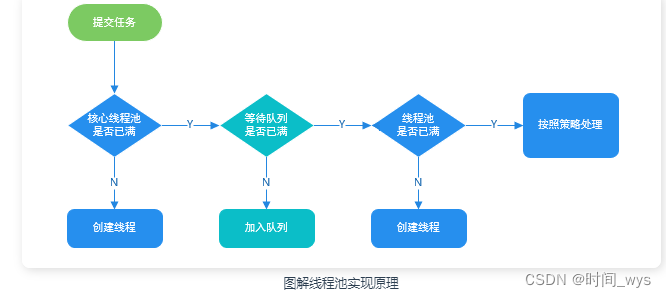
手把手利用PyTorch实现扩散模型DDPM
- DDPM代码实现
- 神经网络
- 定义辅助函数
- 位置嵌入
- ResNet block
- 注意力模块
- 分组归一化
- Conditional U-Net
- 定义前向扩散过程
- 定义PyTorch数据集+DataLoader
- 采样
- 训练模型
- 采样
- 后续阅读
- 参考链接
上一篇博文已经手把手推导了扩散模型DDPM,本文利用PyTorch在Google Colab notebook中实现扩散模型。
DDPM代码实现
注意,扩散模型有几种观点。在这里,我们采用discrete-time(潜变量模型)的观点,但请务必查看其他观点。
神经网络
神经网络需要在特定的时间步接收噪声图像,并返回预测的噪声。需要注意的是,预测的噪声是一个与输入图像具有相同大小/分辨率的张量。因此从技术上讲,网络接收和输出具有相同形状的张量。在这种情况下,可以使用什么类型的神经网络呢?
在这里通常使用的方法与自编码器(Autoencoder)非常相似,你可能还记得它出现在典型的“intro to deep learning门”教程中。Autoencoders在encoder和decoder之间具有一个所谓的“bottleneck”层。编码器首先将图像编码为较小的隐藏表示,称为“bottleneck”,然后解码器将该隐表示解码回实际图像。这迫使网络在瓶颈层中仅保留最重要的信息。
在体系结构方面,DDPM 的作者采用了一个 U-Net 结构,该结构由(Ronneberger等人,2015)引入,当时在医学图像分割领域取得了最先进的结果。这个网络,像任何自编码器一样,由一个位于中间的瓶颈层组成,确保网络仅学习最重要的信息。重要的是,它在编码器和解码器之间引入了残差连接,大大改善了梯度流动(灵感来自于 He等人,2015年的 ResNet)。
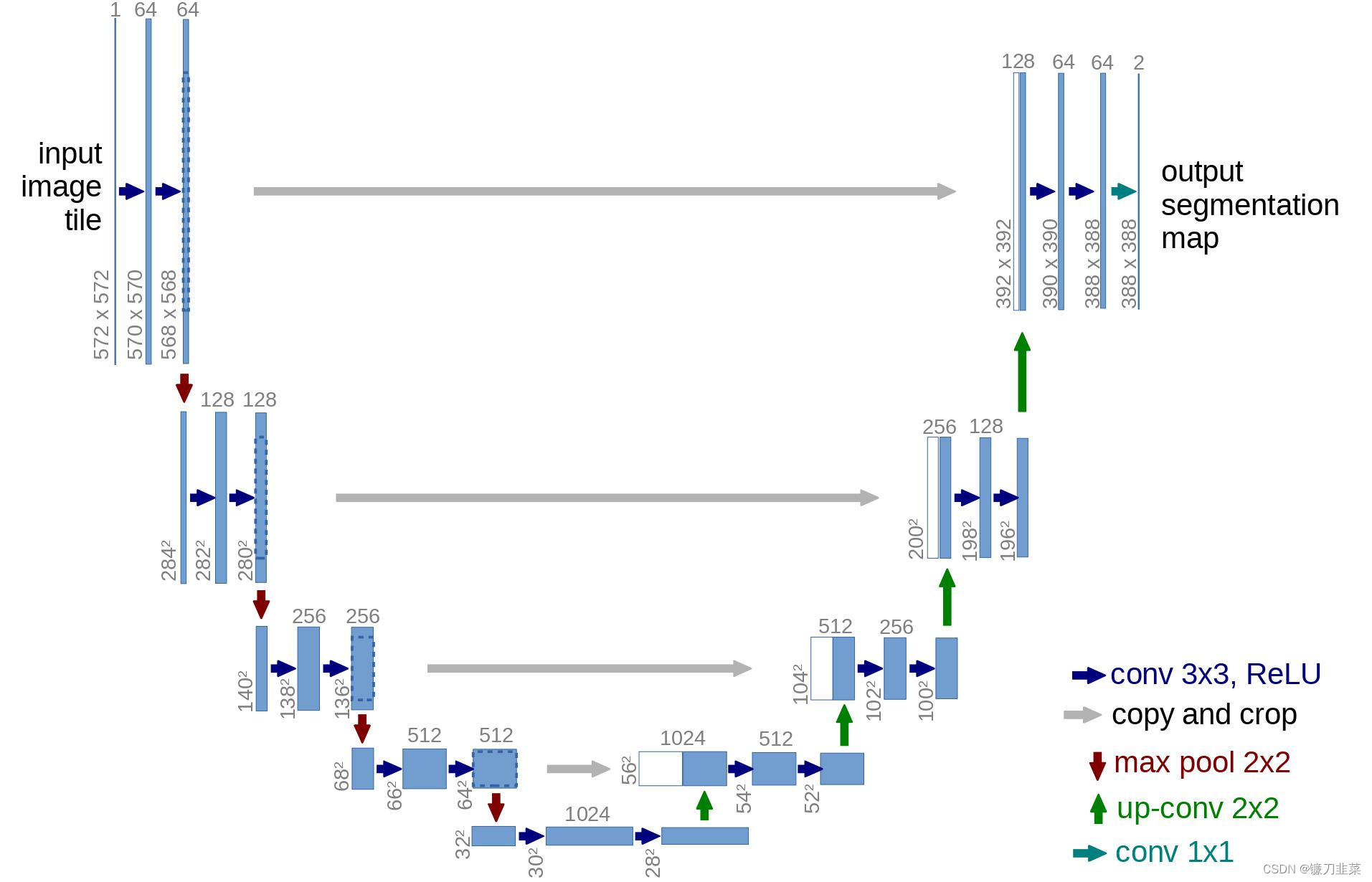
如图所示,U-Net 模型首先对输入进行下采样(即在空间分辨率方面使输入变小),然后进行上采样。
接下来,我们逐步实现这个网络。
!pip install -q -U einops datasets matplotlib tqdm
导入相关依赖库
import math
from inspect import isfunction
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from einops import rearrange, reduce
from einops.layers.torch import Rearrange
import torch
from torch import nn, einsum
import torch.nn.functional as F
定义辅助函数
首先,定义一些在实现神经网络时将使用的辅助函数和类。重要的是,定义了一个残差模块,它将输入简单地添加到特定函数的输出中(换句话说,将残差连接添加到特定函数中)。
def exists(x):
return x is not None
def default(val, d):
if exists(val):
return val
return d() if isfunction(d) else d
def num_to_groups(num, divisor):
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
我们还为上采样和下采样操作定义了别名。
def Upsample(dim, dim_out=None):
return nn.Sequential(
nn.Upsample(scale_factor=2, mode='nearest'),
nn.Conv2d(dim, default(dim_out, dim), 3, padding=1),
)
def Downsample(dim, dim_out=None):
# 不再有阶梯卷积或池
return nn.Sequential(
Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2),
nn.Conv2d(dim * 4, default(dim_out, dim), 1),
)
位置嵌入
由于神经网络的参数在不同时间(噪声水平)之间共享,作者采用了受 Transformer(Vaswani et al., 2017)启发的正弦位置嵌入(sinusoidal position embeddings)来编码 t t t。这使得神经网络可以“know”它正在处理批次中的每个图像的特定时间步(噪声水平)。
SinusoidalPositionEmbeddings 模块接受形状为(batch_size,1)的张量作为输入(即批次中多个带噪声图像的噪声水平),并将其转换为形状为(batch_size,dim)的张量,其中 dim 是位置嵌入的维度。然后将其添加到每个残差块中,我们将在后面看到。
class SinusoidalPositionEmbeddings(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
