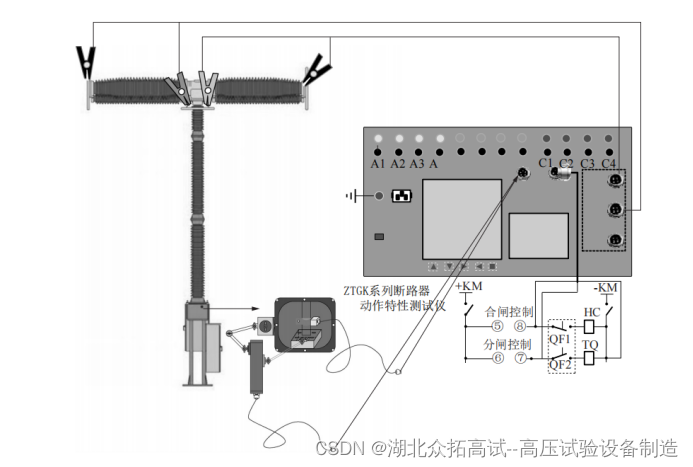
时间序列相关的项目在我之前的很多博文中都有涉及,覆盖的数据领域也是比较广泛的,很多任务或者是项目中往往是搭建出来指定的模型之后就基本完成任务了,比较少去通过实验的维度去探索分析不同参数对模型性能的影响,这两天正好有时间也有这么个机会,就想着从这个角度做点事情来对模型产生的结果进行分析。
数据可以使用任意时序的数据都是可以的,本质都是时间序列的数据即可。简单的实例数据如下所示:
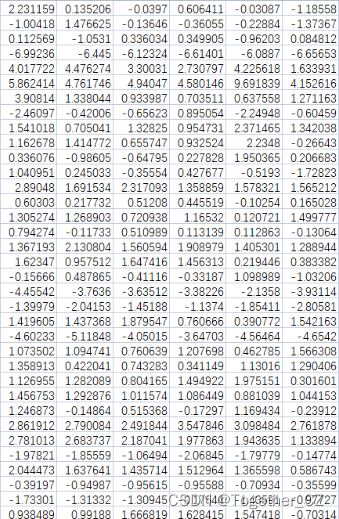
参考前面的博文即可知晓如何将时序数据转化为标准的预测数据集,这里就不再赘述了。
