Python进阶
| 1. 模块和包 2. random随机数 3. datetime日期模块 4. pandas和DataFrame |
1. 模块和包
| 1.1 模块:就是一个以.py结尾的文件,模块中可以定义函数,类和变量,可执行的代码 Python模块分为:内置模块和第三方模块
(1)模块安装:pip3 install 模块名1 -i 国内镜像地址 (或在pycharm中设置àpython解释器) 华为镜像源 https://mirrors.huaweicloud.com/ 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/ 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/ 浙江大学开源镜像站 http://mirrors.zju.edu.cn/ 腾讯开源镜像站 http://mirrors.cloud.tencent.com/pypi/simple 豆瓣 http://pypi.douban.com/simple/ 网易开源镜像站 http://mirrors.163.com/ 搜狐开源镜像 http://mirrors.sohu.com/ (2)导入模块中全部功能:import 模块名1 as 别名,模块名2 as别名2 部分功能:from 模块名 import 函数名1 as别名1,函数名2 as 别名2 (3)导入模块后使用方式:模块名/别名.函数/变量名 |
| 1.2 包:包中包含多个模块,可以将多个功能相似或关联的模块放在一起管理 |
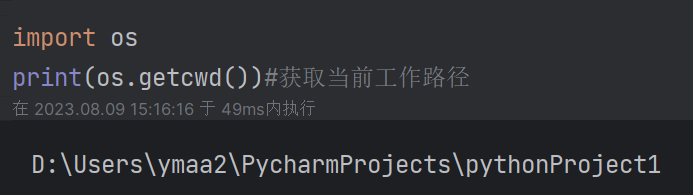
| 1.3 os模块常用方法: (1)获取当前工作路径:getcwd()
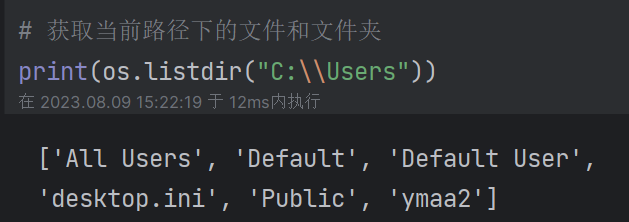
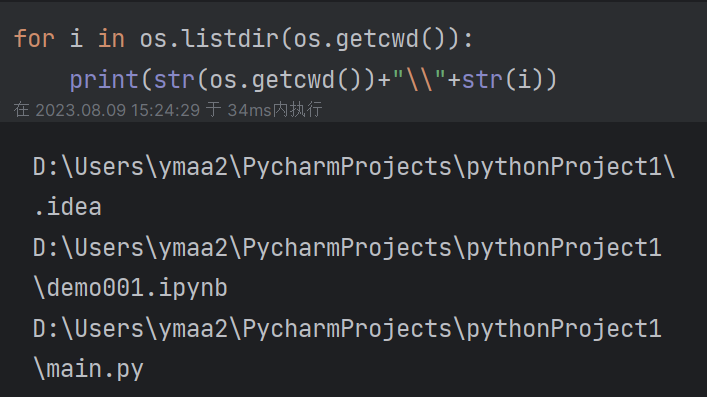
(2)获取当前路径下的文件及文件夹列表:listdir()或walk()
(3)判断路径下的文件是否存在:.path.exists("路径")
(4)创建文件夹:mkdir("路径")创建单个文件夹,当文件存在时无法创建, makedirs()递归创建多个嵌套文件夹
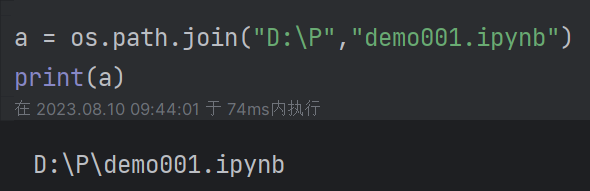
(5)删除文件夹:rmdir("路径"),只能删除空文件夹 (6)路径拼接:os.path.join("路径1","路径2")
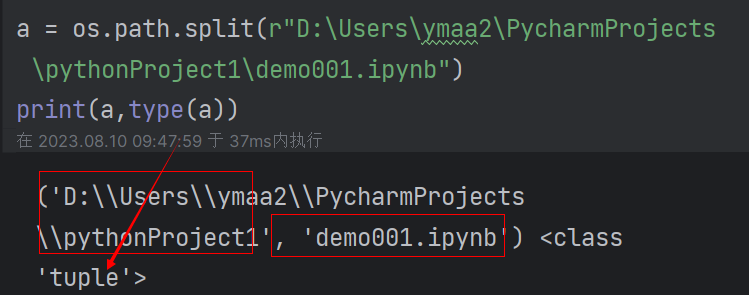
(7)拆分路径:os.path.split(path)拆成绝对路径和文件名
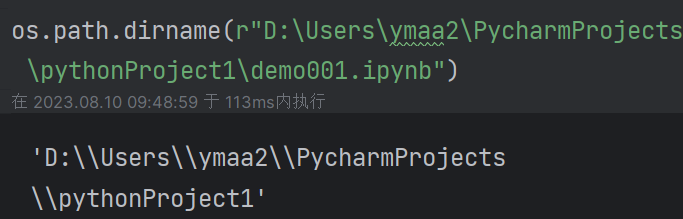
(8)获取绝对路径:os.path.dirname(path)
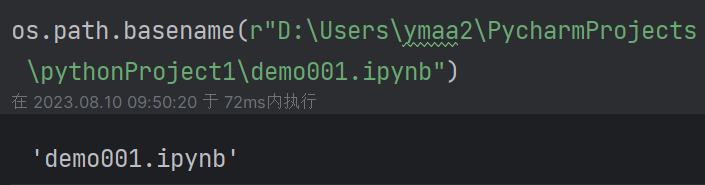
(8)获取文件名:os.path.basename(path)
(9)判断路径是否为文件夹:os.path.isdir(path)