half_dim = self.dim // 2
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = time[:, None] * embeddings[None, :]
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
总之就是将 t t t 编码为embedding,和原本的输入一起进入网络,让网络“知道”当前的输入属于哪个step。
ResNet block
接下来,定义 U-Net 模型的核心构建块。DDPM 的作者使用了 Wide ResNet block(Zagoruyko et al., 2016),但 Phil Wang 将标准卷积层替换为“weight standardized”版本,这与分组归一化的结合效果更好(有关详细信息,请参见(Kolesnikov et al., 2019))。
class WeightStandardizedConv2d(nn.Conv2d):
"""
https://arxiv.org/abs/1903.10520
weight standardization purportedly works synergistically with group normalization
"""
def forward(self, x):
eps = 1e-5 if x.dtype == torch.float32 else 1e-3
weight = self.weight
mean = reduce(weight, "o ... -> o 1 1 1", "mean")
var = reduce(weight, "o ... -> o 1 1 1", partial(torch.var, unbiased=False))
normalized_weight = (weight - mean) * (var + eps).rsqrt()
return F.conv2d(
x,
normalized_weight,
self.bias,
self.strides,
self.padding,
self.dilation,
self.groups,
)
class Block(nn.Module):
def __init__(self, dim, dim_out, groups=8):
super().__init__()
self.proj = WeightStandardizedConv2d(dim, dim_out, 3, padding=1)
self.norm = nn.GroupNorm(groups, dim_out)
self.act = nn.SiLU()
def forward(self, x, scale_shift=None):
x = self.proj(x)
x = self.norm(x)
if exists(scale_shift):
scale, shift = scale_shift
x = x * (scale + 1) + shift
x = self.act(x)
return x
class ResnetBlock(nn.Module):
"""https://arxiv.org/abs/1512.03385"""
def __init__(self, dim, dim_out, *, time_emb_dim=None, groups=8):
super().__init__()
self.mlp = (
nn.Sequential(nn.SiLU(), nn.Linear(time_emb_dim, dim_out * 2))
if exists(time_emb_dim)
else None
)
self.block1 = Block(dim, dim_out, groups=groups)
self.block2 = Block(dim_out, dim_out, groups=groups)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb = None):
scale_shift = None
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
time_emb = rearrange(time_emb, "b c -> b c 1 1")
scale_shift = time_emb.chunk(2, dim=1)
h = self.block1(x, scale_shift=scale_shift)
h = self.block2(h)
return h + self.res_conv(x)
注意力模块
现在,定义注意力模块,这是 DDPM 的作者在卷积块之间添加的。注意力是著名的 Transformer 架构(Vaswani et al., 2017)的构建块,在人工智能的各个领域,从自然语言处理和视觉到蛋白质折叠都取得了巨大的成功。Phil Wang 使用了两种注意力的变体:一种是常规的多头自注意力(multi-head self-attention)(就像在 Transformer 中使用的那样),另一种是线性注意力变体(linear attention variant)(Shen et al., 2018),其时间和内存要求与序列长度线性缩放,而不是常规注意力的二次缩放。
