
'score': 95,
'message': '文章质量良好',
'post_time': '2023-08-12 17: 45: 24'
}
}
'''
score_model = data1["data"]
score_models.append(score_model)
print(
f'文章Id:{score_model["article_id"]}\n分数:{score_model["score"]}\n文章质量:{score_model["message"]}\n发布时间:{score_model["post_time"]}')
return score_models
def send_request(url, data, headers):
session = requests.Session()
prepared_request = PreparedRequest()
prepared_request.prepare(method='POST', url=url,
headers=headers, data=data)
return session.send(prepared_request)
# 示例调用
urlList = ["https://dontla.blog.csdn.net/article/details/132240693"]
scoreModels = get_score_models(urlList)
上面的验证信息,我从那篇博客里搞来的,怎么生成的,我就搞不清楚了。。。
运行上面代码,能成功得到质量分信息:

读取我们上一篇文章中的博客列表articles.json,逐个获取质量分,最后把结果保存到processed_articles.json★★★
我们上一篇文章得到的articles.json是这样的:
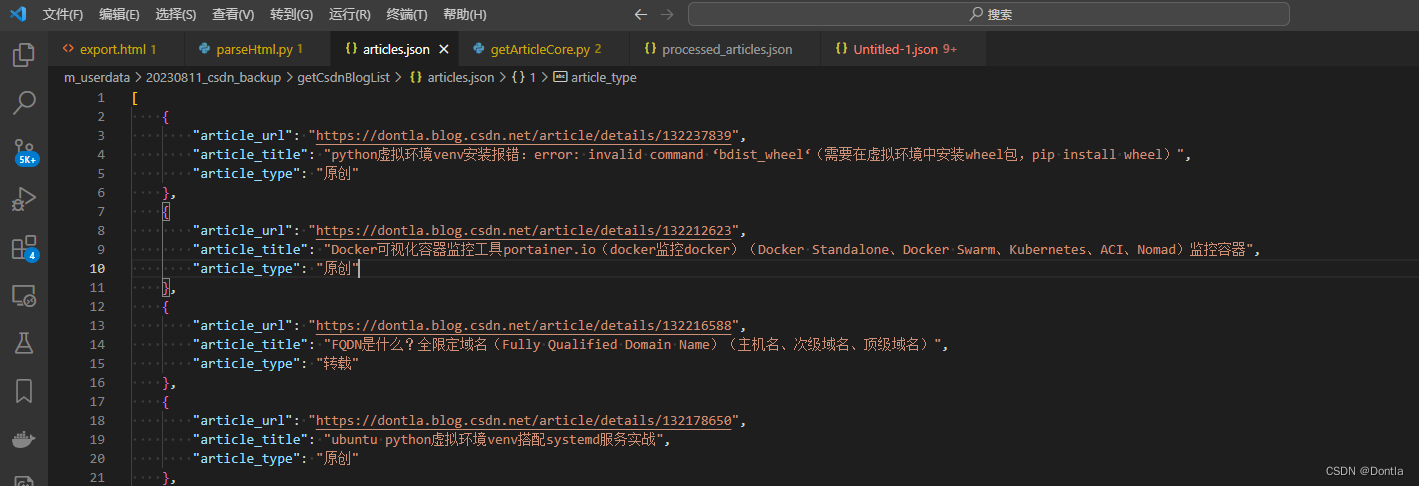
下面代码将读取它并逐个获取质量分:
(getArticleScore.py)
import requests
from requests.models import PreparedRequest
import json
def get_score_models(url):
