Linux 1.2.13 -- IP分片重组源码分析
- 引言
- 为什么需要分片
- 传输层是否存在分段操作
- IP分片重组源码分析
- ip_create
- ip_find
- ip_frag_create
- ip_done
- ip_glue
- ip_free
- ip_expire
- ip_defrag
- ip_rcv
- 总结
本文源码解析参考: 深入理解TCP/IP协议的实现之ip分片重组 – 基于linux1.2.13
计网理论部分参考: << 自顶向下学习计算机网络 >>
Linux 1.2.13 源码仓库链接: read-linux-1.2.13-net-code
引言
笔者在完成cs144 lab 后,发现自己对IP层分片这部分知识点模糊不清,阅读了自顶向下学习计算机网络书籍对应章节后,发现书上对IP层分片这部分内容讲解较为简单,所以特此翻阅Linux网络子系统源码进行学习。
在正式进入主题之前,我想先抛出我在没有研究源码前的一些疑惑:
- 既然书上说IP协议是不可靠的协议,那么IP层进行分片,又需要进行分片重组,只有重组完毕后才能将数据报交给上层,那么如果分片丢失或者超时迟迟未到该如何处理呢?
- 如果IP层需要被分片的数据再完全组装后才能上交上层,那么是否需要使用到序列号,ACK,重传等机制确保可靠性呢?
- 如果IP层需要实现可靠性传输,那么为什么又说IP协议是不可靠的呢?
- . . .
带着以上种种疑惑,我开启了对Linux 1.2.13 net模块的探索之路。
