目录
- Python中的difflib模块
- 模块用法
- 报告涉及的符号
- 实现文本对比
- 普通文本对比
- 文本对比生成HTML报告
- 余弦相似度
- sklearn
- 安装
- 使用sklearn的余弦相似度
- 词袋模型
- Jaccard相似度
- 编辑距离(Levenshtein距离)
- TF-IDF
- Word2Vec
- Doc2Vec
- BERT
- 结论
Python中的difflib模块
difflib 是 Python 标准库中的一个模块,用于执行字符串序列之间的差异比较。它提供了一些工具来比较和处理文本、序列等之间的差异,主要用于生成差异报告、合并文本以及执行类似版本控制系统的操作。
以下是 difflib 模块中一些重要的类和函数:
-
Differ类:用于执行行级别的差异比较,并生成差异报告。主要方法是compare(),它会接受两个文本序列作为参数,并返回一个生成差异报告的迭代器。 -
ndiff()函数:对比两个字符串序列,返回一个生成差异报告的迭代器,以行为单位显示添加、删除和修改的内容。 -
HtmlDiff类:用于生成 HTML 格式的差异报告,可以将差异以颜色标记的方式呈现在网页上。 -
SequenceMatcher类:执行序列级别的差异比较,可以计算两个序列的相似度,以及它们之间的最长匹配子序列。它有一些方法,如ratio()用于计算相似度,get_opcodes()用于获取操作码,表示如何将一个序列转换成另一个。 -
get_close_matches()函数:用于查找与给定字符串相似的候选字符串列表,通常用于拼写纠正。 -
其他辅助函数:
context_diff()、unified_diff()、ndiff()等函数用于生成不同格式的差异报告。
使用 difflib 可以在文本处理、版本控制、数据对比等领域进行差异比较和合并操作。例如,你可以使用 Differ 类来比较两个文本文件之间的差异并生成差异报告,或者使用 SequenceMatcher 类来比较两个序列之间的差异并找到相似度等。
模块用法
| 用法 | 说明 |
|---|---|
| splitlines() | 按照行(’\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| difflib.Differ() | 用于过滤函数(或None),默认值是None |
| d.compare(a,b) | 比较两个行序列,并生成delta(一系列行) |
| difflib.HtmlDiff() | 可以用于创建一个完整HTML文件,该文件显示具有行间和行内更改突出的文本的逐行比较 |
| d.make_file(text1,text2) | 比较a和b(字符串列表)并返回一个字符串,该字符串是一个完整的HTML文件,其中包含一个表格,显示逐行差异,突出显示行间和行内更改 |
报告涉及的符号
| 符号 | 含义 |
|---|---|
| ‘-’ | 包含在第一个系列行中,但不包含第二个 |
| ‘+’ | 包含在第二个系列行中,但不包含第一个 |
| ’ ’ | 两个系列行一致 |
| ‘?’ | 存在增量差异 |
| ‘^’ | 存在差异字符 |
实现文本对比
普通文本对比
import difflib
text1 = ''' 1. Beautiful is better than ugly.
2. Explicit is better than implicit.
3. Simple is better than complex.
4. Complex is better than complicated.
'''.splitlines(keepends=True)
text2 = ''' 1. Beautiful is better than ugly.
3. Simple is better than complex.
4. Complicated is better than complex.
5. Flat is better than nested.
'''.splitlines(keepends=True)
d = difflib.Differ()
# d.compare的结果是一个生成器
print(''.join(list(d.compare(text1, text2))))
或者使用更简洁的ndiff方法:
print("".join(difflib.ndiff(text1, text2)))
二者结果是相同的:
1. Beautiful is better than ugly.
- 2. Explicit is better than implicit.
- 3. Simple is better than complex.
+ 3. Simple is better than complex.
? ++
- 4. Complex is better than complicated.
- + 4. Complicated is better than complex.
+ 5. Flat is better than nested.
