Python爬虫:抓取表情包的下载链接
- 1. 前言
- 2. 具体实现
- 3. 实现代码
1. 前言
最近发现了一个提供表情包的网址,觉得上面的内容不错,于是就考虑用Python爬虫获取上面表情包的下载链接。整体而言,实现这个挺简单的,就是找到提供表情包json数据的api接口即可,接口中没有任何加密操作。网址为:表情包
2. 具体实现
还是通过搜索功能,找到匹配搜索词的相关表情包,如下:

可以发现,当向下滑动滚动条时,表情包数据进行动态刷新增加,由此可以判定这个界面的表情包数据是通过请求api接口,然后一些js操作实现的。直接使用requests模块访问当前界面,你是无法访问到这个表情包数据的。实现上的确是这样,打开开发者工具,来到网络下的Fetch/XHR,可以找到一个api接口链接,打开这个接口,那里面有我们想要的表情包数据。
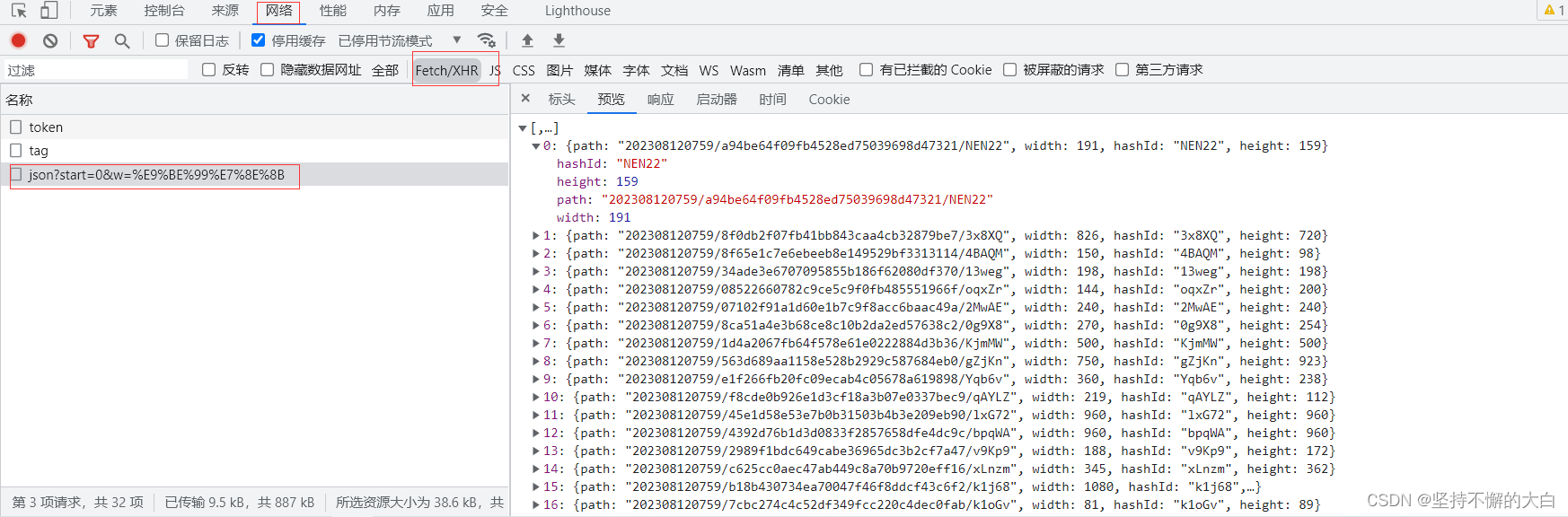
这个接口链接为:https://www.dbbqb.com/api/search/json?start=0&w=%E9%BE%99%E7%8E%8B,明显这个w后的参数值应该就是我们搜索的词进行的编码操作。
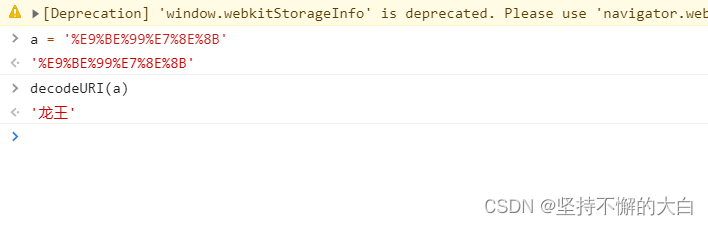
至于start后的参数值,应该用于分页的操作,通过向下滑动滚动条,发现这个参数值初始为0,第二页为100,第三页为200,。。。。。。
至于这个接口中的数据,的确是图片的下载链接,如下:

3. 实现代码
实现代码仅仅把这些表情包的下载链接获取到,至于怎样下载,读者自行操作。可以考虑使用
from urllib import request
url = 'https://image.dbbqb.com/202308120759/a94be64f09fb4528ed75039698d47321/NEN22'
request.urlretrieve(url=url,filename='龙王.png')
或者
import requests
url = 'https://image.dbbqb.com/202308120759/a94be64f09fb4528ed75039698d47321/NEN22'
rsp = requests.get(url=url)
with open(file='龙王2.png',mode='wb') as f:
f.write(rsp.content)
参考代码如下:
import requests
import json
from urllib import parse
