1.背景
ML code仅是Machine Learning systems中的一小部分,像数据收集、特征抽取、配置管理、资源管理、模型部署、模型监控等同样十分的重要。一个典型的机器学习系统由这么多组件或子系统构成时,那么这么多子系统应该如何高效的配合起来?
答案是机器学习工作流。 通过机器学习工作流,可以有效的将各个子系统串联起,每一个业务场景可以通过一个端到端的机器学习工作流来描述,同时通过工作流也可以追溯每一次模型产出或模型上线的元信息(例如数据、配置、base model等)
2.Kubeflow Pipelines介绍
kubeflow/kubeflow 是一个胶水项目,pipelines 是基于 kubeflow 实现的工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发
-
Kubeflow 是一个基于云原生的Machine Learning Platform,它把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等等结合在了一起,部署了 kubeflow 用户就可以利用它进行不同的机器学习任务,旨于快速在kubernetes环境中构建一套开箱即用的机器学习平台,它将机器学习的代码像构建应用一样打包,使其他人也能够重复使用。
-
Pipelines是Kubeflow社区开源的一个端到端工作流项目,工作流的原理是每一个组件都定义好自己的输入和输出,然后根据输入和输出关系确定工作流的流程。所以工作流的方式对于组件的复用可以起到很好的作用。Pipelines基于 kubeflow 实现工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发
Kubeflow pipeline(简称KFP) 通过定义一个有向无环图DAG描述流水线系统(pipeline),流水线中每一步流程是由容器定义组成的组件(component),将机器学习中的应用代码按照流水线的方式编排,形成可重复的工作流,并提供平台,帮助编排,部署,管理,这些端到端机器学习工作流,同时提供了下述能力
- 任务编排:KFP通过argo提供workflow的能力,能够实现丰富多样的DAG 工作流,用户可以根据的业务需求定义、管理和复用自己工作流;
- 实验管理:KFP通过Experiments的能力,能够展示和对比不同实验参数(例如:模型超参)下Pipeline的运行结果,用户可以根据结果来对工作流任务进行调优;
- 模型追溯:KFP通过Tracking的能力,能够记录每一次Pipeline运行中每个step的输入和输出信息,用户可以根据记录的内容进行问题排查或模型调优;
2.1 Kubeflow pipelines(KFP) 基本概念
当我们想要发起一次机器学习的试验时,需要创建一个experiment,在experiment中发起运行任务(run)。Experiment 是一个抽象概念,用于分组管理运行任务。
- Pipeline:定义一组操作的工作流,其中每一步都由component组成。 背后是一个Argo的模板配置。
- Component: 一个容器操作,可以通过pipeline的sdk 定义。每一个component 可以定义定义输出(output)和产物(artifact), 输出可以通过设置下一步的环境变量,作为下一步的输入, artifact 是组件运行完成后写入一个约定格式文件,在界面上可以被渲染展示。
- Experiment: 可以看做一个工作空间,在其中可以针对工作流尝试不同的配置,管理一组运行任务。
- Run: pipeline 的运行任务实例,这些任务会对应一个工作流实例。由Argo统一管理运行顺序和前后依赖关系。工作流的一次执行,用户在执行的过程中可以看到每一步的输出文件,以及日志