+
ndiff() 函数和 difflib.Differ().compare() 方法的作用都是执行字符串序列之间的差异比较,然后生成差异报告。它们的结果是相似的,但有一些细微的差别:
-
返回值格式:
ndiff()函数返回一个包含差异信息的迭代器,每一行表示一个差异操作,以及相应的文本。difflib.Differ().compare()方法返回一个生成差异报告的迭代器,每一行由差异操作符和文本组成。
-
格式控制:
ndiff()函数的差异报告会标记每一行的差异操作,例如 " “(相同行)、”-“(删除行)、”+"(添加行)。Differ().compare()方法的差异报告默认不会标记差异操作,但你可以根据需要进行定制,通过设置Differ()类的一些属性来修改输出格式。
虽然这两种方法都可以执行类似的差异比较,但根据需求选择哪种方法可能会更方便。如果希望直接获得标记了差异操作的文本报告,可能会更倾向于使用 ndiff() 函数。如果需要更多格式的定制和控制,那么使用 Differ().compare() 方法可能更合适。
-
linejunk参数:
linejunk参数是一个函数,用于判断是否应该跳过指定的行。默认情况下,它是None,表示不跳过任何行。如果你传递一个自定义的函数,函数会接受一个字符串作为参数,你可以在函数中定义逻辑来判断是否应该跳过这个字符串代表的行。例如,如果你的文本文件包含注释行,而在差异比较时你不想考虑这些注释行,你可以传递一个函数给
linejunk参数,这个函数会判断是否跳过以 “#” 开头的行。 -
charjunk参数:
charjunk参数也是一个函数,用于判断是否应该跳过指定的字符。同样,默认情况下,它是None,表示不跳过任何字符。你可以传递一个自定义的函数,函数会接受一个字符作为参数,用于判断是否应该跳过这个字符。例如,如果你在文本比较中不想考虑空格字符,你可以传递一个函数给
charjunk参数,这个函数会判断是否跳过空格字符。
总之,linejunk 和 charjunk 参数允许在差异比较过程中过滤掉特定的行和字符,以便更准确地执行差异比较。这对于处理特殊情况或者排除不重要的内容非常有用。
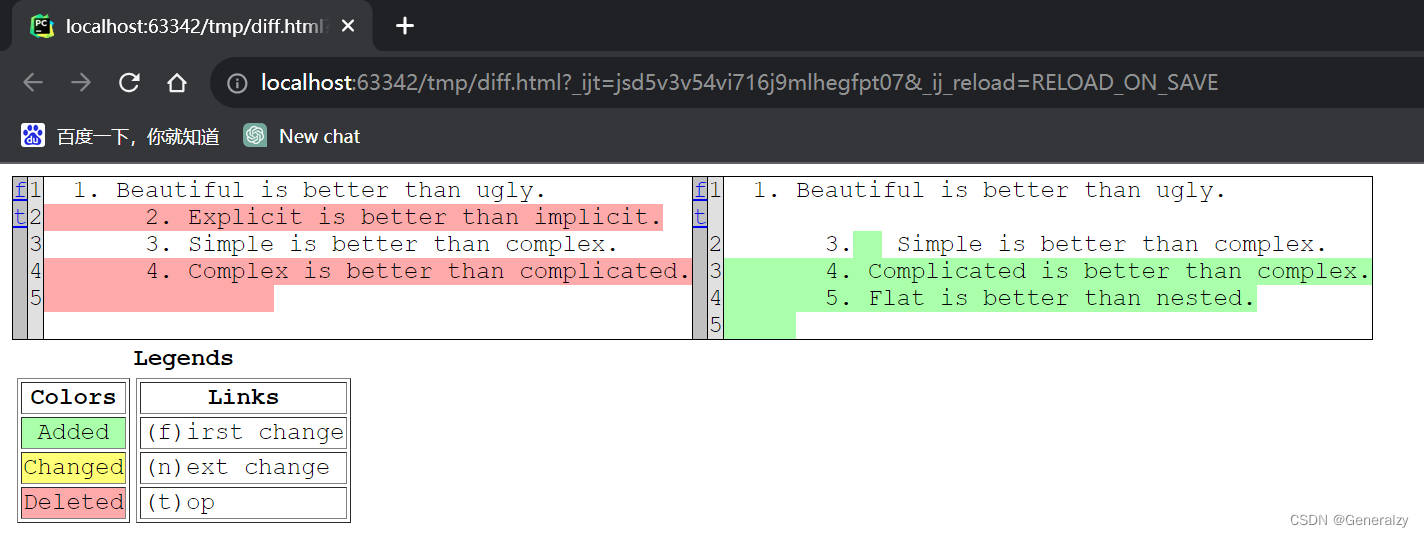
文本对比生成HTML报告
import difflib
text1 = ''' 1. Beautiful is better than ugly.
2. Explicit is better than implicit.
3. Simple is better than complex.
4. Complex is better than complicated.
'''.splitlines(keepends=True)
text2 = ''' 1. Beautiful is better than ugly.
