一、说明
在LangChain的帮助下创建LLM应用程序可以帮助我们轻松地链接所有内容。LangChain 是一个创新的框架,它正在彻底改变我们开发由语言模型驱动的应用程序的方式。通过结合先进的原则,LangChain正在重新定义通过传统API可以实现的极限。
在上一篇博客中,我们详细讨论了 LangChain 中存在的模块,对其进行了修改。
实际实施 LangChain 以构建自定义数据机器人涉及合并内存、提示模板和链,以及创建基于 Web 的应用程序。
钦迈·巴勒劳
二、让我们从导入开始
导入 LangChain 和 OpenAI for LLM 部分。如果您没有任何这些,请安装它。
# IMPORTS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import ConversationalRetrievalChain
from langchain.vectorstores import ElasticVectorSearch, Pinecone, Weaviate, FAISS
from PyPDF2 import PdfReader
from langchain import OpenAI, VectorDBQA
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.document_loaders import TextLoader
# from langchain import ConversationalRetrievalChain
from langchain.chains.question_answering import load_qa_chain
from langchain import LLMChain
# from langchain import retrievers
import langchain
from langchain.chains.conversation.memory import ConversationBufferMemory py2PDF 用于阅读和处理 PDF。此外,还有不同类型的记忆,它们具有特定的功能要执行。我正在写这个系列的下一个博客,专门讨论记忆,所以我将在那里详细说明所有内容。ConversationBufferMemory, ConversationBufferWindowMemory
三、让我们设置环境。
我想你知道如何获得OpenAI API密钥。但以防万一,
- 转到 OpenAI API 页面,
- 单击创建新的密钥
- 这将是您的 API 密钥。粘贴到下面
import os
os.environ["OPENAI_API_KEY"] = "sk-YOUR API KEY"使用哪种模型?达芬奇、巴贝奇、居里还是艾达?基于 GPT 3?基于 GPT 3.5 还是基于 GPT 4?关于模型有很多问题,所有模型都适用于不同的任务。很少有便宜的,很少有更准确的。我们还将在本系列的第 4 篇博客中详细介绍所有模型。
为简单起见,我们将使用最便宜的型号“gpt-3.5-turbo”。温度是一个参数,它让我们了解答案的随机性。温度值越大,我们得到的随机答案就越多。
llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")您可以在此处添加自己的数据。您可以添加任何格式,如PDF,文本,文档,CSV。根据您的数据格式,您可以注释/取消注释以下代码。
# Custom data
from langchain.document_loaders import DirectoryLoader
pdf_loader = PdfReader(r'Your PDF location')
# excel_loader = DirectoryLoader('./Reports/', glob="**/*.txt")
# word_loader = DirectoryLoader('./Reports/', glob="**/*.docx")我们不能一次添加所有数据。我们将数据拆分为块并发送它以创建数据的嵌入。如果你不知道什么是嵌入,那么
嵌入以数值向量或数组的形式捕获模型操作和生成的令牌的本质和上下文信息。这些嵌入派生自模型的参数或权重,用于编码和解码输入和输出文本。


这就是创建嵌入的方式。我从CODEBASIC截取了这些截图,这是一个学习LLM的好渠道,[来源:这里]
简单来说,
嵌入LLM是一种将文本表示为数字向量的方法。这允许语言模型理解单词和短语的含义,并执行文本分类、摘要和翻译等任务。通俗地说,嵌入是一种将单词转换为数字的方式。这是通过在大型文本语料库上训练机器学习模型来完成的。该模型学习将每个单词与唯一的数字向量相关联。这个向量表示单词的含义,以及它与其他单词的关系。

来源:官方语言链博客
让我们做与上图中表示完全相同的事情。
#Preprocessing of file
raw_text = ''
for i, page in enumerate(pdf_loader.pages):