本文所讲内容未必完全正确,如有错误,欢迎在评论区指出。
为什么需要分片
不同的链路层协议所能承载的网络层分组大小是不同的,有的协议能承载大数据报,而有的协议只能承载小分组。例如:
- 以太网帧能够承载不超过1500字节的数据,而某些广域网链路的帧可承载不超过576字节的数据
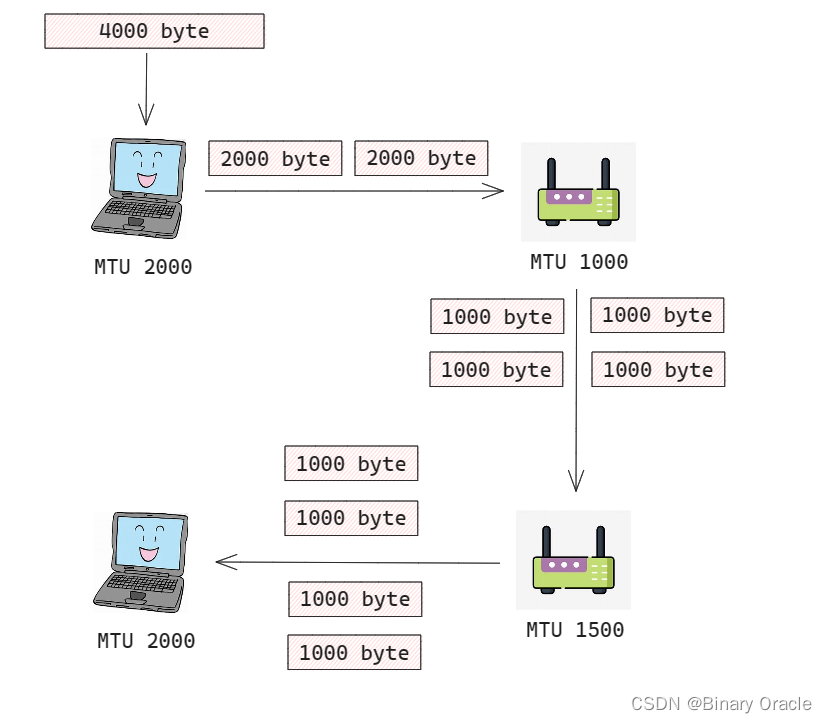
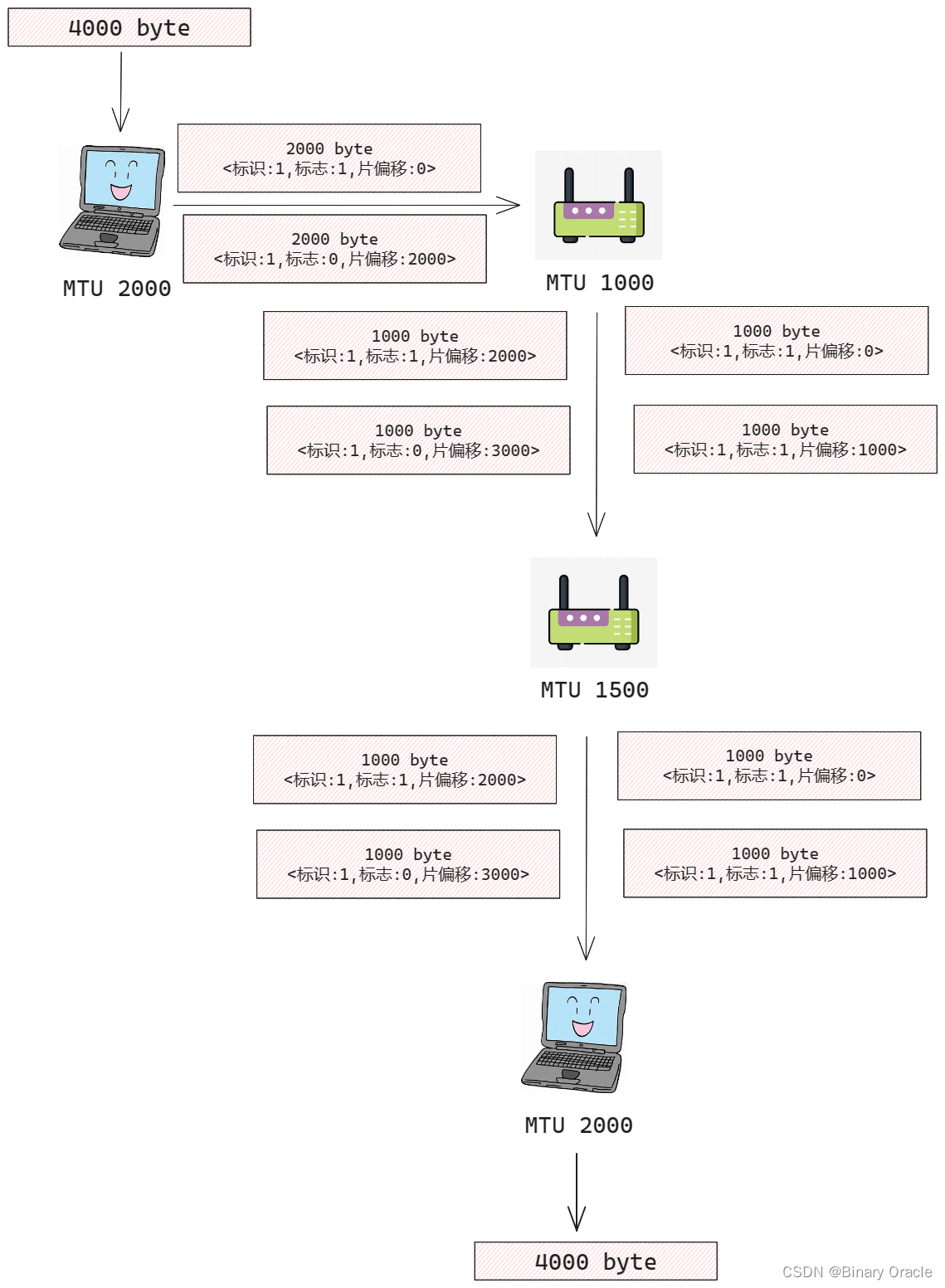
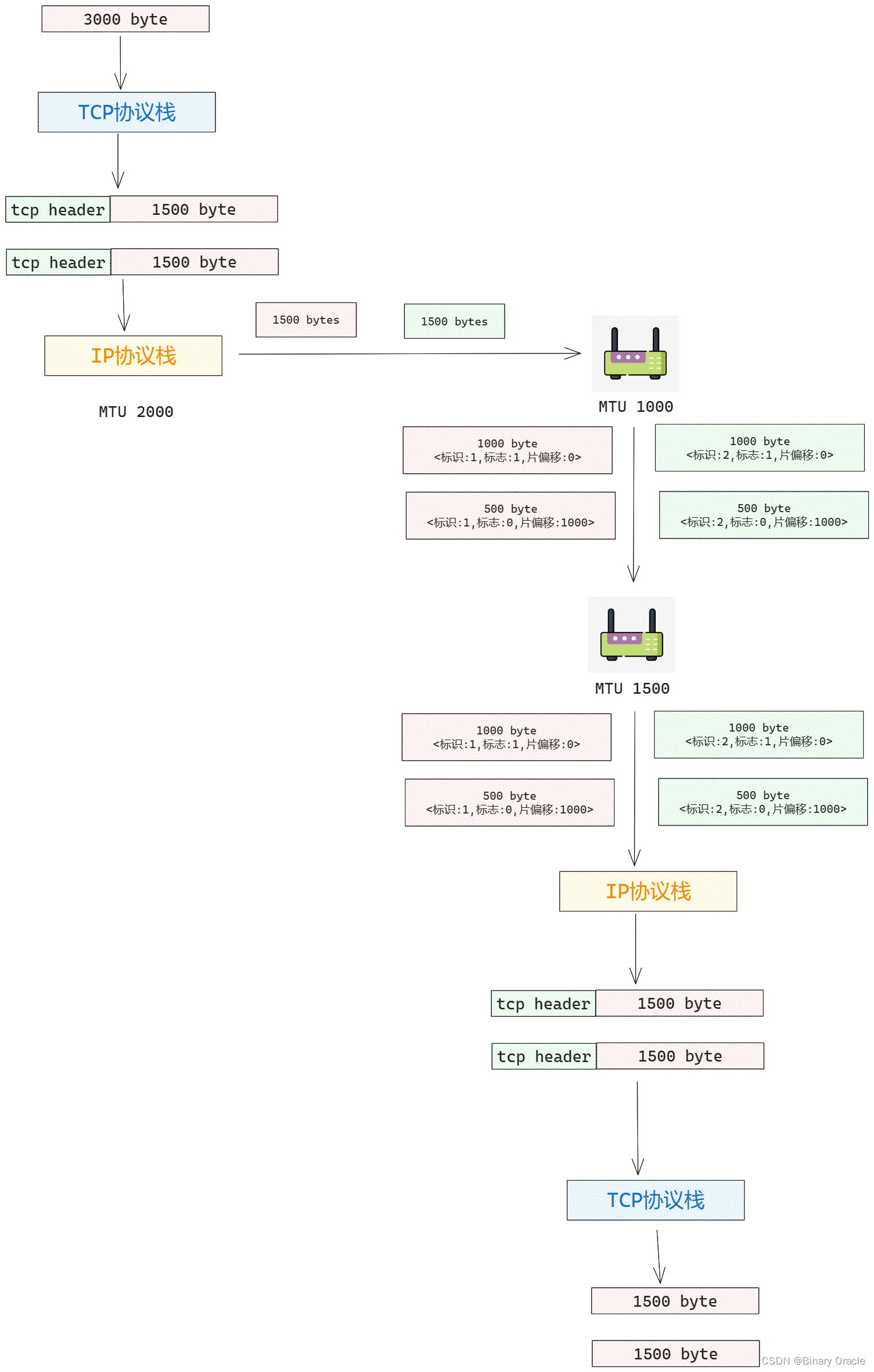
我们将一个链路层帧能承载的最大数据量叫做最大传送单元(MTU),因为每个IP数据报封装在链路层帧中从一台路由器传输到下一台路由器,因此链路层协议的MTU严格限制着IP数据报的长度。同时发送方与目的地路径上每段链路可能使用不同的链路层协议,且每种协议可能具有不同的MTU,这意味着已经分片的IP数据报可能面临再次分片,那么我们该如何处理这种情况呢?
- 如果遇到MTU更小的链路层协议,则将现有分片分成两个或多个更小的IP数据报,用单独的链路层帧封装这些较小的IP数据报,然后通过输出链路发送这些帧
使用IPV4协议的路由器才会执行再分片操作,使用IPV6协议的路由器不会进行再分片操作,而是回复一个ICMP错误报文,表示IP数据包过大
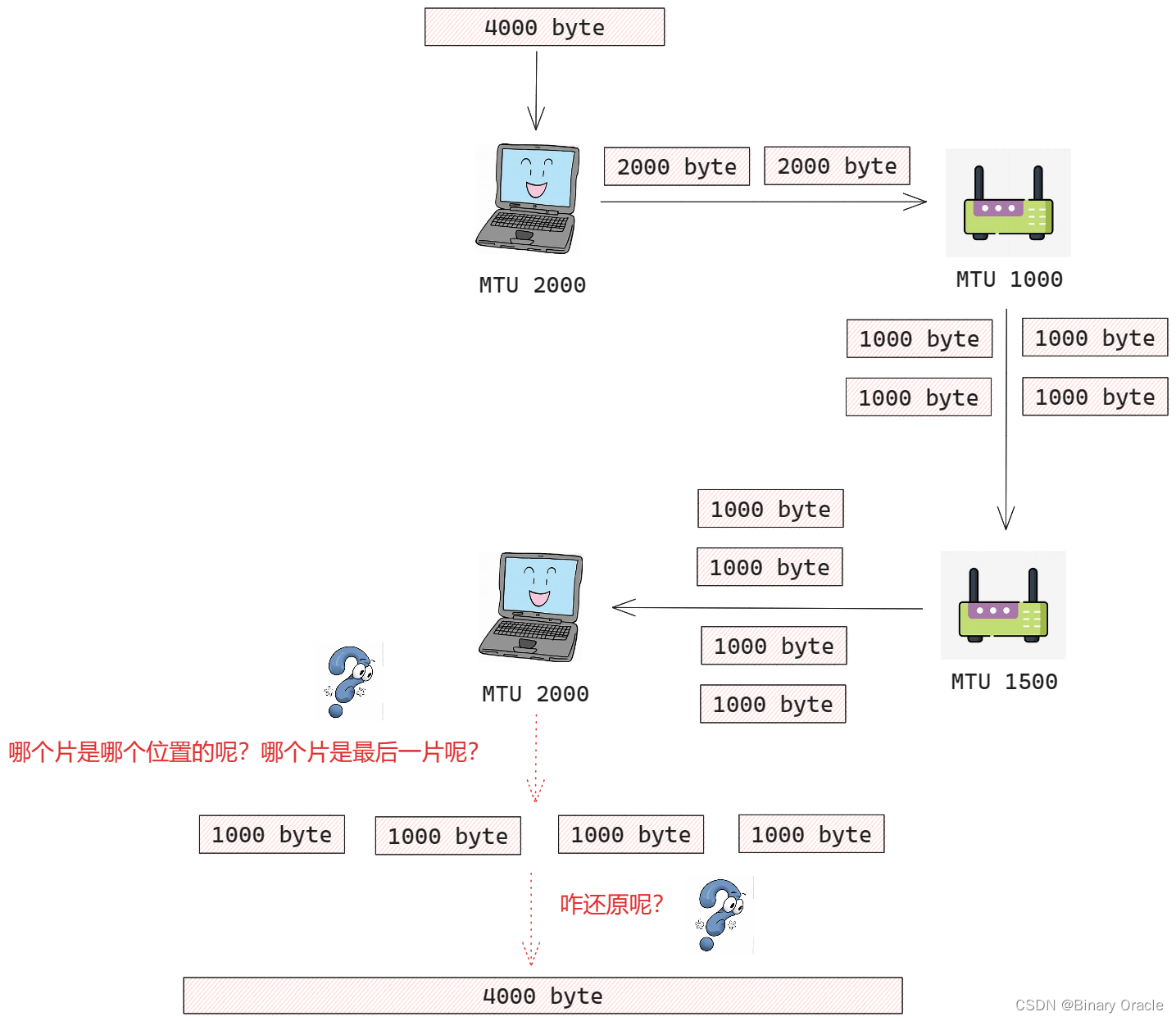
TCP与UDP都希望从网络层接受到完整的,未分片的报文,那么如果我们在路由器中重新组装数据报是否合理呢?
