文章目录
- 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。
- 1、使用Kafka原生API
- 1.1、创建spring工程
- 1.2、创建发布者
- 1.3、对生产者的优化
- 1.4、批量发送消息
- 1.5、创建消费者组
- 1.6 消费者同步手动提交
- 1.7、消费者异步手动提交
- 1.8、消费者同异步手动提交
- 2、SpringBoot Kafka
- 2.1、定义发布者
- 1、修改配置文件
- 2、定义发布者处理器
- 2.2、定义消费者
- 1、修改配置文件
- 2、定义消费者
首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。

1、使用Kafka原生API
1.1、创建spring工程
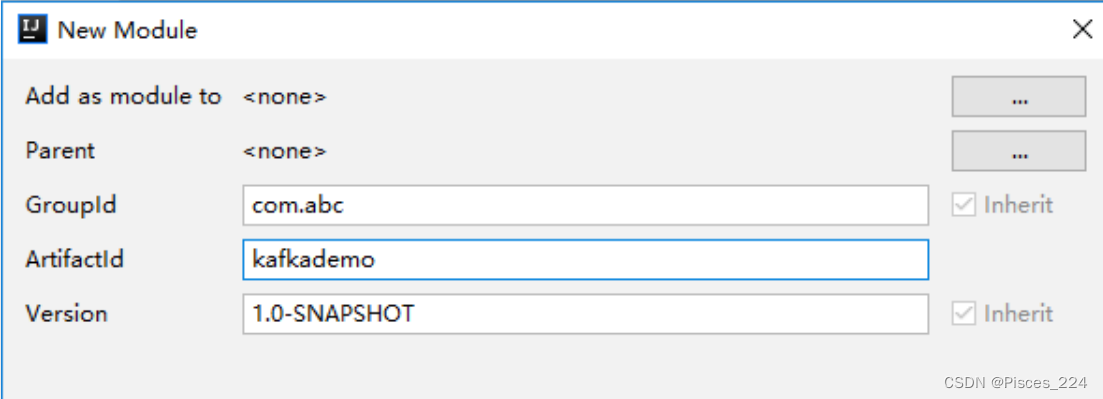
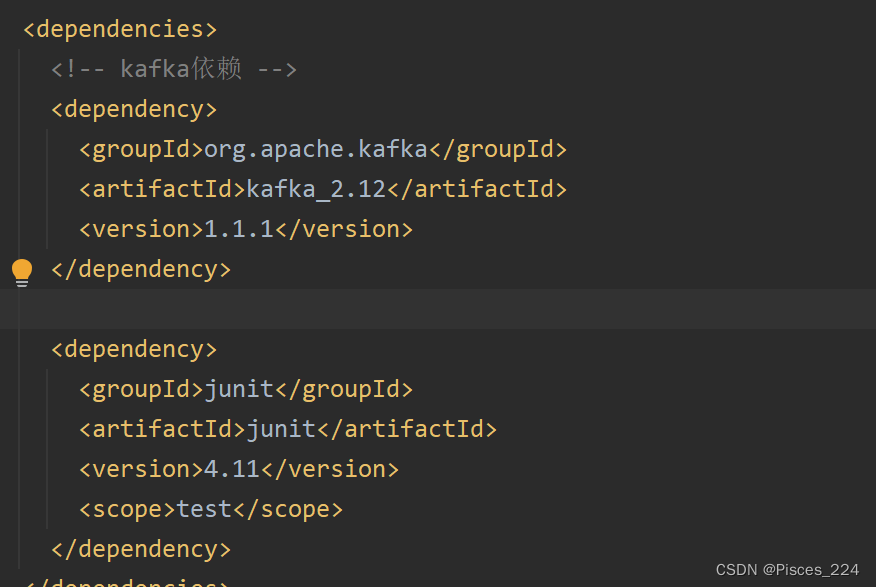
导入依赖:
1.2、创建发布者
先创建一个发布者类OneProsucer:
(注意需要配置一下ip主机名映射:添加映射)
public class OneProducer {
// 第一个泛型:当前生产者所生产消息的key
// 第二个泛型:当前生产者所生产的消息本身
private KafkaProducer<Integer, String> producer;
public OneProducer() {
Properties properties = new Properties();
// 指定kafka集群
properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
// 指定key与value的序列化器
properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
this.producer = new KafkaProducer<Integer, String>(properties);
}
public void sendMsg() {
// 创建消息记录(包含主题、消息本身) (String topic, V value)
// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "tianjin");
// 创建消息记录(包含主题、key、消息本身) (String topic, K key, V value)
// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin");
// 创建消息记录(包含主题、partition、key、消息本身) (String topic, Integer partition, K key, V value)
ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin");
producer.send(record);
}
}
注意代码中的字符串kafka都是有对应的常量的,这里便于理解用原生字符串来来写。
一般情况下,我们可能无法记住这些参数名。为此,Kafka的ProducerConfig类提供了一系列的参数常量。例如:
bootstrap.servers 可替换为 ProducerConfig.BOOTSTRAP_SERVERS_CONFIG
key.serializer 可替换为 ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG
value.serializer 可替换为 ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG
api生产的消息与命令行消息的区别:
参考:Kafka生产者
再创建一个测试类:
public class OneProducerTest {
public static void main(String[] args) throws IOException {
OneProducer producer = new OneProducer();
producer.sendMsg();
System.in.read();
}
}
xshell启动主题为cities的一个消费者:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.255.212:9092 --topic cities --from-beginning
启动生产者测试类生产消息:

查看linux端消费者,可以看到消息:

3台主机消费者都可以收到。
1.3、对生产者的优化
对于上一小节,有两个不舒服的点:
- 生产者端启动后控制台没有任何输出,只能通过看消费端消息才确认发送接收成功;
- 生产消息,指定分区的测试
这里可以使用回调方式,发送成功后,触发回调方法,生产端返回提示。
创建发布者类(修改senMsg方法):
public class TwoProducer {
// 第一个泛型:当前生产者所生产消息的key
// 第二个泛型:当前生产者所生产的消息本身
private KafkaProducer<Integer, String> producer;
public TwoProducer() {
Properties properties = new Properties();
// 指定kafka集群
properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
// 指定key与value的序列化器
properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
this.producer = new KafkaProducer<Integer, String>(properties);
}
public void sendMsg() {
// 创建消息记录(包含主题、消息本身) (String topic, V value)
// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "tianjin");
// 创建消息记录(包含主题、key、消息本身) (String topic, K key, V value)
// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin");
// 创建消息记录(包含主题、partition、key、消息本身) (String topic, Integer partition, K key, V value)
ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 2, 1, "tianjin");
producer.send(record, (metadata, ex) -> {
System.out.println("topic = " + metadata.topic());
System.out.println("partition = " + metadata.partition());
System.out.println("offset = " + metadata.offset());
});
}
}
创建测试类:
public class TwoProducerTest {
public static void main(String[] args) throws IOException {
TwoProducer producer = new TwoProducer();
producer.sendMsg();
System.in.read();
}
}
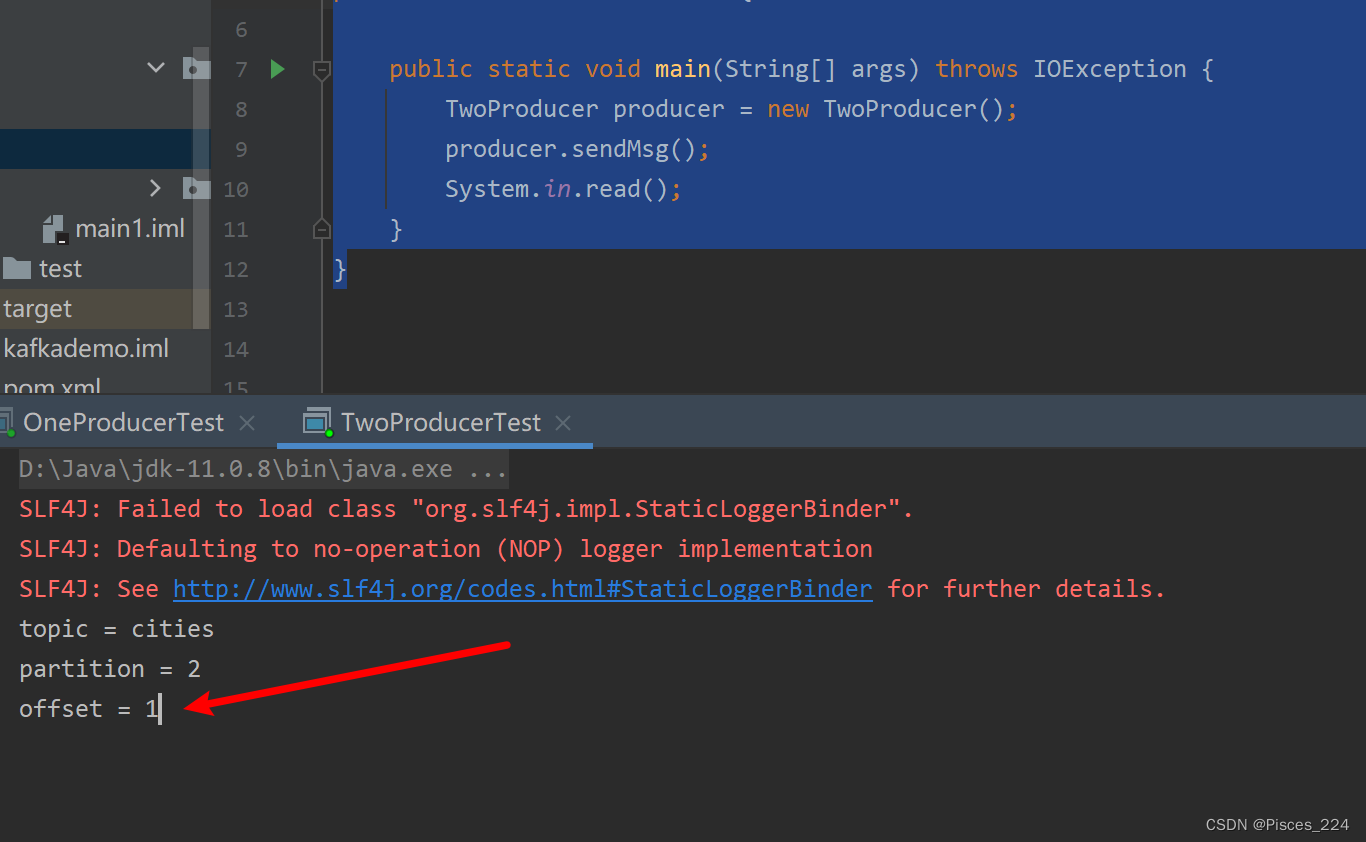
启动运行:
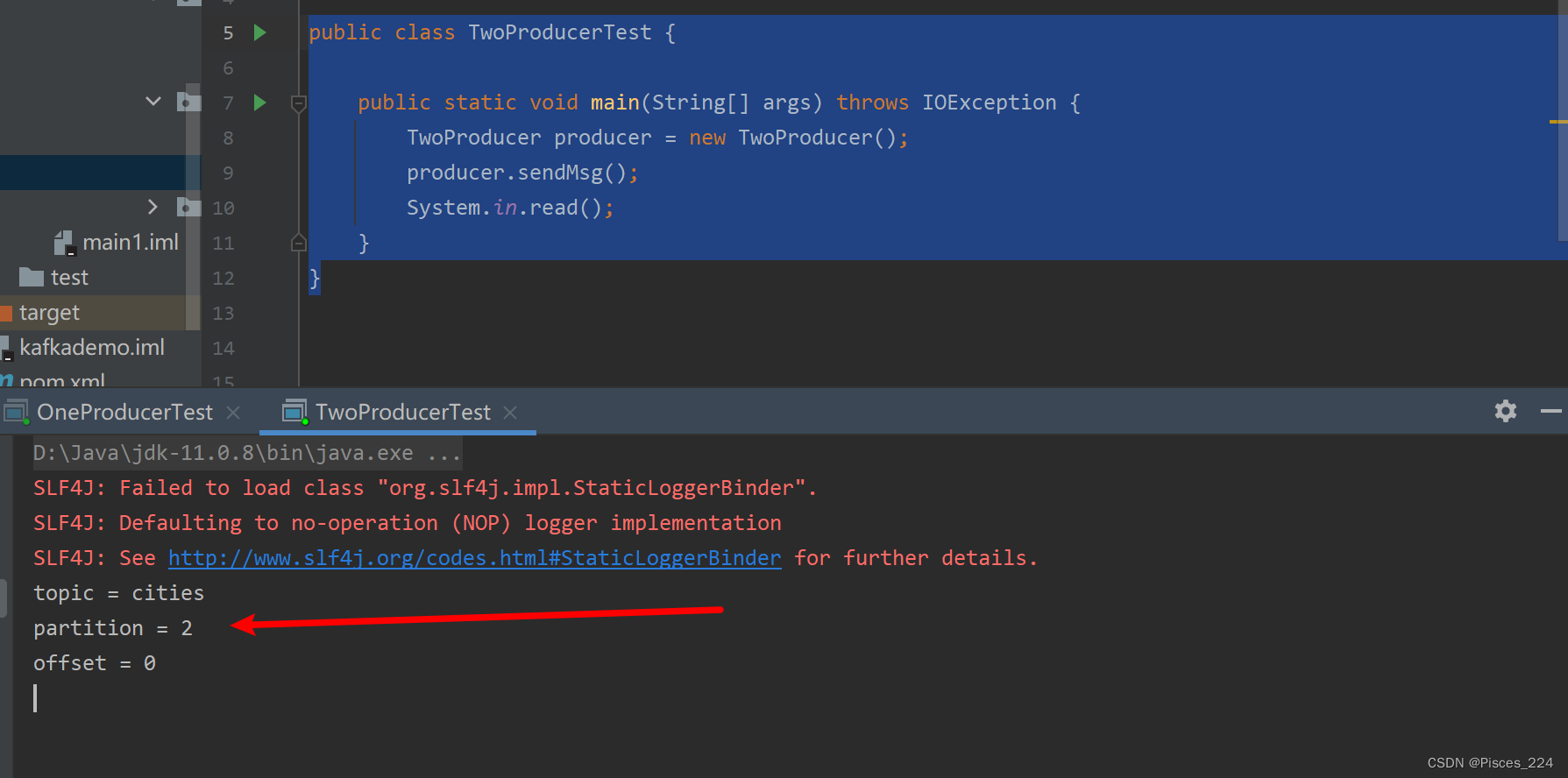
消费端:

再次生产消息,偏移量变为1:
但是到目前为止,生产者一次只能发送一条消息,接下来看生产者批量发送消息。
1.4、批量发送消息
创建发布者类:
public class SomeProducerBatch {
// 第一个泛型:当前生产者所生产消息的key
// 第二个泛型:当前生产者所生产的消息本身
private KafkaProducer<Integer, String> producer;
public SomeProducerBatch() {
Properties properties = new Properties();
// 指定kafka集群
properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
// 指定key与value的序列化器
properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 指定生产者每10条向broker发送一次
properties.put("batch.size", 10);
// 指定生产者每50ms向broker发送一次
properties.put("linger.ms", 50);
this.producer = new KafkaProducer<Integer, String>(properties);
}
public void sendMsg() {
for(int i=0; i<50; i++) {
ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "city-" + i);
int k = i;
producer.send(record, (metadata, ex) -> {
System.out.println("i = " + k);
System.out.println("topic = " + metadata.topic());
System.out.println("partition = " + metadata.partition());
System.out.println("offset = " + metadata.offset());
});
}
}
}
注意:
- batch.size
- lingger.ms
如果50ms没产生50条,时间到了也发消息。
创建一个测试类:
public class ProducerBatchTest {
public static void main(String[] args) throws IOException {
SomeProducerBatch producer = new SomeProducerBatch();
producer.sendMsg();
System.in.read();
}
}
本身send方法执行了50次,但是并不是每一次都发送,仅仅是生产了50条消息;发送是按照上面的设置每10条向broker发送一次或者每50ms发送一次。
(分区是轮询的):
i = 0
topic = cities
partition = 0
offset = 2
i = 3
topic = cities
partition = 0
offset = 3
i = 1
topic = cities
partition = 2
