es环境搭建参考:ElasticSearch:环境搭建步骤_Success___的博客-CSDN博客
需求:
-
用户输入关键可搜索文章列表
-
关键词高亮显示
-
文章列表展示与home展示一样,当用户点击某一篇文章,可查看文章详情
思路:
为了加快检索的效率,在查询的时候不会直接从数据库中查询文章,需要在elasticsearch中进行高速检索。

1、使用postman往虚拟机es中创建索引和映射
put请求 : http://192.168.200.130:9200/app_info_article
{
"mappings":{
"properties":{
"id":{
"type":"long"
},
"publishTime":{
"type":"date"
},
"layout":{
"type":"integer"
},
"images":{
"type":"keyword",
"index": false
},
"staticUrl":{
"type":"keyword",
"index": false
},
"authorId": {
"type": "long"
},
"authorName": {
"type": "text"
},
"title":{
"type":"text",
"analyzer":"ik_smart"
},
"content":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
} 下图为例添加成功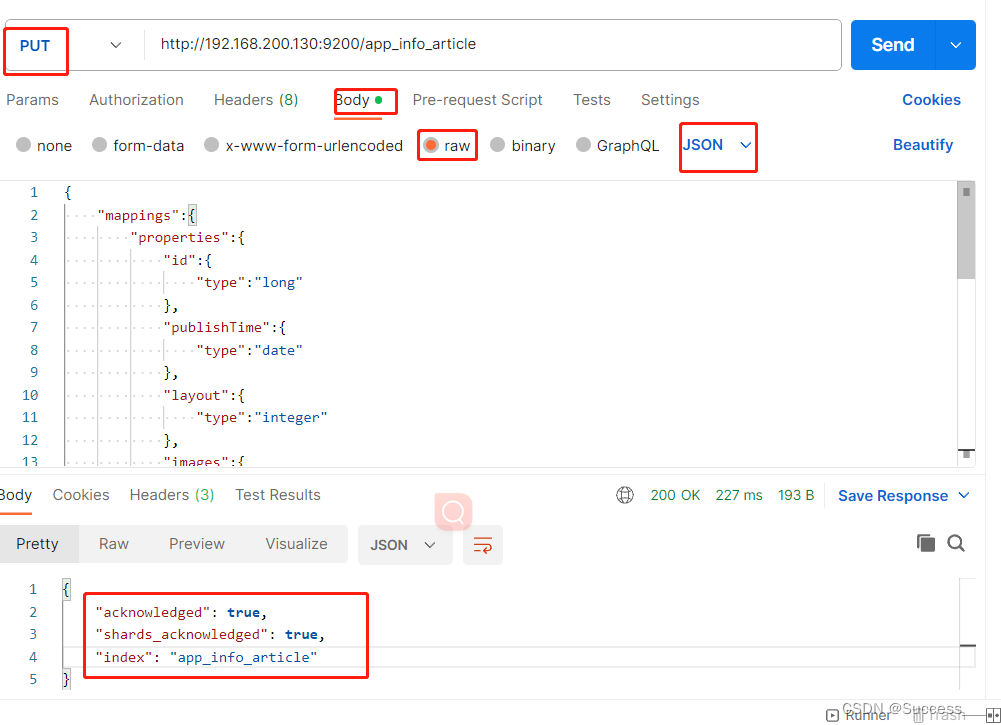
GET请求查询映射:http://192.168.200.130:9200/app_info_article
DELETE请求,删除索引及映射:http://192.168.200.130:9200/app_info_article
GET请求,查询所有文档:http://192.168.200.130:9200/app_info_article/_search
2、将数据从数据库导入到ES索引库中
①创建es-init工程,pom文件如下
<dependencies>
<!-- 引入依赖模块 -->
<dependency>
<groupId>com.heima</groupId>
<artifactId>heima-leadnews-common</artifactId>
</dependency>
<!-- Spring boot starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--elasticsearch-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<!-- web项目可以不排除下面的依赖 -->
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-smile</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-yaml</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-cbor</artifactId>
</exclusion>
</exclusions>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.4</version>
</dependency>
</dependencies>②配置application.yml文件
server:
port: 9999
spring:
application:
name: es-article
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/leadnews_article?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 1234
# 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.common.article.model.po
#自定义elasticsearch连接配置
elasticsearch:
host: 192.168.200.130
port: 9200
③在工程config中创建配置类ElasticSearchConfig用来操作es
package com.heima.es.config;
import lombok.Getter;
import lombok.Setter;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Getter