- Recurring run: 定时任务,定义运行周期,Pipeline 组件会定期拉起对应的Pipeline Run。
2.2 Argo Workflows
之前提到Kubeflow pipelines很大程度上依赖Argo来进行任务编排,Argo Workflows是一个开源的本地容器工作流引擎,用于在Kubernetes上编排并行作业。Argo工作流是作为Kubernetes CRD(自定义资源定义)实现的。
- 定义工作流,其中工作流中的每个步骤都是一个容器。
- 将多步骤工作流建模为一系列任务,或者使用有向无环图(DAG)捕获任务之间的依赖关系。
- 使用Kubernetes上的Argo工作流,在很短的时间内轻松运行用于机器学习或数据处理的计算密集型作业。
- Argo的步骤间可以通过管理面中转传递信息,即下一步(容器)可以获取上一步(容器)的结果。结果传递有2种:
- 文件:上一步容器新生成的文件,会直接出现在下一步容器里面。
- 结果信息:上一步的执行结果信息(如某文件内容),下一步也可以拿到。
2.2.1 Argo传递文件
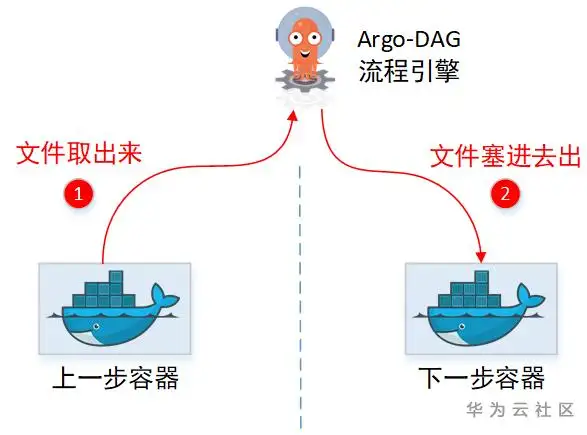
没有共享目录,那中转文件,只能是通过先取出来,再塞回去的方式喽。实际上Argo也确实这么做的,只是实现上还有些约束。
(1)“临时中转仓库”需要引入第三方软件(Minio)
(2)文件不能太大
(3)需要在用户容器侧,增加“代理”帮忙上传&下载文件。
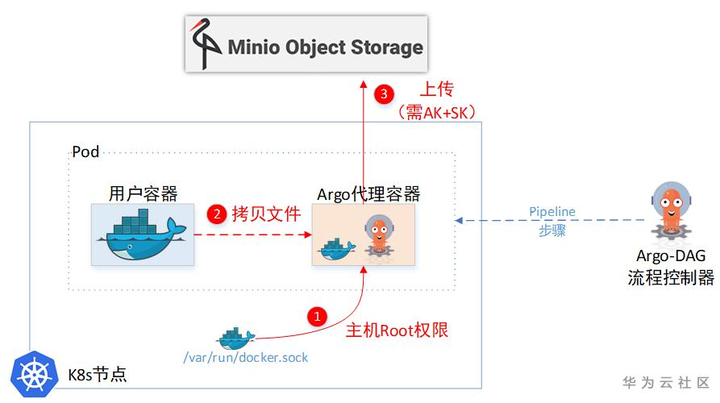
(1)Argo给用户容器设置了一个SideCar容器,通过这个SideCar去读取用户的文件,然后上传到临时仓库。
(2) 一个Pod里面的两个Container,文件系统也是独立的,并不能直接取到另一个Container的文件。所以Sidecar容器为了取另一个容器里的文件,又把主机上面的docker.sock挂载进来了。这样就相当于拿到了主机Root权限,可以任意cp主机上任意容器里面的文件。
2.2.2 Argo传递结果信息
Argo自己没有存储Information的临时仓库,所以它需要记录这些临时待中转的information(Argo使用了Minio对象存储用来暂存中转文件,但Minio只能存文件,没有存Metadata元数据功能)。于是Argo使用Pod里面的Annotation字段即ETCD中(ETCD的单个对象不能超过1M大小),当做临时中转仓库。先把信息记这里,下一步容器想要,就来这里取。
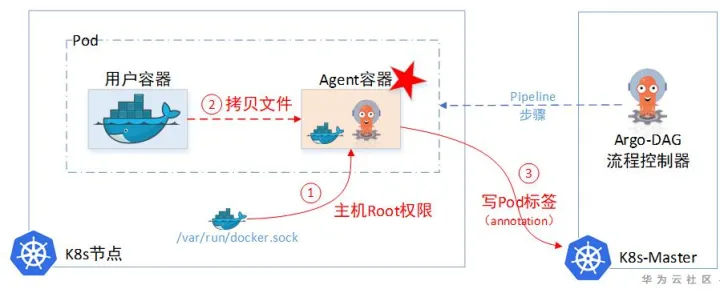
2.2.3 Argo缺陷
Argo是基于K8s云原生这套理念,即ETCD充当“数据库”来运行的,导致约束比较大。像:流程模板,历史执行记录,这些大量的信息很明显需要一个持久化层(数据库)来记录的,单纯依赖ETCD会有单条记录不能超过1M,总记录大小不能超过8G的约束。
所以一个完整的流程引擎,包含一个数据库也都是很常规的。因此KFP在这一层做了较大的增强。
另外,在ML领域的用户界面层,KFP也做了较多的用户体验改进。包括可以查看每一步的训练输出结果,直接通过UI进行可视化的图形展示。
2.3 查看Pipeline
2.4 Kubeflow pipelines架构
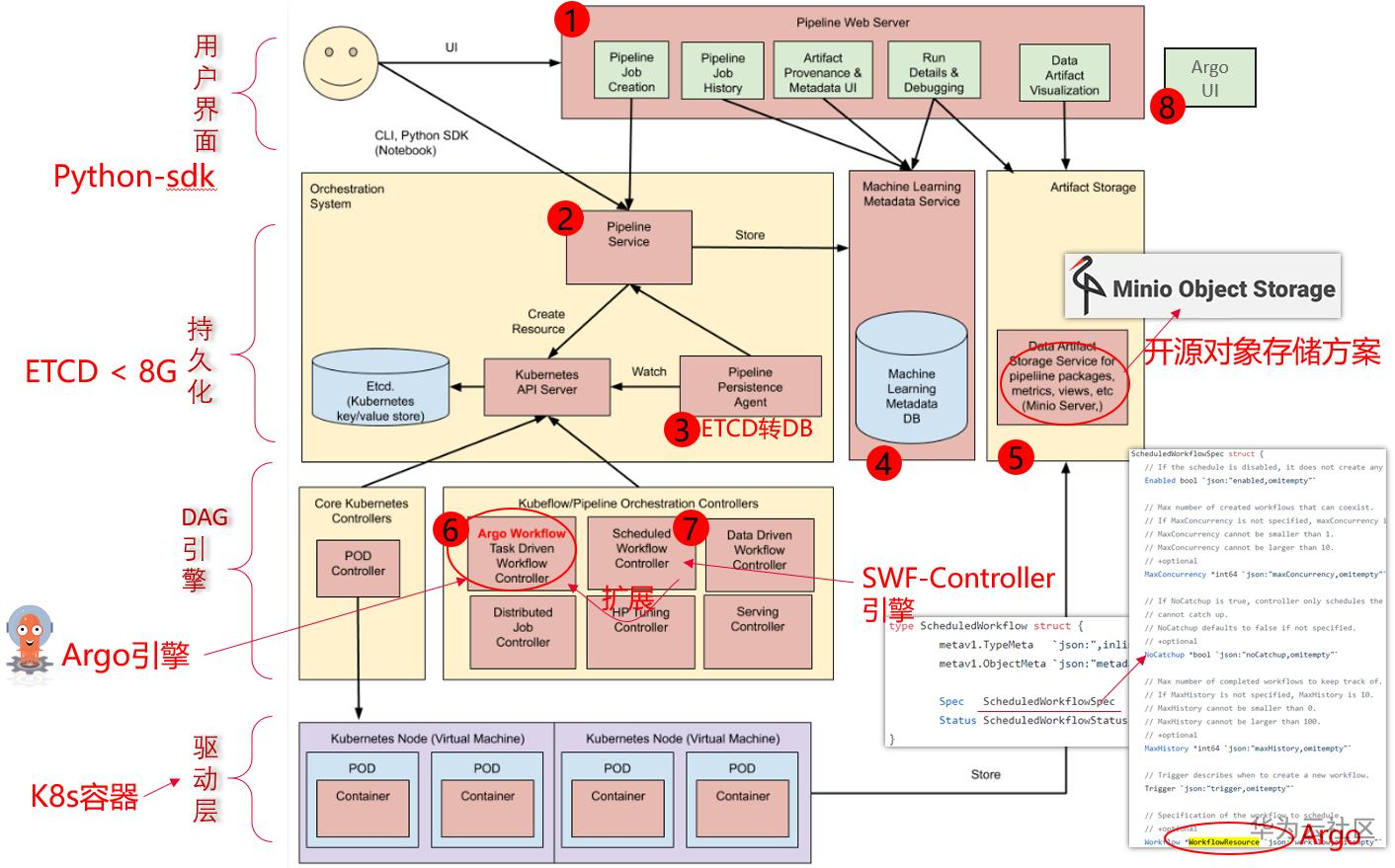
上图为Kubeflow Pipelines的架构图,主要分为八个部分:
- Python SDK: 负责构造出工作流,并且根据工作流构造出 ScheduledWorkflow 的 YAML 定义,随后将其作为参数传递给工作流系统的后端服务。