3. Simple is better than complex.
4. Complicated is better than complex.
5. Flat is better than nested.
'''.splitlines(keepends=True)
d = difflib.HtmlDiff()
htmlContent = d.make_file(text1,text2)
# print(htmlContent)
with open('diff.html','w') as f:
f.write(htmlContent)
也可以将对比做成一个简单的服务:
import difflib
from flask import Flask,request, render_template
from werkzeug.datastructures import FileStorage
from io import StringIO
app = Flask(__name__, template_folder="./templates")
@app.route("/", methods=["GET", "POST"])
def index():
if request.method == "GET":
return render_template("index.html")
if request.method == "POST":
files = request.files
left_file_obj = files.get("left") # type:FileStorage
right_file_obj = files.get("right")
buff = StringIO()
diff = difflib.HtmlDiff()
f = diff.make_file(
left_file_obj.read().decode("utf-8").splitlines(),
right_file_obj.read().decode("utf-8").splitlines()
)
for line in f:
buff.write(line)
buff.seek(0)
return buff.read()
if __name__ == '__main__':
app.run(threaded=True)
余弦相似度
余弦相似度是一种常用的用于衡量向量之间相似性的度量方法,通常应用于文本相似度、推荐系统、信息检索等领域。它可以用来比较两个向量之间的方向,而不考虑其大小。
在自然语言处理领域中,余弦相似度常用于比较文本的相似性。它将文本看作向量空间中的向量,计算两个文本向量之间的夹角余弦值,用来衡量它们在向量空间中的相似程度。
余弦相似度的计算公式为:

在 Python 中,可以使用 NumPy 来计算余弦相似度。以下是一个示例代码,演示了如何使用 NumPy 计算两个向量的余弦相似度:
import numpy as np
def cosine_similarity(vector1, vector2):
dot_product = np.dot(vector1, vector2)
norm_vector1 = np.linalg.norm(vector1)
norm_vector2 = np.linalg.norm(vector2)
similarity = dot_product / (norm_vector1 * norm_vector2)
return similarity
if __name__ == "__main__":
vector1 = np.array([1, 2, 3])
vector2 = np.array([4, 5, 6])
similarity = cosine_similarity(vector1, vector2)
print("Cosine Similarity:", similarity)
在这个示例中,np.dot() 计算了向量的点积,np.linalg.norm() 计算向量的范数。最后,计算得到的余弦相似度值表示向量的相似程度,值越接近 1 表示越相似,越接近 -1 表示越不相似。
对于文本的向量化,有许多方法可以选择,其中一种常用的方法是词袋模型(Bag of Words)。在词袋模型中,文本被表示为一个向量,向量的每个维度表示一个单词,而向量中的值则表示该单词在文本中出现的次数或其他权重。通过这种方式,可以将不同文本之间的相似性转化为向量之间的距离或相似度计算。
以下是一个示例,演示了如何将文本使用词袋模型转换为向量:
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
# 假设有两段文本
text1 = "This is a sample sentence for text analysis."
text2 = "Text analysis is important for natural language processing."
# 创建词袋模型
vectorizer = CountVectorizer()
corpus = [text1, text2]
X = vectorizer.fit_transform(corpus)
# 将文本向量转换为数组
vector1 = np.array(X[0].toarray()).flatten()
vector2 = np.array(X[1].toarray()).flatten()
# 计算余弦相似度
similarity = np.dot(vector1, vector2) / (np.linalg.norm(vector1) * np.linalg.norm(vector2))
print("Cosine Similarity:", similarity)
在这个示例中使用了 CountVectorizer 类从文本中构建词袋模型。然后,将两段文本转换为向量,并计算了它们之间的余弦相似度。
需要注意的是,这只是一个简单的示例,实际上在 NLP 中,还有更复杂和高级的向量化方法,例如 TF-IDF、Word2Vec、BERT 等,它们能更好地捕捉单词和文本之间的语义关系。
sklearn
scikit-learn,也简称为 sklearn,是一个用于机器学习和数据挖掘的开源 Python 库。它提供了各种机器学习算法、数据预处理、特征工程、模型评估等功能,使得开发者能够轻松地构建和部署机器学习模型。
