目录
绪论
1、正则表达式
1.1 通配符
1.2 正则表达式分类
1.3 基本正则
1.4 正则表达式中表示次数的表达式
1.5 位置锚定
1.5.1 词首锚定和词尾锚定
1.6 分组()
1.7 逻辑或
1.8 扩展正则
绪论
正则表达式:有一类特殊字符以及文本字符所编写的一种模式,用来处理文本当中的内容,其中的一些字符不表示字符的字面含义,表示控制或者通配的功能
通配符:只能匹配文件名与目录名,不能匹配文件的内容
1、正则表达式
1.1 通配符
只能匹配文件名与目录名,不能匹配文件的内容
*匹配任意一个或者多个字符
touch 1.txt 2.txt 3.txt
ls *.txt
?匹配任意一个字符(就是匹配单个字符)
ls ?.txt
[ ] 匹配范围内的任意单个字符
touch {a..z}.txt
ls [a-n].txt
1.2 正则表达式分类
· 基本正则表达式
· 扩展正则表达式
1.3 基本正则
字符匹配,元字符
. 匹配任意的单个字符,可以是一个汉字,\表示转义符,\.就是一个点
eg:ls | grep "12." 输出为123.txt
"()括号表示分组的意思",\(\)就是括号
eg:"[]"匹配指定范围内的任意单个字符
ls | grep "[0-9]"
eg:大小写和数字一起匹配
ls | grep "[0-9A-Za-z]"
eg:"[^]"取反,指定范围之外的
ls | grep "[^A-Z]"
[[:space:]]包含空格,tab键,换行的空格,回车的空格
[[:blank:]] 空白字符(空格和tab制表符)
eg:以rc开头的任意单个字符0-6的数字
ls /etc | grep "rc[0-6]"
eg:只匹配以rc开头的文件,.不是正则
ls /etc | grep "rc\."
通配符不能完全匹配大小写, 正则可以
1.4 正则表达式中表示次数的表达式
" * "匹配前面的字符任意次,0次也行,无数次也行,有多少匹配多少(贪婪模式),没有也行
eg:
echo goole | grep "go*gle" 输出为google
echo ggle | grep "go*gle" 输出为ggle
" .* "匹配任意长度的字符,至少要有一次,不包括0次
eg:
echo goole | grep "go.*gle" 输出为google
echo ggle | grep "go.*gle" 此时匹配不到
" \?"匹配前面的字符0次或者一次,可有可无
" \+ " 匹配前面的字符至少1次,最多可以无数次
eg:
echo ggle | grep "go\+gle"
\{n\}匹配前面的字符等于n次,必须连续出现才能匹配
eg:echo gogle | grep "go\{|\}gle"
\{m,n\}匹配前面的字符,最少m次,最多n次
\{,n\}匹配前面的字符,最多n次(只要出现几次,出现都算,除非没有,只要前面的字符有,都算)
eg:echo ggle | grep "go\{,3}gle"
\{n,\}匹配前面的字符至少n次
1.5 位置锚定
^ 以什么为开头,在模式的左侧
eg:cat /etc/passwd | grep "^root"
$ 以什么为结尾,在模式的右侧 r$表示以r为结尾
^root$ 用于匹配整行,而且整行中只有以后个root
^$ / ^[[:space:]]$ 匹配空行
1.5.1 词首锚定和词尾锚定
词首锚定 \< 或者 \b
词尾锚定 \> 或者 \b
根据\b的前后位置判断
eg:echo hello-123 | grep "123\b"
输出为标红的hello-123
echo hello-123 | grep "\bhello"
输出为标红的hello-123
\<root\> 表示匹配整个单词
1.6 分组()
echo abccc | grep "abc\{3\}"
输出为abccc
\{n\}表示正好出现n次,n次表示前面的字符必须要连续出现才能匹配
\{,n}只要你出现几次都算,除非没有
eg:echo golgogle | grep "\(go \)\{}\}gle"
输出为gogle
\(go\)是一个租,连续的go只出现一个,两个不连续的go都出现
1.7 逻辑或
\|:斜杠管道符表示逻辑或
echo | abc2abc | grep "(1\|2\)abc"
1.8 扩展正则
不用写斜杠了
需要使用grep -E 或者egrep
echo 1abc2abc | grep -E "(1|2)abc"
匹配邮箱号码 :
vim /opt/pipei.txt
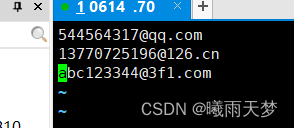
cat pipei.txt | grep -E "[0-9a-z]{9,11}@[0-9a-z]{2,3}\.[a-z]{2,3}



![Java并发编程(三)线程同步 上[synchronized/volatile]](https://img-blog.csdnimg.cn/a07261944dfa424c8df9453179a0257d.png)