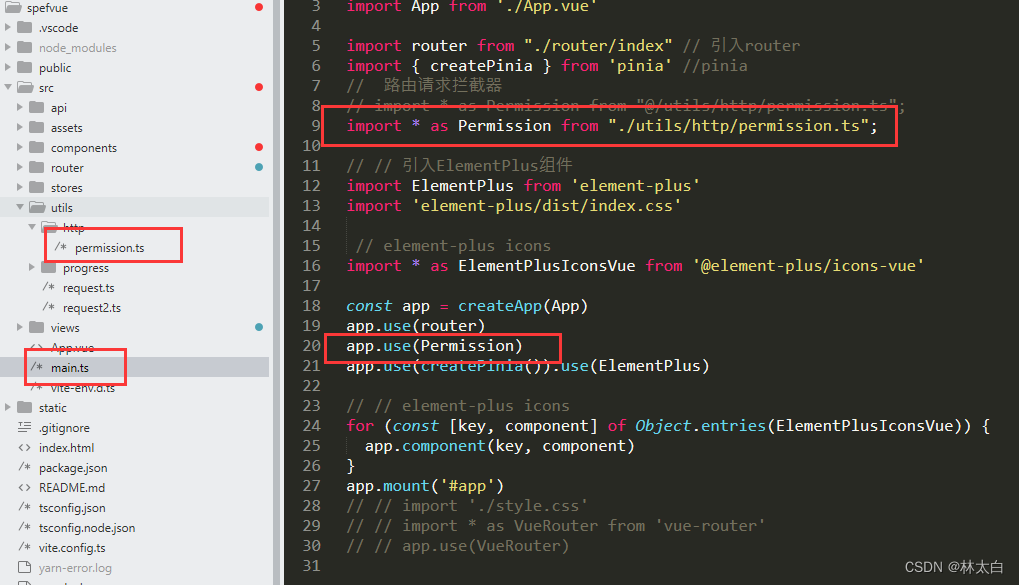
这里主要是想从实验角度来分析结果,基础模型构建如下所示,首先考虑的是模型层数产生的影响,这里层数从1叠加至3层:
def initModel(steps, features):
"""
模型初始化
"""
model = Sequential()
model.add(
LSTM(
64,
activation="relu",
input_shape=(steps, features),
kernel_regularizer=l2(0.001),
return_sequences=False,
)
)
model.add(Dense(features))