text = page.extract_text()
if text:
raw_text += text
# print(raw_text[:100])
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)
texts = text_splitter.split_text(raw_text) 实际上,当用户启动查询时,将在向量存储中进行搜索,并检索最合适的索引并将其传递给LLM。然后,LLM 对索引中找到的内容进行改革,以向用户提供格式化的响应。
我建议进一步深入研究向量存储和嵌入的概念,以增强您的理解。
embeddings = OpenAIEmbeddings()
# vectorstore = Chroma.from_documents(documents, embeddings)
vectorstore = FAISS.from_texts(texts, embeddings)嵌入直接存储在向量数据库中。有许多矢量数据库为我们工作,如松果、FAISS等。让我们在这里使用FAISS。
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say GTGTGTGTGTGTGTGTGTG, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
QA_PROMPT = PromptTemplate(
template=prompt_template, input_variables=['context',"question"]
)您可以使用自己的提示来优化查询和答案。写完提示后,让我们将其链接到最终的链。
让我们调用最后一个链,它将包括我们之前链接的所有内容。我们在这里使用ConversationalRetrievalChain。这有助于我们像人类一样与机器人进行对话。它会记住以前的聊天对话。
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.8), vectorstore.as_retriever(),qa_prompt=QA_PROMPT)我们将使用简单的Gradio来创建Web应用程序。您可以使用流光或任何前端技术。此外,还有许多免费的部署选项可用,例如在拥抱脸或本地主机上部署,我们可以稍后再做。
# Front end web app
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("## Grounding DINO ChatBot")
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.Button("Clear")
chat_history = [] def user(user_message, history)
print("Type of use msg:",type(user_message))
# Get response from QA chain
response = qa({"question": user_message, "chat_history": history})
# Append user message and response to chat history
history.append((user_message, response["answer"]))
print(history)
return gr.update(value=""), history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False)
clear.click(lambda: None, None, chatbot, queue=False)
############################################
if __name__ == "__main__":
demo.launch(debug=True)此代码将启动指向 Web 应用的本地链接,你直接提出问题并查看响应。同样在 IDE 中,您将看到正在维护的聊天记录。
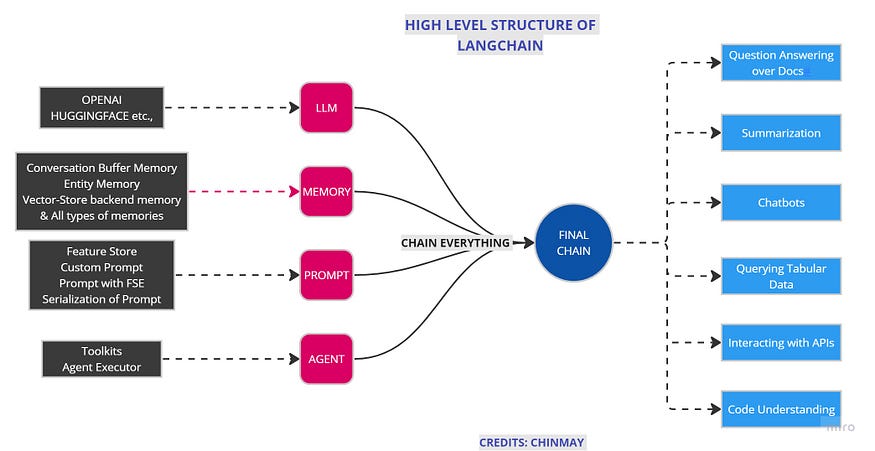
LangChain 的快照 [图片来源:作者]
今天就够了。这是一个简单的介绍,用于链接不同的模块并使用它们来启动最终链。您可以通过扭曲不同的模块和代码来做很多事情。我想说,玩耍是研究的最高形式!!
在下一篇博客中,我将介绍 LangChain 中的记忆和模型。如何选择模型,记忆如何做出贡献,以及更多......因此,请继续关注,如果有任何建议或问题,请与我联系。
四、如果您发现这篇文章有见地
事实证明,“慷慨使你成为一个更快乐的人”;因此,如果您喜欢这篇文章,请为它鼓掌。如果您觉得这篇文章很有见地,请在LinkedIn和媒体上关注我。您也可以订阅以在我发布文章时收到通知。让我们创建一个社区!感谢您的支持!