关于注意力机制的详细解释,请参阅 Jay Allamar 的精彩博客文章。
class Attention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim=1)
q, k, v = map(
lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
)
q = q * self.scale
sim = einsum("b h d i, b h d j -> b h i j", q, k)
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
attn = sim.softmax(dim=-1)
out = einsum("b h i j, b h d j -> b h i d", attn, v)
out = rearrange(out, "b h (x y) d -> b (h d) x y", x=h, y=w)
return self.to_out(out)
class LinearAttention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = nn.Sequential(nn.Conv2d(hidden_dim, dim, 1), nn.GroupNorm(1, dim))
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim=1)
q, k, v = map(
lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
)
q = q.softmax(dim=2)
k = k.softmax(dim=-1)
q = q * self.scale
context = torch.einsum("b h d n, b h e n -> b h d e", k, v)
out = torch.einsum("b h d e, b h d n -> b h e n", context, q)
out = rearrange(out, "b h c (x y) -> b (h c) x y", h=self.heads, x=h, y=w)
return self.to_out(out)
分组归一化
DDPM 的作者在 U-Net 的卷积/注意力层之间交错使用了分组归一化(group normalization)(Wu et al., 2018)。在下面,定义了一个 PreNorm 类,该类将在注意力层之前应用分组归一化,正如我们将在后面看到的。值得注意的是,关于在 Transformer 中是在注意力之前还是之后应用归一化一直存在争议。
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.GroupNorm(1, dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
Conditional U-Net
现在,我们已经定义了所有构建块(position embeddings,ResNet blocks,attention和group normalization),现在该定义整个神经网络了。回想一下网络 ϵ θ ( x t , t ) \boldsymbol{\epsilon}_\theta\left(\mathbf{x_t}, t\right) ϵθ(xt,t)的工作是获取一批有噪声的图像及其各自的噪声水平,并输出添加到输入的噪声。更正式地说:
- 网络采集一批形状为(batch_size, num_channels, height, width)的噪声图像和一批形状为 (batch_size, 1)的噪声水平作为输入,并返回一个形状为 (batch_size, num_channels, height, width)的张量
网络构建如下:
- 首先,在一批有噪声的图像上应用卷积层,并计算噪声水平的位置嵌入(position embeddings)
- 然后,执行一系列的下采样阶段(downsampling stages)。每个下采样阶段由2个ResNet blocks+ groupnorm+ attention+residual connection+a downsample operation组成
- 在网络的中间,再次应用ResNet block,与attention交错
- 接下来,执行一系列上采样阶段(upsampling stages)。每个上采样阶段由2个ResNet blocks + groupnorm +attention + residual connection + an upsample operation组成
- 最后,在一个卷积层后面应用一个ResNet block。
最终,神经网络就像乐高积木一样层层堆叠(但了解它们是如何工作的很重要)。
class Unet(nn.Module):
def __init__(self, dim, init_dim=None, out_dim=None, dim_mults=(1, 2, 4, 8), channels=3, self_condition=False,