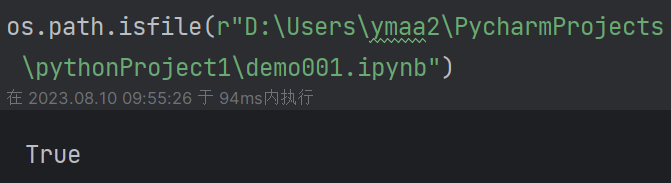
判断路径是否为文件:os.path.isfile(path)
(10)返回当前操作系统下的路径分隔符:os.path.sep
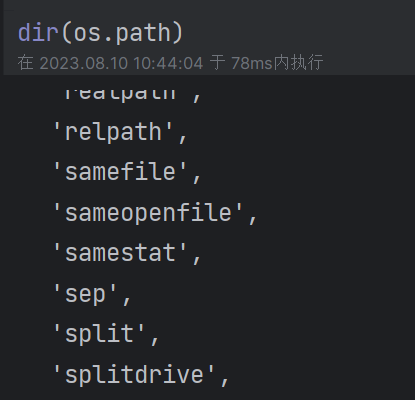
(11)查看文件字节大小:os.path.getsize(path) (12)查看当前模块下的模块或方法:dir()
|







2.random随机数
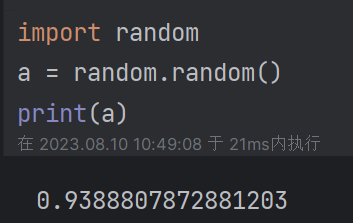
| 2.1 常用方法: (1)random.random():随机产生0-1 的浮点数
(2)random.randint(a,b):随机生成a,b之间的随机整数
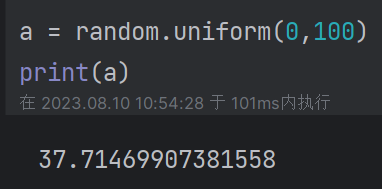
(3)random.uniform(a,b):随机生成a,b之间的浮点数
(3)random.choice(序列):随机从序列中生成一个随机数
(4)random.sample(序列,长度):随机从序列中获得指定长度的随机数
(5)random.shuffle(序列):打乱
|




3.datetime日期模块
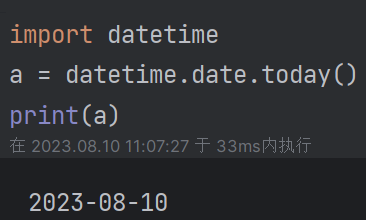
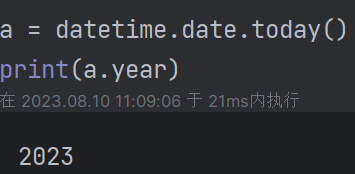
| 3.1 date (1)获取当前日期:datetime.date.today(),获取年,月,日
|
| 3.2 time 时间转换