- 很显然,这很不河里 ! 路由器中重新组装数据报会给协议带来相当大的复杂性并且影响路由器的性能,为坚持网路内核保持简单的原则,IPV4设计者决定将数据报的重新组装工作放到端系统中,而不是网络路由器中。
当一台目的主机从相同源收到一系列数据报时,它需要确定这些数据报中的某些是否是一些原来较大的数据报的片,这个该如何实现呢? 如果某些数据报是这些片的话,则它必须进一步确定何时收到了最后一片,并且将这些接收到的片拼接到一起以形成初始的数据报,这又该如何实现呢?
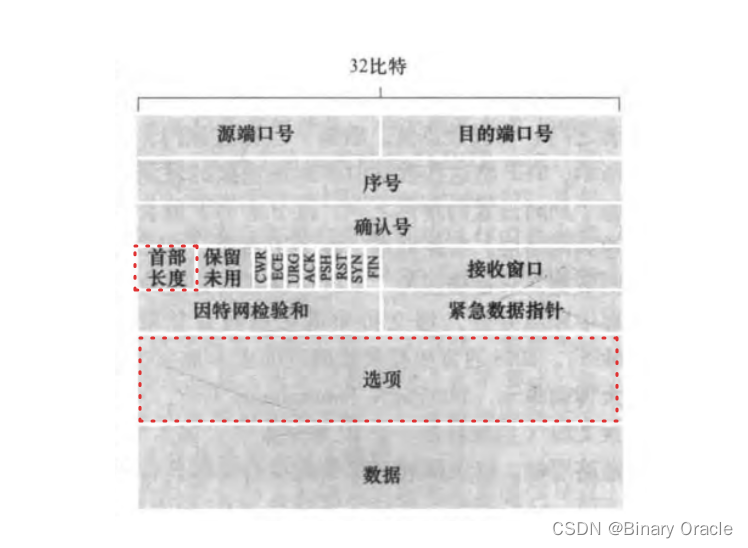
IPV4的设计者将标识,标志和片偏移字段放在IP数据报首部中:
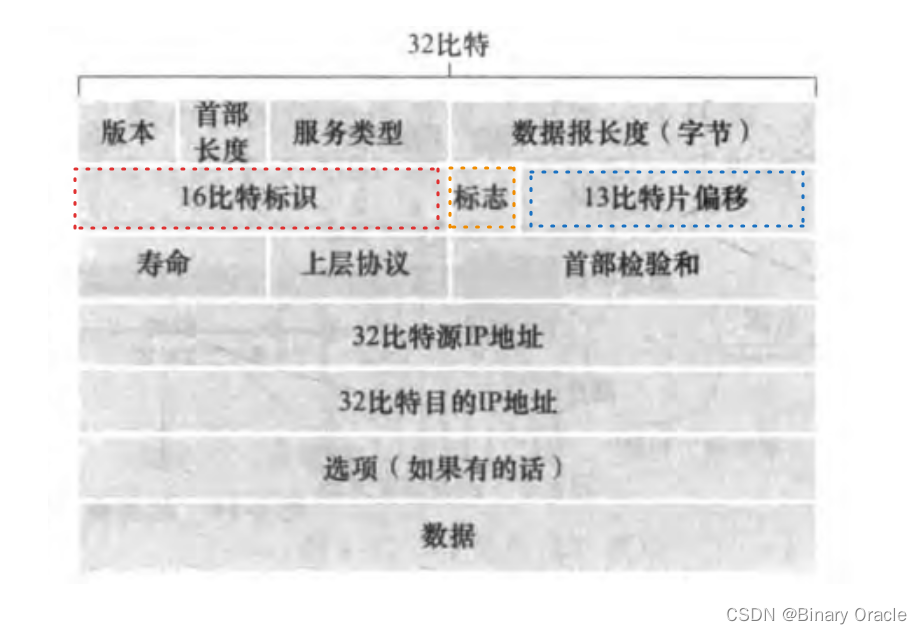
- 标识 : 检查标识号以确定哪些数据报实际是同一较大数据报的分片
- 标志: 当前分片是否是最后一个分片
(最后一个片的比特设为0,其他片均设置为1),由于IP是一种不可靠服务,一个或多个片可能永远也无法达到目的地,所以即使接收到了最后一个分片,也未必等同于接收到了所有分片,还需要重组后通过校验和来检验是否接收到完整数据报数据 - 片偏移: 偏移字段指定当前片应放在IP数据报的哪个位置
传输层是否存在分段操作
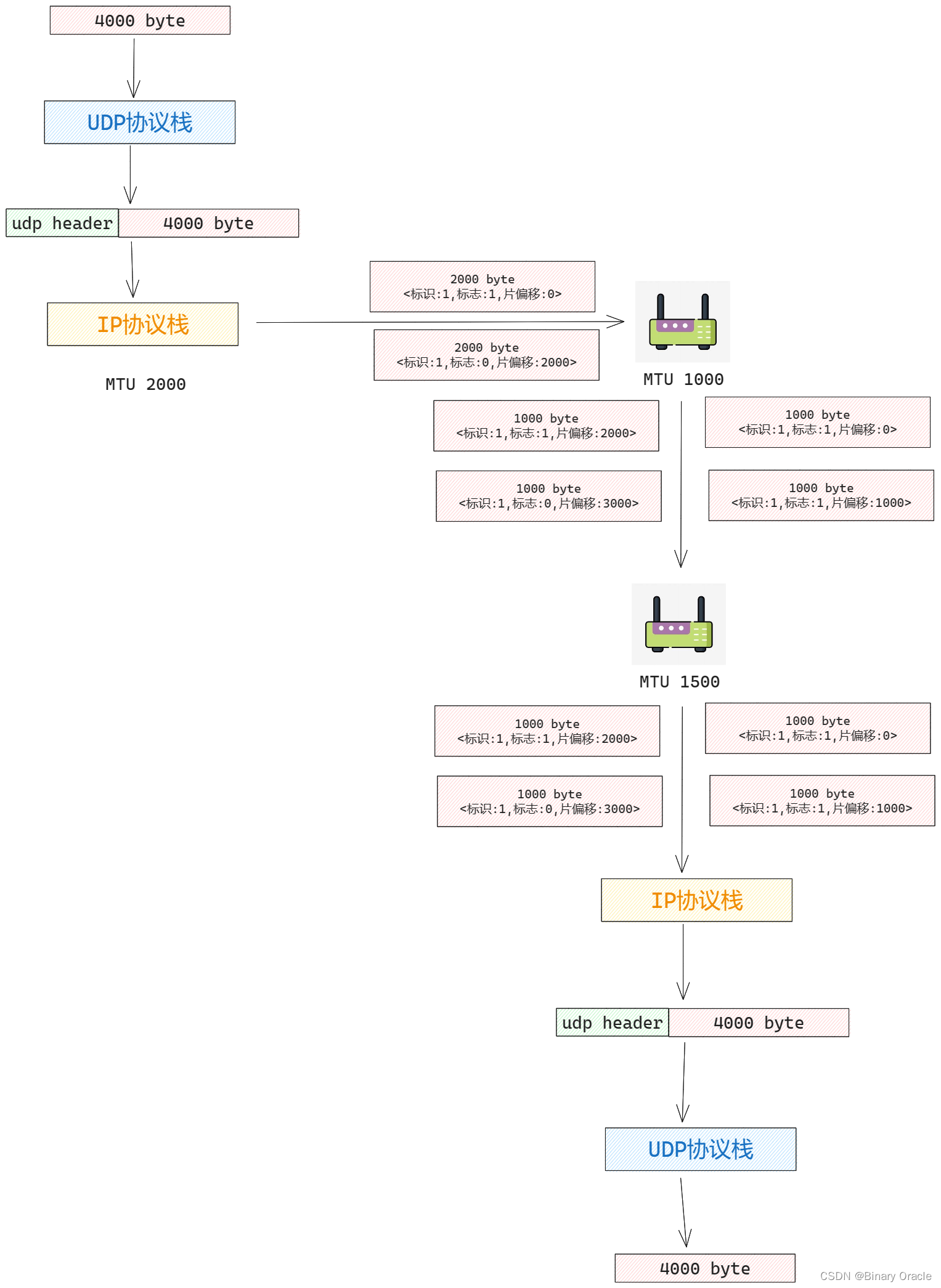
传输层是否存在分段行为,这个问题需要分协议而论之,但就不可靠无连接的UDP协议而言,回答是NO!UDP协议除了端口复用/分解功能及少量的差错检测外,它几乎没有对IP增加别的东西。实际上,如果应用程序开发人员选择UDP而不是TCP,则该应用程序差不多就是直接和IP打交道。
对于UDP协议栈而言,它会把应用程序传下来的数据直接封装为一个大的UDP数据报,然后传递给网络层,如果数据报大于当前主机链路层协议的MTU协议限制,则会由IP层进行分片和重组处理,正如上一小节所讲。而接收端会接收到IP层重组后得到的完整UDP数据报,然后进行校验和检验后,将payload传递给应用程序,整个过程中UDP协议并不会对接收的应用程序进行分段:
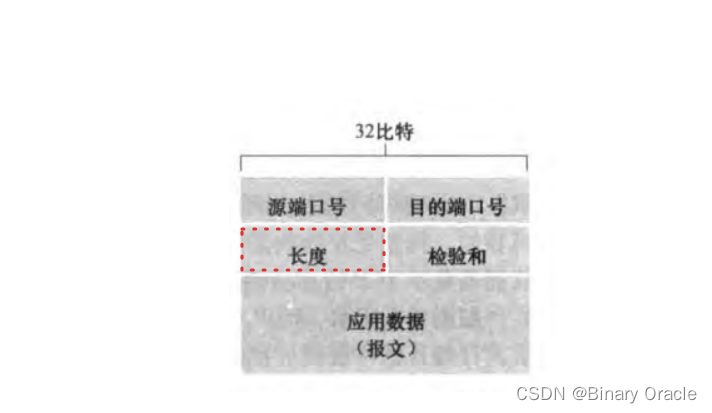
但是UDP协议的header头部中存在长度字段,因此整个UDP数据报的大小会受到该字段的长度限制:
但是对于TCP协议而言,这个回答是YES,TCP协议本身是可靠的有连接的流传输协议,通过GBN(回退N步)加SR(选择重传)协议混合实现可靠传输,依靠滑动窗口实现流量控制,最后依靠拥塞窗口实现拥塞控制。
对于TCP协议而言,当应用程序传递下来数据需要发送时,是将数据全部封装在单个TCP数据报中一次性发送出去,还是拆分成多次发送取决于以下五个因素:
-
当前TCP连接发送窗口的剩余空闲大小

-
当前TCP连接对端的接收窗口剩余空闲大小
-
最大报文段长度(MSS)
-
拥塞窗口大小
-
tcp数据报中len字段长度
本次发送数据大小 = Min(当前TCP连接发送窗口的剩余空闲大小,当前TCP连接对端的接收窗口剩余空闲大小,最大报文段长度(MSS),拥塞窗口大小,tcp数据报中len字段长度, 应用程序传输数据大小)
MSS通常根据最初确定的由本地发送主机发送的最大链路层帧长度(MTU)设置,MSS的值实际可以看做是MTU - TCP首部 - IP首部剩下的大小,也就是说MSS实际指代的是TCP报文段中应用层数据的最大长度,而不是指包括TCP首部的整个TCP报文段的最大长度。
TCP协议通常会通过首部中的选项字段完成发送方和接收方对最大报文段长度(MSS)的协商。
所以对于TCP协议而言,如果应用程序传下来一个较大的数据包,协议栈可能会分为多批次进行传输,也就是进行分段,大的数据报切分成多个小数据报进行传输,并且由于tcp协议栈会保证单次传输的数据报大小小于MTU限制,所以一般不会在IP层发生分片操作,但是如果传输链路上出现了更小的MTU限制,还是会进行IP分片和重组:
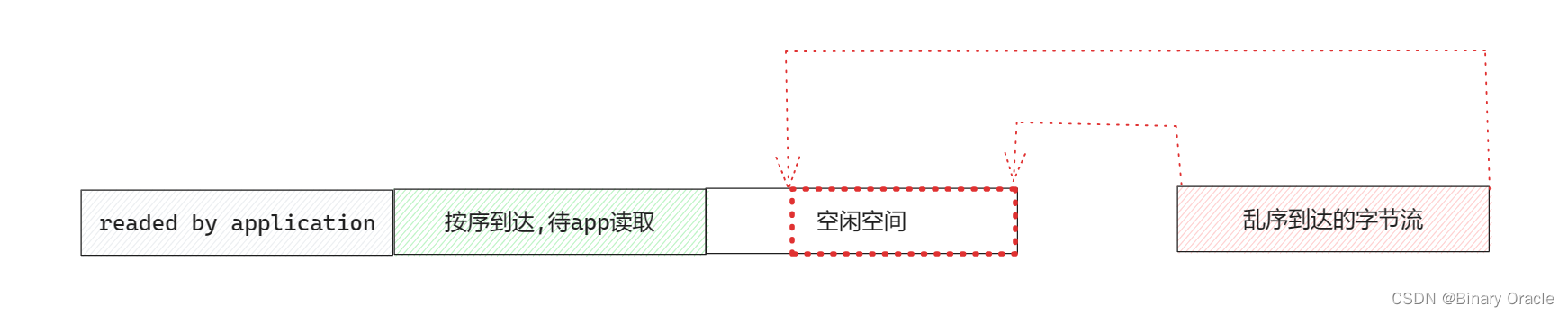
并且和UDP不同的一点时,TCP只要接收到按序到达的一段字节流,并且此时应用程序正在等待读取数据,TCP协议栈就会把这段按序到达的数据丢给应用程序,然后把接收窗口的已读指针向前推进部分,因此这也是为什么称TCP为流式协议 – 就像水龙头一样,只要有水就会流出来。
如果UDP发送端发送的是一个大的数据报,那么UDP接收端会在接收完整个大的数据报后,才会把接收到的数据丢给应用程序,因此也称UDP协议为数据报协议。
IP分片重组源码分析