- DSL Compiler: 将Python代码转换成YAML静态配置文件(DSL编译器);
- Pipeline Web Server: Pipeline的前端服务,可视化整个工作流的过程,以及获取日志,发起新的运行等,显示当前正在运行的Pipeline列表、Pipeline执行的历史记录,有关各个Pipeline运行的调试信息和执行状态等;
- Pipeline Service:Pipeline的后端服务,调用K8S服务,从YAML创建 Pipeline运行;依赖关系存储数据库(如 MySQL)和对象存储(如 Amazon S3),处理所有工作流中的 CRUD 请求。
- Kubernetes Resources:创建CRDs运行Pipeline;
- Machine Learning Metadata Service: 用于监视由Pipeline Service创建的Kubernetes资源,并可以将这些资源的状态持久在保留ML元数据服务中(存储任务流容器之间的input/output数据交互);
- Artifact Storage:用于存储Metadata和Artifact。Kubeflow Pipelines可以将元数据存储在MySQL数据库中,也可以将工件制品存储在Minio服务器或S3等工件存储中;
- Orchestration controllers:对任务的编排,比如Argo Workflow控制器,可以协调任务驱动的工作流。
2.5 Kubeflow Pipelines SDK
pipeline sdk是使用python配合kubeflow pipelines功能的工具包。为了简化用户使用kubeflow pipelines功能,Kubeflow Pipelines SDK 提供了许多API,以下是一些常用的包:
-
kfp.components:该子包提供了一系列可重用的组件的实现,这些组件可以在不同的流程中重复使用。组件可以是定义了输入和输出的容器化软件,也可以是表示命令行工具的Python函数。
kfp.components.func_to_container_op:调用将函数构建为 apipeline task(ContainerOp) 实例,在容器中运行原始函数。kfp.components.load_component_from_file: kfp.components.load_component_from_file是一个函数,用于从本地文件系统中加载 Kubeflow 组件。使用此函数,您可以在运行时加载和使用预编译的 Kubeflow 组件。这使得组件的共享和重用变得更加容易。
-
kfp.dsl:该子包提供了一组构建块,可用于创建KFP编排定义。DSL提供了可用于编写和组合步骤、输入输出和流程的代码库。
kfp.dsl.component: kfp.dsl.component 是一个装饰器,允许您将一个函数转换为 Kubeflow 组件。使用这个装饰器,您可以通过编写 Python 函数来定义 Kubeflow 流水线中的任务。一旦定义了组件,您可以在多个 Kubeflow 流水线中重复使用它。kfp.dsl.Pipeline: kfp.dsl.Pipeline是一个用于定义 Kubeflow 流水线的类。您可以使用此类来定义流水线的所有组件,以及它们之间的依赖关系。一旦定义了流水线,您可以使用 kfp.compiler将其编译为可在 Kubeflow 上运行的格式。kfp.dsl.ContainerOp: kfp.dsl.ContainerOp是一个用于定义容器操作的类。这个类允许您定义一个容器镜像,并指定容器启动时应该执行的命令。容器操作可以被组合成一个流水线,并在 Kubeflow 上执行。
-