|
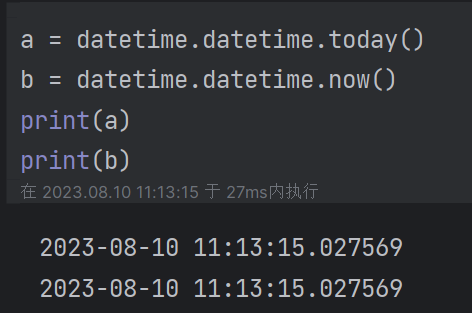
| 3.3 datetime:now()获得程序当前时间,today()获得今天时间
|
| 3.4 timedelta |
| 3.5 tzinfo虚拟基 |

4.pandas和DataFrame
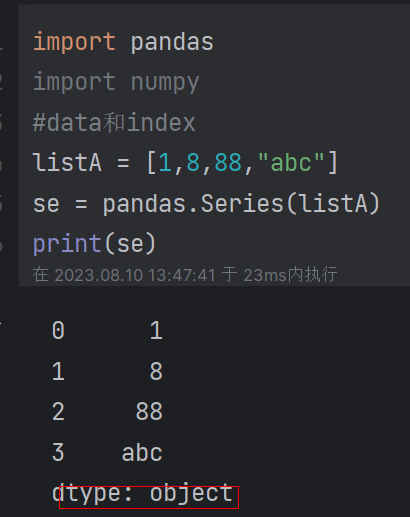
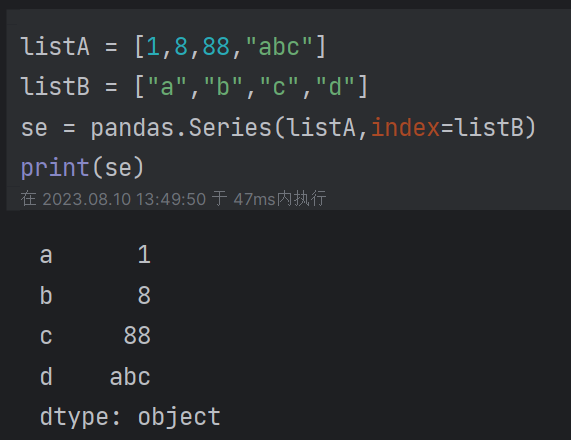
| 4.1 series:是pandas中一维的、可变长度的、有序的、带标签的数组 (1)series的生成:通过列表、字典、标量等等可迭代对象生成(可指定索引)
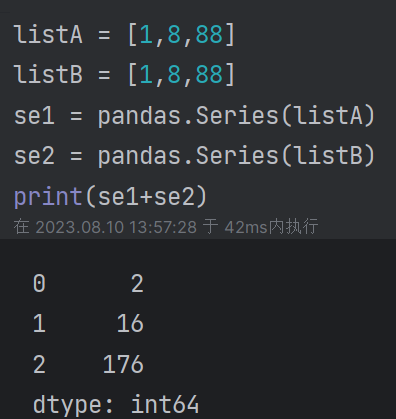
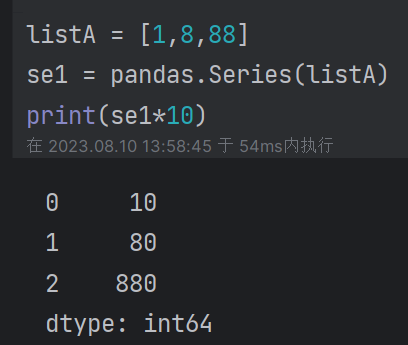
(2)series矢量计算:
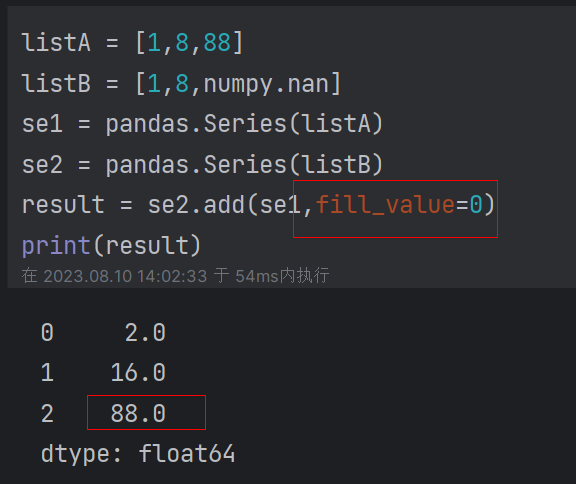
numpy.nan 为空值:任意计算都为空,需做处理为0后计算
索引对齐:索引相同的可以直接计算,索引不同的自动补齐NaN值计算出空值
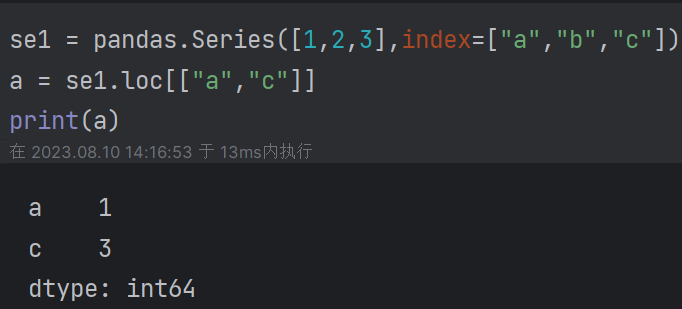
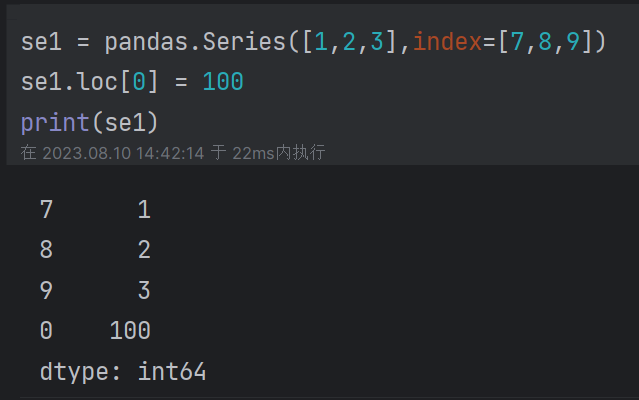
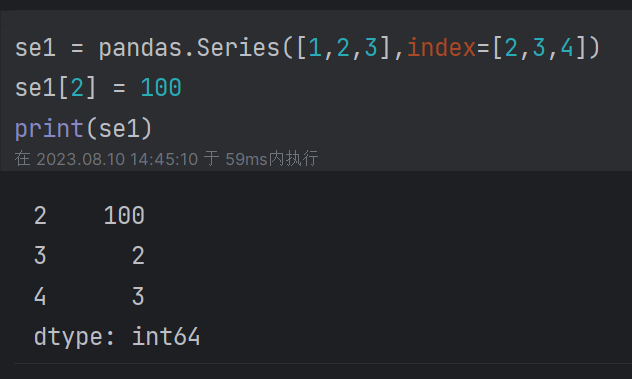
(3)位置索引(通过iloc[]取值)和标签索引(通过loc[]取值):
