文章目录
- 常数操作
- 时间复杂度
- 空间复杂度
- O(N^2) O(1) 数据情况发生变化不影响流程
- 选择排序
- 冒泡排序
- 使用抑或运算
- 提取出不为零的数最右边的1
- 1. 实现两个变量交换值
- 2. 数组中一种数字出现奇数次,other是偶数次,找到那一种数字
- 3. 数组中有两种数字出现奇数次,other是偶数次,找到那两种数字
- O(N^2) O(1) 数据情况发生变化影响流程
- 插入排序(码牌)
- 二分法
- 对数器
- 归并排序
- 最小和问题
- 不漏算
- 不重复计算
- 荷兰国旗问题
- 快排
- version1
- version2
- version3
- 堆
- 扩容
- 使用系统提供的堆-黑盒测试
- 桶排序
- 计数排序
- 基数排序
- 数据结构如何实现入桶出桶模拟?
- 稳定性
- 选择排序-否-O(n^2)
- 冒泡排序-是-O(n^2)
- 插入排序-O(n^2)
- 归并-是-O(nlogn)
- 快排-否-O(nlogn)
- 堆排-否-O(nlogn)
- 坑
- 改进
- 冒泡排序-是-O(n^2)
- 插入排序-O(n^2)
- 归并-是-O(nlogn)
- 快排-否-O(nlogn)
- 堆排-否-O(nlogn)
- 坑
- 改进
动图帮助理解网站
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 直接插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(nlogn)~O(n^2) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(n*logn) | O(n*logn) | O(n*logn) | O(n) | 稳定 |
| 快速排序 | O(n*logn) | O(n*logn) | O(n^2) | O(logn)~O(n) | 不稳定 |
常数操作
一个操作如果和样本的数据量没有关系,每次都是固定时间内完成的操作,叫做常数操作
数组获取值:固定时间,常数操作.连续空间,距离和偏移量可以直接确认.链表不是连续空间
时间复杂度
具体来说,先要对一个算法流程非常熟悉,然后去写出这个算法流程中,发生了多少常数操作,
进而总结出常数操作数量的表达式。
在表达式中,只要高阶项,不要低阶项,也不要高阶项的系数,剩下的部分如果为f(N),那
么时间复杂度为O(f(N))。
先看时间复杂度指标,如果指标可以决出优劣即可,如果不能决出优劣指标相同,就需要再比较不同数据样本下的时间,常数项时间.
空间复杂度
另外开辟空间大小.
O(N^2) O(1) 数据情况发生变化不影响流程
选择排序
void SelectSort(int* a, int n)
{
if (a == nullptr || n < 2)
return;
for (int i = 0; i < n - 1; i++)
{
int minIndex = i;
for (int j = i + 1; j < n; j++)
{
minIndex = a[minIndex] > a[j] ? j : minIndex;
}
swap(a[minIndex], a[i]);
}
}
冒泡排序
void BubbleSort(int* a, int n)
{
if (a == nullptr || n < 2)
return;
for (int e = n - 1; e > 0; e--)//右区间边界,一直向左缩小(因为一次遍历将最大值交换到最后)
{
for (int i = 0; i < e; i++)
{
if (a[i] > a[i + 1])
swap(a[i], a[i + 1]);
}
}
}
使用抑或运算
提取出不为零的数最右边的1
int rightOne=num&(~num+1);
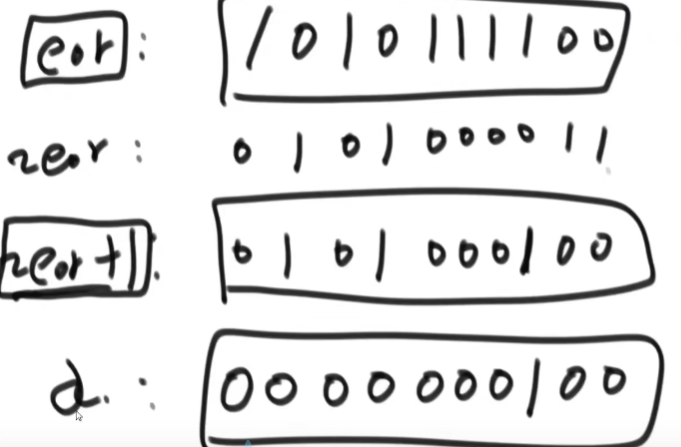
1. 实现两个变量交换值
不开辟另外的空间,但是两个变量必须指向两个空间,否则就会将这个位置的数值改为0.
抑或运算性质:
- 可理解为无进位相加
- 满足交换律 结合律
2. 数组中一种数字出现奇数次,other是偶数次,找到那一种数字
从头抑或到尾,得到的就是那个数字.
3. 数组中有两种数字出现奇数次,other是偶数次,找到那两种数字
从头抑或到尾得到eor,eor某一位必然不相同为1.根据这一位对数组进行分类,
再从新从头抑或一遍那一位为1的数字,偶数次的直接没,最后得到的一个不是a,就是b.
最后eor^eor’就是另一个数字.
O(N^2) O(1) 数据情况发生变化影响流程
插入排序(码牌)
数据情况发生变化影响流程.如果是想要的有序状态,就是O(N).按照算法最差情况估计时间复杂度O(N^2).
//想让0~i的范围内有序
void InsertSort(vector<int>& a, int n)
{
if (a.size()==0 || n < 2)
return;
for (int i = 1; i < n-1; i++)
{
for (int j = i - 1; j >= 0 && a[j] > a[j + 1]; j--)
{
swap(a[j], a[j + 1]);
}
}
}
二分法