model.compile(optimizer="adam", loss="mse")
return model结果如下所示:
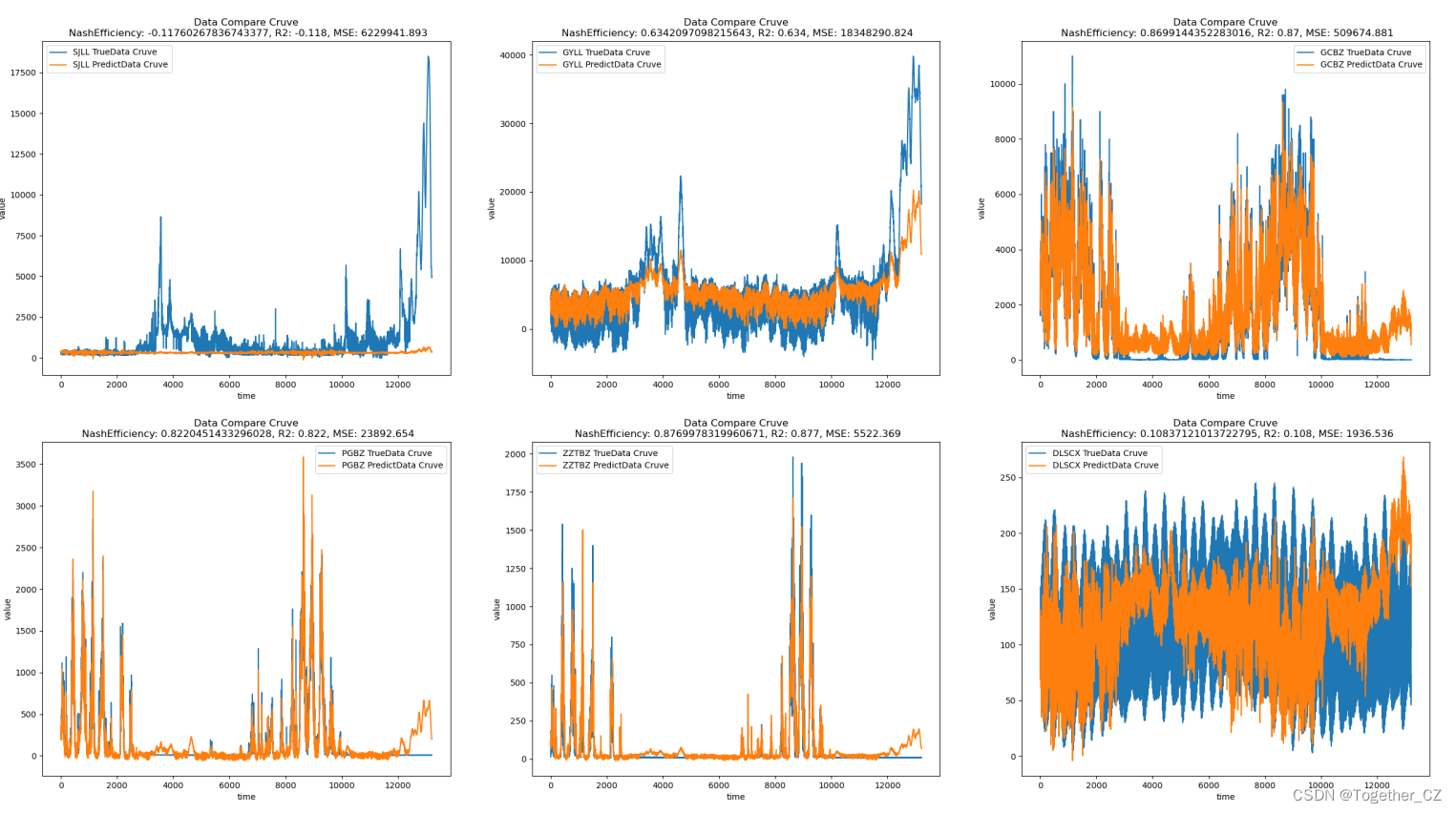
接下来是两层的,如下所示:
def initModel(steps, features):
"""
模型初始化
"""
model = Sequential()
model.add(
LSTM(
64,
activation="relu",
input_shape=(steps, features),
kernel_regularizer=l2(0.001),
return_sequences=True,
)
)
