一、hashMap的底层实现hashmap的底层结构在jdk1.7之前是数组+链表,但是在jdk1.8以后,其变成了数组+链表+红黑树,
这个操作会加快在链表时候的查询速度。
当链表的长度大于8 的时候,链表就会变为红黑树,而当长度小于6的时候,会从红黑树变回链表。
这里又有一个问题:为什么是8 和 6 这两个阈值呢?
因为TreeNodes的大小大约是常规节点的两倍,我们只在bins包含足够的节点来保证使用时才使用它们(参见TREEIFY_THRESHOLD)。
当它们变得太小(由于删除或调整大小)时,它们被转换回普通容器。 在使用分布良好的用户hashCodes时,很少使用树容器。
理想情况下,在随机hashCodes下,bin中的节点频率遵循泊松分布(http://en.wikipedia.org/wiki/Poisson_distribution),默认调整大小阈值为0.75,参数平均约为0.5,尽管由于调整粒度而存在很大的差异。
忽略方差,列表大小k的预期出现次数为(exp(-0.5) * pow(0.5, k) / factorial(k))。
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
如果不设退化阀值,只以8来树化与退化: 那么8将成为一个临界值,时而树化,时而退化,此时会非常影响性能,因此,我们需要一个比8小的退化阀值;
UNTREEIFY_THRESHOLD = 7 同样,与上面的情况没有好多少,仅相差1个元素,仍旧会在链表与树之间反复转化;
那为什么是6呢? 源码中也说了,考虑到内存(树节点比普通节点内存大2倍,以及避免反复转化),所以,退化阀值最多为6。HashMap有4个构造器,其他构造器如果用户没有传入initialCapacity 和loadFactor这两个参数,会使用默认值initialCapacity(初始容量)默认为16,loadFactory默认为0.75
那么负载因子为什么是0.75 呢?
负载因子 = 1.0
负载因子为1.0时,意味着,只有当 table 全部被填满,table 才会扩容;当 table 中的元素越来越多时,会出现大量的冲突:
若此时是链表,则查询效率是 O(n),即线性;(插入/删除结点也要遍历到链表);
若此时是红黑树,查询效率是 O(logN),但红黑树的插入与删除就异常复杂,每次都要调整树;
因此,负载因子1.0,实际是牺牲了时间,但保证了空间的利用率。
负载因子 = 0.5
负载因子为0.5时,意味着,当 table 中的元素达到一半时,就发生扩容,table 容量扩大一倍:
hash 冲突减少;
链表长度不会很长;
即便链表长度超过8时转成红黑树,树的高度也不会很高;
查询效率提高了,但这里,我们发现,会有大量的内存浪费,因为数组中的个数永远小于数组长度的一半。
因此,负载因子0.5,实际是牺牲了空间,但保证了时间效率。
负载因子在【0.5 1.0】分别对应着时间极端和空间极端,为了平衡这两个极端的情况,于是就进行了中和,使用了0.75这个中间的负载因子,为了平衡时间和空间成本hashMap不是线程安全的。因为其中的方法没有使用synchronized 来修饰方法hashMap的put方法
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断当前确定的索引位置是否存在相同hashcode和相同key的元素,
//如果存在相同的hashcode和相同的key的元素,那么新值覆盖原来的旧值,并返回旧值。
//如果存在相同的hashcode,那么他们确定的索引位置就相同,这时判断他们的key是否相同,
//如果不相同,这时就是产生了hash冲突。
//Hash冲突后,那么HashMap的单个bucket里存储的不是一个 Entry,而是一个 Entry 链。
//系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的Entry
//位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),
//那系统必须循环到最后才能找到该元素。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
二、hashMap的扩容机制
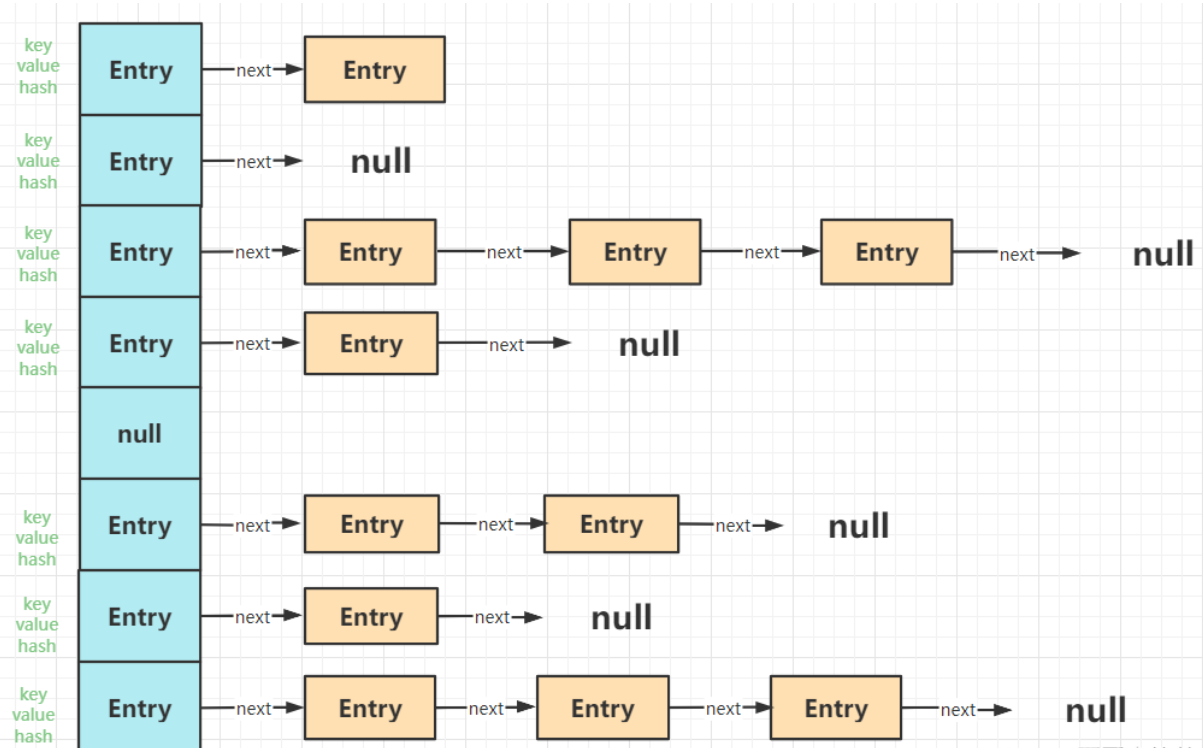
三、什么是hash冲突
根据key(键)即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经被占用了。这就是所谓的hash冲突。四、hashMap如何解决hash冲突1)开放定址法
该方法也叫做再散列法,其基本原理是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi 。2)再Hash法
这种方法就是同时构造多个不同的哈希函数: Hi=RH1(key) i=1,2,…,k。当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。3)链地址法(Java就是采用这种方法)
其基本思想: 将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。4)建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
本文章学习参考以下文章:https://blog.csdn.net/jiu_mu_mu/article/details/120919564https://blog.csdn.net/abcd1430/article/details/52745155https://blog.csdn.net/weixin_42398171/article/details/112096446https://www.jianshu.com/p/a7a76c5b8435https://www.jianshu.com/p/f323f4b0c109










![[附源码]Node.js计算机毕业设计儿童成长记录与分享系统Express](https://img-blog.csdnimg.cn/922237a72f9e44fb904dc81c8ef0354a.png)