offset = 2
i = 4
topic = cities
partition = 2
offset = 3
i = 6
topic = cities
partition = 0
offset = 4
i = 9
topic = cities
partition = 0
offset = 5
i = 7
topic = cities
partition = 2
offset = 4
i = 10
topic = cities
partition = 2
offset = 5
i = 12
topic = cities
partition = 0
offset = 6
i = 15
topic = cities
partition = 0
offset = 7
i = 13
topic = cities
partition = 2
offset = 6
i = 16
topic = cities
partition = 2
offset = 7
i = 18
topic = cities
partition = 0
offset = 8
i = 21
topic = cities
partition = 0
offset = 9
i = 24
topic = cities
partition = 0
offset = 10
i = 27
topic = cities
partition = 0
offset = 11
i = 19
topic = cities
partition = 2
offset = 8
i = 22
topic = cities
partition = 2
offset = 9
i = 30
topic = cities
partition = 0
offset = 12
i = 33
topic = cities
partition = 0
offset = 13
i = 36
topic = cities
partition = 0
offset = 14
i = 39
topic = cities
partition = 0
offset = 15
i = 42
topic = cities
partition = 0
offset = 16
i = 45
topic = cities
partition = 0
offset = 17
i = 25
topic = cities
partition = 2
offset = 10
i = 28
topic = cities
partition = 2
offset = 11
i = 31
topic = cities
partition = 2
offset = 12
i = 34
topic = cities
partition = 2
offset = 13
i = 37
topic = cities
partition = 2
offset = 14
i = 40
topic = cities
partition = 2
offset = 15
i = 43
topic = cities
partition = 2
offset = 16
i = 46
topic = cities
partition = 2
offset = 17
i = 48
topic = cities
partition = 0
offset = 18
i = 49
topic = cities
partition = 2
offset = 18
i = 2
topic = cities
partition = 1
offset = 0
i = 5
topic = cities
partition = 1
offset = 1
i = 8
topic = cities
partition = 1
offset = 2
i = 11
topic = cities
partition = 1
offset = 3
i = 14
topic = cities
partition = 1
offset = 4
i = 17
topic = cities
partition = 1
offset = 5
i = 20
topic = cities
partition = 1
offset = 6
i = 23
topic = cities
partition = 1
offset = 7
i = 26
topic = cities
partition = 1
offset = 8
i = 29
topic = cities
partition = 1
offset = 9
i = 32
topic = cities
partition = 1
offset = 10
i = 35
topic = cities
partition = 1
offset = 11
i = 38
topic = cities
partition = 1
offset = 12
i = 41
topic = cities
partition = 1
offset = 13
i = 44
topic = cities
partition = 1
offset = 14
i = 47
topic = cities
partition = 1
offset = 15
linux端:
city-1
city-4
city-7
city-10
city-0
city-3
city-6
city-9
city-13
city-16
city-19
city-22
city-25
city-28
city-31
city-34
city-37
city-40
city-12
city-15
city-18
city-21
city-24
city-27
city-30
city-33
city-36
city-39
