- (꒪ꇴ꒪ ),Hello我是祐言QAQ
- 我的博客主页:C/C++语言,Linux基础,ARM开发板,软件配置等领域博主🌍
- 快上🚘,一起学习,让我们成为一个强大的攻城狮!
- 送给自己和读者的一句鸡汤🤔:集中起来的意志可以击穿顽石!
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
内核链表(Kernel Linked List)是操作系统内核中常用的一种数据结构,用于管理和维护一系列数据元素(节点)。它也是一种线性数据结构,其中每个节点包含了数据元素本身以及指向下一个节点的指针。内核链表在操作系统中广泛应用于管理进程、文件描述符、内存分配等诸多场景。
一、内核链表概述
内核链表通常由一个特定的数据结构定义,该数据结构包含一个或多个指向链表中首个和最后一个节点的指针,以及其他用于操作和管理链表的属性。在C语言中,内核链表的定义示例:
//数据
typedef int Datatype;
//节点(大结构体)
typedef struct Kernel_node
{
Datatype data; //数据域
struct kernel_list list; //指针域
}k_node;
//指针节点(小结构体)
struct kernel_list {
struct kernel_list *prev;//前驱指针
struct kernel_list *next;//后继指针
};
kernel_list结构体定义了一个内核链表的节点,其中prev指向前一个节点,next指向下一个节点,这一点在某种意义上与常规的双向循环链表一致,但是还是有区别的。我们再来看看之前所学习的双向循环链表的节点定义:
//数据
typedef int Datatype;
//节点
typedef struct Node
{
DataType data; //数据域
struct Node *prev; //指针域:前驱指针
struct Node *next; //指针域:后继指针
}node;这样一对比,就会发现常规链表与内核链表最大的区别就是嵌套,内核链表的节点结构通常嵌套在某个容器数据结构中,可以理解为能单独对指针域进行操作,而不影响数据。
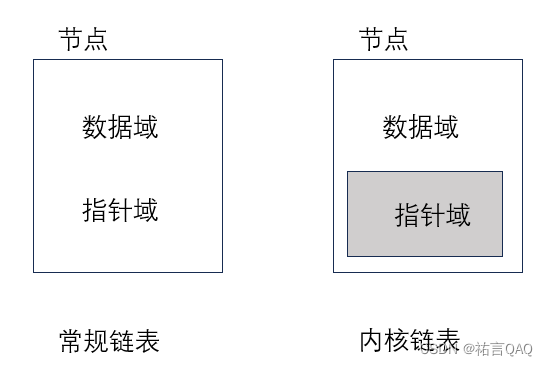
所以这也暴露了常规链表的缺陷:
(1)每一种应用中,节点都是特殊的,导致每一条链表都是特殊的,因此每一种链表的增删查改这些算法也都是特殊的;
(2)当一个节点处于变化的数据结构网络中的时候,节点指针无法指向稳定不变的节点。
这样的描述或许不能让你有直观的感觉,但当你往下看,真正去理解了内核链表再回过头来,你就会豁然开朗。
二、内核链表的原理
内核链表的节点结构通常嵌套在某个容器数据结构中,以实现紧密关联。节点结构中至少包含两个指针,一个指向前一个节点,一个指向后一个节点。这样的设计使得在链表中插入、删除节点的操作更加高效,无需像数组那样移动大量元素。我们可以这样理解:
(1)将链表的结构抽象出来,去除节点中的具体数据,只保留逻辑的双向指针,形成一条只包含逻辑的“纯粹的链表”。
(2)将链表“寄宿”于具体的数据节点之中,使他贯穿这些节点,可以借助一定的方式通过“纯粹链表“的指针域得到数据节点。
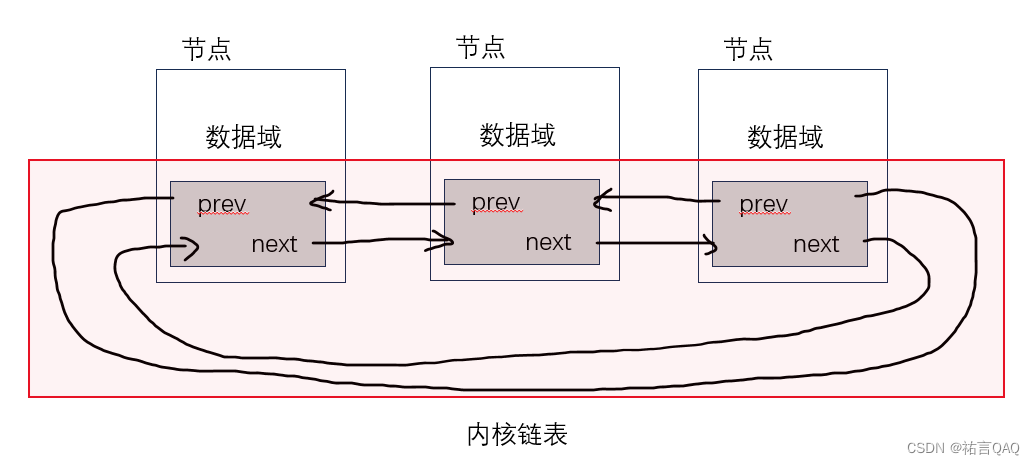
内核链表做到了将数据和逻辑(指针)分开,在红色方框内的这样只有前后两指针的链表形式被称为Linux标准双向循环链表。
三、内核链表的操作
在学习内核链表的操作之前,我们先要来了解一下list.h文件。list.h 是一个常见的头文件,通常用于实现内核链表(双向链表)的相关功能。在 Linux 内核中,list.h 提供了一种高效的方式来操作链表,包括插入、删除、遍历等操作。完整的该文件可从网上各处找到,接下来我们将只举例用到的结构体。
1. 节点声明
//数据
typedef int Datatype;
//链表节点(大结构体)
typedef struct Kernel_node
{
Datatype data; //数据域
struct list_head list; //指针域
}k_node;list_head 是在list.h中已经定义好的指针域部分,我们可以将其称之为小结构体,用它来构建“纯粹链表”。
struct list_head {
struct list_head *next, *prev;
};2.初始化链表
//初始化链表
k_node *init_kernel_list()
{
k_node *head = malloc(sizeof(k_node));
if (head==NULL)
{
perror("malloc");
exit(0);
}
else
{
INIT_LIST_HEAD(&(head->list));//带参宏,初始化小结构体里面的这两个指针成员
}
return head;
}
INIT_LIST_HEAD也是list.h中已经定义好的带参宏,原型如下:
#define INIT_LIST_HEAD(ptr) do { \