@Setter
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
private String host;
private int port;
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost(
host,
port,
"http"
)
));
}
}
④在工程pojo中创建实体类SearchArticleVo
需要存储到es索引库中的字段
package com.heima.es.pojo;
import lombok.Data;
import java.util.Date;
@Data
public class SearchArticleVo {
// 文章id
private Long id;
// 文章标题
private String title;
// 文章发布时间
private Date publishTime;
// 文章布局
private Integer layout;
// 封面
private String images;
// 作者id
private Long authorId;
// 作者名词
private String authorName;
//静态url
private String staticUrl;
//文章内容
private String content;
}⑤在工程mapper中创建方法用来查询对应的数据库字段
package com.heima.es.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.es.pojo.SearchArticleVo;
import com.heima.model.common.article.model.po.ApArticle;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface ApArticleMapper extends BaseMapper<ApArticle> {
List<SearchArticleVo> loadArticleList();
}
⑥创建mapper.xml动态sql文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.heima.es.mapper.ApArticleMapper">
<resultMap id="resultMap" type="com.heima.es.pojo.SearchArticleVo">
<id column="id" property="id"/>
<result column="title" property="title"/>
<result column="author_id" property="authorId"/>
<result column="author_name" property="authorName"/>
<result column="layout" property="layout"/>
<result column="images" property="images"/>
<result column="publish_time" property="publishTime"/>
<result column="static_url" property="staticUrl"/>
<result column="content" property="content"/>
</resultMap>
<select id="loadArticleList" resultMap="resultMap">
SELECT
aa.*, aacon.content
FROM
`ap_article` aa,
ap_article_config aac,
ap_article_content aacon
WHERE
aa.id = aac.article_id
AND aa.id = aacon.article_id
AND aac.is_delete != 1
AND aac.is_down != 1
</select>
</mapper>⑦创建test类并执行数据导入代码
package com.heima.es;
import com.alibaba.fastjson.JSON;
import com.heima.es.mapper.ApArticleMapper;
import com.heima.es.pojo.SearchArticleVo;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