city-42
city-45
city-43
city-46
city-49
city-48
city-2
city-5
city-8
city-11
city-14
city-17
city-20
city-23
city-26
city-29
city-32
city-35
city-38
city-41
city-44
city-47
1.5、创建消费者组
消费者类:
public class SomeConsumer extends ShutdownableThread {
private KafkaConsumer<Integer, String> consumer;
public SomeConsumer() {
// 两个参数:
// 1)指定当前消费者名称
// 2)指定消费过程是否会被中断
super("KafkaConsumerTest", false);
Properties properties = new Properties();
String brokers = "kafka01:9092,kafka02:9092,kafka03:9092";
// 指定kafka集群
properties.put("bootstrap.servers", brokers);
// 指定消费者组ID
properties.put("group.id", "cityGroup1");
// 开启自动提交,默认为true
properties.put("enable.auto.commit", "true");
// 指定自动提交的超时时限,默认5s
properties.put("auto.commit.interval.ms", "1000");
// 指定消费者被broker认定为挂掉的时限。若broker在此时间内未收到当前消费者发送的心跳,则broker
// 认为消费者已经挂掉。默认为10s
properties.put("session.timeout.ms", "30000");
// 指定两次心跳的时间间隔,默认为3s,一般不要超过session.timeout.ms的 1/3
properties.put("heartbeat.interval.ms", "10000");
// 当kafka中没有指定offset初值时,或指定的offset不存在时,从这里读取offset的值。其取值的意义为:
// earliest:指定offset为第一条offset
// latest: 指定offset为最后一条offset
properties.put("auto.offset.reset", "earliest");
// 指定key与value的反序列化器
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.IntegerDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<Integer, String>(properties);
}
@Override
public void doWork() {
// 订阅消费主题
consumer.subscribe(Collections.singletonList("cities"));
// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。
// 0,表示没有消息什么也不返回
// >0,表示当时间到后仍没有消息,则返回空
ConsumerRecords<Integer, String> records = consumer.poll(1000);
for(ConsumerRecord record : records) {
System.out.println("topic = " + record.topic());
System.out.println("partition = " + record.partition());
System.out.println("key = " + record.key());
System.out.println("value = " + record.value());
}
}
}
测试类:
public class ConsumerTest {
public static void main(String[] args) {
SomeConsumer consumer = new SomeConsumer();
consumer.start();
}
}
启动运行,查看消费者控制台:
topic = cities
partition = 0
key = 1
value = tianjin
topic = cities
partition = 0
key = 1
value = tianjin
topic = cities
partition = 0
key = null
value = city-0
topic = cities
partition = 0
key = null
value = city-3
topic = cities
partition = 0
key = null
value = city-6
topic = cities
partition = 0
...
1.6 消费者同步手动提交
(1) 自动提交的问题
前面的消费者都是以自动提交 offset 的方式对 broker 中的消息进行消费的,但自动提交
可能会出现消息重复消费的情况。所以在生产环境下,很多时候需要对 offset 进行手动提交,
以解决重复消费的问题。
(2) 手动提交分类
手动提交又可以划分为同步提交、异步提交,同异步联合提交。这些提交方式仅仅是