class BS
{
public:
//有序
bool BSExist(int* a, int n, int x)
{
if (a == nullptr || n < 2)
return false;
int l = 0, r = n - 1;
while (l < r)
{
int mid = l + ((r-l) >> 2);
if (a[mid] > x)
r = mid - 1;
else if (a[mid] < x)
l = mid + 1;
else
return true;
}
return a[l]==x;
}
//有序
//找到最左侧大于等于x的位置值
int BSNearLeft(int* a, int n,int x)
{
if (a == nullptr || n < 2)
return -1;
int l = 0, r = n - 1;
int index = -1;
while (l < r)
{
int mid = l + (r - l) / 2;
if (a[mid] >= x)
{
index = mid;
r = mid - 1;
}
else if (a[mid] < x)
{
l = mid + 1;
}
}
return index;
}
//无序
//找局部最小值
int FindOneLessValue(int* a, int n)
{
if (a == nullptr || n == 0)
return -1;
//0位置
if (n == 1 || a[0] < a[1])
return a[0];
//n-1位置
if (a[n - 1] < a[n - 2])
return a[n - 1];
//[0,n-1]位置上必存在拐点,也就是局部最小值,直接取mid
int l = 0, r = n - 1;
int mid = 0;
while (l < r)
{
mid = l + (r - l) / 2;
if (a[mid] < a[mid + 1] && a[mid] < a[mid - 1])
return mid;
else if (a[mid - 1] < a[mid])
r = mid - 1;
else if (a[mid + 1] < a[mid])
l = mid + 1;
}
return l;
}
};
对数器

归并排序

class MergeSort
{
public:
//拆分为二分,则b=2 a=2 log(b,a)==d==1
// d:其他操作是将N个数据->tmp中,tmp->arr原数组所以是2*T(N)是O(N)
//T(N)=N^1*logN
//O(N^2)的选择冒泡,几乎比较了将近N次才完成一个数位置的确定
//归并:左有序区间开始和右边有序区间依次比较,没有浪费比较次数
void mergeSort(vector<int>& arr)
{
if (arr.size() < 2)
return;
merageSortHelper(arr,0,arr.size()-1);
}
void merageSortHelper(vector<int>& arr, int l, int r)
{
if (l == r)return;
int mid = l + ((r - l) >> 1);
merageSortHelper(arr,l,mid);
merageSortHelper(arr,mid+1,r);
merge(arr,l,mid,r);
}
void merge(vector<int>& arr, int l, int mid, int r)
{
vector<int>tmp(r-l+1);
int i = 0;
int p1 = l;
int p2 = mid + 1;
while (p1 <= mid && p2 <= r)
{
tmp[i++] = arr[p1] > arr[p2] ? arr[p2++] : arr[p1++];
}
while (p1 <= mid)
tmp[i++] = arr[p1++];
while (p2 <= r)
tmp[i++] = arr[p2++];
for (i = 0; i < tmp.size(); i++)
arr[l + i] = tmp[i];
}
};

