在系统设计时,如果能预先看到一些问题,并在设计层面提前解决,就会给后期的开发带来很大的便捷。相反,有缺陷的架构设计可能会导致后期的开发工作十分艰难,甚至会造成“推倒重来”的情形。因此,在系统设计阶段,应该尽可能的规避项目开发中可能会遇到的各种问题。本文就选取了几个经典的问题进行介绍。
Session共享问题
在Web项目中,Session是服务端用于保存客户端信息的重要对象。单系统中的Session对象可以直接保存在内存中,但在分布式或集群环境下,多个不同的节点就要采取措施来共享Session对象,具体可以使用以下几种方式。
1.Session Replication
SessionReplication是指在客户端第一次发出请求后,处理该请求的服务端就会创建一个与之对应的Session对象,用于保存客户端的状态信息,之后为了让其他服务端也能保存一份此Session对象,就需要将此Session对象在各个服务端节点之间进行同步,如图1所示。
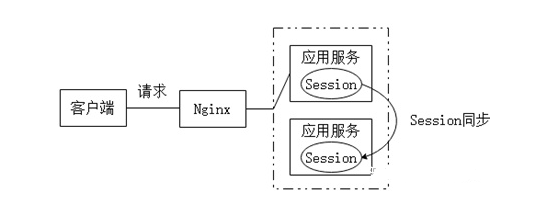
图1 Session Replication
SessionReplication的这种Session同步机制虽然能够使所有的服务节点都拥有一份Session对象,但缺点也是很明显的,如下所示。
(1)容易引起广播风暴。试想,如果有50个服务节点,那么当一个节点产生了Session对象后,就需要将该Session对象同步到其他49个节点中,因此会增大网络的开销。
(2)会造成严重的冗余。如果有多个用户同时在访问,那么每个服务节点中都会保存多个用户的Session对象。可以发现,服务节点的个数越多,Session冗余的问题就越严重。因此Session Replication方式只适用于服务节点较少的场景。
2.Session Sticky
Session Sticky是通过Nginx等负载均衡工具对各个用户进行标记(例如对Cookie标记),使每个用户在经过负载均衡工具后都请求固定的服务节点,如图2所示。
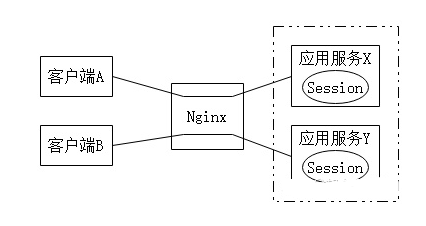
图2 Session Sticky
客户端A的所有请求都被Nginx转发到了应用服务X上,客户端B的所有请求都被转发到了应用服务Y上,因此各个服务中的Session就无需同步。但此种做法也有严重的弊端:如果某个服务节点宕机,那么该节点上的所有Session对象都会丢失。
3.独立Session服务器
除了Session Replication和Session Sticky两种方式以外,还可以将系统中所有的Session对象都存放到一个独立的Session服务中,之后各个应用服务再分别从这个Session服务中获取需要的Session对象,如图3所示。在大规模分布式系统中,就推荐使用这种独立Session服务方式。并且这种方式在存储Session对象时,既可以用数据库,也可以使用各种分布式或集群存储系统。

图3 独立Session服务器
在使用了“独立Session服务器”之后,应用服务就是一种“无状态服务”,换句话说,此时的应用服务与用户的状态是无关的。例如,无论是哪个用户在什么时间发出的请求,所有的应用服务都会进行完全相同的处理:先从Session服务中获取Session对象,再进行相同的业务处理。
读者也可以从“有状态服务”来对比理解“无状态服务”。“有状态服务”是指不同的应用服务与用户的状态有着密切的关系。例如,假设应用服务A中保存着用户Session,应用服务B中没有保存。之后,如果用户发出一个请求,经过ngnix转发到了应用服务A中,那么就可以直接进行下单、结算等业务;而如果用户的请求被ngnix转发到了应用服务B中,就会提示用户“请先登陆……”。类似这种,不同应用服务因为对用户状态的持有情况不同,从而导致的执行方式不同,就可以理解为“有状态服务”。
总的来讲,“无状态服务”有很多优势,如下所示。
1.数据同步。
“有状态服务”为了在不同的服务节点之间共享数据,必然会进行数据同步,而不同节点之间的数据同步又会带来CPU/内存损耗、网络延迟、数据冗余等问题;而“无状态服务”不需要数据同步;
2.快速部署。
如果系统的压力太大,就需要增加新的服务节点,从而对系统扩容。如果采用的是“有状态服务”,就需要在扩容后先将其他服务节点上的Session等信息同步到新节点上;而如果采用的是“无状态服务”,就不必同步。可以发现,快速部署的优势本质上也归功于“数据同步”。
实际上,我们这里介绍的“状态”不仅仅是Session,也可以是任意类型的数据、结构化数据、非结构化数据、文件等。因此,要想真正的实现应用服务的“无状态”,就需要先将各种类型的“状态”各自集中存储,具体存储方式如下。
(1)Session等保存在内存中的数据:构建独立的服务,如Session服务。
(2)结构化数据:MySQL等关系型数据库。
(3)非结构化数据:
·适合存储非结构化数据的数据库,如HBase等;
·如果是海量的“状态”,也可以存储在ElasticSearch等搜索引擎中。
(4)文件:
·独立文件服务器,如HDFS、FastDFS等
·CDN。
以上的对应关系,如图4所示。