resnet_block_groups=4):
super().__init__()
# determine dimensions
self.channels = channels
self.self_condition = self_condition
input_channels = channels * (2 if self_condition else 1)
init_dim = default(init_dim, dim)
self.init_conv = nn.Conv2d(input_channels, init_dim, 1, padding=0) # changed to 1 and 0 from 7,3
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
block_klass = partial(ResnetBlock, groups=resnet_block_groups)
# time embeddings
time_dim = dim * 4
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbeddings(dim),
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim),
)
# layers
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append(
nn.ModuleList(
[
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Downsample(dim_in, dim_out)
if not is_last
else nn.Conv2d(dim_in, dim_out, 3, padding=1),
]
)
)
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
for ind, (dim, dim_out) in enumerate(reversed(in_out)):
is_last = ind == (len(in_out) - 1)
self.ups.append(
nn.ModuleList(
[
block_klass(dim_out + dim_in, dim_out, time_emb_dim=time_dim),
block_klass(dim_out + dim_in, dim_out, time_emb_dim=time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Upsample(dim_out, dim_in)
if not is_last
else nn.Conv2d(dim_out, dim_in, 3, padding=1),
]
)
)
self.out_dim = default(out_dim, channels)
self.final_res_block = block_klass(dim * 2, dim, time_emb_dim=time_dim)
self.final_conv = nn.Conv2d(dim, self.out_dim, 1)
def forward(self, x, time, x_self_cond=None):
if self.self_condition:
x_self_cond = default(x_self_cond, lambda: torch.zeros_like(x))
x = torch.cat((x_self_cond, x), dim=1)
x = self.init_conv(x)
r = x.clone()
t = self.time_mlp(time)
h = []
for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
h.append(x)
x = block2(x, t)
x = attn(x)
h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
for block1, block2, attn, upsample in self.ups:
x = torch.cat((x, h.pop()), dim=1)
x = block1(x, t)
x = torch.cat((x, h.pop()), dim=1)
x = block2(x, t)
x = attn(x)
x = upsample(x)
x = torch.cat((x, r), dim=1)
x = self.final_res_block(x, t)
return self.final_conv(x)
定义前向扩散过程
forward diffusion process在
T
T
T个时间步内逐渐将噪声从真实分布添加到图像中,这是根据variance schedule发生的。最初的DDPM作者采用了linear schedule:
我们将前向过程的方差设置为线性增加的常数 from β 1 = 1 0 − 4 \beta_1=10^{-4} β1=10−4 to β T = 0.02 \beta_T=0.02 βT=0.02.