model.add(LSTM(64, activation="relu", kernel_regularizer=l2(0.001)))
model.add(Dense(features))
model.compile(optimizer="adam", loss="mse")
return model
结果如下所示:
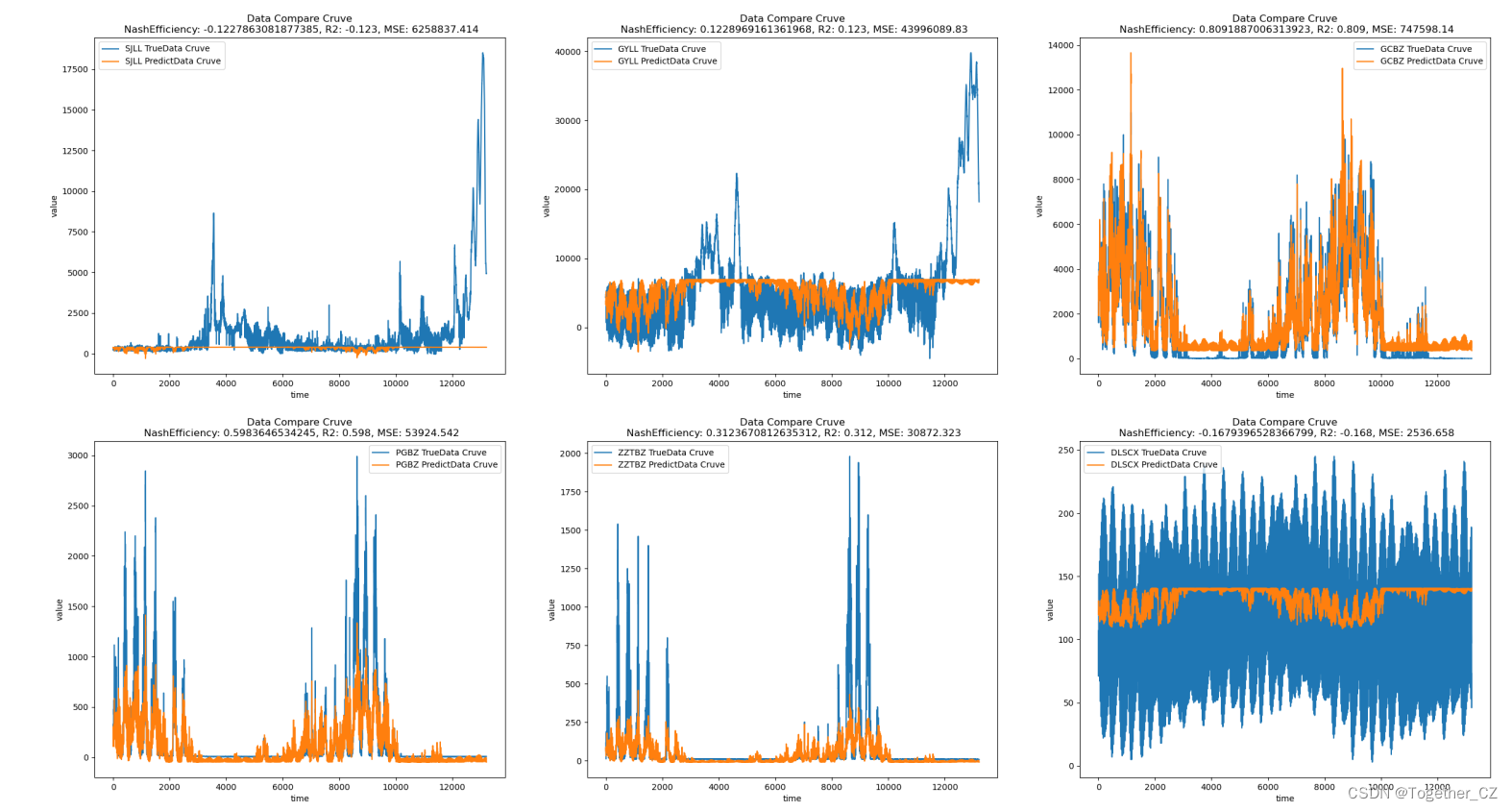
最后是3层的,如下所示:
def initModel(steps, features):
"""
模型初始化
"""
model = Sequential()
model.add(
LSTM(
64,
activation="relu",
input_shape=(steps, features),