上面铺垫了很多理论知识,从本节开始,我们进入实践环节,看看IP分片重组过程是否如我们所言一般。
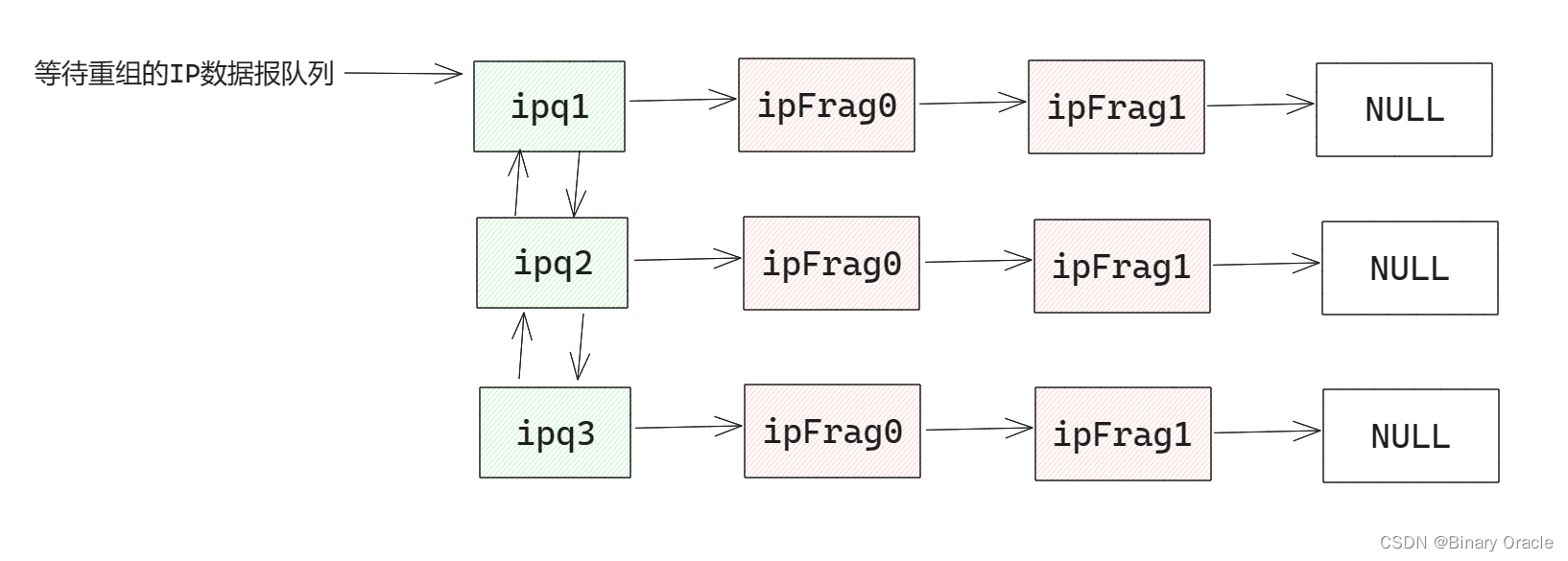
在Linux 1.2.13的net模块中,使用ipfrag结构来描述一个ip分片信息,使用ipq结构来描述一个完整的传输层数据包信息:
ip.h:
/* Describe an IP fragment. */
// 描述一个IP分片
struct ipfrag {
int offset; /* offset of fragment in IP datagram - IP分片的在IP数据报里面的偏移 */
int end; /* last byte of data in datagram - 是否是最后一个分片 */
int len; /* length of this fragment -- 当前分片大小 */
struct sk_buff *skb; /* complete received fragment */
unsigned char *ptr; /* pointer into real fragment data -- 指向分片数据 */
struct ipfrag *next; /* linked list pointers -- 串联起前后分片 */
struct ipfrag *prev;
};
/* Describe an entry in the "incomplete datagrams" queue. */
// 用于描述一个完整的传输层数据包,同时通过前后指针将未重组完成的IP数据报串联起来
struct ipq {
unsigned char *mac; /* pointer to MAC header -- MAC头部地址 */
struct iphdr *iph; /* pointer to IP header -- IP头 */
int len; /* total length of original datagram -- 原始数据报大小 */
short ihlen; /* length of the IP header -- IP头大小 */
short maclen; /* length of the MAC header -- MAC头大小 */
struct timer_list timer; /* when will this queue expire? -- 定时器 --> 重组分片最大等待时长 */
struct ipfrag *fragments; /* linked list of received fragments -- IP分片链表 */
struct ipq *next; /* linked list pointers -- 串联起未完成重组的IP数据报 */
struct ipq *prev;
struct device *dev; /* Device - for icmp replies -- 重组失败后通过该接口发送ICMP包 */
};
ip.c:
ip_create
- ip_create函数用于添加一个新的ipq节点到已有的ipq队列中,该队列用于等待接收一个新的IP数据报的所有分片到达,其维护了属于同一个分片组(同一个传输层数据包)的多个分片
/*
* Add an entry to the 'ipq' queue for a newly received IP datagram.
* We will (hopefully :-) receive all other fragments of this datagram
* in time, so we just create a queue for this datagram, in which we
* will insert the received fragments at their respective positions.
*/
// 创建一个队列用于重组分片
// 参数: 承载当前分片数据信息,ip首部,从哪个链路层设备上接收到的以太网帧
static struct ipq *ip_create(struct sk_buff *skb, struct iphdr *iph, struct device *dev)
{
struct ipq *qp;
int maclen;
int ihlen;
// 分片一个新的表示分片队列的节点
qp = (struct ipq *) kmalloc(sizeof(struct ipq), GFP_ATOMIC);