最小和问题
转化为右边有多少个数比我大,我就累加几次的问题.
不漏算
任何一个数x的历程,左侧区间先和自己比然后合并为一个部分,计算产生小和,右侧区间再与自己所在有序区间合并,然后组成更大的部分,再和这一更大的部分右边更大的部分合并计算小和…
不重复计算
只有在左组和右组合并时才会产生小和的计算,组成的有序区间内部是不会有小和的计算的.
class SmallSum
{
public:
int smallSum(vector<int>& arr)
{
if (arr.size() < 2)return 0;
return mergeSort(arr,0,arr.size()-1);
}
int mergeSort(vector<int>& arr, int l, int r)
{
if (l == r)return 0;
int mid = l + ((r - l)) >> 1;
return mergeSort(arr,l,mid)+
mergeSort(arr,mid+1,r)+
merge(arr,l,mid,r);
}
int merge(vector<int>& arr, int l, int mid, int r)
{
vector<int>tmp(r-l+1);
int i = 0;
int p1 = l, p2 = mid + 1;
int res = 0;
while (p1 <= mid && p2 <= r)
{
res += arr[p1] < arr[p2] ? arr[p1] * (r - p2 + 1) : 0;
tmp[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];//相等时一定是p2++,保证后续最小和正确性
}
while (p1 <= mid)
tmp[i++] = arr[p1++];
while (p2<=r)
tmp[i++] = arr[p2++];
for (i = 0; i < tmp.size(); i++)
arr[l + i] = tmp[i];
return res;
}
};
荷兰国旗问题

class NetherlandsFlag
{
public:
//1. [i]<num [i]和less区间右边的数字交换,less区间右扩,i++
//2. [i]>num [i]和more区间左边的数字交换,more区间左扩,i不变,因为此时i位置值是刚交换过来的,还不知道是啥值
//3. [i]==num[i],i++即可,不做交换处理
//动态观察就是less区间推着==区间向右挤压待定区域接近more区间,反之亦然.
//如何推?相等区间最左(右)边值和[i](<num)交换,然后i++,实现的,反之亦然.
pair<int,int> partition(vector<int>& arr,int l,int r,int p)
{
int less = l-1;
int more = r + 1;
while (l<more)
{
if (arr[l] < p)
{
swap(arr[l], arr[less + 1]);
less++;
l++;
}
else if (arr[l] > p)
{
swap(arr[l], arr[more - 1]);
more--;
}
else
{
l++;
}
}
return std::make_pair(less+1,more-1);//返回中间=区域的左边界和右边界
}
};
快排
version1
就是将最后一个数当作num,让前n-1个数,[0,n-2]进行区间划分,最后将num和more区间最左边的值进行交换即可,这样搞定num一个数…然后划分左区间(<=num),右区间(>num)各自重复刚才的操作,取区间最后一个值作为num…;
version2
进行荷兰国旗问题,num和more区间最左值交换之后和前面的=num的区间合并,=num的区间一批数就不用再处理了,效率相对于version1更快点.再依次将less和more进行处理.
不管哪个版本,当是升序且不重复值的时候,每次partition只能搞定一个num值,即划分值num打的很极端,要么是最大要么是最小,最坏情况即T(N)=O(N^2).只有num是中间值1/2时才是最好的即
T(N)=2*T(N/2)+O(N)=>T(N)=O(N*logN)
version3
那么我随机选择一个数字作为num,然后对区间进行划分,可能我就选中那个使得数组一半一半的一种情况,也可能造成T(N/3)+T(2N/3)+O(N),选值也可能造成T(N/4)+T(3N/4)+O(N),每一种可能的概率是等价的1/N,因为我是在N个数中随机选择一个值进行对区间的划分,所有可能情况求期望就是O(N*logN)
class QuickSort
{
public:
void quickSort(vector<int>& arr)
{
if (arr.size() < 2)
return;
quickSortHelper(arr, 0, arr.size() - 1);
}
void quickSortHelper(vector<int>& arr, int l, int r)
{
if (l < r)
{
swap(arr[l + (int)(rand() * (r - l + 1))], arr[r]);
pair<int, int>p = partition(arr,l,r);
quickSortHelper(arr,l,p.first-1);
quickSortHelper(arr,p.second+1,r);
}
}
pair<int, int>partition(vector<int>& arr, int l, int r)
{
int less = l - 1;
int more = r + 1;
while (l < more)
{
if (arr[l] > arr[r])
{
swap(arr[less + 1], arr[l]);
l++;
less++;
}
else if (arr[l] < arr[r])
{
swap(arr[more - 1], arr[l]);
more--;
}
else
l++;
}
swap(arr[r],arr[more]);
return make_pair(less+1,more-1);
}
};
空间复杂度
需要记录划分区间的中间值的位置,最差情况是O(N),当取到值正好二分区间时,情况就是O(logN)
只有记录了中点信息,才能确定右区间的范围,所以这个点需要记录,因为递归栈的存在记录了这个点的信息.
堆