@SpringBootTest
@RunWith(SpringRunner.class)
public class ApArticleTest {
@Autowired
private ApArticleMapper apArticleMapper;
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 注意:数据量的导入,如果数据量过大,需要分页导入
* @throws Exception
*/
@Test
public void init() throws Exception {
/*查询符合条件的文章数据*/
List<SearchArticleVo> searchArticleVos = apArticleMapper.loadArticleList();
/*批量导入es数据*/
//索引库名称
BulkRequest bulkRequest = new BulkRequest("app_info_article");
for (SearchArticleVo searchArticleVo : searchArticleVos) {
IndexRequest indexRequest =
new IndexRequest()
.id(searchArticleVo.getId().toString())
.source(JSON.toJSONString(searchArticleVo), XContentType.JSON);
bulkRequest.add(indexRequest);
}
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
}
}⑧使用postman请求查看数据
导入成功
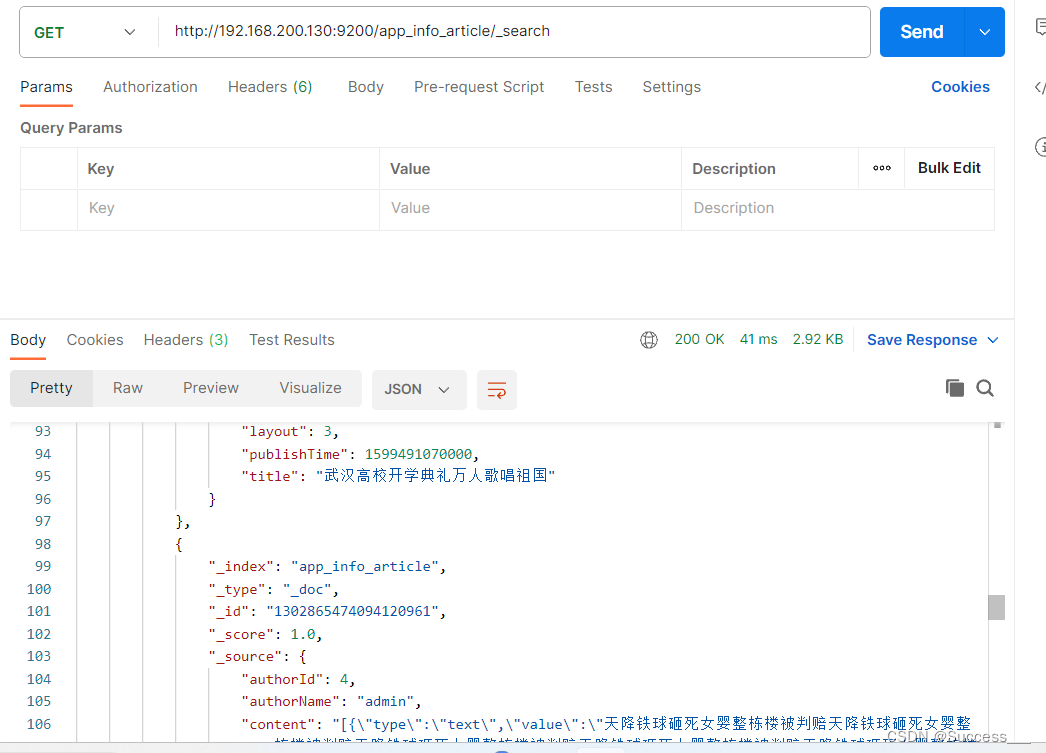
3、文章搜索功能实现
①创建heima-leadnews-search搜索工程
pom文件内容如下
<!--elasticsearch-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<!-- web项目可以不排除下面的依赖 -->
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-smile</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-yaml</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-cbor</artifactId>
</exclusion>
</exclusions>
<version>7.4.0</version>
</dependency>
②配置nacos
server:
port: 51804
spring:
application:
name: leadnews-search
cloud:
nacos:
discovery:
server-addr: 192.168.200.130:8848
config:
server-addr: 192.168.200.130:8848
file-extension: yml③nacos中配置elasticsearch
spring:
autoconfigure:
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
elasticsearch:
host: 192.168.200.130
port: 9200④创建controller
package com.heima.search.controller.v1;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.search.UserSearchDto;
import com.heima.search.service.ArticleSearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {
@Autowired
ArticleSearchService articleSearchService;
@PostMapping("/search")
public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {
return articleSearchService.search(dto);
}
}
⑤实现service层
package com.heima.search.service.impl;