if (qp == NULL)
{
printk("IP: create: no memory left !\n");
return(NULL);
skb->dev = qp->dev;
}
memset(qp, 0, sizeof(struct ipq));
/*
* Allocate memory for the MAC header.
*
* FIXME: We have a maximum MAC address size limit and define
* elsewhere. We should use it here and avoid the 3 kmalloc() calls
*/
// mac头长度等于ip头减去mac头首地址
maclen = ((unsigned long) iph) - ((unsigned long) skb->data);
qp->mac = (unsigned char *) kmalloc(maclen, GFP_ATOMIC);
if (qp->mac == NULL)
{
printk("IP: create: no memory left !\n");
kfree_s(qp, sizeof(struct ipq));
return(NULL);
}
/*
* Allocate memory for the IP header (plus 8 octets for ICMP).
*/
// ip头长度由ip头字段得出,多分配8个字节给icmp
ihlen = (iph->ihl * sizeof(unsigned long));
qp->iph = (struct iphdr *) kmalloc(ihlen + 8, GFP_ATOMIC);
if (qp->iph == NULL)
{
printk("IP: create: no memory left !\n");
kfree_s(qp->mac, maclen);
kfree_s(qp, sizeof(struct ipq));
return(NULL);
}
/* Fill in the structure. */
// 把mac头内容复制到mac字段
// 第一个参数是dst,第二个是source,是将skb中相关信息copy到qp中
memcpy(qp->mac, skb->data, maclen);
// 把ip头和传输层的8个字节复制到iph字段,8个字段的内容用于发送icmp报文时
memcpy(qp->iph, iph, ihlen + 8);
// 未分片的ip报文的总长度,未知,收到所有分片后重新赋值
qp->len = 0;
// 当前分片的ip头和mac头长度
qp->ihlen = ihlen;
qp->maclen = maclen;
qp->fragments = NULL;
qp->dev = dev;
/* Start a timer for this entry. */
// 开始计时,一定时间内还没收到所有分片则重组失败,发送icmp报文
qp->timer.expires = IP_FRAG_TIME; /* about 30 seconds */
qp->timer.data = (unsigned long) qp; /* pointer to queue */
qp->timer.function = ip_expire; /* expire function */
add_timer(&qp->timer);
/* Add this entry to the queue. */
qp->prev = NULL;
cli();
// 头插法插入分片重组的队列
// ipqueue是全局头指针,指向ipq队列首元素
qp->next = ipqueue;
// 如果当前新增的节点不是第一个节点则把当前第一个节点的prev指针指向新增的节点
if (qp->next != NULL)
qp->next->prev = qp;
//更新ipqueue指向新增的节点,新增节点是首节点
ipqueue = qp;
sti();
return(qp);
}
ip_find
- ip_find函数负责根据ip头查找对应的ipq队列
/*
* Find the correct entry in the "incomplete datagrams" queue for
* this IP datagram, and return the queue entry address if found.