以下是一些 scikit-learn 提供的主要功能和特性:
-
丰富的机器学习算法:
scikit-learn支持多种经典和先进的机器学习算法,包括分类、回归、聚类、降维、模型选择等。 -
统一的接口: 无论是监督学习、无监督学习,还是特征选择等任务,
scikit-learn提供了一致的 API,使得学习和使用不同算法更加方便。 -
数据预处理和特征工程:
scikit-learn提供了丰富的数据预处理和特征工程工具,如缺失值处理、标准化、归一化、独热编码等,以便为模型提供更好的输入数据。 -
模型评估和选择: 提供了模型性能评估、交叉验证、参数调优等工具,帮助你选择最优的模型及其参数配置。
-
可视化工具:
scikit-learn集成了一些数据可视化工具,用于帮助你理解数据和模型的表现。 -
内置数据集:
scikit-learn内置了一些标准数据集,可以帮助你在学习和测试算法时快速上手。 -
扩展性:
scikit-learn支持扩展,你可以集成其他库来扩展其功能。 -
活跃的社区:
scikit-learn拥有活跃的社区,提供丰富的文档、教程和示例,使得学习和使用更加容易。
示例代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载内置的 Iris 数据集
iris = load_iris()
X, y = iris.data, iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 K 最近邻分类器
clf = KNeighborsClassifier(n_neighbors=3)
# 在训练集上拟合模型
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
在这个示例中,使用了 scikit-learn 中的内置数据集 Iris,创建了一个 K 最近邻分类器,然后使用训练集进行拟合并在测试集上进行预测,最后计算了预测的准确率。这只是一个简单的示例,展示了 scikit-learn 在机器学习任务中的使用。
安装
pip install scikit-learn
使用sklearn的余弦相似度
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def calculate_cosine_similarity(text1, text2):
vectorizer = CountVectorizer()
corpus = [text1, text2]
vectors = vectorizer.fit_transform(corpus)
similarity = cosine_similarity(vectors)
return similarity[0][1]
text1 = "I love Python programming"
text2 = "Python programming is great"
cosine_similarity = calculate_cosine_similarity(text1, text2)
print(cosine_similarity)
词袋模型
词袋模型(Bag of Words Model)是一种常用的文本表示方法,用于将文本转换为数值化的向量表示,以便在机器学习和自然语言处理任务中使用。在词袋模型中,文本被看作一个“袋子”(bag),其中包含了文本中所有的单词,而不考虑单词的顺序和语法。
词袋模型的基本思想是将文本中的单词提取出来,然后统计每个单词在文本中的出现频率,最终将每个单词的频率作为向量的一个维度,从而得到一个数值化的表示。
以下是构建词袋模型的一般步骤:
-
收集文本数据集,例如一组文档、句子或段落。
-
建立词汇表:将所有文本数据中出现的单词收集起来,形成一个词汇表。
-
对每个文本进行向量化:对于每个文本,统计词汇表中每个单词在文本中出现的次数,或者使用其他权重(如 TF-IDF),得到一个向量,向量的维度等于词汇表中的单词数量。
-
构建文本向量空间:将每个文本的向量拼接在一起,形成一个文本向量空间。每个文本向量表示一个文本在词汇表中每个单词的出现情况。
-
对向量空间进行机器学习:可以将文本向量空间用于各种机器学习任务,如文本分类、情感分析、主题建模等。
虽然词袋模型的简单性和高效性使其成为文本处理中的常见方法,但它忽略了单词之间的顺序和语法结构,也没有考虑单词的语义关系。因此,在一些任务中,词袋模型可能无法捕捉到文本的深层语义信息。为了解决这个问题,还有许多其他更高级的文本表示方法,如 Word2Vec、TF-IDF、BERT 等。
在 scikit-learn 中,使用 CountVectorizer 类可以方便地创建词袋模型。CountVectorizer 类将文本数据转换为词袋向量表示,其中每个维度对应一个词汇表中的单词,而每个元素表示对应单词在文本中出现的次数。
以下是使用 CountVectorizer 创建词袋模型的步骤:
-
导入库:
首先,导入CountVectorizer类。from sklearn.feature_extraction.text import CountVectorizer -
创建实例:
创建一个CountVectorizer类的实例,可以根据需要设置一些参数来定制模型。vectorizer = CountVectorizer() -
准备文本数据:
准备文本数据,将其存储在一个列表中,每个元素代表一篇文本。corpus = [text1, text2, ...] -
转换为词袋向量:
使用fit_transform()方法将文本数据转换为词袋向量表示。这将构建词汇表,并将文本数据转换为对应的向量。X = vectorizer.fit_transform(corpus)在转换后的
X中,每行表示一个文本,每列表示一个单词在词汇表中的位置,而每个元素表示对应单词在文本中出现的次数。
完整示例代码如下:
from sklearn.feature_extraction.text import CountVectorizer
# 创建 CountVectorizer 实例
vectorizer = CountVectorizer()
# 准备文本数据
text1 = "This is a sample sentence."