url_score = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
headers = {
"accept": "application/json, text/plain, */*",
"x-ca-key": "203930474",
"x-ca-nonce": "22cd11a0-760a-45c1-8089-14e53123a852",
"x-ca-signature": "RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=",
"x-ca-signature-headers": "x-ca-key,x-ca-nonce",
"x-ca-signed-content-type": "multipart/form-data"
}
data = {"url": url}
response = send_request(url_score, data, headers)
data1 = response.json()
# print(data1)
'''
{
'code': 200,
'message': 'success',
'data': {
'article_id': '132240693',
'score': 95,
'message': '文章质量良好',
'post_time': '2023-08-12 17: 45: 24'
}
}
'''
score_model = data1["data"]
return score_model
def send_request(url, data, headers):
session = requests.Session()
prepared_request = PreparedRequest()
prepared_request.prepare(method='POST', url=url,
headers=headers, data=data)
return session.send(prepared_request)
def process_article_json():
# 读取articles.json文件
with open('articles.json', 'r') as f:
articles = json.load(f)
# 遍历每个元素并处理
for article in articles:
score_model = get_score_models(article['article_url'])
article['article_score'] = score_model['score']
print(article)
# 保存处理后的结果到新的JSON文件
output_file = 'processed_articles.json'
with open(output_file, 'w') as f:
json.dump(articles, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
process_article_json()
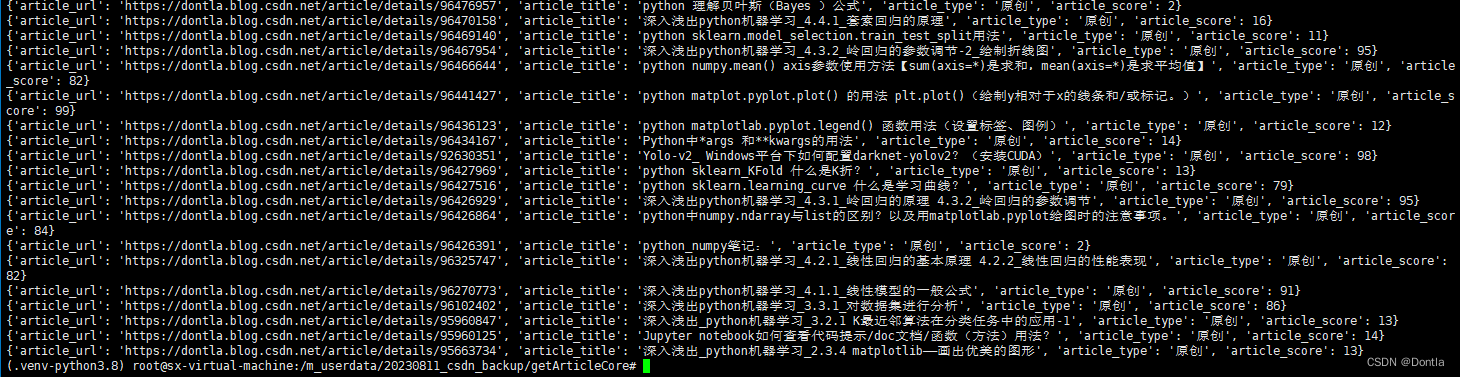
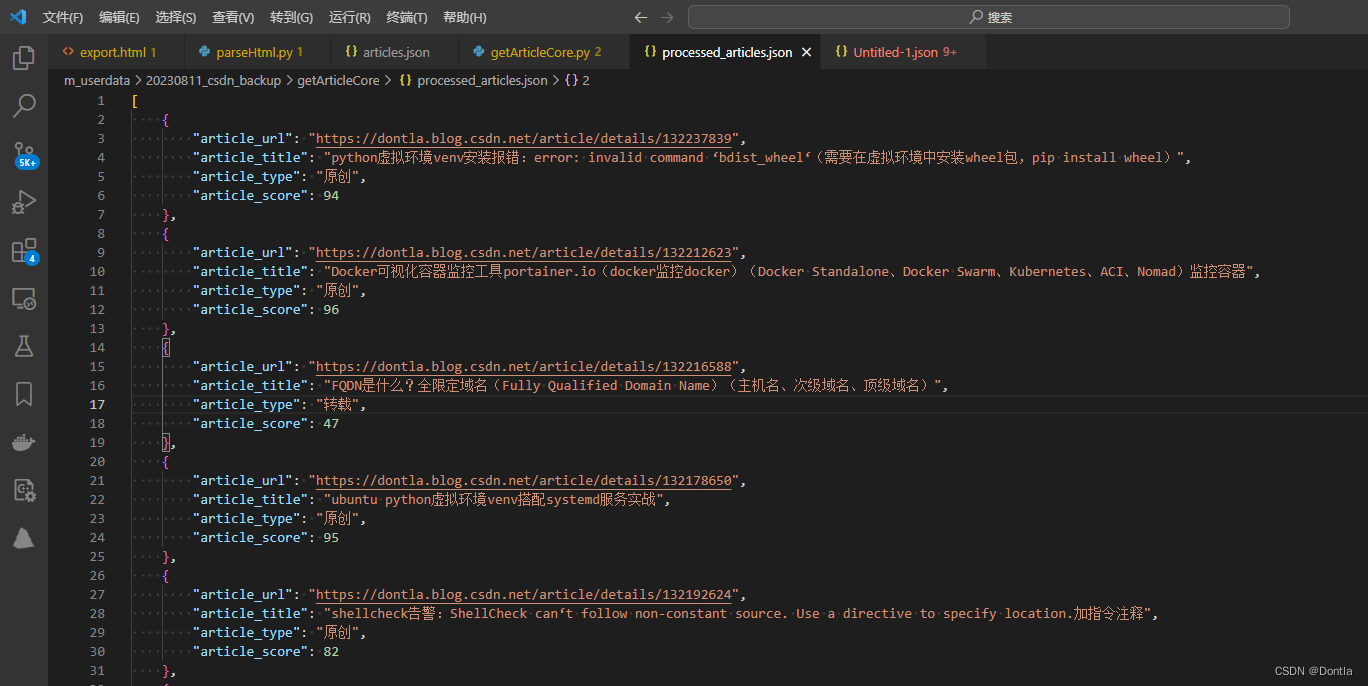
最终得到processed_articles.json:
编写代码处理processed_articles.json,提取原创文章,根据url去重,并按质量分由小到大排序,生成original_sorted_articles.json★★★
(getOriginalSort.py)
import json
# 读取JSON文件
with open('processed_articles.json', 'r') as f:
data = json.load(f)
# 过滤和排序数据,并去除重复的元素
filtered_data = []
seen_urls = set()
for article in data:
if article['article_type'] == '原创' and article['article_url'] not in seen_urls:
filtered_data.append(article)
seen_urls.add(article['article_url'])
sorted_data = sorted(filtered_data, key=lambda x: x['article_score'])
# 保存到新的JSON文件
with open('original_sorted_articles.json', 'w') as f:
json.dump(sorted_data, f, indent=4, ensure_ascii=False)
执行:
python3 getOriginalSort.py
生成文件original_sorted_articles.json:
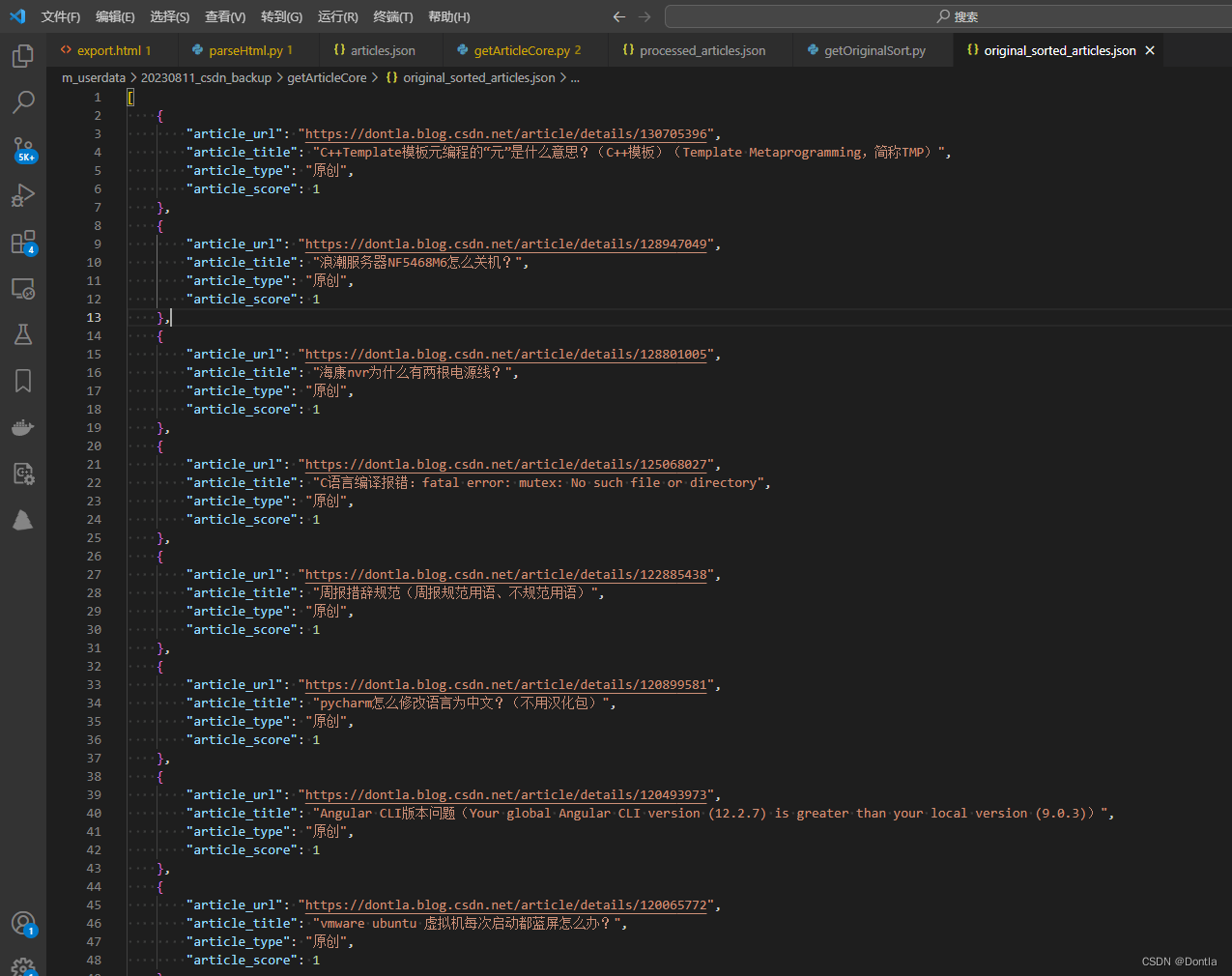
不看不知道,一看吓一跳啊,居然这么多一分的。。。心塞
编写代码统计original_sorted_articles.json中原创文章数量,计算平均质量分★★★
(getAverageScore.py)
import json
# 读取 JSON 文件
with open('original_sorted_articles.json', 'r') as file:
articles = json.load(file)
# 统计 article_score 并计算平均值
total_score = 0
num_articles = len(articles)
for article in articles:
total_score += article['article_score']
average_score = total_score / num_articles
# 打印结果
print(f"元素数量:{num_articles}")
print(f"平均 article_score:{average_score}")
# 保存结果到文本文件
with open('average_score_result.txt', 'w') as file:
file.write(f"元素数量:{num_articles}\n")
file.write(f"平均 article_score:{average_score}\n")

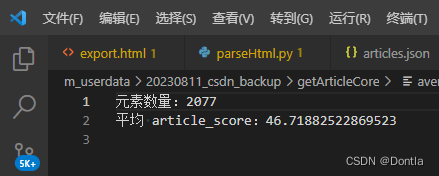
我去,这也太低了吧,客服咋给我算出60几分的,难道只统计最近一两年的?
唉,反正慢慢改吧。。。😔

![[静态时序分析简明教程(九)]多周期路径set_multicycle_path](https://img-blog.csdnimg.cn/ccb61d38eb154b0cb76cc342b2d54ebc.png)