*/
// 根据ip头找到分片队列的头指针
static struct ipq *ip_find(struct iphdr *iph)
{
struct ipq *qp;
struct ipq *qplast;
cli();
qplast = NULL;
for(qp = ipqueue; qp != NULL; qplast = qp, qp = qp->next)
{ // 对比ip头里的几个字段
if (iph->id== qp->iph->id && iph->saddr == qp->iph->saddr &&
iph->daddr == qp->iph->daddr && iph->protocol == qp->iph->protocol)
{ // 找到后重置计时器,在这删除,在ip_find外面新增一个计时
del_timer(&qp->timer); /* So it doesn't vanish on us. The timer will be reset anyway */
sti();
return(qp);
}
}
sti();
return(NULL);
}
ip_frag_create
- ip_frag_create函数负责创建一个表示单个ip分片的结构体ipfrag – 它表示其中一个分片
/*
* Create a new fragment entry.
*/
// 创建一个表示ip分片的结构体
static struct ipfrag *ip_frag_create(int offset, int end, struct sk_buff *skb, unsigned char *ptr)
{
struct ipfrag *fp;
fp = (struct ipfrag *) kmalloc(sizeof(struct ipfrag), GFP_ATOMIC);
if (fp == NULL)
{
printk("IP: frag_create: no memory left !\n");
return(NULL);
}
memset(fp, 0, sizeof(struct ipfrag));
/* Fill in the structure. */
fp->offset = offset; // ip分配的首字节在未分片数据中的偏移
fp->end = end; // 最后一个字节的偏移 + 1,即下一个分片的首字节偏移
fp->len = end - offset; // 分片长度
fp->skb = skb;
fp->ptr = ptr; // 指向分片的数据首地址
return(fp);
}
ip_done
- ip_done函数负责判断分片是否已经全部到达
/*
* See if a fragment queue is complete.
*/
// 判断分片是否全部到达
static int ip_done(struct ipq *qp)
{
struct ipfrag *fp;
int offset;
/* Only possible if we received the final fragment. */
// 收到最后分片的时候会更新len字段,如果没有收到他就是初始化0,所以为0说明最后一个分片还没到达,直接返回未完成
if (qp->len == 0)
return(0);
// 接收到最后一个分片,但分片可能是无序到达的,因此需要检查是否接收到了当前IP数据报的所有IP分片
/* Check all fragment offsets to see if they connect. */
fp = qp->fragments;
offset = 0;
// 检查所有分片,每个分片是按照偏移量从小到大排序的链表,因为每次分片节点到达时会插入相应的位置
while (fp != NULL)
{ /*
如果当前节点的偏移大于期待的偏移(即上一个节点的最后一个字节的偏移+1,由end字段表示),
说明有中间节点没到达,直接返回未完成
*/
if (fp->offset > offset)
return(0); /* fragment(s) missing */
offset = fp->end;
fp = fp->next;
}
/* All fragments are present. */
// 分片全部到达并且每个分片的字节连续则重组完成
return(1);
}
ip_glue
- ip_glue函数负责重组同一队列里的所有ip分片
/*
* Build a new IP datagram from all its fragments.
*
* FIXME: We copy here because we lack an effective way of handling lists
* of bits on input. Until the new skb data handling is in I'm not going
* to touch this with a bargepole. This also causes a 4Kish limit on
* packet sizes.
*/
// 重组成功后构造完整的ip报文
static struct sk_buff *ip_glue(struct ipq *qp)
{
struct sk_buff *skb;
struct iphdr *iph;
struct ipfrag *fp;
unsigned char *ptr;
int count, len;
/*
* Allocate a new buffer for the datagram.
*/
// 整个包的长度等于mac头长度+ip头长度+数据长度
len = qp->maclen + qp->ihlen + qp->len;
// 分配新的skb
if ((skb = alloc_skb(len,GFP_ATOMIC)) == NULL)
{
ip_statistics.IpReasmFails++;
printk("IP: queue_glue: no memory for gluing queue 0x%X\n", (int) qp);
ip_free(qp);
return(NULL);
}
/* Fill in the basic details. */
// 这里应该是等于qp->len?
skb->len = (len - qp->maclen);
skb->h.raw = skb->data; // data字段指向新分配的内存首地址
skb->free = 1;
/* Copy the original MAC and IP headers into the new buffer. */
ptr = (unsigned char *) skb->h.raw;
memcpy(ptr, ((unsigned char *) qp->mac), qp->maclen); // 把mac头复制到新的内存
ptr += qp->maclen;
memcpy(ptr, ((unsigned char *) qp->iph), qp->ihlen); // 把ip头复制到新的内存
ptr += qp->ihlen; // 指向数据部分的首地址
skb->h.raw += qp->maclen;// 指向ip头首地址
count = 0;
/* Copy the data portions of all fragments into the new buffer. */
fp = qp->fragments;
// 开始复制数据部分
while(fp != NULL)
{ // 如果当前节点的数据长度+已经复制的内容长度大于skb->len则说明内容溢出了,丢弃该数据包
if(count+fp->len > skb->len)
{
printk("Invalid fragment list: Fragment over size.\n");
ip_free(qp);
kfree_skb(skb,FREE_WRITE);
ip_statistics.IpReasmFails++;
return NULL;
}
// 把分片中的数据复制到对应偏移的位置
memcpy((ptr + fp->offset), fp->ptr, fp->len);
// 已复制的数据长度
count += fp->len;
fp = fp->next;
}
/* We glued together all fragments, so remove the queue entry. */
ip_free(qp);// 数据复制完后可以释放分片队列了
/* Done with all fragments. Fixup the new IP header. */
iph = skb->h.iph; // 上面的raw字段指向了ip头首地址,skb->h.iph等价于raw字段的值
iph->frag_off = 0; // 清除分片字段
// 更新总长度为ip头+数据的长度
iph->tot_len = htons((iph->ihl * sizeof(unsigned long)) + count);
skb->ip_hdr = iph;
ip_statistics.IpReasmOKs++;
return(skb);
}
重组的大致流程就是申请一块新内存,然后把mac头、ip头复制过去。再遍历分片队列,把每个分片的数据拼起来。最后更新一些字段。
ip_free
- ip_free函数负责释放ip分片队列
/*
* Remove an entry from the "incomplete datagrams" queue, either
* because we completed, reassembled and processed it, or because
* it timed out.
*/
// 释放ip分片队列
static void ip_free(struct ipq *qp)
{
struct ipfrag *fp;
struct ipfrag *xp;
/*
* Stop the timer for this entry.
*/
// 删除定时器
del_timer(&qp->timer);
/* Remove this entry from the "incomplete datagrams" queue. */
cli();
/*
被删除的节点前面没有节点说明他是第一个节点,因为不是循环链表,
修改首指针ipqueue指向被删除节点的下一个,如果下一个不为空,下一个节点的prev节点指向空,
因为这时候他为第一个节点。
*/
if (qp->prev == NULL)
{
ipqueue = qp->next;
if (ipqueue != NULL)
ipqueue->prev = NULL;
}
else
{
/*
被删除节点不是第一个节点,但可能是最后一个,
被删除节点的前一个节点的next指针指向被删除节点的下一个节点,
如果如果被删除节点的下一个节点不为空则他的prev指针执行被删除节点
前面的节点
*/
qp->prev->next = qp->next;
if (qp->next != NULL)
qp->next->prev = qp->prev;
}
/* Release all fragment data. */
fp = qp->fragments;
// 删除所有分片节点
while (fp != NULL)
{
xp = fp->next;
IS_SKB(fp->skb);
kfree_skb(fp->skb,FREE_READ);
kfree_s(fp, sizeof(struct ipfrag));
fp = xp;
}
// 删除mac头和ip头,8字节是icmp用的,存放传输层的前8个字节
/* Release the MAC header. */
kfree_s(qp->mac, qp->maclen);
/* Release the IP header. */
kfree_s(qp->iph, qp->ihlen + 8);
/* Finally, release the queue descriptor itself. */
kfree_s(qp, sizeof(struct ipq));
sti();
}
ip_expire
- ip_expire函数负责处理分片重组超时的情况
/*
* Oops- a fragment queue timed out. Kill it and send an ICMP reply.
