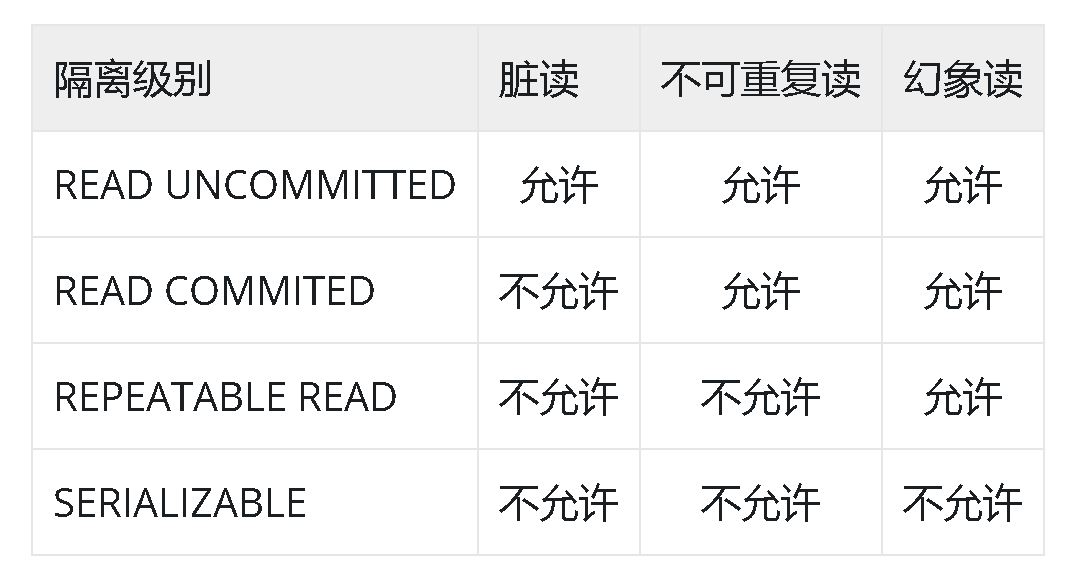
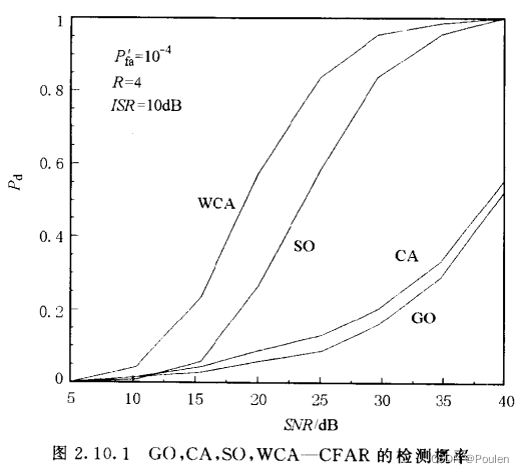
在优化理论中,损失或成本函数测量拟合或预测值与实际值之间的距离。对于大多数机器学习模型,提高性能意味着最小化损失函数。
但对于深度神经网络,执行梯度下降以最小化每个参数的损失函数可能会消耗大量资源。传统方法包括手动推导和编码,或使用 TensorFlow 等机器学习框架的句法和语义约束实现神经模型。
但是,如果可以使用 NumPy 库简单地写下损失函数并自动完成工作呢?这是JAX的工作 - 谷歌在2018年推出的即时编译器,它使用Autograd和XLA(加速线性代数),可以通过大量的Python功能(如ifs,循环,递归和闭包)自动区分原生Python和NumPy代码。JAX 还允许通过跨多个加速器(如 GPU 和 TPU)自动并行化代码来实现快速科学计算。
更进一步,谷歌最近推出了Flax——一个用于JAX的神经网络库,专为灵活性而设计。Flax可以通过从其官方GitHub存储库中分叉一个示例来训练神经网络。在修改模型时,开发人员不再需要向框架添加功能,他们可以简单地修改训练循环(例如train_step设置)即可达到相同的结果。Flax的核心是围绕称为模块的参数化函数构建的,这些函数覆盖了应用,可以用作普通函数。
from flax import nn
import jax.numpy as jnp
class Linear(nn.Module):
def apply(self, x, num_features, kernel_init_fn):
input_features = x.shape[-1]
W = self.param('W', (input_features, num_features), kernel_init_fn)
return jnp.dot(x, W)

用于定义学习线性变换的亚麻代码。
亚麻的发布在社交媒体上引起了轰动。NVIDIA Anima Anandkumar 的机器学习研究总监在推特上发布了 Flax GitHub 链接,并补充说:“我们使用 CGD 来训练 GAN 和 RL 中的约束问题。这个库将非常有用。谷歌大脑研究科学家David Ha(推特名称hardmaru)也支持新的存储库。
对于那些有兴趣尝试亚麻的人来说,目前有三个例子可供测试:MNIST,一个手写数字数据库,主要用作手写数字识别任务;ResNet,一种用于图像识别的深度残差学习架构,在ImageNet中训练,主要用于测量大规模集群计算能力;和 1 亿字语言模型基准测试,这是语言建模实验的标准训练和测试设置。
Flax团队还呼吁开发人员帮助构建额外的端到端示例,例如翻译,语义分割,GAN,VAE等。
Google Research: Flax存储库位于GitHub上。