text2 = "Another sentence for testing."
corpus = [text1, text2]
# 转换为词袋向量
X = vectorizer.fit_transform(corpus)
# 打印词汇表
print("Vocabulary:", vectorizer.get_feature_names_out())
# 打印词袋向量
print("Bag of Words Matrix:")
print(X.toarray())
在这个示例中使用了两个简单的句子作为文本数据,创建了 CountVectorizer 实例,然后将这些文本数据转换为词袋向量表示。get_feature_names_out() 方法用于获取词汇表中的单词列表,toarray() 方法将稀疏矩阵转换为密集矩阵。
Jaccard相似度
Jaccard相似度通过计算两个集合之间的交集和并集之间的比率来衡量相似性。
Jaccard 相似度(Jaccard Similarity)是一种常用的用于衡量两个集合相似性的度量方法,通常用于比较集合之间的共同元素。
Jaccard 相似度定义为两个集合的交集大小除以它们的并集大小。其计算公式为:

Jaccard 相似度的值范围在 0 到 1 之间,数值越大表示集合之间的共同元素越多,相似性越高。当两个集合没有共同元素时,Jaccard 相似度为 0;当两个集合完全相同时,Jaccard 相似度为 1。
Jaccard 相似度通常应用于集合的比较,例如在文本挖掘中,可以用来比较文档之间的词语共现情况,或者在推荐系统中,用来比较用户的喜好集合。
以下是一个计算 Jaccard 相似度的简单示例:
def jaccard_similarity(set1, set2):
intersection = len(set1.intersection(set2))
union = len(set1.union(set2))
similarity = intersection / union
return similarity
if __name__ == "__main__":
set1 = set([1, 2, 3, 4, 5])
set2 = set([4, 5, 6, 7, 8])
similarity = jaccard_similarity(set1, set2)
print("Jaccard Similarity:", similarity)
在这个示例中定义了一个计算 Jaccard 相似度的函数 jaccard_similarity,然后使用两个集合作为输入,计算它们的 Jaccard 相似度。
对比相似度:
def calculate_jaccard_similarity(text1, text2):
set1 = set(text1.split())
set2 = set(text2.split())
intersection = len(set1.intersection(set2))
union = len(set1.union(set2))
return intersection / union
text1 = "I love Python programming"
text2 = "Python programming is great"
jaccard_similarity = calculate_jaccard_similarity(text1, text2)
print(jaccard_similarity)
编辑距离(Levenshtein距离)
编辑距离是衡量两个字符串之间差异的一种方法,即将一个字符串转换为另一个字符串所需的最小单字符编辑操作(插入、删除或替换)次数。
import numpy as np
def calculate_levenshtein_distance(text1, text2):
m, n = len(text1), len(text2)
dp = np.zeros((m + 1, n + 1))
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]) + 1
return dp[m][n]
text1 = "I love Python programming"
text2 = "Python programming is great"
levenshtein_distance = calculate_levenshtein_distance(text1, text2)
print(levenshtein_distance)
TF-IDF
TF-IDF是一种统计方法,用于评估单词在文档集中的重要性。它可以将文本表示为向量,进而计算余弦相似度。
TF-IDF,全称为 Term Frequency-Inverse Document Frequency,是一种用于衡量一个词语在文本集合中的重要性的统计方法,常用于信息检索、文本挖掘和自然语言处理领域。TF-IDF 结合了词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF),用来在文本中确定一个词语的权重。

TF-IDF 的主要思想是,某个词语在当前文档中出现频率高(TF 高)且在整个文本集合中出现次数较少(IDF 高),则该词语在当前文档中具有较高的重要性。相反,如果词语在文档中频率低或者在整个文本集合中出现次数很多,则其重要性较低。
TF-IDF 在信息检索中被用来计算文档与查询的相似性,或者在文本分类、聚类等任务中用来表示文本特征。通常情况下,会对计算结果进行归一化处理,例如将 TF-IDF 向量进行标准化或 L2 归一化,以便更好地用于机器学习模型的训练。