*/
// 分片重组超时处理函数
static void ip_expire(unsigned long arg)
{
struct ipq *qp;
qp = (struct ipq *)arg;
/*
* Send an ICMP "Fragment Reassembly Timeout" message.
*/
ip_statistics.IpReasmTimeout++;
ip_statistics.IpReasmFails++;
/* This if is always true... shrug */
// 发送icmp超时报文
if(qp->fragments!=NULL)
icmp_send(qp->fragments->skb,ICMP_TIME_EXCEEDED,
ICMP_EXC_FRAGTIME, 0, qp->dev);
/*
* Nuke the fragment queue.
*/
// 释放分片队列
ip_free(qp);
}
ip_defrag
- ip_defrag函数接收到一个IP数据报后判断是否为某个IP数据报分片的一部分,如果是,则处理好分片重叠问题,然后将当前分片插入ipq队列对应位置处,最后检查当前IP数据报全部分片是否都已到达,如果是,则进入重组阶段,最终返回重组后的IP数据报
/*
* Process an incoming IP datagram fragment.
*/
// 处理分片报文
static struct sk_buff *ip_defrag(struct iphdr *iph, struct sk_buff *skb, struct device *dev)
{
struct ipfrag *prev, *next;
struct ipfrag *tfp;
struct ipq *qp;
struct sk_buff *skb2;
unsigned char *ptr;
int flags, offset;
int i, ihl, end;
ip_statistics.IpReasmReqds++;
/* Find the entry of this IP datagram in the "incomplete datagrams" queue. */
qp = ip_find(iph); // 根据ip头找是否已经存在分片队列
/* Is this a non-fragmented datagram? */
offset = ntohs(iph->frag_off);
flags = offset & ~IP_OFFSET; // 取得三个分片标记位
offset &= IP_OFFSET; // 取得分片偏移
// 如果没有更多分片了,并且offset=0(第一个分片),则属于出错,第一个分片后面肯定还有分片,否则干嘛要分片
if (((flags & IP_MF) == 0) && (offset == 0))
{
if (qp != NULL)
ip_free(qp); /* Huh? How could this exist?? */
return(skb);
}
// 偏移乘以8得到数据的真实偏移
offset <<= 3; /* offset is in 8-byte chunks */
/*
* If the queue already existed, keep restarting its timer as long
* as we still are receiving fragments. Otherwise, create a fresh
* queue entry.
*/
/*
如果已经存在分片队列,说明之前已经有分片到达,重置计时器,所以超时的逻辑是,
如果IP_FRAG_TIME时间内没有分片到达,则认为重组超时,这里没有以总时间来判断。
*/
if (qp != NULL)
{
del_timer(&qp->timer);
qp->timer.expires = IP_FRAG_TIME; /* about 30 seconds */
qp->timer.data = (unsigned long) qp; /* pointer to queue */
qp->timer.function = ip_expire; /* expire function */
add_timer(&qp->timer);
}
else
{
/*
* If we failed to create it, then discard the frame
*/
// 新建一个管理分片队列的节点
if ((qp = ip_create(skb, iph, dev)) == NULL)
{
skb->sk = NULL;
kfree_skb(skb, FREE_READ);
ip_statistics.IpReasmFails++;
return NULL;
}
}
/*
* Determine the position of this fragment.
*/
// ip头长度
ihl = (iph->ihl * sizeof(unsigned long));
// 偏移+数据部分长度等于end,end的值是最后一个字节+1
end = offset + ntohs(iph->tot_len) - ihl;
/*
* Point into the IP datagram 'data' part.
*/
// data指向整个报文首地址,即mac头首地址,ptr指向ip报文的数据部分
ptr = skb->data + dev->hard_header_len + ihl;
/*
* Is this the final fragment?
*/
// 是否是最后一个分片,是的话,未分片的ip报文长度为end,即最后一个报文的最后一个字节的偏移+1,因为偏移从0算起
if ((flags & IP_MF) == 0)
qp->len = end;
/*
* Find out which fragments are in front and at the back of us
* in the chain of fragments so far. We must know where to put
* this fragment, right?
*/
prev = NULL;
// 插入分片队列相应的位置,保证分片的有序
for(next = qp->fragments; next != NULL; next = next->next)
{ // 找出第一个比当前分片偏移大的节点
if (next->offset > offset)
break; /* bingo! */
prev = next;
}
/*
* We found where to put this one.
* Check for overlap with preceding fragment, and, if needed,
* align things so that any overlaps are eliminated.
*/
// 处理分片重叠问题
/*
处理当前节点和前面节点的重叠问题,因为上面保证了offset >= prev->offset,
所以只需要比较当前节点的偏移和prev节点的end字段
*/
if (prev != NULL && offset < prev->end)
{
// 说明存在重叠,算出重叠的大小,把当前节点的重叠部分丢弃,更新offset和ptr指针往前走,没处理完全重叠的情况
i = prev->end - offset;
offset += i; /* ptr into datagram */
ptr += i; /* ptr into fragment data */
}
/*
* Look for overlap with succeeding segments.
* If we can merge fragments, do it.
*/
// 处理当前节点和后面节点的重叠问题
for(; next != NULL; next = tfp)
{
tfp = next->next;
// 当前节点及其后面的节点都不会发生重叠了
if (next->offset >= end)
break; /* no overlaps at all */
// 反之发生了重叠,算出重叠大小
i = end - next->offset; /* overlap is 'i' bytes */
// 更新和当前节点重叠的节点的字段,往后挪
next->len -= i; /* so reduce size of */
next->offset += i; /* next fragment */
next->ptr += i;
/*
* If we get a frag size of <= 0, remove it and the packet
* that it goes with.
*/
// 发生了完全重叠,则删除旧的节点
if (next->len <= 0)
{
if (next->prev != NULL)
next->prev->next = next->next;// 说明旧节点不是第一个节点
else
qp->fragments = next->next;// 说明旧节点是第一个节点
// 这里应该是tfp !=NULL ?
if (tfp->next != NULL)
next->next->prev = next->prev;
kfree_skb(next->skb,FREE_READ);
kfree_s(next, sizeof(struct ipfrag));
}
}
/*
* Insert this fragment in the chain of fragments.
*/
tfp = NULL;
// 创建一个分片节点
tfp = ip_frag_create(offset, end, skb, ptr);
/*
* No memory to save the fragment - so throw the lot
*/
if (!tfp)
{
skb->sk = NULL;
kfree_skb(skb, FREE_READ);
return NULL;
}
// 插入分片队列
tfp->prev = prev;
tfp->next = next;
if (prev != NULL)
prev->next = tfp;
else
qp->fragments = tfp;
if (next != NULL)
next->prev = tfp;
/*
* OK, so we inserted this new fragment into the chain.
* Check if we now have a full IP datagram which we can
* bump up to the IP layer...
*/
// 判断全部分片是否到达,是的话重组
if (ip_done(qp))
{
skb2 = ip_glue(qp); /* glue together the fragments */
return(skb2);
}
return(NULL);
}
ip_rcv
- ip_rcv函数负责完成一个IP数据报的接收过程
/*
* This function receives all incoming IP datagrams.
*/
int ip_rcv(struct sk_buff *skb, struct device *dev, struct packet_type *pt)
{
struct iphdr *iph = skb->h.iph;
struct sock *raw_sk=NULL;
unsigned char hash;
unsigned char flag = 0;
unsigned char opts_p = 0; /* Set iff the packet has options. */
struct inet_protocol *ipprot;
static struct options opt; /* since we don't use these yet, and they
take up stack space. */
int brd=IS_MYADDR;
int is_frag=0;
#ifdef CONFIG_IP_FIREWALL
int err;
#endif
ip_statistics.IpInReceives++;
/*
* Tag the ip header of this packet so we can find it
*/
skb->ip_hdr = iph;
/*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* (4. We ought to check for IP multicast addresses and undefined types.. does this matter ?)