doWork()方法不相同,其构造器是相同的。所以下面首先在前面消费者类的基础上进行构造
器的修改,然后再分别实现三种不同的提交方式。
创建创建消费者类 SyncManualConsumer:
-
A、原理
同步提交方式是,消费者向 broker 提交 offset 后等待 broker 成功响应。若没有收到响
应,则会重新提交,直到获取到响应。而在这个等待过程中,消费者是阻塞的。其严重影响
了消费者的吞吐量。 -
B、 修改构造器
直接复制前面的 SomeConsumer,在其基础上进行修改。
public class SyncManualConsumer extends ShutdownableThread {
private KafkaConsumer<Integer, String> consumer;
public SyncManualConsumer() {
// 两个参数:
// 1)指定当前消费者名称
// 2)指定消费过程是否会被中断
super("KafkaConsumerTest", false);
Properties properties = new Properties();
String brokers = "kafkaOS1:9092,kafkaOS2:9092,kafkaOS3:9092";
// 指定kafka集群
properties.put("bootstrap.servers", brokers);
// 指定消费者组ID
properties.put("group.id", "cityGroup1");
// 开启手动提交
properties.put("enable.auto.commit", "false");
// 指定自动提交的超时时限,默认5s
// properties.put("auto.commit.interval.ms", "1000");
// 指定一次提交10个offset
properties.put("max.poll.records", 10);
// 指定消费者被broker认定为挂掉的时限。若broker在此时间内未收到当前消费者发送的心跳,则broker
// 认为消费者已经挂掉。默认为10s
properties.put("session.timeout.ms", "30000");
// 指定两次心跳的时间间隔,默认为3s,一般不要超过session.timeout.ms的 1/3
properties.put("heartbeat.interval.ms", "10000");
// 当kafka中没有指定offset初值时,或指定的offset不存在时,从这里读取offset的值。其取值的意义为:
// earliest:指定offset为第一条offset
// latest: 指定offset为最后一条offset
properties.put("auto.offset.reset", "earliest");
// 指定key与value的反序列化器
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.IntegerDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<Integer, String>(properties);
}
@Override
public void doWork() {
// 订阅消费主题
consumer.subscribe(Collections.singletonList("cities"));
// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。
// 0,表示没有消息什么也不返回
// >0,表示当时间到后仍没有消息,则返回空
ConsumerRecords<Integer, String> records = consumer.poll(1000);
for(ConsumerRecord record : records) {
System.out.println("topic = " + record.topic());
System.out.println("partition = " + record.partition());
System.out.println("key = " + record.key());
System.out.println("value = " + record.value());
// 手动同步提交
consumer.commitSync();
}
}
}
创建测试类:
public class SyncManualTest {
public static void main(String[] args) {
SyncManualConsumer consumer = new SyncManualConsumer();
consumer.start();
}
}
1.7、消费者异步手动提交
(1) 原理
手动同步提交方式需要等待 broker 的成功响应,效率太低,影响消费者的吞吐量。异步提交方式是,消费者向 broker 提交 offset 后不用等待成功响应,所以其增加了消费者的吞吐量。
(2) 创建消费者类 AsyncManualConsumer
复制前面的 SyncManualConsumer 类,在其基础上进行修改。
public class AsynManualConsumer extends ShutdownableThread {
private KafkaConsumer<Integer, String> consumer;
public AsynManualConsumer() {
...