kernel_regularizer=l2(0.001),
return_sequences=True,
)
)
model.add(LSTM(64, activation="relu", kernel_regularizer=l2(0.001),return_sequences=True))
model.add(LSTM(64, activation="relu", kernel_regularizer=l2(0.001)))
model.add(Dense(features))
model.compile(optimizer="adam", loss="mse")
return model结果如下所示:
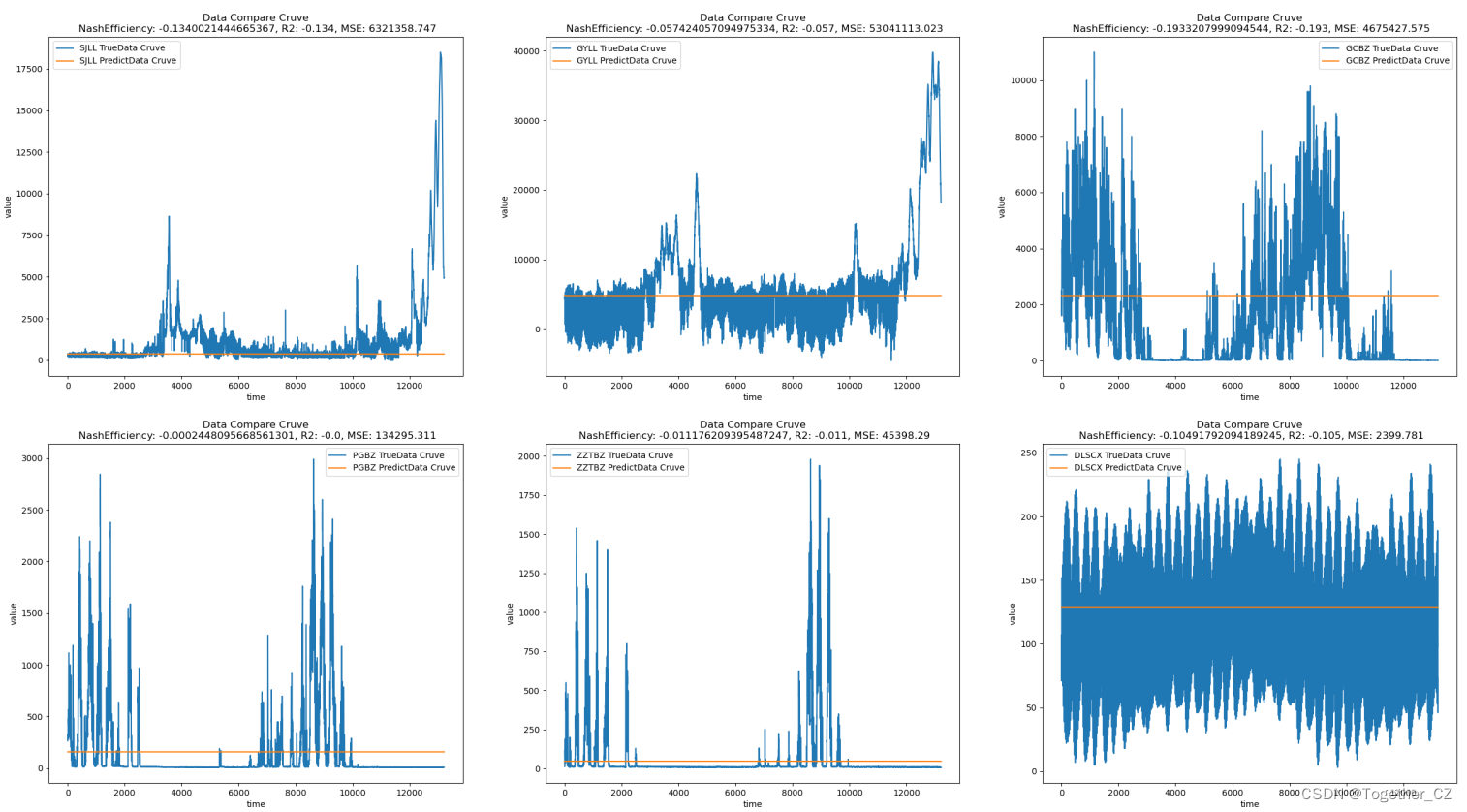
直观体验下来是层数的增加并没有带来提升,反而是带来了崩溃式的结果。
接下来想要看下同样结构下,改变参数值带来的变化。
简单的实例如下所示:
def initModel(steps, features):
"""
模型初始化
"""
model = Sequential()
model.add(
LSTM(
128,
activation="relu",
input_shape=(steps, features),
kernel_regularizer=l2(0.001),
return_sequences=False,
)
)
model.add(Dense(features))