(4)切片: 通过位置索引切片:series名.iloc[start : stop : step](左闭右开)
或通过标签索引切片:series名.loc[start : stop : step](左闭右闭)
(5)添加或修改值:有该索引则修改,无则新增(位置索引只能修改,不能用此方法新增)
(6)删除元素(默认inplace=False,删除则为原地操作True):原地操作即在原件中操作,False则为复制一份再删除
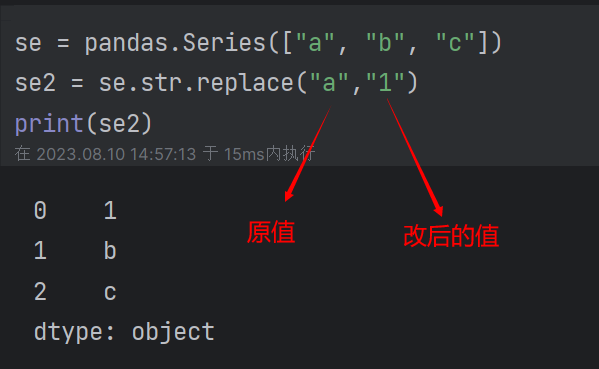
(7)其他常用函数:add(),sub(),div(),mul(),isnull(),notnull(),sum(),max()........ replace():替换操作
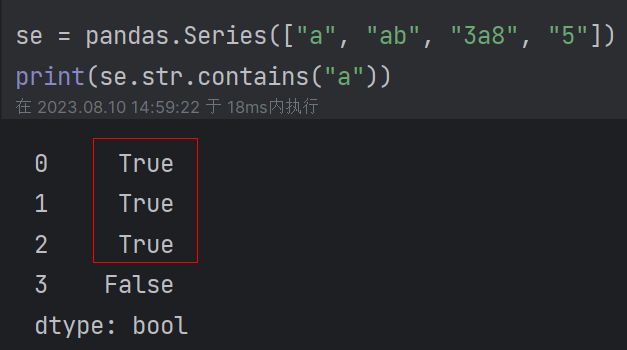
contains():查看每个元素是否包含某个字符,每次判断返回一个bool值
|
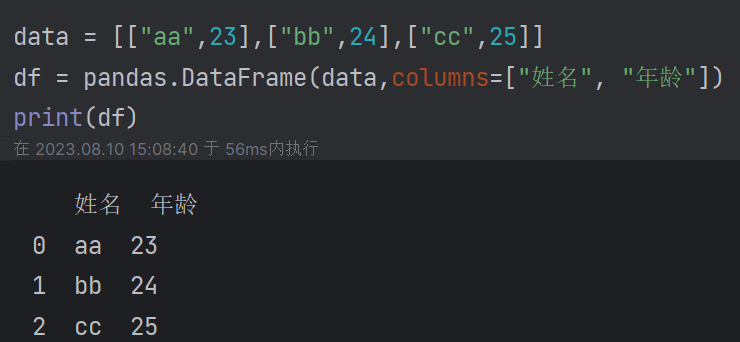
| 4.2 DataFrame:一种数据类型(可以变相的理解为多个sseries组合而成) (1)创建方式: 通过列表创建
通过字典创建:
使用series转换成DataFrame:.to_frame()
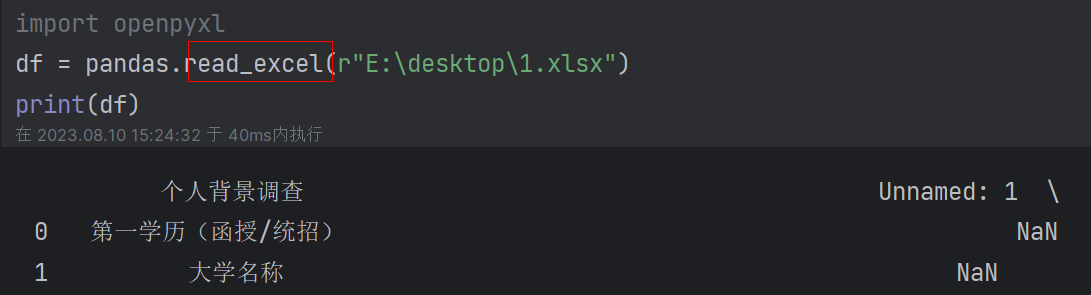
(2)读取表格:read_excel或read_csv对应读取不同格式的表格
(3)写出表格:写出为csv文件或其他类型的文件to_csv、to_excel.........