kfp.compiler:该子包提供了编译器的实现,用于编译和导出 Kubeflow Pipelines 流水线,您可以使用此 API 将 Kubeflow 流水线定义编译为 YAML 或 JSON 格式,以便在 Kubeflow 上执行它将KFP编排定义编译为Kubernetes的自定义资源(CRD)以部署和执行。
kfp.compiler.Compiler.compile:将您的Python DSL代码编译成Kubeflow Pipelines服务可以处理的单一静态配置(YAML格式)。Kubeflow Pipelines服务将staticconfiguration转换成一组用于执行的Kubernetes资源。kfp.compiler.build_docker_image:根据 Dockerfile 构建容器镜像,并将镜像推送到 URI。在参数中,您需要提供包含映像规范的 Dockerfile 的路径,以及目标映像(例如容器注册表)的 URI。
-
kfp.Client:该子包为KFP服务提供了Python客户端库。它允许您通过API与KFP服务器进行交互,例如对运行中的流程进行操作。
kfp.Client.create_experiment:创建一个工作流实验环境并返回kfp.Client.run_pipeline:创建一个运行任务实例
-
kfp.Notebook:该子包为Jupyter Notebook提供了扩展,使其能够与KFP服务进行交互。它包含了KFP的Web UI和其它可视化工具。
总之,Kubeflow Pipelines SDK 提供了一些用于定义和构建 Kubeflow 流水线的强大的 API。使用这些 API,可以快速开发和管理复杂的机器学习工作流。
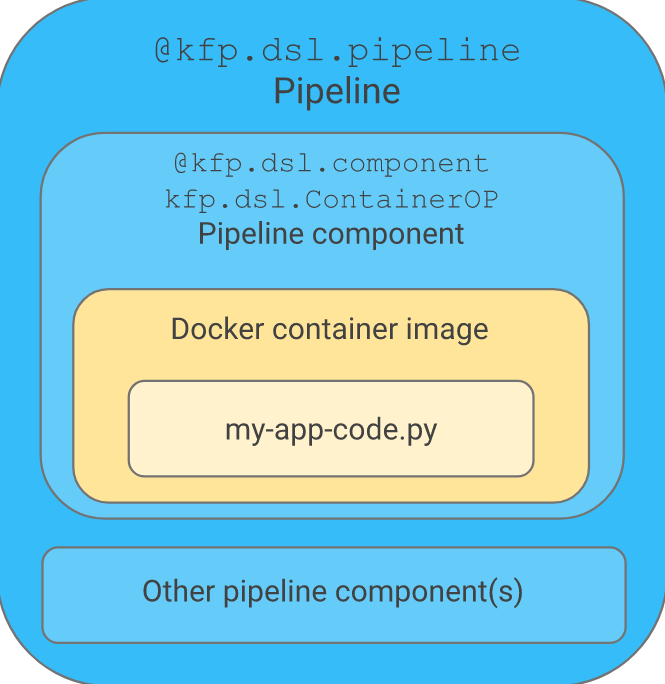
2.6 Pipeline实践
流水线的定义可以分为两步,
- 首先是定义组件,组件可以从镜像开始完全自定义。这里介绍一下自定义的方式:首先需要打包一个Docker镜像,这个镜像是组件的依赖,每一个组件的运行,就是一个Docker容器。其次需要为其定义一个python函数,描述组件的输入输出等信息,这一定义是为了能够让流水线理解组件在流水线中的结构,有几个输入节点,几个输出节点等。接下来组件的使用就与普通的组件并无二致了。
- 实现流水线的第二步,就是根据定义好的组件组成流水线,在流水线中,由输入输出关系会确定图上的边以及方向。在定义好流水线后,可以通过 python中实现好的流水线客户端提交到系统中运行。
虽然kubeflow/pipelines的使用略显复杂,但它的实现其实并不麻烦。整个的架构可以分为五个部分,分别是ScheduledWorkflow CRD以及其operator流水线前端,流水线后端,Python SDK和persistence agent。
ScheduledWorkflow CRD扩展了argoproj/argo的Workflow定义。这也是流水线项目中的核心部分,它负责真正地在Kubernetes上按照拓扑序创建出对应的容器完成流水线的逻辑。Python SDK负责构造出流水线,并且根据流水线构造出 ScheduledWorkflow的YAML定义,随后将其作为参数传递给流水线系统的后端服务。后端服务依赖关系存储数据库(如MySQL)和对象存储(如S3),处理所有流水线中的CRUD请求。前端负责可视化整个流水线的过程,以及获取日志,发起新的运行等。Persistence agent负责把数据从Kubernetes Master的etcd中sync到后端服务的关系型数据库中,其实现的方式与CRD operator类似,通过informer来监听 Kubernetes apiserver对应资源实现。
Pipelines提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。这部分主要基于Argo Workflow。