}
@Override
public void doWork() {
// 订阅消费主题
consumer.subscribe(Collections.singletonList("cities"));
// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。
// 0,表示没有消息什么也不返回
// >0,表示当时间到后仍没有消息,则返回空
ConsumerRecords<Integer, String> records = consumer.poll(1000);
for(ConsumerRecord record : records) {
System.out.println("topic = " + record.topic());
System.out.println("partition = " + record.partition());
System.out.println("key = " + record.key());
System.out.println("value = " + record.value());
// 手动异步提交
// consumer.commitAsync();
consumer.commitAsync((offsets, ex) -> {
if(ex != null) {
System.out.print("提交失败,offsets = " + offsets);
System.out.println(", exception = " + ex);
}
});
}
}
}
启动类:
public class AsyncManualTest {
public static void main(String[] args) {
AsynManualConsumer consumer = new AsynManualConsumer();
consumer.start();
}
}
1.8、消费者同异步手动提交
(1) 原理
同异步提交,即同步提交与异步提交组合使用。一般情况下,若偶尔出现提交失败,其
也不会影响消费者的消费。因为后续提交最终会将这次提交失败的 offset 给提交了。
但异步提交会产生重复消费,为了防止重复消费,可以将同步提交与异常提交联合使用。
(2) 创建消费者类 SyncAsyncManualConsumer
复制前面的 AsyncManualConsumer 类,在其基础上进行修改。
@Override
public void doWork() {
// 订阅消费主题