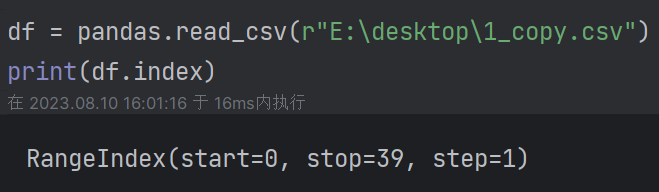
(4)更改表格中字段数据类型: df = pandas.read_csv(r"E:\desktop\1_copy.csv",usecols=["列名"]) df["列名"] = df["列名"].astype(float) (5)查看行数df.index:
列名list(df):
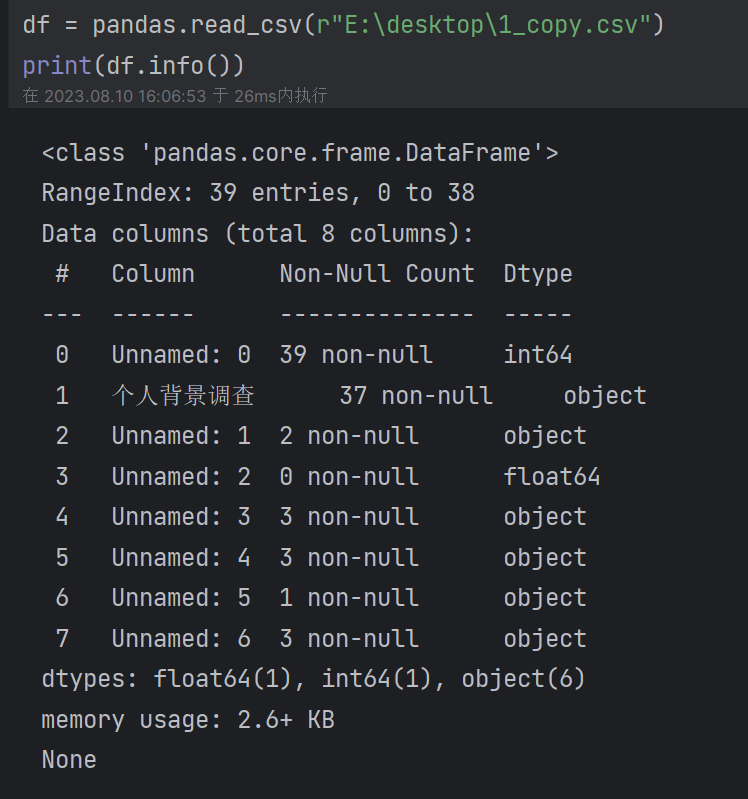
查看具体信息df.info():
读取前n行,默认为5行df.head():
读取后n行,默认为5行df.tail():
查看数据形状df.shape:
随机抽取数据中n行,默认抽取一行df.sample():
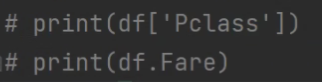
查看单列数据:df["列索引"]或df. 列索引
查看多列数据:
(6)增加或修改单列:df["列索引"] = 列数据(如果列索引存在则修改,不存在则新增) 修改或增加多列:df.assign(列索引=数据,列索引2=数据..........) (7)删除单列:df.drop("列索引", axis = 1)(axis默认为0为行,=1则为列) 删除多列:df.drop(["列索引1","列索引2"..........], axis = 1) del ,pop:删除 (8)位置索引和标签索引: 切片:通过位置索引切片:df.iloc[start : stop : step](左闭右开); 或通过标签索引切片:df.loc[start : stop : step](左闭右闭) (9)增加一行数据(了解,不推荐使用):df._append([[数据1,数据2......]], colnmns=[列名1,列名2......]) 增加行(常用):pandas.concat([df1,df2,df3.....] , keys= , axis= )keys为指定合并后的列名,多个列名使用列表传入;axis合并方向按照行或列合并,默认为0按行合并(合并成多行),为1则为按列合并(合并成多列) |

























![[FPAG开发]使用Vivado创建第一个程序](https://img-blog.csdnimg.cn/695c686409db4c9c90a342a1742d8bd0.png)