2.6.1 构造Pipeline
Kubeflow Pipelines提供了Python的SDK让用户来快速构建符合自己业务场景的Pipeline。通过Kubeflow Pipelines,您可以使用KFP Python SDK创作组件和Pipeline,将Pipeline编译为中间表示YAML,并提交管道以在符合KFP标准的后端上运行。
以下代码来自官网:https://www.kubeflow.org/docs/components/pipelines/v2/installation/quickstart/
from kfp import dsl
from kfp import client
@dsl.component
def addition_component(num1: int, num2: int) -> int:
return num1 + num2
@dsl.pipeline(name='addition-pipeline')
def my_pipeline(a: int, b: int, c: int = 10):
add_task_1 = addition_component(num1=a, num2=b)
add_task_2 = addition_component(num1=add_task_1.output, num2=c)
endpoint = '<KFP_ENDPOINT>'
kfp_client = client.Client(host=endpoint)
run = kfp_client.create_run_from_pipeline_func(
my_pipeline,
arguments={
'a': 1,
'b': 2
},
)
url = f'{endpoint}/#/runs/details/{run.run_id}'
print(url)
以上代码包括以下几个部分:
- 第一部分中,使用@dsl.component装饰器创建了一个轻量级的Python组件:
@dsl.component
def addition_component(num1: int, num2: int) -> int:
return num1 + num2
@dsl.component装饰器将Python函数转化为可在工作流中使用的组件。在参数上需要指定类型注释和返回值,这样可以告诉KFP执行器如何序列化和反序列化组件之间传递的数据。类型注释和返回值还使得KFP编译器能够对工作流任务之间传递的数据进行类型检查。
- 第二部分中,使用@dsl.pipeline装饰器创建了一个工作流:
@dsl.pipeline(name=’addition-pipeline’)
def my_pipeline(a: int, b: int, c: int = 10):
…
与组件装饰器类似,@dsl.pipeline装饰器将Python函数转化为KFP后端可执行的工作流。工作流可以具有参数,这些参数也需要进行类型注释。在这个例子中,参数c有一个默认值10。
-
第三部分中,以下代码在工作流函数中将组件连接起来形成一个计算有向无环图(DAG):
add_task_1 = addition_component(num1=a, num2=b) add_task_2 = addition_component(num1=add_task_1.output, num2=c)这个例子中通过为每个任务传递不同的参数,从同一个名为addition_component的组件中实例化了两个不同的加法任务,必须始终使用关键字参数传递组件参数,具体如下:
- 第一个任务将工作流参数a和b作为输入参数。
- 第二个任务将add_task_1.output(即add_task_1的输出)作为第一个输入参数,并将工作流参数c作为第二个输入参数。
