目录
前言
按1小时分组统计
按2小时分组统计
按X小时分组统计
前言
统计数据时这种是最常见的需求场景,今天写需求时发现按2小时进行分组统计也特别简单,特此记录下。
按1小时分组统计
sql:
select hour(pass_time) as `hour`,
(case when is_out = 0 then 'in' when is_out = 1 then 'out' end) as name,
count(id) as `count`
from vehicle_traffic_record
where (pass_time between '2023-08-03' and '2023-08-03 23:59:59')
group by `hour`, `name`;返回值:

没啥好说的,直接使用 hour() 函数获取时间字段的小时部分进行分组统计即可
按2小时分组统计
sql:
SELECT FLOOR(HOUR(pass_time) / 2) * 2 as hour,
(case when is_out = 0 then 'in' when is_out = 1 then 'out' end) as name,
count(id) as `count`
FROM vehicle_traffic_record
where (pass_time between '2023-08-03' and '2023-08-03 23:59:59')
group by hour, name
order by hour;返回值:
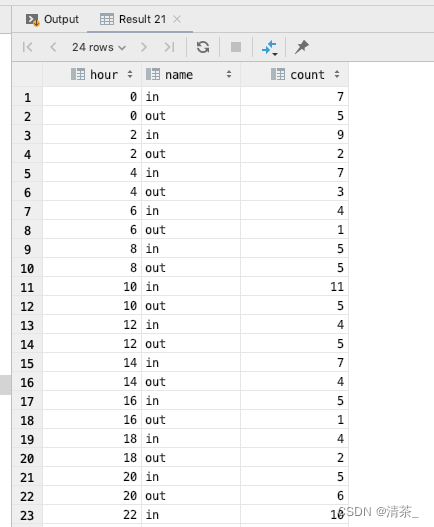
思路是一样的,先使用 hour() 函数获取时间字段的小时部分,然后除以2并使用 floor() 向下取整,最后乘以2以获得2小时间隔的起始值。
如果不好理解,这里将语句拆分下:
select pass_time,
HOUR(pass_time),
HOUR(pass_time) / 2,
FLOOR(HOUR(pass_time) / 2),
FLOOR(HOUR(pass_time) / 2) * 2
from vehicle_traffic_record
where (pass_time between '2023-08-03' and '2023-08-03 23:59:59');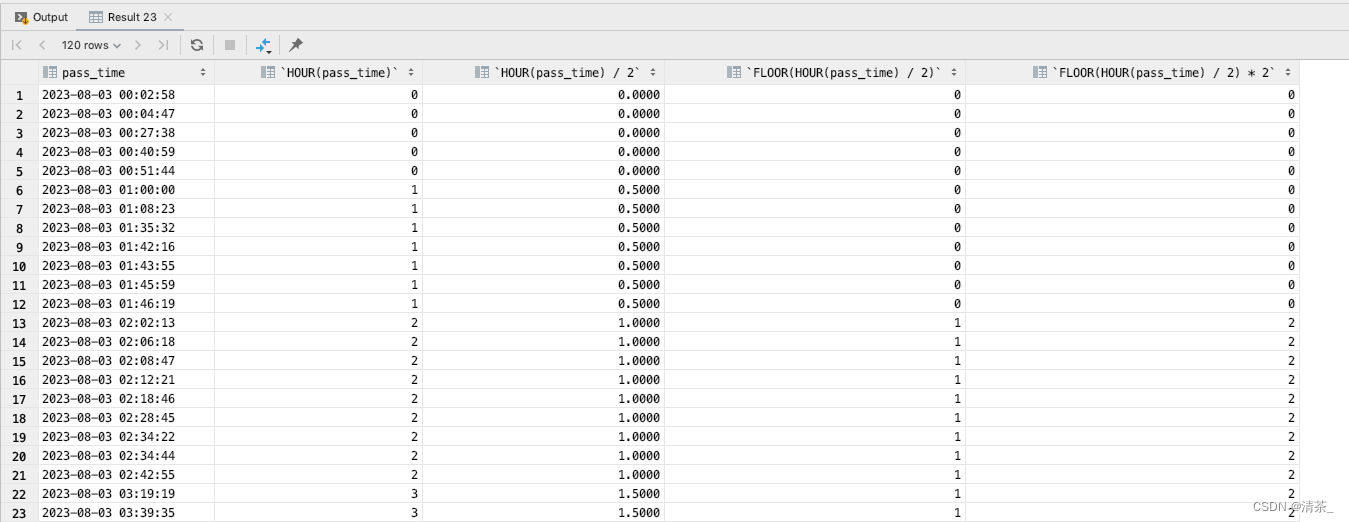
按X小时分组统计
其余小时分组均同理,比如按3小时分组,替换上面的2即可





![[保研/考研机试] KY235 进制转换2 清华大学复试上机题 C++实现](https://img-blog.csdnimg.cn/af2f731570cb4da6bc150fe8987190e6.png)