图4 “状态”的存储方式
明确了各个“状态”的存储方式后,我们就可以搭建出一套可快速扩容的系统:将系统中的应用服务设置为“无状态”,并注册到Eureka或ZooKeeper中。因为是“无状态”的服务,因此单个服务的宕机、重启等都不会影响到集群中的其他服务,并且很容易对应用服务进行横向扩展。另一方面,将带有数据的服务设置为“有状态”,并进行集群的“集中部署”(如MySQL集群),从而降低集群内部数据同步带来的延迟。
说明:“集中部署”是指尽可能的将相同或相关的数据、业务部署在同一机房中,利用内网提高数据的传输速度,尽量避免跨机房调用,如图5所示。
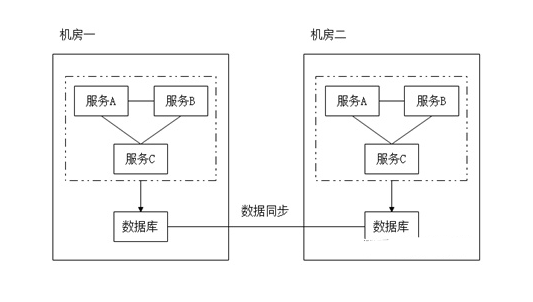
图5 多机房部署
在实际部署时,应该通过IP分组等方法尽量避免跨机房的数据传输、接口调用。并且使用DNS、Nginx等工具在某个机房整体故障时,将流量快速转接到其他机房。
最后要提醒大家的是,“无状态服务”虽然有很多的优势,但也不能盲目的将其作为唯一的选择。任何技术或架构的选择,都得看具体的业务场景,例如在小型项目或者仅有一个服务的项目中,就可以采用“有状态服务”来简化开发难度,缩短开发周期。
技术选型原则与数据库设计
在做技术选型时,既要注意待选技术的性能,也要考虑技术的安全性。并预估这些技术是否有足够长的生命力,项目组新成员是否能够快速掌握,而不能一味地追求技术的先进性。
这里以设计数据库为例,介绍一种数据库选型的思路。
以MySQL数据库为例,各种版本MySQL默认的并发连接数约为一二百,单机可配置的最大连接数为16384(一般情况下,由于计算机自身硬件的限制,单机实际能够负载的并发数最多为一千左右)。因此,高并发系统面临的最大性能瓶颈就是数据库。我们之前设计的各种缓存的目的,就是为了尽可能的减少对数据库的访问。
除了在页面、应用程序中增加缓存以外,我们还可以在应用程序和数据库之间加一层Redis高速缓存,从而提高数据的访问速度并且减少对数据库的访问次数,具体如下。
1.搭建高可用Redis集群,并通过主从同步进行数据备份、通过读写分离降低并发写操作的冲突、通过哨兵模式在Master挂掉之后选举新的Master;
2.搭建双Master的MySQL集群,并通过主从同步做数据备份;
3.通过MyCat对大容量的数据进行分库/分表,并控制MySQL的读写分离;
4.通过Haproxy搭建MyCat集群;
5.通过Keepalived搭建Haproxy集群,通过心跳机制防止单节点故障;并且Keepalived可以生成一个VIP,并用此VIP与Redis建立连接。
以上步骤如图6所示。