-
第四部分中,以下代码使用部署步骤中获取的端点实例化了一个KFP客户端,并将工作流与所需的工作流参数提交给KFP后端:
endpoint = ‘<KFP_ENDPOINT>’ kfp_client = client.Client(host=endpoint) run = kfp_client.create_run_from_pipeline_func( my_pipeline, arguments={ 'a’: 1, ‘b’: 2 }, ) url = f’{endpoint}/#/runs/details/{run.run_id}’ print(url)在这个例子中,将工作流的endpoint替换为在部署步骤中获取的KFP端点URL。或者,还可以将工作流编译为IR YAML以供以后使用:
from kfp import compiler compiler.Compiler().compile(pipeline_func=my_pipeline, package_path=’pipeline.yaml’)
目前提交运行pipelines有2种方法,二者本质都是使用sdk编译pipelines组件
- 在notebook中使用sdk提交pipelines至服务中心,直接可以在ui中查看pipelines实验运行进度。
- 将pipelines组件打成zip包通过ui上传至服务中心,同样可以在ui查看实验运行进度。
2.6.2 启动Pytorch工作流实例
import json
from typing import NamedTuple
from collections import namedtuple
import kfp
import kfp.dsl as dsl
from kfp import components
from kfp.dsl.types import Integer
def get_current_namespace():
"""Returns current namespace if available, else kubeflow"""
try:
current_namespace = open(
"/var/run/secrets/kubernetes.io/serviceaccount/namespace"
).read()
except:
current_namespace = "kubeflow"
return current_namespace
def create_worker_spec(
worker_num: int = 0
) -> NamedTuple(
"CreatWorkerSpec", [("worker_spec", dict)]
):
"""
Creates pytorch-job worker spec
"""
worker = {}
if worker_num > 0:
worker = {
"replicas": worker_num,
"restartPolicy": "OnFailure",
"template": {
"metadata": {
"annotations": {
"sidecar.istio.io/inject": "false"
}
},
"spec": {
"containers": [
{
"args": [
"--backend",
"gloo",
],
"image": "public.ecr.aws/pytorch-samples/pytorch_dist_mnist:latest",
"name": "pytorch",
"resources": {
"requests": {
"memory": "4Gi",
"cpu": "2000m",