然而,在(Nichol et al.,2021)中表明,使用cosine schedule可以获得更好的结果。下面,我们定义 T T T个时间步的不同的schedule(我们稍后会选择一个):
def cosine_beta_schedule(timesteps, s=0.008):
"""
cosine schedule as proposed in https://arxiv.org/abs/2102.09672
"""
steps = timesteps + 1
x = torch.linspace(0, timesteps, steps)
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])
return torch.clip(betas, 0.0001, 0.9999)
def linear_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start, beta_end, timesteps)
def quadratic_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start**0.5, beta_end**0.5, timesteps) ** 2
def sigmoid_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
betas = torch.linspace(-6, 6, timesteps)
return torch.sigmoid(betas) * (beta_end - beta_start) + beta_start
首先,使用T=300个时间步的linear schedule,并从
β
t
\beta_t
βt中定义我们需要的变量,例如,方差的累积乘积KaTeX parse error: Undefined control sequence: \bat at position 1: \̲b̲a̲t̲{\alpha}_t。下面的每个变量都只是一维张量,存储从
t
t
t到
T
T
T的数值。注意,我们还定义了一个extract函数,它允许我们按照
t
t
t提取一个批次的索引。
timesteps = 300
# define beta schedule
betas = linear_beta_schedule(timesteps=timesteps)
# define alphas
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
# calculations for diffusion q(x_t | x_{t-1}) and others
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
def extract(a, t, x_shape):
batch_size = t.shape[0]
out = a.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
我们将用猫图像说明如何在扩散过程的每个时间步中添加噪声:
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw) # PIL image of shape HWC
image

将噪声添加到Pytorch张量,而不是Pillow Images中。首先定义能够将PIL图像转换为Pytorch张量(可以在上面添加噪声)的图像转换,反之亦然。
这些转换非常简单:我们首先通过除以255(其结果能在[0,1]范围),然后确保它们在[-1,1]范围。DDPM 文中提到:
我们假设图像数据由在集合{ 0 ,1 、. . . , 255}中的整数组成,然后线性缩放到[−1, 1]。 这确保了神经网络逆向过程能够从标准正态先验 p ( x T ) p(x_T) p(xT)开始且一致缩放的输入上运行。"
from torchvision.transforms import Compose, ToTensor, Lambda, ToPILImage, CenterCrop, Resize
image_size = 128
transform = Compose([
Resize(image_size),
CenterCrop(image_size),
ToTensor(), # turn into torch Tensor of shape CHW, divide by 255
Lambda(lambda t: (t * 2) - 1),
])
x_start = transform(image).unsqueeze(0)
x_start.shape
输出结果:
torch.Size([1, 3, 128, 128])
另外,还定义了反向变换(reverse transform),它接收一个PyTorch张量,其中包含[-1,1],并将它们重新转换回PIL图像:
import numpy as np
reverse_transform = Compose([
Lambda(lambda t: (t + 1) / 2),
Lambda(lambda t: t.permute(1, 2, 0)), # CHW to HWC
Lambda(lambda t: t * 255.),
Lambda(lambda t: t.numpy().astype(np.uint8)),
ToPILImage(),
])
reverse_transform(x_start.squeeze())

现在,可以像论文中定义前向扩散过程:
# forward diffusion (using the nice property)
def q_sample(x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x_start.shape
)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
在特定的时间步中进行测试:
def get_noisy_image(x_start, t):
# add noise
x_noisy = q_sample(x_start, t=t)
# turn back into PIL image
noisy_image = reverse_transform(x_noisy.squeeze())