from sklearn.feature_extraction.text import TfidfVectorizer
def calculate_tfidf_cosine_similarity(text1, text2):
vectorizer = TfidfVectorizer()
corpus = [text1, text2]
vectors = vectorizer.fit_transform(corpus)
similarity = cosine_similarity(vectors)
return similarity[0][1]
text1 = "I love Python programming"
text2 = "Python programming is great"
tfidf_cosine_similarity = calculate_tfidf_cosine_similarity(text1, text2)
print(tfidf_cosine_similarity)
对比词袋模型和TF-IDF:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# tf-idf
def calculate_tfidf_cosine_similarity(text1, text2):
vectorizer = TfidfVectorizer()
corpus = [text1, text2]
vectors = vectorizer.fit_transform(corpus)
similarity = cosine_similarity(vectors)
return similarity[0][1]
# 词袋
def calculate_cosine_similarity(text1, text2):
vectorizer = CountVectorizer()
corpus = [text1, text2]
vectors = vectorizer.fit_transform(corpus)
similarity = cosine_similarity(vectors)
return similarity[0][1]
text1 = "I love Python programming"
text2 = "Python programming is great"
print(calculate_tfidf_cosine_similarity(text1, text2))
print(calculate_cosine_similarity(text1, text2))
Word2Vec
Doc2Vec
BERT
结论
-
Word2Vec:
- 优点:Word2Vec 通过将词语映射到向量空间中,捕捉词语之间的语义关系。这种方法适用于词语层面的相似度计算,能够找到在语义上相似的词语。
- 缺点:Word2Vec 主要关注单词层面,无法捕捉句子的整体结构。也可能需要大量数据进行训练,不太适合处理较短的文本。
-
Doc2Vec:
- 优点:在 Word2Vec 基础上引入文档向量,可以捕捉整个文档的语义信息。适合处理整个文档的相似度计算。
- 缺点:训练时间较长,需要更多的数据和计算资源。适合处理较大规模的文本数据。
-
BERT:
- 优点:BERT 利用预训练的语言模型,能够更好地理解句子的上下文和语义。适用于需要更准确的句子相似度计算,如文本分类、信息检索等。
- 缺点:模型较大,计算资源要求高,需要更长的预测时间。
-
difflib 模块:
- 优点:适用于计算文本之间的差异,可以用来比较较短的文本片段,查找差异之处。
- 缺点:主要关注差异性,不适合用于衡量文本的相似度或语义关系。
-
余弦相似度:
- 优点:计算简单,适用于向量化表示的文本相似度计算。可用于衡量词向量、文档向量等在向量空间中的相似度。
- 缺点:不考虑向量的长度和重要性,可能受到文本长度影响。
-
Jaccard 相似度:
- 优点:适用于衡量集合之间的相似度,比如词语、词集合的相似性计算。
- 缺点:不考虑单词的顺序和语义,只适用于词语层面的相似度计算。
-
编辑距离(Levenshtein 距离):
- 优点:用于计算两个字符串之间的距离,适用于比较字符串的相似度。
- 缺点:不考虑语义关系,只关注字符的相似性。
-
TF-IDF:
- 优点:捕捉词语在文本中的重要性,适用于文本分类、检索等任务。
- 缺点:只考虑词语频率,无法捕捉更深层的语义信息。
根据任务和数据特点,你可以根据以下几个方面进行取舍和选择:
-
任务类型: 如果需要比较整个句子或文档的相似性,可以考虑使用 Doc2Vec、BERT、TF-IDF 等方法。如果需要比较词语之间的相似性,可以使用 Word2Vec、余弦相似度、Jaccard 相似度等方法。
-
计算效率: 有些方法(如 BERT)可能需要更长的预测时间,而其他方法(如余弦相似度)计算较快。
-
数据量: 如果你有大规模的文本数据,训练 Word2Vec 或 Doc2Vec 可能会更有效。对于少量数据,可以考虑使用余弦相似度、Jaccard 相似度等。
-
任务目标: 考虑你需要什么样的相似度度量,是仅仅关注语义相似性,还是包含结构和上下文信息。
-
计算资源: 如果你拥有大量计算资源,可以选择使用较复杂的模型(如 BERT)来获得更准确的相似度度量。
综合考虑以上因素,你可以根据任务需求选择合适的方法,甚至结合多种方法进行文本相似度计算,以获得更全面的结果。




![LeetCode[1122]数组的相对排序](https://img-blog.csdnimg.cn/5179b0e80d134eeb9776e7d596d7f35f.png)