# Uncomment for GPU
# "nvidia.com/gpu": 1,
},
"limits": {
"memory": "4Gi",
"cpu": "2000m",
# Uncomment for GPU
# "nvidia.com/gpu": 1,
},
},
}
]
},
},
}
worker_spec_output = namedtuple(
"MyWorkerOutput", ["worker_spec"]
)
return worker_spec_output(worker)
worker_spec_op = components.func_to_container_op(
create_worker_spec,
base_image="python:slim",
)
@dsl.pipeline(
name="launch-kubeflow-pytorchjob",
description="An example to launch pytorch.",
)
def mnist_train(
namespace: str = get_current_namespace(),
worker_replicas: int = 1,
ttl_seconds_after_finished: int = -1,
job_timeout_minutes: int = 600,
delete_after_done: bool = False,
):
pytorchjob_launcher_op = components.load_component_from_file(
"./component.yaml"
)
master = {
"replicas": 1,
"restartPolicy": "OnFailure",
"template": {
"metadata": {
"annotations": {
# See https://github.com/kubeflow/website/issues/2011
"sidecar.istio.io/inject": "false"
}
},
"spec": {
"containers": [
{
# To override default command
# "command": [
# "python",
# "/opt/mnist/src/mnist.py"
# ],
"args": [
"--backend",
"gloo",
],
# Or, create your own image from
# https://github.com/kubeflow/pytorch-operator/tree/master/examples/mnist
"image": "public.ecr.aws/pytorch-samples/pytorch_dist_mnist:latest",
"name": "pytorch",
"resources": {
"requests": {
"memory": "4Gi",
"cpu": "2000m",
# Uncomment for GPU
# "nvidia.com/gpu": 1,
},
"limits": {
"memory": "4Gi",
"cpu": "2000m",
# Uncomment for GPU
# "nvidia.com/gpu": 1,
},
},
}
],
# If imagePullSecrets required
# "imagePullSecrets": [
# {"name": "image-pull-secret"},
# ],
},
},
}
worker_spec_create = worker_spec_op(
worker_replicas
)