数组从0出发连续的数字,可以想象为一个完全二叉树,左孩子2*i+1,右孩子是2*i+2,父亲节点是(i-1)/2

class Heap
{
public:
//我们认为前heapSize个值作为堆来看待
//
//需求: 一个个在index位置添加值,如何建立大堆
//向上调整
void HeapInsert(vector<int>& arr, int index)
{
//index=0时,(index-1)/2=0,依然不满足条件
while (arr[index] > arr[(index - 1) >> 1])
{
swap(arr[index],arr[(index-1)>>1]);
index = (index - 1) >> 1;
}
}
// 需求: 返回堆中最大值,并将他移除之后,仍然保持大堆
// 将第heapSize-1位置的值放在0位置处,从顶开始向下调整
// 选出两个孩子中较大值,比较之后交换位置
// 交换跳出条件:
//1. 交换之后没有孩子节点继续向下
//2. 父亲节点大于max孩子节点
//向下调整
void HeapIfy(vector<int>& arr, int index, int heapSize)
{
int left = 2 * index + 1;
while (left < heapSize)
{
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
largest = arr[index] > arr[largest] ? index : largest;
if (largest == index)
break;
swap(arr[largest], arr[index]);
index = largest;
left = index * 2 + 1;
}
}
//在某一个位置发生值的改变,要么是变小了,如果保持大根堆,向下调整,变大了就向上调整
//调整代价均为LogN级别
//需求: 将已知数组中整理为大跟堆,我们初始化heapSize=0,认为[0,heapSize]认为是堆空间
//就相当于一个个heapInsert操作
void heapSort(vector<int>& arr)
{
if (arr.size() < 2)
return;
for (int i = 0; i < arr.size(); i++)//O(N)
{
HeapInsert(arr,i);//经历调整确定位置O(logN)
}
int heapSize = arr.size();
swap(arr[0],arr[--heapSize]);
while (heapSize > 0)//O(N)
{
HeapIfy(arr,0,heapSize); //O(log(N))
swap(arr[0],arr[--heapSize]);//O(1)
}
}
//额外空间复杂度是O(1) 只需要申请几个变量空间即可
};
//需求:将整个数组调整为大跟堆,从最后一个父亲节点开始向下调整heapIfy
//最底层占将近一半,N/2,无法向下再调整,只看一眼,代价是1
//倒数第二层N/4个,可以向下操作,看一眼,代价是2
//倒数第二层N/8个,可以向下操作2次,看一眼,代价是3
//....
//整体复杂度就是T(N)=N/2*1+N/4*2+N/8*3....
//从heapInsert的O(N*logN)=>O(N)
//for (int i = (arr.size() - 1) / 2; i >= 0; i--)//O(N)
//{
// HeapIfy(arr, i,heapSize);//经历调整确定位置O(logN)
//}
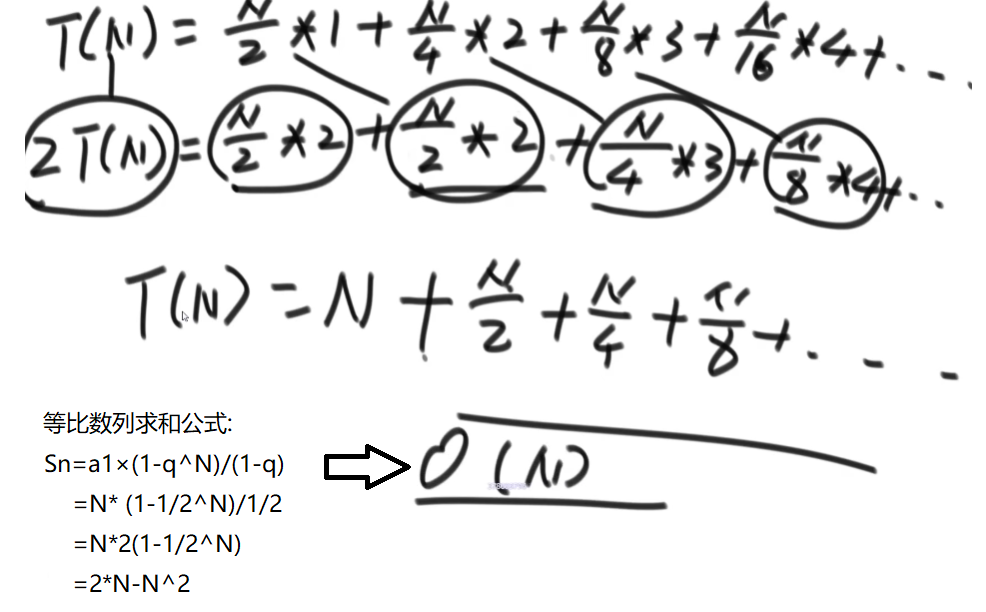