return noisy_image
# take time step
t = torch.tensor([40])
get_noisy_image(x_start, t)

可视化不同时间步的结果:
import matplotlib.pyplot as plt
# use seed for reproducability
torch.manual_seed(0)
# source: https://pytorch.org/vision/stable/auto_examples/plot_transforms.html#sphx-glr-auto-examples-plot-transforms-py
def plot(imgs, with_orig=False, row_title=None, **imshow_kwargs):
if not isinstance(imgs[0], list):
# Make a 2d grid even if there's just 1 row
imgs = [imgs]
num_rows = len(imgs)
num_cols = len(imgs[0]) + with_orig
fig, axs = plt.subplots(figsize=(200,200), nrows=num_rows, ncols=num_cols, squeeze=False)
for row_idx, row in enumerate(imgs):
row = [image] + row if with_orig else row
for col_idx, img in enumerate(row):
ax = axs[row_idx, col_idx]
ax.imshow(np.asarray(img), **imshow_kwargs)
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
if with_orig:
axs[0, 0].set(title='Original image')
axs[0, 0].title.set_size(8)
if row_title is not None:
for row_idx in range(num_rows):
axs[row_idx, 0].set(ylabel=row_title[row_idx])
plt.tight_layout()
plot([get_noisy_image(x_start, torch.tensor([t])) for t in [0, 50, 100, 150, 199]])

在给定模型的情况下定义损失函数:
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):
if noise is None:
noise = torch.randn_like(x_start)
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
predicted_noise = denoise_model(x_noisy, t)
if loss_type == 'l1':
loss = F.l1_loss(noise, predicted_noise)
elif loss_type == 'l2':
loss = F.mse_loss(noise, predicted_noise)
elif loss_type == "huber":
loss = F.smooth_l1_loss(noise, predicted_noise)
else:
raise NotImplementedError()
return loss
dnoise_model就是上面定义的U-Net。在真实噪声和预测噪声之间使用Huber损失。
定义PyTorch数据集+DataLoader
这里定义一个常规的PyTorch数据集。该数据集仅由真实数据集(如Fashion、MNIST、CIFAR-10或ImageNet)的图像组成,线性缩放至
[
−
1
,
1
]
[-1,1]
[−1,1]。
每个图像都被调整为相同的大小,同时是随机水平翻转的。从论文中:
我们在 CIFAR10 的训练过程中使用了随机水平翻转;我们尝试了有翻转和没有翻转的训练,发现翻转可以稍微提高样本质量。
在这里,使用Datasets库轻松地从hub加载 Fashion MNIST 数据集。该数据集由已经具有相同分辨率的图像组成,即 28x28。
from datasets import load_dataset
# load dataset from the hub
dataset = load_dataset('fashion_mnist')
image_size = 28
channels = 1
batch_size = 128
接下来,定义一个函数,将在整个数据集上即时应用它。为此使用该with_transform功能。该函数只是应用了一些基本的图像预处理:随机水平翻转、重新缩放并最终使它们在[-1,1]范围。
from torchvision import transforms
from torch.utils.data import DataLoader
# define image transformations(e.g. using torchvision)
transform = Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Lambda(lambda t: (t * 2) -1)
])
# define function
def transforms(examples):
examples["pixel_values"] = [transform(image.convert("L")) for image in examples["image"]]
del examples["image"]
return examples
transformed_dataset = dataset.with_transform(transforms).remove_columns("label")
# create dataloader
dataloader = DataLoader(transformed_dataset["train"], batch_size=batch_size, shuffle=True)