(ptr)->next = (ptr); (ptr)->prev = (ptr); \
} while (0)3.创建节点
//创建节点
k_node *create_kernel_node(Datatype data)
{
k_node *new = malloc(sizeof(k_node));
if (new != NULL)
{
new->data = data;
new->list.next = NULL;
new->list.prev = NULL;
}
return new;
}
4.遍历链表
//遍历链表
void display(k_node *head)
{
struct list_head *pos = NULL;
k_node *Node = NULL;
list_for_each(pos, &(head->list))
{
Node = list_entry(pos, k_node, list);
printf("%d ", Node->data);
}
printf("\n");
}其中list_for_each和list_entry也是在list.h中定义好的带参宏:
//遍历链表的for循环,每一次循环体内得到的就是一个小结构体指针
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); \
pos = pos->next)
//小结构体指针ptr,大结构体类型type,小结构体在大结构体内部的成员名
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
做完这些操作,我们就可以通过一个实例来验证我们的操作是否正确,我们可以创建一个10个节点的链表并打印。

实例代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include "list.h"
//数据
typedef int Datatype;
//链表节点
typedef struct Kernel_node
{
Datatype data; //数据域
struct list_head list; //指针域
}k_node;
//初始化链表
k_node *init_kernel_list()
{
k_node *head = malloc(sizeof(k_node));
if (head==NULL)
{
perror("malloc");
exit(0);
}
else
{
INIT_LIST_HEAD(&(head->list));
}
return head;
}
//创建节点
k_node *create_kernel_node(Datatype data)
{
k_node *new = malloc(sizeof(k_node));
if (new != NULL)
{
new->data = data;
new->list.next = NULL;
new->list.prev = NULL;
}
return new;
}
//遍历链表
void display(k_node *head)
{
struct list_head *pos = NULL;
k_node *Node = NULL;
list_for_each(pos, &(head->list))
{
Node = list_entry(pos, k_node, list);
printf("%d ", Node->data);
}
printf("\n");
}
int main(int argc, char const *argv[])
{
k_node *head = init_kernel_list();
for (int i = 0; i < 10; ++i)
{
k_node *new = create_kernel_node(i+1);
//插入节点到链表
list_add_tail(&(new->list), &(head->list));
}
//遍历链表
display(head);
return 0;
}
(未完待续...)
四、今日总结
与一般链表相比,内核链表有一些特点和优势:
1.容器结构体: 在内核链表中,节点通常嵌套在某个数据结构中,这个数据结构即所谓的容器结构体。这种设计可以让数据元素和链表节点紧密关联,方便数据的操作和管理。
2.稳定性和预测性: 内核链表在操作系统内核中广泛应用,而且内核链表的实现通常被优化为在各种情况下都能够稳定和预测地工作,不容易受到异常情况的影响。
3.特定操作: 内核链表通常提供一系列针对特定操作的函数,如插入、删除、遍历等。这些函数经过精心的设计和优化,能够高效地处理链表操作。
总之,内核链表是操作系统内核中的一种重要数据结构,用于高效地管理各种资源和数据。它与一般链表相比,更注重稳定性和性能优化,以满足操作系统的特定需求。
更多C语言、Linux系统、ARM板实战和数据结构相关文章,关注专栏:
手撕C语言
玩转linux
脚踢数据结构
6818(ARM)开发板实战
📢写在最后
- 今天的分享就到这啦~
- 觉得博主写的还不错的烦劳
一键三连喔~ - 🎉感谢关注🎉