选择小根堆,将K+1个数字插入到小跟堆中,堆顶就是最小值放到数组0的位置,继续向后遍历将值放入小跟堆,得到堆顶元素,再放到1的位置,全部入堆之后依次弹出堆顶元素即可.
O(N*logK)
#include<iostream>
#include<vector>
#include<queue>
using namespace std;
class SortArrDistanceLessK
{
public:
void sortArrDistanceLessK(vector<int>& arr, int k)
{
priority_queue<int,vector<int>,greater<int>> heap;
int index = 0;
int n = arr.size();
for (; index < min(k, n); index++)
{
heap.push(arr[index]);
}
int i = 0;
for (; index < n; i++,index++)
{
heap.push(arr[index]);
arr[i] = heap.top();
heap.pop();
}
while (!heap.empty())
{
arr[i++] = heap.top();
heap.pop();
}
}
};
int main()
{
//priority_queue<int, vector<int>, less<int>> heap;//大堆
//priority_queue<int> heap;//大堆
priority_queue<int, vector<int>, greater<int>> heap;//大堆
heap.push(8);
heap.push(4);
heap.push(6);
heap.push(1);
heap.push(3);
while (!heap.empty())
{
cout << heap.top() << " ";
heap.pop();
}
}
扩容
每次扩容的代价是O(N)的,因为成倍的扩容需要将源数据拷贝到新数组中,但是扩容的次数是O(logN)
整体扩容代价就是O(N*logN),均摊到单点扩容时就是O(N*logN)/N=>O(logN)
使用系统提供的堆-黑盒测试
你add一个值,它弹出栈顶值返回一个值此时就不需要手写堆.
系统自身维护好的堆结构,想更改堆中值并想让他自己调整为合法堆结构是不支持的,只能采用遍历的方式决定怎么调整,效率很低.
自己手写的支持某一个位置值开始,效率较高的决定向上或者向下调整.
所以你想更改堆结构中的某一个值并让他自己高效率调整回堆结构时,还是自己手写一个更好.