# Launch and monitor the job with the launcher
pytorchjob_launcher_op(
# Note: name needs to be a unique pytorchjob name in the namespace.
# Using RUN_ID_PLACEHOLDER is one way of getting something unique.
name=f"name-{kfp.dsl.RUN_ID_PLACEHOLDER}",
namespace=namespace,
master_spec=master,
# pass worker_spec as a string because the JSON serializer will convert
# the placeholder for worker_replicas (which it sees as a string) into
# a quoted variable (eg a string) instead of an unquoted variable
# (number). If worker_replicas is quoted in the spec, it will break in
# k8s. See https://github.com/kubeflow/pipelines/issues/4776
worker_spec=worker_spec_create.outputs[
"worker_spec"
],
ttl_seconds_after_finished=ttl_seconds_after_finished,
job_timeout_minutes=job_timeout_minutes,
delete_after_done=delete_after_done,
)
if __name__ == "__main__":
import kfp.compiler as compiler
pipeline_file = "test.tar.gz"
print(
f"Compiling pipeline as {pipeline_file}"
)
compiler.Compiler().compile(
mnist_train, pipeline_file
)
# # To run:
# client = kfp.Client()
# run = client.create_run_from_pipeline_package(
# pipeline_file,
# arguments={},
# run_name="test pytorchjob run"
# )
# print(f"Created run {run}")
2.6.3 kfp-kubernetes库
kfp-kubernetes Python库支持创作具有kubernetes特定功能的Kubeflow工作流。具体来说,kfp-kubernetes库支持使用以下创作工作流:
-
Secrets
-
PersistentVolumeClaims
首先安装该库
pip install kfp-kubernetes
2.6.3.1 Secret: As environment variable
from kfp import dsl
from kfp import kubernetes
@dsl.component
def print_secret():
import os
print(os.environ['my-secret'])
@dsl.pipeline
def pipeline():
task = print_secret()
kubernetes.use_secret_as_env(task,
secret_name='my-secret',
secret_key_to_env={'password': 'SECRET_VAR'})
2.6.3.2 Secret: As mounted volume
from kfp import dsl
from kfp import kubernetes
@dsl.component
def print_secret():
with open('/mnt/my_vol') as f:
print(f.read())
@dsl.pipeline
def pipeline():
task = print_secret()
kubernetes.use_secret_as_volume(task,
secret_name='my-secret',
mount_path='/mnt/my_vol')
2.6.3.3 PersistentVolumeClaim: Dynamically create PVC, mount, then delete
from kfp import dsl
from kfp import kubernetes
@dsl.component
def make_data():
with open('/data/file.txt', 'w') as f:
f.write('my data')
@dsl.component
def read_data():
with open('/reused_data/file.txt') as f:
print(f.read())
@dsl.pipeline
def my_pipeline():
pvc1 = kubernetes.CreatePVC(
# can also use pvc_name instead of pvc_name_suffix to use a pre-existing PVC
pvc_name_suffix='-my-pvc',
access_modes=['ReadWriteOnce'],
size='5Gi',
storage_class_name='standard',
)
task1 = make_data()
# normally task sequencing is handled by data exchange via component inputs/outputs
# but since data is exchanged via volume, we need to call .after explicitly to sequence tasks
task2 = read_data().after(task1)
kubernetes.mount_pvc(
task1,
pvc_name=pvc1.outputs['name'],
mount_path='/data',
)
kubernetes.mount_pvc(
task2,
pvc_name=pvc1.outputs['name'],
mount_path='/reused_data',
)
# wait to delete the PVC until after task2 completes
delete_pvc1 = kubernetes.DeletePVC(
pvc_name=pvc1.outputs['name']).after(task2)
2.7 Kubeflow-Pipeline后续演进点
Kubeflow-Pipeline是Kubeflow的一个组件,用于构建和部署机器学习工作流程。目前,Kubeflow-Pipeline已经具备了很多强大的功能,如批量数据预处理、模型训练、模型推理等。未来,它可以在以下几个方面进行进一步演进:
-
支持更广泛的机器学习应用场景:目前Kubeflow-Pipeline主要支持传统的机器学习应用场景,但未来可以进一步支持深度学习、强化学习等更广泛的应用场景。
-
更好的可视化和调试支持:Kubeflow-Pipeline已经具备一些可视化和调试功能,但未来可以进一步提高其易用性和可扩展性,以便更好地支持大规模机器学习工作流程。
-
更好的集成和生态系统支持:目前Kubeflow-Pipeline已经与Kubernetes和其他一些工具进行了集成,但未来可以进一步提高其与其他机器学习和数据科学工具的集成和生态系统支持。
-
更好的安全性和可靠性支持:随着Kubeflow-Pipeline被越来越多地用于生产环境中,其安全性和可靠性将变得越来越重要。使用权限过于高的Sidecar容器作为其实现步骤之间元数据传递的途径,也会是KFP生产级使用的一道门槛。未来可以进一步提高其安全性和可靠性支持,以满足生产环境的需求。
-
Dag引擎组件的水平扩展(HPA)是其重要的一个特性,也是要成为一个成熟引擎所必要的能力。当前KFP在稳定性以及组件的水平扩展上都还有待改进,因此商业使用还需要一段时间,这将是KFP未来的一个重要目标。同时,