batch = next(iter(dataloader))
print(batch.keys()) # dict_keys(['pixel_values'])
采样
由于将在训练期间从模型中采样(来跟踪进度),因此定义了下面的代码。采样方法总结如下:

从扩散模型生成新图像是通过逆扩散过程来实现的:从
T
T
T开始,从高斯分布中采样纯噪声,然后使用神经网络逐渐去噪(使用它学到的条件概率),直到在时间步
t
=
0
t=0
t=0结束。如上所示,可以得到一个稍微降噪的图像
x
t
−
1
x_{t-1}
xt−1通过使用我们的噪声预测器插入均值的重新参数化。注意,方差是提前知道的。
理想情况下,最终会得到一张看起来像是来自真实数据分布的图像。下面的代码实现了这一点。
@torch.no_grad()
def p_sample(model, x, t, t_index):
betas_t = extract(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x.shape
)
sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)
# Equation 11 in the paper
# Use our model (noise predictor) to predict the mean
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
if t_index == 0:
return model_mean
else:
posterior_variance_t = extract(posterior_variance, t, x.shape)
noise = torch.randn_like(x)
# Algorithm 2 line 4:
return model_mean + torch.sqrt(posterior_variance_t) * noise
# Algorithm 2 (including returning all images)
@torch.no_grad()
def p_sample_loop(model, shape):
device = next(model.parameters()).device
b = shape[0]
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)
imgs.append(img.cpu().numpy())
return imgs
@torch.no_grad()
def sample(model, image_size, batch_size=16, channels=3):
return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
训练模型
接下来,以常规 PyTorch 方式训练模型。我们还定义了一些逻辑来定期保存生成的图像,使用上面定义的sample定义的方法。
from pathlib import Path
def num_to_groups(num, divisor):
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
results_folder = Path("./results")
results_folder.mkdir(exist_ok = True)
save_and_sample_every = 1000
下面,定义模型,并将其移动到GPU,还定义了一个标准优化器(Adam)。
from torch.optim import Adam
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Unet(
dim=image_size,
channels=channels,
dim_mults=(1, 2, 4,)
)
model.to(device)
optimizer = Adam(model.parameters(), lr=1e-3)
开始训练:
from torchvision.utils import save_image
epochs = 6
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
batch_size = batch["pixel_values"].shape[0]
batch = batch["pixel_values"].to(device)
# Algorithm 1 line 3: sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = p_losses(model, batch, t, loss_type="huber")
if step % 100 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
# save generated images
if step != 0 and step % save_and_sample_every == 0:
milestone = step // save_and_sample_every
batches = num_to_groups(4, batch_size)
all_images_list = list(map(lambda n: sample(model, batch_size=n, channels=channels), batches))
all_images = torch.cat(all_images_list, dim=0)
all_images = (all_images + 1) * 0.5
save_image(all_images, str(results_folder / f'sample-{milestone}.png'), nrow = 6)
训练过程:
Loss: 0.5570111274719238
Loss: 0.06583500653505325
Loss: 0.06006840616464615
Loss: 0.051015421748161316
Loss: 0.0394190177321434