model.compile(optimizer="adam", loss="mse")
return model结果如下所示:
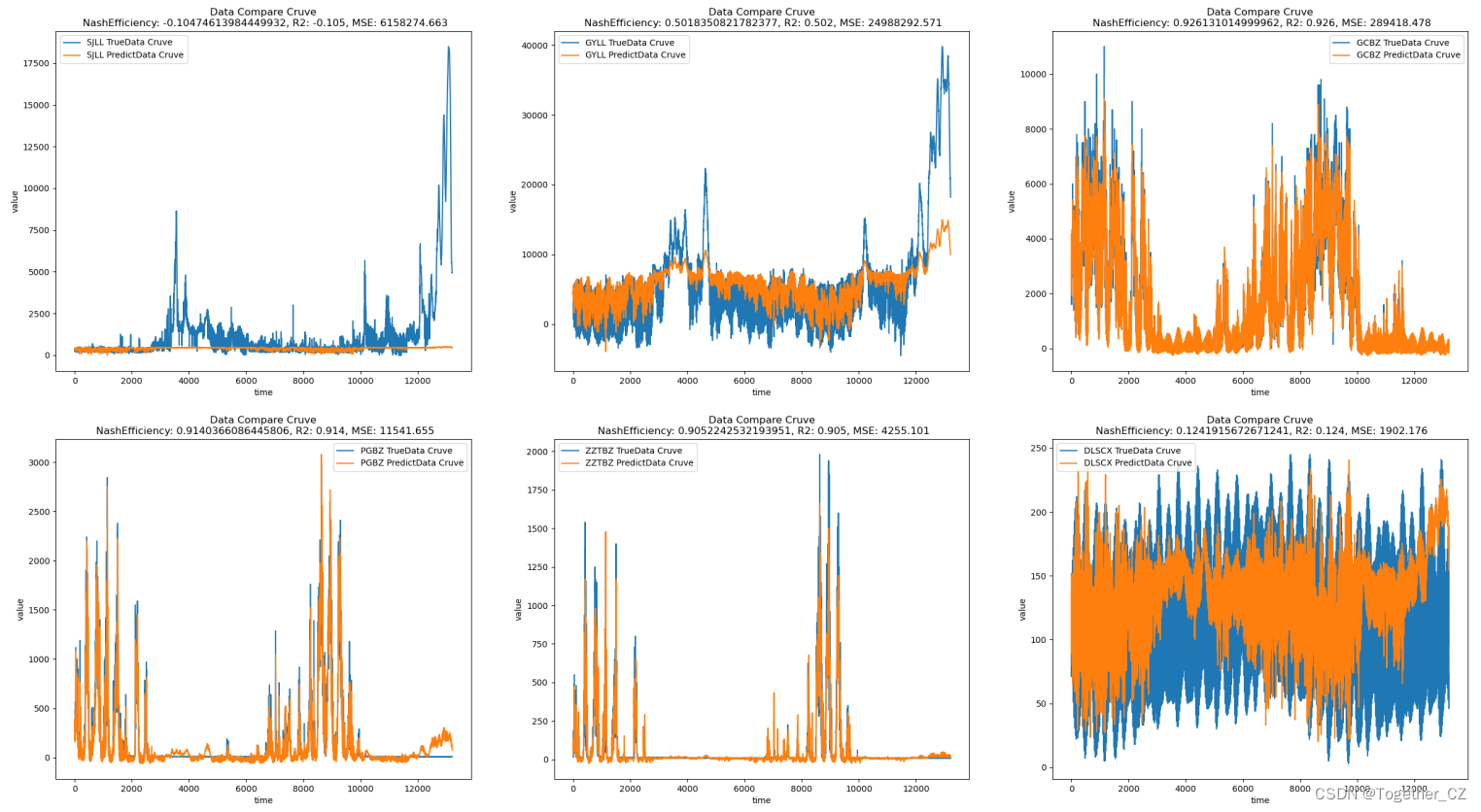
接下来同样的思路改变参数,结果如下所示:
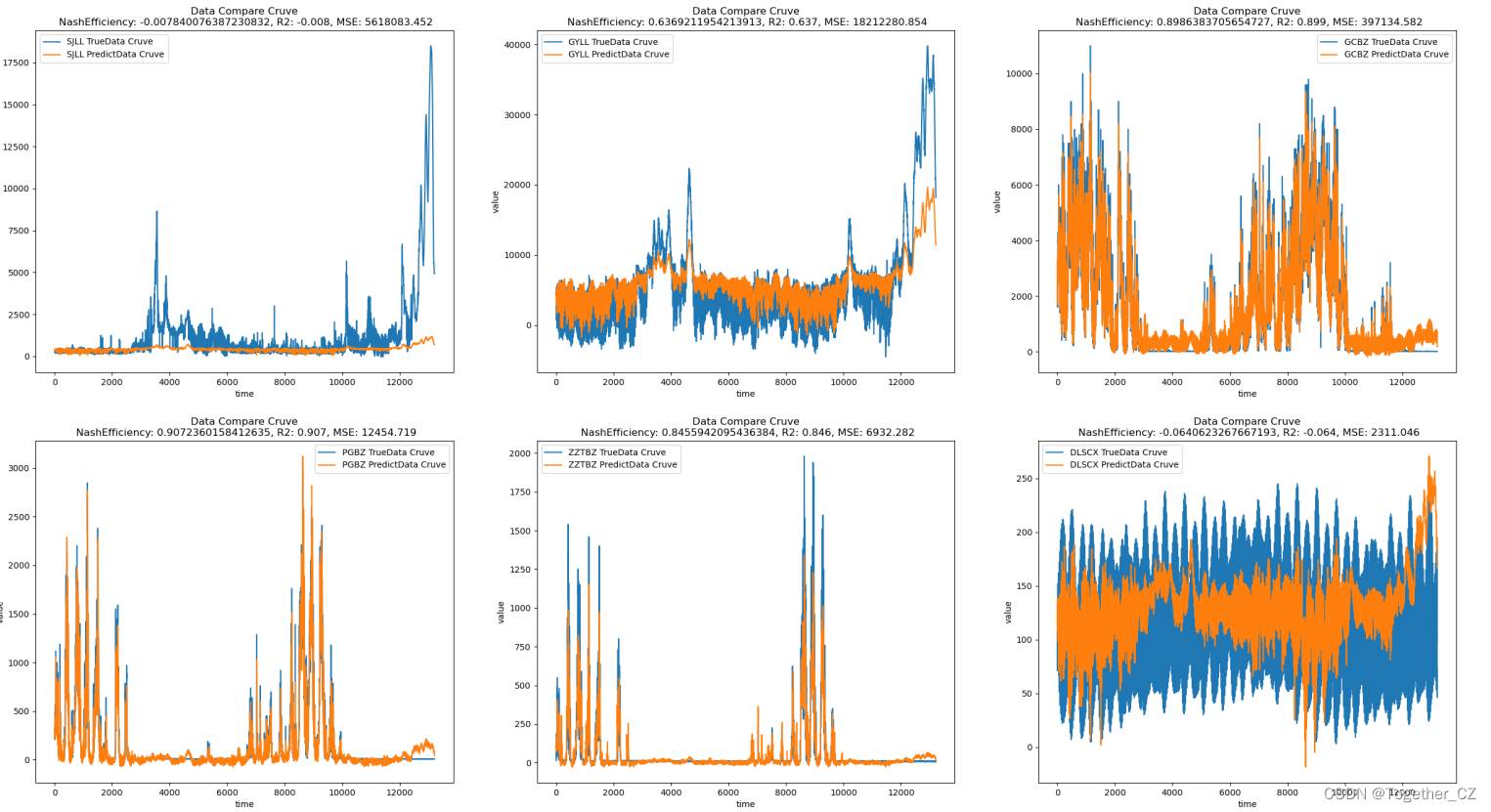
参数的调整能带来一定的改变但是限定在一定的复读内,接下来考虑借鉴之前目标检测里面的方案来改造设计新的结构,借助于搜索技术可以事半功倍,结果如下所示:
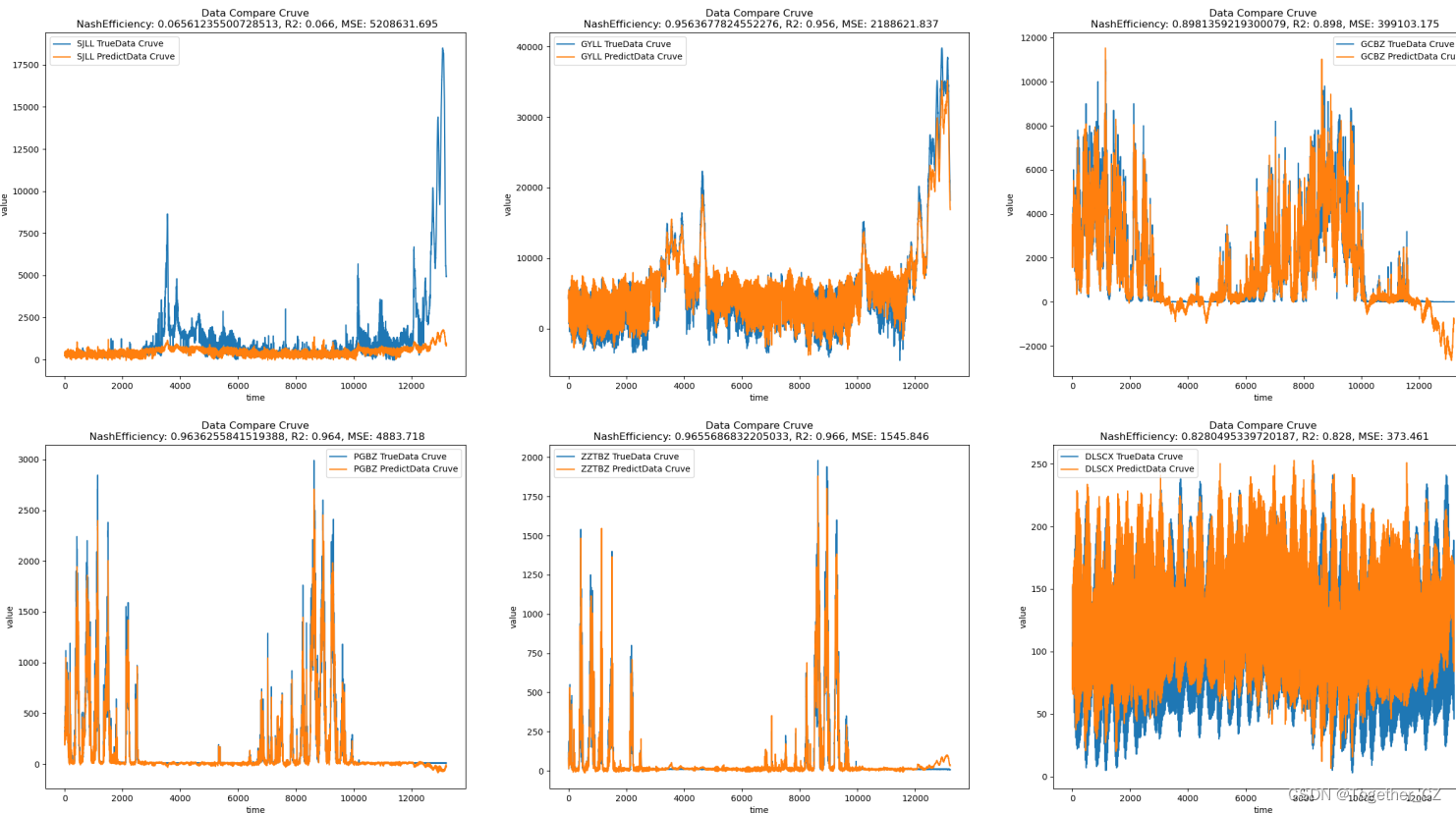
可以看到:结果有了质的提升。后面有时间再继续深度研究下。