from crawlers.userAgent import useragent
keyword = input('搜索关键词:')
pages = input('页数:')
u = useragent()
# pages
url2 = 'https://image.dbbqb.com/'
encode_kw = parse.quote(keyword)
print(encode_kw)
for i in range(int(pages)):
url = f'https://www.dbbqb.com/api/search/json?start={i*100}&w={encode_kw}'
print(f'第{i + 1}页->url:{url}')
headers = {
'user-agent':u.getUserAgent(),
"Accept":"application/json",
"Cache-Control":"no-cache",
"Connection":"keep-alive",
"Content-Type":"application/json",
"Cookie":"Hm_lvt_7d2469592a25c577fe82de8e71a5ae60=1690285252,1690367974,1690963288,1691797900; Hm_lpvt_7d2469592a25c577fe82de8e71a5ae60=1691798363",
"sec-ch-ua":";Not A Brand;v=99, Chromium;v=94",
"sec-ch-ua-mobile":"?0",
"sec-ch-ua-platform":"Windows",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"same-origin",
"Web-Agent":"web",
}
rsp = requests.get(url=url,headers=headers)
arr = json.loads(rsp.text)
for e in arr:
download_url = url2 + e['path']
print(download_url)
运行结果: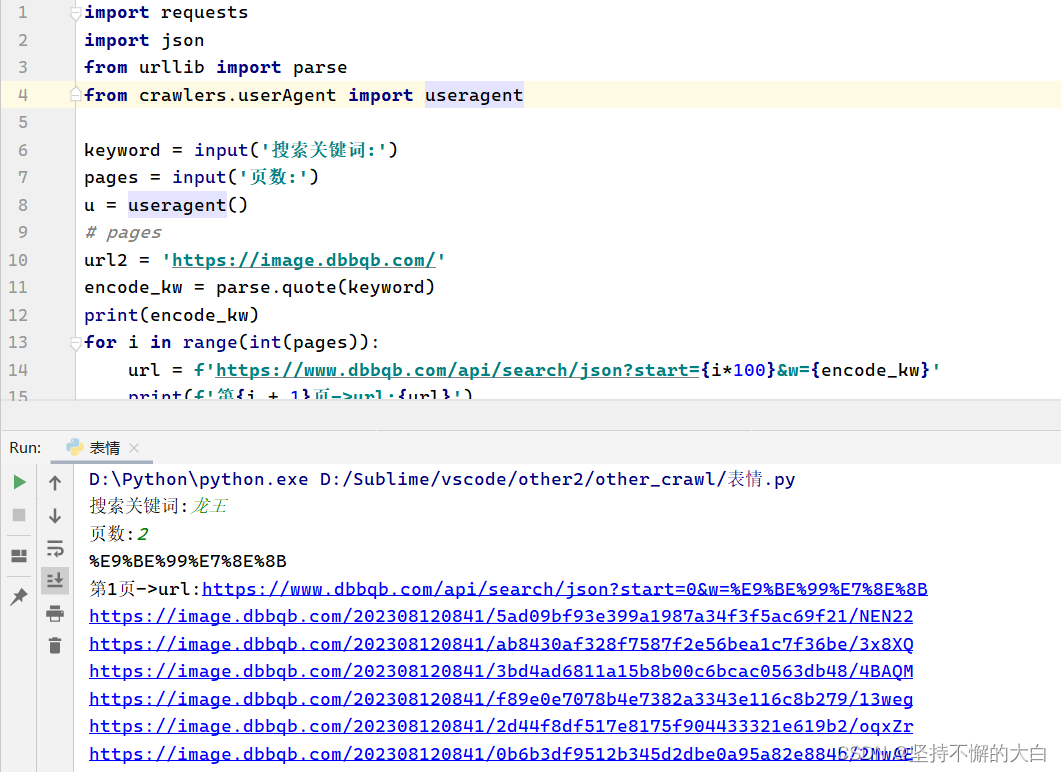
上述内容仅学习使用,不能用于商业活动,希望读者切记。
![Kubernetes pod调度约束[亲和性 污点] 生命阶段 排障手段](https://img-blog.csdnimg.cn/6f088c56456341a997a940efd0df442e.png)