图6高性能高可用数据库架构
在实际进行数据库开发时,还需要合理使用索引技术以及适当设置数据库的各项性能参数,从而最大限度的优化数据访问操作。
缓存穿透与缓存雪崩问题
缓存可以在一定程度上缓解高并发造成的性能问题,但在一些特定场景下缓存自身也会带来一些问题,比较典型的就是缓存穿透与缓存雪崩问题。
注:为了讲解的方便,本文用MySQL代指所有的关系型数据库,用Redis代指所有数据库的缓存组件。
1.缓存穿透
缓存穿透是指大量查询一些数据库中不存在的数据,从而影响数据库的性能。例如Redis等KV存储结构的中间件可以作为MySQL等数据库的缓存组件,但如果某些数据没有被Redis缓存却被大量的查询,就会对MySQL带来巨大压力,如图7所示。
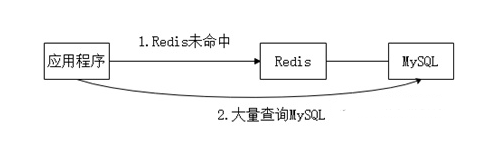
图7 缓存穿透
前面介绍过,单机MySQL最大能够承受的并发连接数只有一千左右,因此无论是设计失误(例如,某个高频访问的缓存对象过期)、恶意攻击(例如,频繁查询某个不存在的数据),还是偶然事件(例如,由于社会新闻导致某个热点的搜索量大增)等,都可能让MySQL遭受缓存穿透,从而宕机。
理解了缓存穿透的原因后,解决思路就已经明确了,举例如下。
(1)拦截非法的查询请求,仅将合理的请求发送给MySQL。如,可以使用验证码、IP限制等手段限制恶意攻击,并用敏感词过滤器等拦截不合理的非法查询。
(2)缓存空对象。如,假设在iphone9上市后,可能会导致大量用户搜索iphone9,但此时Redis和MySQL中还没有iphone9这个词。一种解决办法就是,将数据库中不存在的iphone9也缓存在Redis中,如Key=iphone9,value=””。之后,当用户再次搜索iphone9时,就可以直接从Redis中拿到结果,从而避免对MySQL的访问,如图8所示。

图8 缓存空对象
提示:为了减少Redis对大量空对象的缓存,可以适当减少空对象的过期时间。
(3)建立数据标识仓库。将MySQL中的所有数据的name值都映射成hash值,例如可以将“商品表”中的商品名“iphone8”映射成MD5计算出来的hash值b2dd48ff3e52d0796675693d08fb192e,然后再将全部name的hash值放入Redis中,从而构建出一个“数据库中所有可查数据的hash仓库”。之后,每次在查询MySQL之前都会先查询这个hash仓库,如果要查询数据的hash值存在于仓库中,再进入MySQL做真实的查询,如果不存在则直接返回。
需要注意的是,由于不同数据的hash值在概率上时可能相同的,因此可能会漏掉对个别数据的拦截,如图9中的“B”。
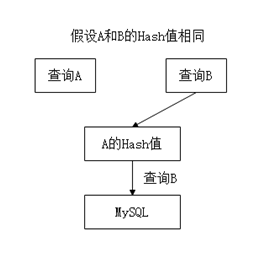
图9 不同数据的Hash值相同而造成的问题
2.缓存雪崩
除了缓存穿透以外,在使用缓存时还需要考虑缓存雪崩的情况。缓存雪崩是指由于某种原因造成Redis突然失效,从而造成MySQL瞬间压力骤增,进而严重影响MySQL性能甚至造成MySQL服务宕机。以下是造成缓存雪崩的两个常见原因:
(1)Redis重启;
(2)Redis中的大量缓存对象都设置了相同的过期时间。
为了避免缓存雪崩的发生,可参考使用以下解决方案:
(1)搭建Redis集群,保证高可用;
(2)避免大量缓存对象的key集中失效,尽力让过期时间分配均匀一些,例如,可以给各个缓存的过期时间乘一个随机数;
(3)通过队列、锁机制等控制并发访问MySQL的线程数。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:【文末领取】
【下面是我整理的2023年最全的软件测试工程师学习知识架构体系图+全套资料】
一、Python编程入门到精通
二、接口自动化项目实战

三、Web自动化项目实战
四、App自动化项目实战

五、一线大厂简历
六、测试开发DevOps体系

七、常用自动化测试工具
八、JMeter性能测试
九、总结(文末尾部小惊喜)
生命不息,奋斗不止。每一份努力都不会被辜负,只要坚持不懈,终究会有回报。珍惜时间,追求梦想。不忘初心,砥砺前行。你的未来,由你掌握!
生命短暂,时间宝贵,我们无法预知未来会发生什么,但我们可以掌握当下。珍惜每一天,努力奋斗,让自己变得更加强大和优秀。坚定信念,执着追求,成功终将属于你!
只有不断地挑战自己,才能不断地超越自己。坚持追求梦想,勇敢前行,你就会发现奋斗的过程是如此美好而值得。相信自己,你一定可以做到!