consumer.subscribe(Collections.singletonList("cities"));
// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。
// 0,表示没有消息什么也不返回
// >0,表示当时间到后仍没有消息,则返回空
ConsumerRecords<Integer, String> records = consumer.poll(1000);
for(ConsumerRecord record : records) {
System.out.println("topic = " + record.topic());
System.out.println("partition = " + record.partition());
System.out.println("key = " + record.key());
System.out.println("value = " + record.value());
consumer.commitAsync((offsets, ex) -> {
if(ex != null) {
System.out.print("提交失败,offsets = " + offsets);
System.out.println(", exception = " + ex);
// 同步提交
consumer.commitSync();
}
});
}
}
2、SpringBoot Kafka
新建一个简单案例,将发布者和订阅者定义到一个工程中。
创建一个SpringBoot工程,pom.xml添加如下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2.1、定义发布者
Spring 是通过 KafkaTemplate 来完成对 Kafka 的操作的。
1、修改配置文件
# 自定义属性
kafka:
topic: cities
# 配置Kafka
spring:
kafka:
bootstrap-servers: kafkaOS1:9092,kafkaOS2:9092,kafkaOS3:9092
# producer: # 配置生产者
# key-serializer: org.apache.kafka.common.serialization.StringSerializer
# value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # 配置消费者
group-id: group0 # 消费者组