import com.alibaba.cloud.commons.lang.StringUtils;
import com.alibaba.fastjson.JSON;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import com.heima.model.common.search.UserSearchDto;
import com.heima.search.service.ArticleSearchService;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {
@Autowired
RestHighLevelClient restHighLevelClient;
/*文章搜索*/
@Override
public ResponseResult search(UserSearchDto dto) throws IOException {
//参数校验
System.out.println(dto);
//1.检查参数
if(dto == null || StringUtils.isBlank(dto.getSearchWords())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.设置查询条件
SearchRequest searchRequest = new SearchRequest("app_info_article");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//关键字的分词之后查询
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);
boolQueryBuilder.must(queryStringQueryBuilder);
//查询小于mindate的数据
// RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());
// boolQueryBuilder.filter(rangeQueryBuilder);
//分页查询
searchSourceBuilder.from(0);
searchSourceBuilder.size(dto.getPageSize());
//按照发布时间倒序查询
searchSourceBuilder.sort("publishTime", SortOrder.DESC);
//设置高亮 title
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("<font style='color: red; font-size: inherit;'>");
highlightBuilder.postTags("</font>");
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//3.结果封装返回
List<Map> list = new ArrayList<>();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
Map map = JSON.parseObject(json, Map.class);
//处理高亮
if(hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0){
Text[] titles = hit.getHighlightFields().get("title").getFragments();
String title = org.apache.commons.lang.StringUtils.join(titles);
//高亮标题
map.put("h_title",title);
}else {
//原始标题
map.put("h_title",map.get("title"));
}
list.add(map);
}
System.out.println(list);
return ResponseResult.okResult(list);
}
}
⑥在gateway网关中配置当前项目
#搜索微服务
- id: leadnews-search
uri: lb://leadnews-search
predicates:
- Path=/search/**
filters:
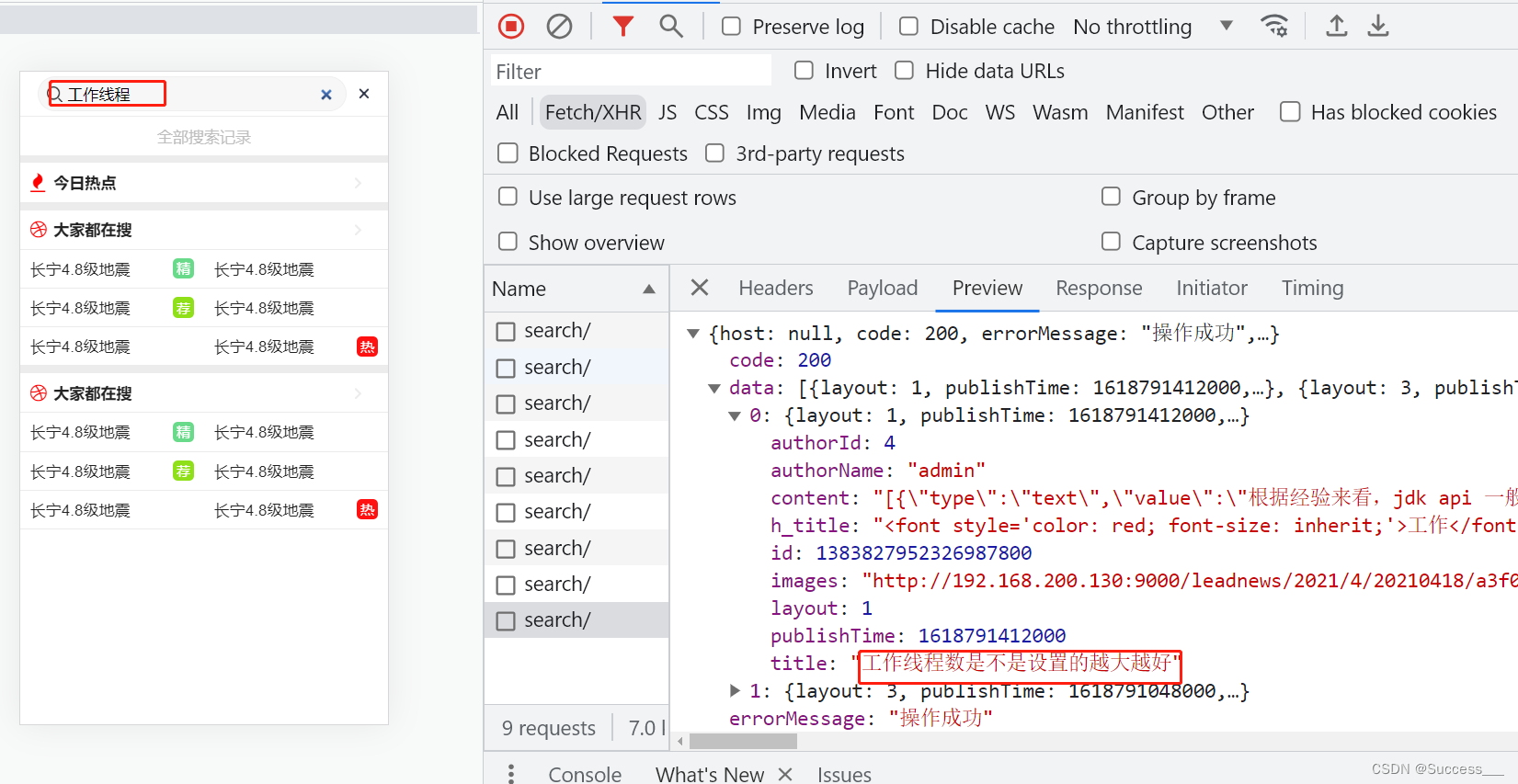
- StripPrefix= 1⑦启动项目并测试
下一篇:ElasticSearch:项目实战(2)