Loss: 0.04075610265135765
Loss: 0.039987701922655106
Loss: 0.03415030241012573
Loss: 0.030019590631127357
Loss: 0.036297883838415146
Loss: 0.037256866693496704
Loss: 0.03864285722374916
Loss: 0.03298967331647873
Loss: 0.03331328555941582
Loss: 0.027535393834114075
Loss: 0.03803558647632599
Loss: 0.03721949830651283
Loss: 0.03478413075208664
Loss: 0.03918925300240517
Loss: 0.03608154132962227
Loss: 0.027622627094388008
Loss: 0.02948344498872757
Loss: 0.029868196696043015
Loss: 0.03154699504375458
Loss: 0.029723389074206352
Loss: 0.039195798337459564
Loss: 0.032130151987075806
Loss: 0.031276602298021317
Loss: 0.03440115600824356
Loss: 0.030476151034235954
采样
要从模型中采样,可以使用上面定义的采样函数:
# sample 64 images
samples = sample(model, image_size=image_size, batch_size=64, channels=channels)
# show a random one
random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")
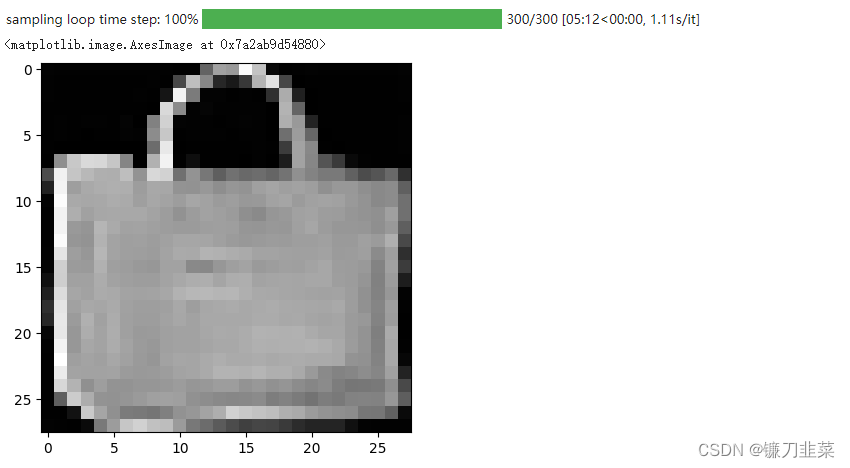
看起来模型能够生成一件漂亮的 T 恤!请记住,用来训练的数据集的分辨率非常低(28x28)。还可以创建去噪过程的 gif 图像:
import matplotlib.animation as animation
random_index = 53
fig = plt.figure()
ims = []
for i in range(timesteps):
im = plt.imshow(samples[i][random_index].reshape(image_size, image_size, channels), cmap="gray", animated=True)
ims.append([im])
animate = animation.ArtistAnimation(fig, ims, interval=50, blit=True, repeat_delay=1000)
animate.save('diffusion.gif')
plt.show()

后续阅读
注意,DDPM 论文表明,扩散模型是(无)条件图像生成的一个promising的方向。从DDPM提出到现在已经(极大地)得到了改进,尤其是在文本条件图像生成方面。下面,列出了一些截至到2022年6月7日之前的重要的(但远非详尽的)后续工作:
- Improved Denoising Diffusion Probabilistic Models (Nichol et al., 2021): 发现学习条件分布的方差(除均值外)有助于提高性能。
- Cascaded Diffusion Models for High Fidelity Image Generation (Ho et al., 2021): 引入了级联扩散,它包含多个扩散模型的pipeline,可生成分辨率不断提高的图像,用于高保真图像合成。
- Diffusion Models Beat GANs on Image Synthesis (Dhariwal et al., 2021): 表明扩散模型可以通过改进 U-Net 架构以及引入分类器引导,达到比SOTA生成式模型更好的效果。
- Classifier-Free Diffusion Guidance (Ho et al., 2021): 表明不需要使用分类器来指导扩散模型,只需要使用单个神经网络联合训练条件扩散模型和无条件扩散模型。
- Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2) (Ramesh et al., 2022): 使用先验将文字说明转换为 CLIP 图像嵌入,然后使用扩散模型将其解码为图像。
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (ImageGen) (Saharia et al., 2022): 表明将大型预训练语言模型(例如 T5)与级联扩散相结合非常适用于文本到图像合成
参考链接
- The Annotated Diffusion Model
- 带你深入理解扩散模型DDPM
- 扩散模型全新课程:扩散模型从0到1实现!
- Denoising Diffusion Probabilitistic Models
- 《Diffusion Models Beat GANs on Image Synthesis》阅读笔记
- How Diffusion Models Work
- DDPM交叉熵损失函数推导
- DDPM(Denoising Diffusion Probabilistic Models)扩散模型简述
- What are Diffusion Models?
- 由浅入深了解Diffusion Model
- 什么是Diffusion模型?
- Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读
- Denoising Diffusion Probabilistic Model, in Pytorch








![2023年中国政务云行业发展概况及发展趋势分析:政务云由基础设施建设向云服务运营转变[图]](https://img-blog.csdnimg.cn/img_convert/6a5e0b59ce7648dd6409f2e736af0c5b.png)