# key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
2、定义发布者处理器
@RestController
public class SomeProducer {
@Autowired
private KafkaTemplate<String, String> template;
// 从配置文件读取自定义属性
@Value("${kafka.topic}")
private String topic;
// 由于是提交数据,所以使用Post方式
@PostMapping("/msg/send")
public String sendMsg(@RequestParam("message") String message) {
template.send(topic, message);
return "send success";
}
}
2.2、定义消费者
Spring 是通过监听方式实现消费者的。
1、修改配置文件
如上一小节,在配置文件中添加消费者配置内容。注意,Spring 中要求必须为消费者指定组。
2、定义消费者
Spring Kafka 是通过 KafkaListener 监听方式来完成消息订阅与接收的。当监听到有指定
主题的消息时,就会触发@KafkaListener 注解所标注的方法的执行
@Component
public class SomeConsumer {
@KafkaListener(topics = "${kafka.topic}")
public void onMsg(String message) {
System.out.println("Kafka消费者接受到消息 " + message);
}
}
run运行,postman访问接口输入消息:
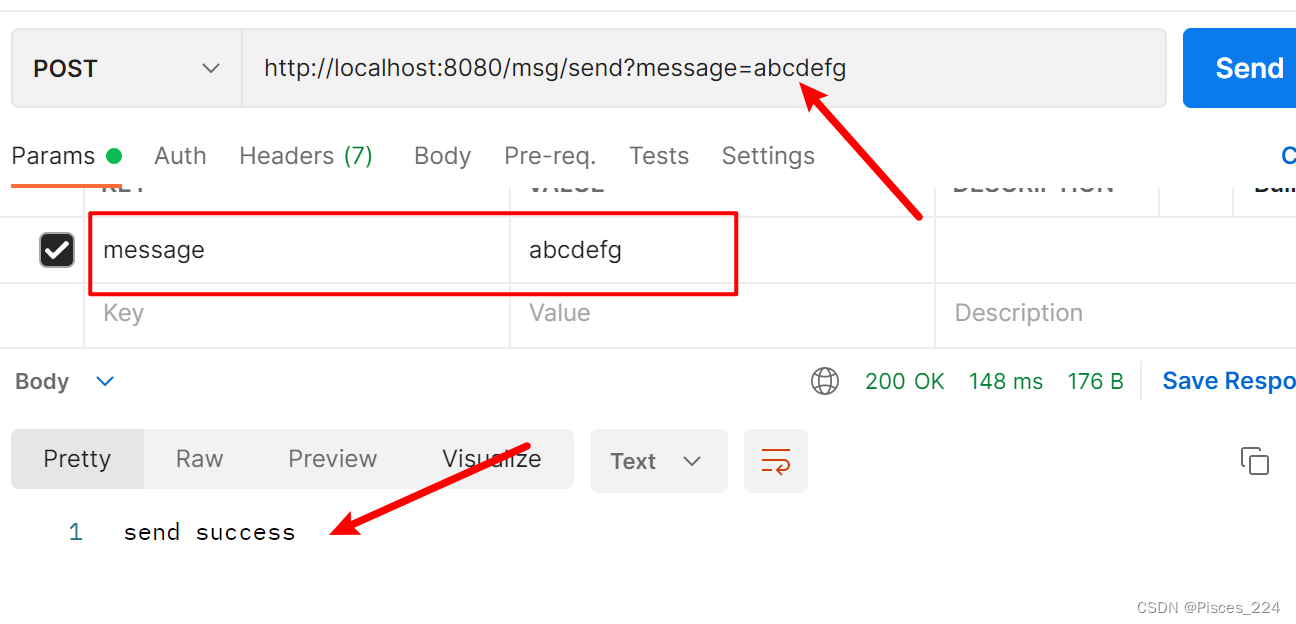
消费者收到消息:

因为SpringBoot自动配置的原理,Kafka自动配置里:
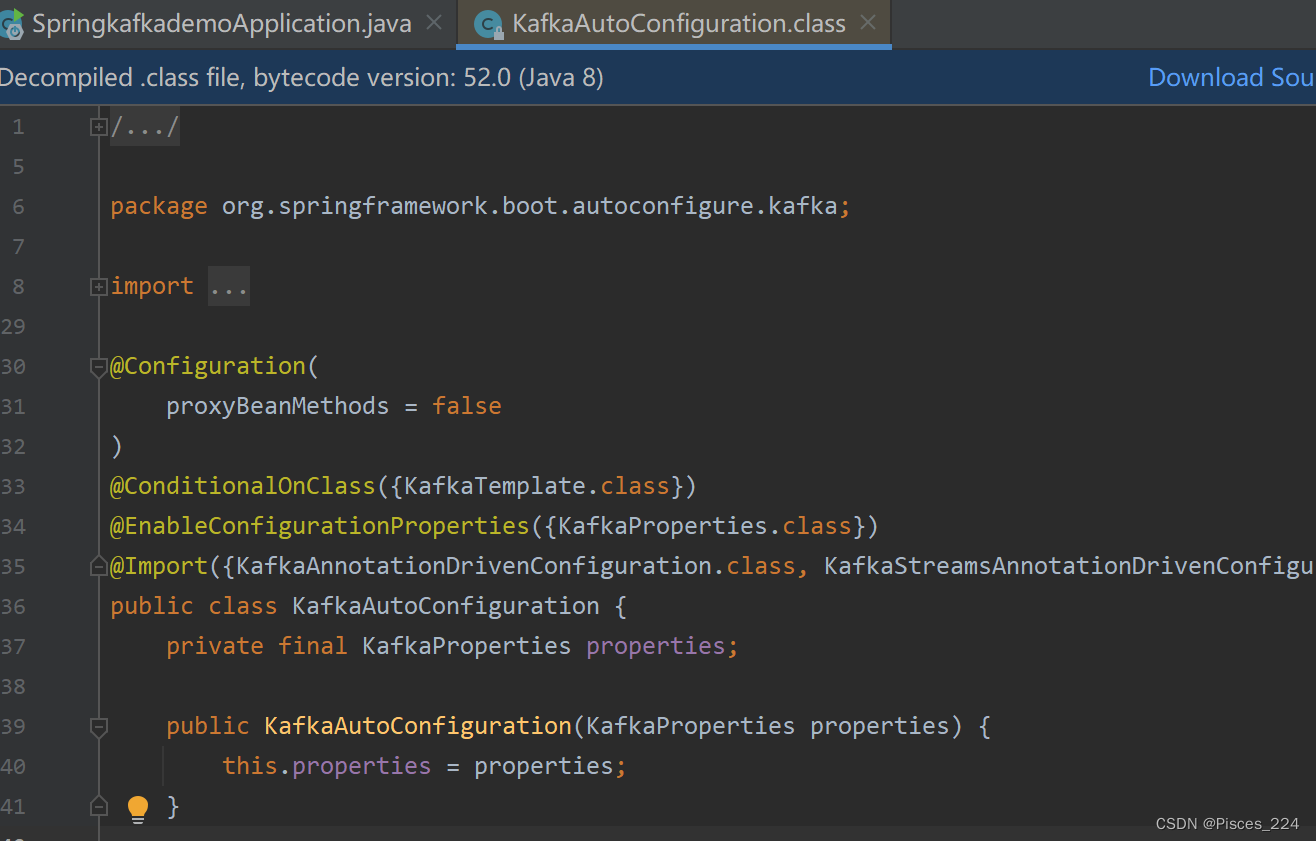
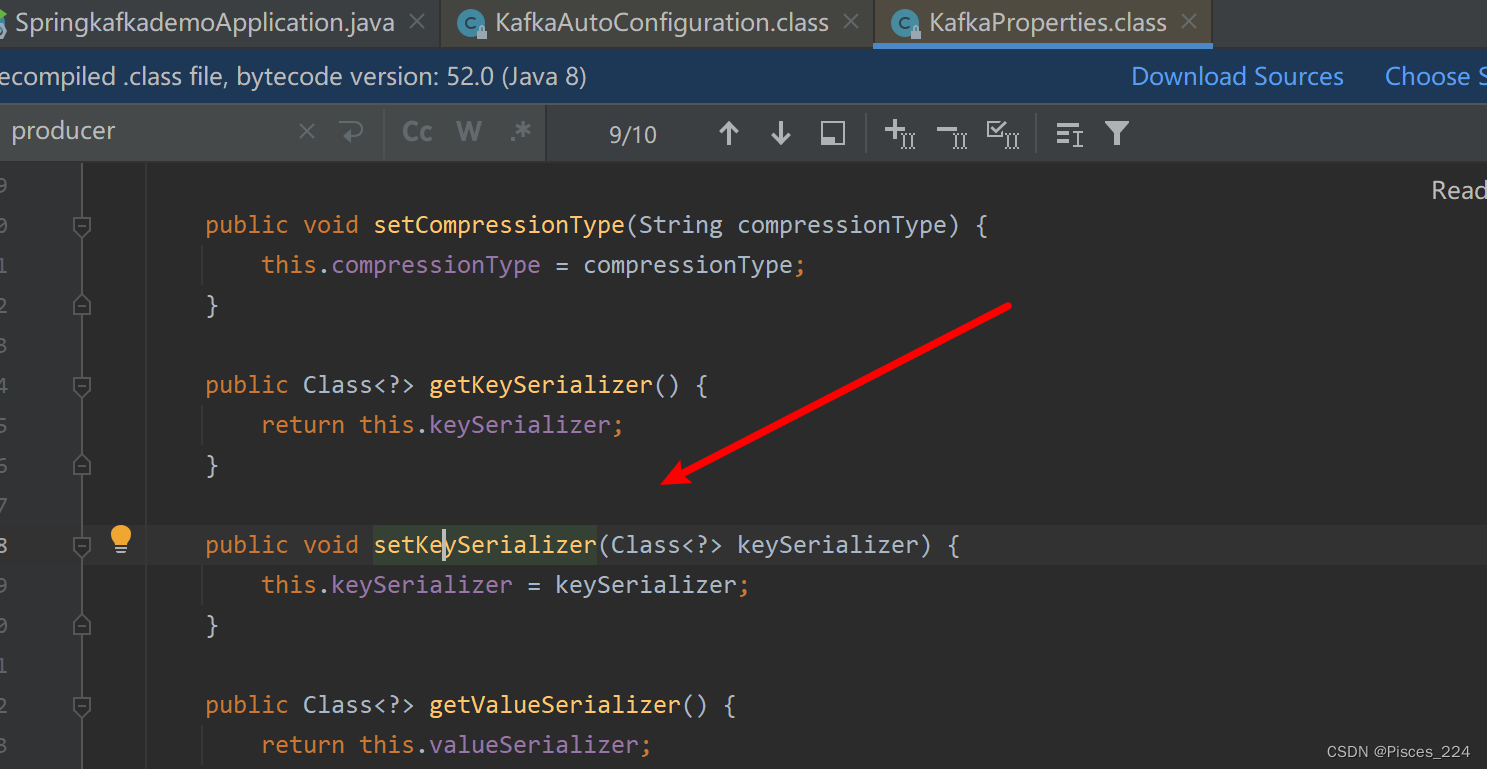
默认就有了序列化,所以配置文件可以不用配置生产者的序列化。






![Qt扫盲-Qt Model/View 理论总结 [下篇]](https://img-blog.csdnimg.cn/ac454f9df6ba4048bfaa7daabc22561b.png)