*/
// 参数检查
if (skb->len<sizeof(struct iphdr) || iph->ihl<5 || iph->version != 4 ||
skb->len<ntohs(iph->tot_len) || ip_fast_csum((unsigned char *)iph, iph->ihl) !=0)
{
ip_statistics.IpInHdrErrors++;
kfree_skb(skb, FREE_WRITE);
return(0);
}
/*
* See if the firewall wants to dispose of the packet.
*/
// 配置了防火墙,则先检查是否符合防火墙的过滤规则,否则则丢掉
#ifdef CONFIG_IP_FIREWALL
if ((err=ip_fw_chk(iph,dev,ip_fw_blk_chain,ip_fw_blk_policy, 0))!=1)
{
if(err==-1)
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0, dev);
kfree_skb(skb, FREE_WRITE);
return 0;
}
#endif
/*
* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
*/
skb->len=ntohs(iph->tot_len);
/*
* Next analyse the packet for options. Studies show under one packet in
* a thousand have options....
*/
// ip头超过20字节,说明有选项
if (iph->ihl != 5)
{ /* Fast path for the typical optionless IP packet. */
memset((char *) &opt, 0, sizeof(opt));
if (do_options(iph, &opt) != 0)
return 0;
opts_p = 1;
}
/*
* Remember if the frame is fragmented.
*/
// 非0则说明是分片
if(iph->frag_off)
{
// 是否设置了MF,即还有更多分片,是的话is_frag等于1
if (iph->frag_off & 0x0020)
is_frag|=1;
/*
* Last fragment ?
*/
// 非0说明有偏移,即不是第一个块分片
if (ntohs(iph->frag_off) & 0x1fff)
is_frag|=2;
}
/*
* Do any IP forwarding required. chk_addr() is expensive -- avoid it someday.
*
* This is inefficient. While finding out if it is for us we could also compute
* the routing table entry. This is where the great unified cache theory comes
* in as and when someone implements it
*
* For most hosts over 99% of packets match the first conditional
* and don't go via ip_chk_addr. Note: brd is set to IS_MYADDR at
* function entry.
*/
if ( iph->daddr != skb->dev->pa_addr && (brd = ip_chk_addr(iph->daddr)) == 0)
{
/*
* Don't forward multicast or broadcast frames.
*/
if(skb->pkt_type!=PACKET_HOST || brd==IS_BROADCAST)
{
kfree_skb(skb,FREE_WRITE);
return 0;
}
/*
* The packet is for another target. Forward the frame
*/
#ifdef CONFIG_IP_FORWARD
ip_forward(skb, dev, is_frag);
#else
/* printk("Machine %lx tried to use us as a forwarder to %lx but we have forwarding disabled!\n",
iph->saddr,iph->daddr);*/
ip_statistics.IpInAddrErrors++;
#endif
/*
* The forwarder is inefficient and copies the packet. We
* free the original now.
*/
kfree_skb(skb, FREE_WRITE);
return(0);
}
#ifdef CONFIG_IP_MULTICAST
if(brd==IS_MULTICAST && iph->daddr!=IGMP_ALL_HOSTS && !(dev->flags&IFF_LOOPBACK))
{
/*
* Check it is for one of our groups
*/
struct ip_mc_list *ip_mc=dev->ip_mc_list;
do
{
if(ip_mc==NULL)
{
kfree_skb(skb, FREE_WRITE);
return 0;
}
if(ip_mc->multiaddr==iph->daddr)
break;
ip_mc=ip_mc->next;
}
while(1);
}
#endif
/*
* Account for the packet
*/
#ifdef CONFIG_IP_ACCT
ip_acct_cnt(iph,dev, ip_acct_chain);
#endif
/*
* Reassemble IP fragments.
*/
// 还有更多分片(等于1),不是第一个分片(等于2)或者两者(等于3)则分片重组
if(is_frag)
{
/* Defragment. Obtain the complete packet if there is one */
skb=ip_defrag(iph,skb,dev);
if(skb==NULL)
return 0;
skb->dev = dev;
iph=skb->h.iph;
}
/*
* Point into the IP datagram, just past the header.
*/
skb->ip_hdr = iph;
// 往上层传之前先指向上层的头
skb->h.raw += iph->ihl*4;
/*
* Deliver to raw sockets. This is fun as to avoid copies we want to make no surplus copies.
*/
hash = iph->protocol & (SOCK_ARRAY_SIZE-1);
/* If there maybe a raw socket we must check - if not we don't care less */
if((raw_sk=raw_prot.sock_array[hash])!=NULL)
{
struct sock *sknext=NULL;
struct sk_buff *skb1;
// 找对应的socket
raw_sk=get_sock_raw(raw_sk, hash, iph->saddr, iph->daddr);
if(raw_sk) /* Any raw sockets */
{
do
{
/* Find the next */
// 从队列中raw_sk的下一个节点开始找满足条件的socket,因为之前的的肯定不满足条件了
sknext=get_sock_raw(raw_sk->next, hash, iph->saddr, iph->daddr);
// 复制一份skb给符合条件的socket
if(sknext)
skb1=skb_clone(skb, GFP_ATOMIC);
else
break; /* One pending raw socket left */
if(skb1)
raw_rcv(raw_sk, skb1, dev, iph->saddr,iph->daddr);
// 记录最近符合条件的socket
raw_sk=sknext;
}
while(raw_sk!=NULL);
/* Here either raw_sk is the last raw socket, or NULL if none */
/* We deliver to the last raw socket AFTER the protocol checks as it avoids a surplus copy */
}
}
/*
* skb->h.raw now points at the protocol beyond the IP header.
*/
// 传给ip层的上传协议
hash = iph->protocol & (MAX_INET_PROTOS -1);
// 获取哈希链表中的一个队列,遍历
for (ipprot = (struct inet_protocol *)inet_protos[hash];ipprot != NULL;ipprot=(struct inet_protocol *)ipprot->next)
{
struct sk_buff *skb2;
if (ipprot->protocol != iph->protocol)
continue;
/*
* See if we need to make a copy of it. This will
* only be set if more than one protocol wants it.
* and then not for the last one. If there is a pending
* raw delivery wait for that
*/
/*
是否需要复制一份skb,copy字段这个版本中都是0,有多个一样的协议才需要复制一份,
否则一份就够,因为只有一个协议需要使用,raw_sk的值是上面代码决定的
*/
if (ipprot->copy || raw_sk)
{
skb2 = skb_clone(skb, GFP_ATOMIC);
if(skb2==NULL)
continue;
}
else
{
skb2 = skb;
}
// 找到了处理该数据包的上层协议
flag = 1;
/*
* Pass on the datagram to each protocol that wants it,
* based on the datagram protocol. We should really
* check the protocol handler's return values here...
*/
ipprot->handler(skb2, dev, opts_p ? &opt : 0, iph->daddr,
(ntohs(iph->tot_len) - (iph->ihl * 4)),
iph->saddr, 0, ipprot);
}
/*
* All protocols checked.
* If this packet was a broadcast, we may *not* reply to it, since that
* causes (proven, grin) ARP storms and a leakage of memory (i.e. all
* ICMP reply messages get queued up for transmission...)
*/
if(raw_sk!=NULL) /* Shift to last raw user */
raw_rcv(raw_sk, skb, dev, iph->saddr, iph->daddr);
// 没找到处理该数据包的上层协议,报告错误
else if (!flag) /* Free and report errors */
{
// 不是广播不是多播,发送目的地不可达的icmp包
if (brd != IS_BROADCAST && brd!=IS_MULTICAST)
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0, dev);
kfree_skb(skb, FREE_WRITE);
}
return(0);
}
总结
经过理论和实践,相信各位已经知道了最开始抛出的答案了:
- IP协议是不可靠协议,虽然IP层需要进行分片和重组,但是不会使用ACK,重传等机制确保该过程的可靠性,而仅仅使用超时定时器来判断分组重组过程是否超时,如果超时,则回应一个ICMP重组超时错误报文