桶排序

不进行数值比较的排序都会受到数据状况的影响.
计数排序
思想:统计数字出现情况开辟多大空间,然后O(N)遍历数组统计词频,输出数字即可.
#include<iostream>
#include<vector>
using namespace std;
class CountSort
{
public:
void countSort(vector<int>& arr)
{
if (arr.size() == 0)
return;
int max_num = INT_MIN;
for (int i = 0; i < arr.size(); i++)
max_num = max(max_num, arr[i]);
vector<int>bucket(max_num+1);
for (int i = 0; i < arr.size(); i++)
{
bucket[arr[i]]++;
}
int i = 0;
for (int j = 0; j < bucket.size(); j++)
while (bucket[j]--)
arr[i++] = j;
}
};
基数排序
进制的存在10进制 ,就安排10个桶(可以是任何容器,数组,链表,队列),先让数字按照个位数字区分,分别进入到0~9编号的桶中,然后依次出桶;再按照十位数字依次入桶出桶…最后数组中完成排序.
最大数字的位数决定了入桶出桶的次数
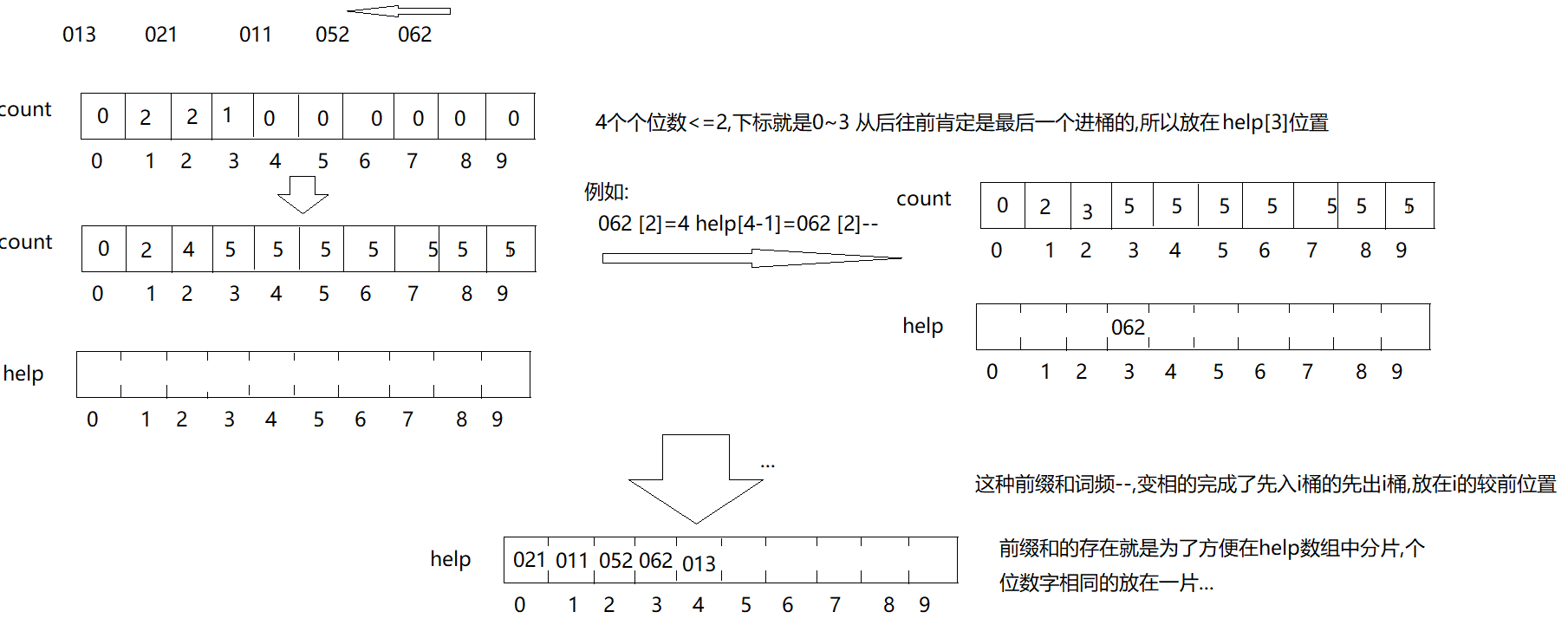
数据结构如何实现入桶出桶模拟?
统计数组中每个数字个位数字出现的频次,入count数组中
然后做成前缀和,i位置表示个位数字小于等于i的数字一共有几个,从arr数组末尾向前遍历做出桶动作,得到数字num,他的个位数字是i,入桶时count数组下标i位置这个桶中,进桶肯定是最后一个进的,所以我们将他放在help数组中,那么他在辅助数组help中的下标就是数组count[i]-1,count[i]--,依次类推完成了一次根据个位数字的入桶出桶操作.
#include<iostream>
#include<vector>
using namespace std;
class RadixSort
{
public:
//基数排序
void radixSort(vector<int>& arr)
{
if (arr.size() == 0)
return;
radixSorthelper(arr, 0, arr.size() - 1,maxDigits(arr));
}
int maxDigits(vector<int>& arr)
{
int max_num = INT_MIN;
for (int i = 0; i < arr.size(); i++)
{
max_num = max(max_num,arr[i]);
}
int res = 0;
while (max_num != 0)
{
res++;
max_num /= 10;
}
return res;
}
int getDigit(int num, int d)
{
return ((num / ((int)pow(10, d - 1))) % 10);
}
void radixSorthelper(vector<int>& arr, int begin, int end,int digit)//多少位
{
int radix = 10;
int i = 0, j = 0;
vector<int>bucket(end-begin+1);//help
for (int d = 1; d <= digit; d++)//位数决定入桶出桶多少次
//d=1代表这次循环是个位
{
vector<int>count(radix);
for (i = begin; i <= end; i++)
{
j = getDigit(arr[i],d);
count[j++];
}
//10个桶,计算每个桶的前缀和
for (i = 1; i < radix; i++)
{
count[i] = count[i] + count[i - 1];
}
for (int i = end; i >= begin; i--)
{
j = getDigit(arr[i],d);
bucket[count[j] - 1] = arr[i];
count[j]--;
}
for (i = begin, j = 0; i <= end; i++, j++)
{
arr[i] = bucket[j];
}
}
}
};
//int main()
//{
// RadixSort rs;
// cout<<rs.getDigit(123,2)<<endl;
// cout << pow(10, 1 - 1) << endl;
// cout << (123 / ((int)pow(10, 2 - 1))) << endl;
// cout << ((123 / ((int)pow(10, 2 - 1))) % 10) << endl;
//}
稳定性
值相同的元素排完之后能否保证相对顺序不发生改变.
基础类型之间稳定性不重要.自定义类型为了稳定性选归并不选快排.
情景:先根据商品的价格由高到低排序,再根据好评率从低到高排序,如果稳定性好,这样开头的就是物美价廉的商品.
选择排序-否-O(n^2)
在[0,n-1]上选择最小的放在0位置处,如果是3 3 3 3 3 3 13 3 3 3 3 ,会将第一个3与1交换,第一个3和1之间的几个3的相对位置发生改变,所以不稳定
冒泡排序-是-O(n^2)
相等值时不交换就完了
插入排序-O(n^2)
[0,i]区间上做到有序,往前看相等的时候,我就不换就完了呗.
归并-是-O(nlogn)
merge时,我让前区间相等值先拷贝到tmp数组中就可以了.
那么之前的最小和问题必须先让后区间相等值考入,那么就没有稳定性了.
快排-否-O(nlogn)
partition时遇到<5的就需要和<区前一个交换
堆排-否-O(nlogn)
很轻易就可以破坏稳定性即相对位置.
不基于比较的排序很容易可以维持稳定性.


坑

经典快排partition是01标准,可以实现奇数在前偶数在后,但是无法实现稳定性,并且空间复杂度O(1)
改进

大样本调度按照快排O(nlogn),小范围比如<=60,就让它小区间直接插入排序O(n^2)混着用就行->综合排序.
在[0,n-1]上选择最小的放在0位置处,如果是3 3 3 3 3 3 13 3 3 3 3 ,会将第一个3与1交换,第一个3和1之间的几个3的相对位置发生改变,所以不稳定
冒泡排序-是-O(n^2)
相等值时不交换就完了
插入排序-O(n^2)
[0,i]区间上做到有序,往前看相等的时候,我就不换就完了呗.
归并-是-O(nlogn)
merge时,我让前区间相等值先拷贝到tmp数组中就可以了.
那么之前的最小和问题必须先让后区间相等值考入,那么就没有稳定性了.
快排-否-O(nlogn)
partition时遇到<5的就需要和<区前一个交换
[外链图片转存中…(img-f2PF5BCk-1691664383774)]
堆排-否-O(nlogn)
很轻易就可以破坏稳定性即相对位置.
不基于比较的排序很容易可以维持稳定性.
[外链图片转存中…(img-qxzV5zE8-1691664383775)]
[外链图片转存中…(img-ZorBBZL9-1691664383775)]
坑
[外链图片转存中…(img-P9EHRawr-1691664383775)]
经典快排partition是01标准,可以实现奇数在前偶数在后,但是无法实现稳定性,并且空间复杂度O(1)
改进
[外链图片转存中…(img-uq2tsAV6-1691664383776)]
大样本调度按照快排O(nlogn),小范围比如<=60,就让它小区间直接插入排序O(n^2)混着用就行->综合排序.


](https://img-blog.csdnimg.cn/593d921ca95b4b1aac6238216a34634a.png)